系统环境
- Ubuntu 18.04
- CUDA 10.1
- cuDNN 7.6.5
获取LibTorch
从官网下载LibTorch的GPU版本二进制包。注意版本。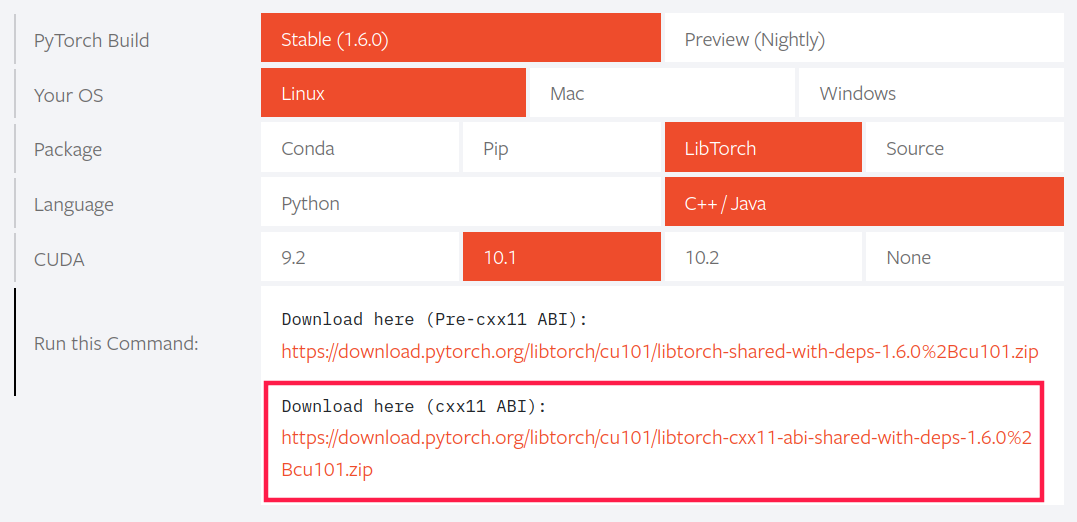
我之前PyTorch用的是1.4版本,因此LibTorch保持同版本,修改下载地址如下:
https://download.pytorch.org/libtorch/cu101/libtorch-cxx11-abi-shared-with-deps-1.4.0.zip
百度云下载地址,有cpu后缀的是CPU版本的,没有的是GPU版本的。
链接: https://pan.baidu.com/s/1mSHh66CIzO6hzVE4-2Ytkw 密码: cb24
解压后即可使用。
CMakeLists.txt编写
cmake_minimum_required(VERSION 3.7)project(deploy)set(CMAKE_CXX_STANDARD 11)# 指定文件夹位置set(OPENCV_DIR /home/luzhan/软件/opencv-3.4.3)#set(Torch_DIR /home/luzhan/软件/libtorch_cpu/share/cmake/Torch)set(Torch_DIR /home/luzhan/软件/libtorch_gpu/share/cmake/Torch)set(CUDA_TOOLKIT_ROOT_DIR /usr/local/cuda)# 自动查找包find_package(Torch REQUIRED)find_package(OpenCV 3.4.3 REQUIRED)# 添加源程序add_executable(deploymain.cpp)# 添加头文件include_directories(${OpenCV_INCLUDE_DIRS} ./include)# 加入库文件位置target_link_libraries(deploy${OpenCV_LIBS}-pthread-lMVSDK/lib/libMVSDK.so)target_link_libraries(deploy${TORCH_LIBRARIES})
主程序代码
/*** @author starrysky* @date 2020/08/16* @version 1.0* @details LibTorch调用PyTorch已经训练好的模型, 对传入的OpenCV的灰度图进行分类*/#include <torch/script.h>#include <torch/torch.h>#include <vector>#include <opencv2/opencv.hpp>#include "opencv2/imgcodecs.hpp"#include "opencv2/imgproc.hpp"#include <iostream>#include <opencv2/tracking.hpp>class DigitalRecognition {private:torch::jit::script::Module module;torch::Device device;const int IMAGE_COLS = 28;const int IMAGE_ROWS = 28;public:/*** 默认使用CPU,可通过标志位开启使用GPU* @param use_cuda 是否使用GPU* @param model_path 模型文件路径*/explicit DigitalRecognition(bool use_cuda = false,const std::string &model_path = "../model/model.pt") : device(torch::kCPU) {if ((use_cuda) && (torch::cuda::is_available())) {std::cout << "CUDA is available! Training on GPU." << std::endl;device = torch::kCUDA;}module = torch::jit::load(model_path, device);}/*** 单张图片分类器* @param img 图片,cv::Mat类型* @return 分类结果*/int matToDigital(cv::Mat &img) {// 正则化img.convertTo(img, CV_32FC1, 1.0f / 255.0f);// 模型用的是 28*28 的单通道灰度图cv::resize(img, img, cv::Size(IMAGE_COLS, IMAGE_ROWS));// 将 OpenCV 的 Mat 转换为 Tensor, 注意两者的数据格式// OpenCV: H*W*C 高度, 宽度, 通道数auto input_tensor = torch::from_blob(img.data, {1, IMAGE_COLS, IMAGE_ROWS, 1});// Tensor: N*C*H*W 数量, 通道数, 高度, 宽度// 数字表示顺序input_tensor = input_tensor.permute({0, 3, 1, 2}).to(device);// 添加数据std::vector<torch::jit::IValue> inputs;inputs.emplace_back(input_tensor);// 模型计算at::Tensor output = module.forward(inputs).toTensor();std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/7) << '\n';// 输出分类的结果int ans = output.argmax(1).item().toInt();std::cout << "当前机器人编号: " << ans << std::endl;return ans;}};int main() {DigitalRecognition digitalRecognition;cv::Mat img = cv::imread("../image/1.jpg", CV_8UC1);digitalRecognition.matToDigital(img);return 0;}

若有收获,就点个赞吧
0 人点赞
