1.基本思路
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 看下面这幅图:
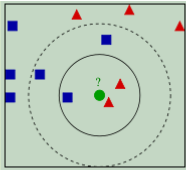
KNN的算法过程是是这样的: 从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形 我们可以看到,KNN本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的。 KNN是一种memory-based learning,也叫instance-based learning,属于lazy learning。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。 具体是每次来一个未知的样本点,就在附近找K个最近的点进行投票。
2.距离计算
KNN算法的实现就是取决于,未知样本和训练样本的“距离”。我们计算“距离”可以利用欧式距离算法: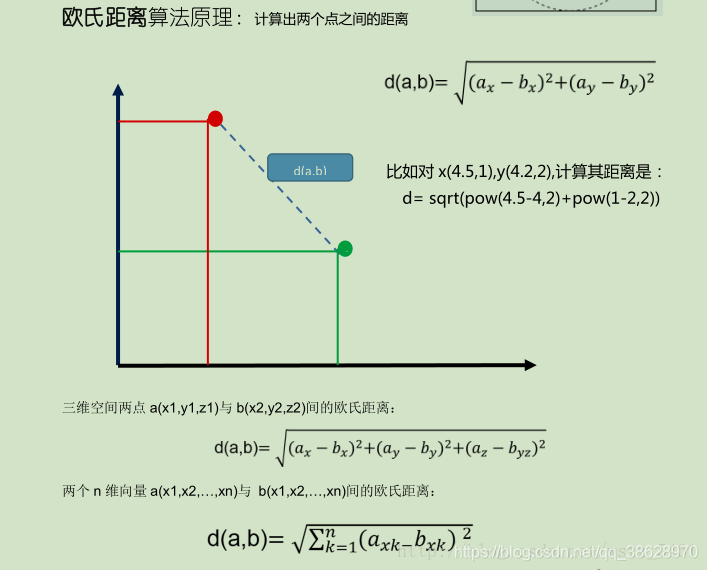
3.算法实现(案例)

4.KNN用于数值预测
求出K个最相近的元组后,用这些元组对应的数值的平均值作为最终结果。
5.K的选择
可以从K=1开始,逐步增加,用检验数据来分析正确率,从而选择最优K。这个结果要均衡考虑正确率与计算量,比如K=3时,正确率为90%,而K=10时,正确率为91%,则需要考虑计算量换来的1%提升是否合算了。
6.一些优化技巧
(1)如果可能的话先对样本数据进行排序,从而知道只需要与哪些数据进行比较。但对于高维数据,这几乎是不可行的。
(2)将样本数据划分为多个子集合,待分类数据只需要与其中的一个或者多个子集合进行比较。比如属性是经纬度,距离是2个经纬度点之间的距离,则可以将样本根据经纬度的整数部分将各个样本分到不同的子集合去,待分类元组只需要跟与自己整数部分相同的子集合进行比较即可,当子集合内的样本数据不足K时,再和邻近的集合进行比较。
7.优缺点
KNN的主要优点有:
(1)理论成熟,思想简单,既可以用来做分类又可以做回归
(2)可以用于非线性分类
(3)训练时间复杂度比支持向量机之类的算法低
(4)和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
(5)由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属的类别,因此对于类域的交叉或重叠较多的待分类样本集来说,KNN方法较其他方法更为适合
(6)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量比较小的类域采用这种算法比较容易产生误分类情况
KNN的主要缺点:
(1)计算量大,尤其是特征数非常多的时候
(2)样本不平衡的时候,对稀有类别的预测准确率低
(3)KD树,球树之类的模型建立需要大量的内存
(4)是慵懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
(5)相比决策树模型,KNN模型的可解释性不强

若有收获,就点个赞吧
0 人点赞
