基本功能列表
import pandas as pd 导入库
df = pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
创建一个DataFrame
| 代码 | 功能 | |
|---|---|---|
| 1 | DataFrame() | 创建一个DataFrame对象 |
| 2 | df.values | 返回ndarray类型的对象 |
| 3 | df.index | 获取行索引 |
| 4 | df.columns | 获取列索引 |
| 5 | df.axes | 获取行及列索引 |
| 6 | df.T | 行与列对调 |
| 7 | df. info() | 打印DataFrame对象的信息 |
| 8 | df.head(i) | 显示前 i 行数据 |
| 9 | df.tail(i) | 显示后 i 行数据 |
| 10 | df.describe() | 查看数据按列的统计信息 |
1.创建一个DataFrame
DataFrame()函数的参数index的值相当于行索引,若不手动赋值,将默认从0开始分配。columns的值相当于列索引,若不手动赋值,也将默认从0开始分配。
data = {'性别':['男','女','女','男','男'],'姓名':['小明','小红','小芳','大黑','张三'],'年龄':[20,21,25,24,29]}df = pd.DataFrame(data,index=['one','two','three','four','five'],columns=['姓名','性别','年龄','职业'])df
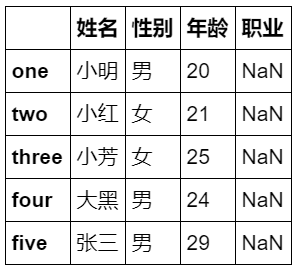
2. df.values 返回ndarray类型的对象
ndarray类型即numpy的 N 维数组对象,通常将DataFrame类型的数据转换为ndarray类型的比较方便操作。如对DataFrame类型进行切片操作需要df.iloc[ : , 1:3]这种形式,对数组类型直接X[ : , 1:3]即可。
X = df.valuesprint(type(X)) #显示数据类型X
运行结果:
<class 'numpy.ndarray'>array([['France', 44.0, 72000.0],['Spain', 27.0, 48000.0],['Germany', 30.0, 54000.0],['Spain', 38.0, 61000.0],['Germany', 40.0, nan],['France', 35.0, 58000.0],['Spain', nan, 52000.0],['France', 48.0, 79000.0],['Germany', 50.0, 83000.0],['France', 37.0, 67000.0]], dtype=object)
3. df.index 获取行索引
df.index
运行结果:
Index(['one', 'two', 'three', 'four', 'five'], dtype='object')
4. df.columns 获取列索引
df.columns
运行结果:
Index(['姓名', '性别', '年龄', '职业'], dtype='object')
5. df.axes 获取行及列索引
df.axes
运行结果:
[Index(['one', 'two', 'three', 'four', 'five'], dtype='object'),Index(['姓名', '性别', '年龄', '职业'], dtype='object')]
6. df.T index 与 columns 对调
df.T
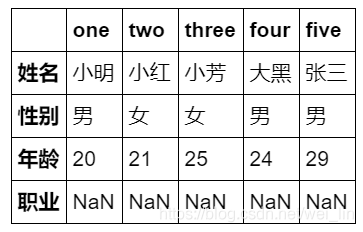
7. df.info() 打印DataFrame对象的信息
df.info()
运行结果:
<class 'pandas.core.frame.DataFrame'>Index: 5 entries, one to fiveData columns (total 4 columns):姓名 5 non-null object性别 5 non-null object年龄 5 non-null int64职业 0 non-null objectdtypes: int64(1), object(3)memory usage: 200.0+ bytes
8.df.head(i) 显示前 i 行数据
df.head(2)
运行结果: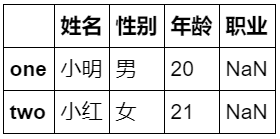
若想要显示前几列数据,可用df.T.head(i)
9. df.tail(i) 显示后 i 行数据
df.tail(2)
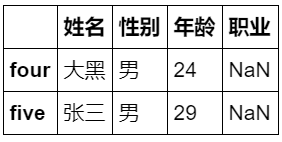
10. df.describe() 查看数据按列的统计信息
可显示数据的数量、缺失值、最小最大数、平均值、分位数等信息

若有收获,就点个赞吧
0 人点赞
