一、数据挖掘的五大流程
- 获取数据
- 数据预处理
- 数据预处理是从数据中检测,纠正或删除孙华,不准确或不适用于模型的记录的过程
- 目的: 让数据适应模型, 匹配模型的需求
- 特征工程
- 特征工程是将原始数据转换为更能代表预测模型的潜在无问题的特征的过程, 可以通过挑选最相关的特征,提取特征以及创造特征来实现.
- 目的: 降低计算成本,提高模型上限
- 建模,测试模型并预测出结果
- 上线,验证模型效果
二、数据预处理(preprocessing)
数据归一化
当数据按照最小值中心化后,在按照极差(最大值-最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0, 1]之间的过程称为数据归一化(Normalization, 又称Min-Max Scaling)

sklearn中的实现方法
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(data)result = scaler.transform(data)# 也可以使用fit_transform将结果一步达成# result = scaler.fit_transform(data)# 将归一化结果逆转scaler.inverse_transform(result)
当特征数量特别多的时候,**fit会报错,这时需要使用partial_fit,与fit**用法相同
数据标准化
当数据按均值中心化后,再按照标准差进行缩放,数据就会服从均值为0,方差为1的正态分布,这个过程称为数据标准化(Standardization, 又称Z-score normalization)

方差:
标准差: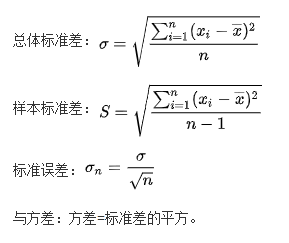
sklearn中的实现方法
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()scaler.fit(data)# 均值scaler.mean_# 方差scaler.var_# 标准化后的结果x_std = scaler.transform(data)# 也可以使用fit_transform将结果一步达成# x_std = scaler.fit_transform(data)# 将归一化结果逆转scaler.inverse_transform(x_std)
StandardScaler和MinMaxScaler选哪个
大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感.在PCA, 聚类, 逻辑回归, 支持向量机, 神经网络等算法中,StandardScaler往往会是更好地选择
MinMaxScaler在不涉及距离度量,梯度,协方差计算以及数据需要被压缩到特定区间时使用广泛,如数字图像处理中量化像素强度时.
缺失值处理
pandas中查看是否存在缺失值以及缺失值数量
data.info()
填补缺失值的方法有
- 均值填补
- 中值填补
- 众数填补
- 也可以使用预测等方法填补
sklearn中的缺失值填补方法
sklearn.impute.SimpleImputer(missing_values: 缺失值的样子,默认为np.nan,strategy: 填补方式, 默认为均值("mean": 均值,'median': 中值,'most_frequent': 众数,'constant': fill_value中的值),fill_value: 当strategy为'constant'时填充该值,copy: 是否返回新副本,否的话在原来数据基础上进行填充)
也可以直接使用pandas提供的fillna直接进行填补
data.loc[:, 'Age'] = data.loc[:, 'Age'].fillna(data.loc[:, 'Age'].median())
也可以直接删除有缺失值的行
data = data.dropna(axis=0, inplace=False)
处理离散型特征和非数值型标签
将离散型特征数据转换成one-hot(向量)格式, 非数值型标签转换为数值型标签
sklearn中将离散型非数值便签转换为数值型标签**
sklearn.preprocessing.LabelEncoder()
可以使用inverse_transform方法进行逆转
sklearn中将离散型非数值型特征转换为数值型特征**
sklearn.preprocessing.OrdinalEncoder()
一般情况下,会将离散型特征转换为One-hot编码格式
sklearn中转换为One-hot格式的方法**
sklearn.preprocessing.OneHotEncoder(categories='auto': 表示自动指定每个特征的类别数)
训练后进行transform返回的是一个稀疏矩阵,需要使用toarray()来转换为array
可以使用categories_属性查看新的特征索引
可以使用inverse_transform方法进行逆转
可以使用onehot.get_feature_names()获取每个系数矩阵的列名
sklearn中将标签转换为one-hot类型
sklearn.preprocessing.LabelBinarizer()
处理连续型特征
二值化
将连续型特征变量,大于阈值的映射为1,小于阈值的映射为0.
sklearn中的二值化方法
from sklearn.preprocessing import Binarizer(threshold: 阈值)
分箱
将连续型变量进行多个划分,每个划分为一定的范围
sklearn中的分箱方法
sklearn.preprocessing.KBinsDiscretizer(n_bins: 每个特征分箱的个数,默认为5,encode: 编码方式,默认为"onehot.('onehot'为one-hot编码, 'ordinal'表示将每一组编码为一个整数, 'onehot-dense': 进行one-hot编码后返回一个密集数组),strategy: 定义箱宽de方式,默认为"quantile".('uniform': 等宽分箱,即间隔大小相同, 'quantile': 等位分箱,即样本数量相同, 'kmeans': 表示聚类分箱))
可以通过
bin_edges_属性查看其分箱边缘(不是列名)
特征选择(feature selection)
一定要先理解数据的含义
特征提取(feature extraction)
Filter过滤法
方差过滤
通过特征本身的方差来筛选特征的类.比如一个特征本身的方差特别小,那么这个特征基本上没有存在的必要(数据之间的该特征基本没什么差别).所以,需要先消除方差为0的特征
sklearn中的方差过滤方法**
sklearn.feature_selection.VarianceThreshold(threshold: float类型, 要过滤的方差大小,默认为0.0)
可以直接使用pandas中的var查看方差,然后使用drop进行删除 如果特征是伯努利随机变量,可以使用p*(1-p)来计算方差(p为某一类的概率)
相关性过滤
卡方过滤
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤.在sklearn中,卡方检验类feature_selection.chi2计算每个非负特征与便签之间的卡方统计量,并按照卡方统计量由高到低为特征排名.再结合
feature_selection.SelectKBest这个可以输入”评分标准”来选出前k个分数最高的特征的类.
sklearn中的卡方统计量**
sklearn.feature_selection.chi2(x, y)
sklearn中的卡方过滤方法**
sklearn.feature_selection.SelectKBest(chi2, k: 选择的特征数)
选择k值时可以使用p值,当小于等于0.05或0.01表示相关,大于表示不相关,p值可以通过pvalues_属性获得,也可以通过chi2获得(返回值是卡方值和p值)
F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法.它既可以做回归又可以做分类.
F检验之前需要先将数据转换成服从正态分布的形式 通常会将卡方检验和F检验一起使用
sklearn中的F检验方法**
sklearn.feature_selection.f_classif(x, y)sklearn.feature_selection.f_regression(x, y)
该方法会返回两个数,分别是F值和p值,p值的判断方式与卡方检验相同
判断出k值(特征数量)后,然后使用SelectKBest进行选取特征,不同的是第一个参数为F检验的方法
sklearn.feature_selection.SelectKBest(f_classif, k: 选择的特征数)sklearn.feature_selection.SelectKBest(f_regression, k: 选择的特征数)
互信息法
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性关系和非线性关系)的过滤方法,可以做回归也可以做分类
sklearn中的互信息法**
sklearn.feature_selection.mutual_info_calssif(x, y)sklearn.feature_selection.mutual_indo_regression(x, y)
会返回一个值表示每个特征与目标之间的互信息量的估计,0表示两个变量独立,1表示两个变量完全相关,通过该值可以确定k的具体数值
其用法与F检验和卡方检验相同,需要搭配SelectKBest使用
sklearn.feature_selection.SelectKBest(mutual_info_calssif, k: 选择的特征数)sklearn.feature_selection.SelectKBest(mutual_indo_regression, k: 选择的特征数)
Embedded嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征
sklearn中的嵌入法**
sklearn.feature_selection.SelectionFromModel(estimator: 模型,只要到feature_importances_或coef_属性或者带惩罚项的模型,threshold: 特征重要性的阈值,低于这个阈值的会被删除,prefit: 默认为False,判断是否将实例化后的模型直接传递给构造函数,若为True,则必须调用fit和transform,不能使用fit_transform,norm_order: k可输入非整数,正无穷,负无穷,默认为1.在模型的coef_属性高于一维的情况下,用于过滤低于阈值的系数的向量的范数的阶数,max_features: 在阈值设定下,要选择的最大特征数.要禁用阈值并仅根据max_features选择,需要配置threshold=-np.inf)
SelectionFromModel可以与任何一个在拟合后具有
coef_,feature_importances_属性或者参数中具有可惩罚项的模型一起使用
Wrapper包装法
包装法也是一个特征选择和孙发训练同时进行的方法,如嵌入法十分相似,他也是依赖于算法自身具有coef_, feature_importances_属性来完成特征选择.但是不同的是,我们往往使用一个目标函数作为黑盒来选取特征.
最典型的目标函数是递归特征消除法(Recursive feature elimination,简称RFE), 它是一种贪婪的优化算法,旨在找到性能最佳的特征子集.它反复创建模型,并且在每次迭代时保留最佳特征或剔除最差特征,下一次,他会使用上一次建模中没有被选中的特征来构建下一个模型,知道所有特征都耗尽为止. 然后,他根据自己保留或剔除特征的顺序来对特征进行排名,最终选出一个最佳子集.
包装法的效果时多有的特征选择方法中最有利于提升模型表现的,它可以使用很少的特征达到很优秀的效果
sklearn中的递归特征消除法(RFE)**
sklearn.feature_selection.RFE(estimator: 模型,n_features_to_selection: 特征选择的个数,step=1: 每次迭代中希望移除的特征个数,verbose=0: 控制输出的长度)
support属性为所有特征的布尔矩阵, ranking属性为特征按次数迭代中综合重要性的排名

若有收获,就点个赞吧
0 人点赞
