二分类(Binary classification)
对二分类问题常用的评估指标是精度(precision)、召回率(recall)、F1值(F1-score)。
原理分析
通常以关注的类为正类,其他类为负类。分类器在测试数据集上预测要么正确要么不正确。4种情况出现的总数分别记作:
tp—将正类预测为正类(true positive)
fn—将正类预测为负类(false negative)
fp—将负类预测为正类(false positive)
tn—将负类预测为负类(true negative)
用医院诊断病人是否有病作为示例,“有病”是被关注的正类,“没病”是负类。该例在本文称之为例1。
| 诊断为有病 | 诊断为没病 | |
|---|---|---|
| 病人 | tp | fn |
| 正常人 | fp | tn |
精度定义:
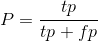……(1)
召回率定义:
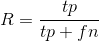……(2)<br /> (思考:为什么叫召回率?病人被诊断为没病,是不是要召回。)
F1值:
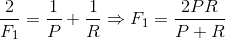……(3) <br /> F1值是精度和召回率的调和平均值。
示例计算:
如例1,下表记录了4中情况的人数。
| 诊断为有病 | 诊断为没病 | |
|---|---|---|
| 病人 | 1000 | 200 |
| 正常人 | 800 | 8000 |
代入公式(1)(2)(3)得出: P = 55.6%, R = 83.3%, F1 = 66.7%
当P和R都很高的时候,F1也会很高。
应用
精度、召回率、F1值能很好地评估一个模型是否合适。F1值越高,模型越合适。
使用例1演示代码,假设现有看病人数4个,病人就是数据集,诊断就是分类器(模型),0代表没病,1代表有病。
1. from sklearn.metrics import precision_score, recall_score, f1_score2. import numpy as np3.4. y_true = np.array([1, 0, 1, 1])5. y_pred = np.array([0, 1, 1, 0])
y_true是病人的真实情况,从数据来看,3个有病,1个没病。
y_pred是病人的预测情况,是分类器从看病的人身上的特征预测出来的。
假设分类器是决策树,X代表特征,即数据集,那么y_pred就是这么来的:
1. from sklearn.tree import DecisionTreeClassifier2. clf = DecisionTreeClassifier() #决策树分类器3. clf.fit(X_train, y_true) #拟合数据4. y_pred = clf.predict(X_test) #得出预测结果,从测试数据集
计算精度P,召回率R,F1值:
1. p = precision_score(y_true, y_pred) #输出结果0.52. r = recall_score(y_true, y_pred) #输出结果0.3333. f1 = f1_score(y_true, y_pred) #输出0.4
从结果看,各项指标都很差,所有得出结论该模型不合适,要么换一种,要么调整参数。
(思考:这里并不知道tp、fp、tn、fn各是多少,p,r,f1是怎么计算出来的?)
计算tp:
tp = sum(y_true & y_pred) #结果1
&计算:[1, 0, 1, 1]&[0, 1, 1, 0] ,判断是否为tp,即正类(有病,1)预测为正类(没病,0),结果是[False,False,True,False]。
sum计算tp的总数。
计算fp:
fp = sum((y_true == 0) & (y_pred == 1)) #结果1
计算tn:
tn = sum((y_true == 0) & (y_pred == 0)) #结果0
计算fn:
fn = sum((y_true == 1) & (y_pred == 0)) #结果2
正类(有病,1)预测为负类(没病,0)。

若有收获,就点个赞吧
0 人点赞
