数据分析的时候经常要把宽数据—->>长数据,有点像你们用excel 做透视跟逆透视的过程,直接看下面例子,希望有助于理解.
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)
参数解释:
frame:要处理的数据集。
id_vars:不需要被转换的列名。
value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了。
var_name和value_name是自定义设置对应的列名。
col_level :如果列是MultiIndex,则使用此级别。
例子:
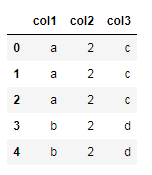
1. >>>d = {'col1': ['a','a','a','b','b'], 'col2': [2,2,2,2,2],'col3':['c','c','c','d','d']}2. >>>df = pd.DataFrame(data=d)3. >>>df
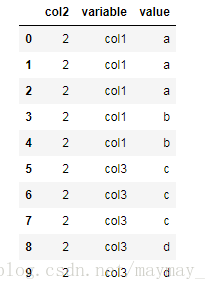
1、设置 id_vars=[‘col2’] ,则不需要转换的列是col2 。所以col1跟col3 合并成了一列。
>>>pd.melt(df,id_vars=['col2'])
2、设置 id_vars=[‘col2’],value_vars=[‘col1’] , 则不需要转换的列是col2 。需要转换的是 col1列 ,拿col3 就不受影响,不展示了。
pd.melt(df,id_vars=['col2'],value_vars=['col1'])
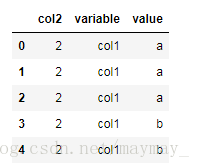
3、对修改后的列设置新列名。
pd.melt(df,id_vars=['col2'],value_vars=['col1'],var_name='hi',value_name='hello')

使用pandas.melt 进行行转列 ,列转行的操作请看
https://blog.csdn.net/maymay_/article/details/105349956

若有收获,就点个赞吧
0 人点赞
