I/O 多路复用
以最简单 socket 网络模型,一步一步的过度到 I/O 多路复用。
最基本的 Socket 模型
要想客户端和服务器能在网络中通信,那必须得使用 Socket 编程,它是进程间通信里比较特别的方式,特别之处在于它是可以跨主机间通信。
Socket 的中文名叫作插口,咋一看还挺迷惑的。事实上,双方要进行网络通信前,各自得创建一个 Socket,这相当于客户端和服务器都开了一个“口子”,双方读取和发送数据的时候,都通过这个“口子”。这样一看,是不是觉得很像弄了一根网线,一头插在客户端,一头插在服务端,然后进行通信。
创建 Socket 的时候,可以指定网络层使用的是 IPv4 还是 IPv6,传输层使用的是 TCP 还是 UDP。
UDP 的 Socket 编程相对简单些,这里只介绍基于 TCP 的 Socket 编程。
服务器的程序要先跑起来,然后等待客户端的连接和数据,先来看看服务端的 Socket 编程过程是怎样的。
服务端首先调用 socket() 函数,创建网络协议为 IPv4,以及传输协议为 TCP 的 Socket ,接着调用 bind() 函数,给这个 Socket 绑定一个 IP 地址和端口,绑定这两个的目的是什么?
- 绑定端口的目的:当内核收到 TCP 报文,通过 TCP 头里面的端口号,来找到应用程序,然后把数据传递给我们。
- 绑定 IP 地址的目的:一台机器是可以有多个网卡的,每个网卡都有对应的 IP 地址,当绑定一个网卡时,内核在收到该网卡上的包,才会发给我们;
绑定完 IP 地址和端口后,就可以调用 listen() 函数进行监听,此时对应 TCP 状态图中的 listen,如果要判定服务器中一个网络程序有没有启动,可以通过 netstate 命令查看对应的端口号是否有被监听。
服务端进入了监听状态后,通过调用 accept() 函数,来从内核获取客户端的连接,如果没有客户端连接,则会阻塞等待客户端连接的到来。
那客户端是怎么发起连接的呢?客户端在创建好 Socket 后,调用 connect() 函数发起连接,该函数的参数要指明服务端的 IP 地址和端口号,然后万众期待的 TCP 三次握手就开始了。
在 TCP 连接的过程中,服务器的内核实际上为每个 Socket 维护了两个队列:
- 一个是还没完全建立连接的队列,称为 TCP 半连接队列,这个队列都是没有完成三次握手的连接,此时服务端处于
syn_rcvd的状态; - 一个是一件建立连接的队列,称为 TCP 全连接队列,这个队列都是完成了三次握手的连接,此时服务端处于
established状态;
当 TCP 全连接队列不为空后,服务端的 accept() 函数,就会从内核中的 TCP 全连接队列里拿出一个已经完成连接的 Socket 返回应用程序,后续数据传输都用这个 Socket。
注意,监听的 Socket 和真正用来传数据的 Socket 是两个:
- 一个叫作监听 Socket;
- 一个叫作已连接 Socket;
连接建立后,客户端和服务端就开始相互传输数据了,双方都可以通过 read() 和 write() 函数来读写数据。
至此, TCP 协议的 Socket 程序的调用过程就结束了,整个过程如下图: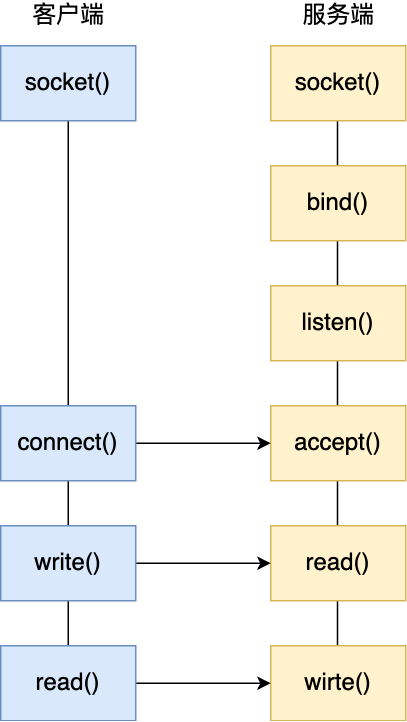
有没有觉得读写 Socket 的方式,好像读写文件一样。
是的,基于 Linux 一切皆文件的理念,在内核中 Socket 也是以「文件」的形式存在的,也是有对应的文件描述符。
文件描述符的作用是什么?每一个进程都有一个数据结构 task_struct,该结构体里有一个指向「文件描述符数组」的成员指针。该数组里列出这个进程打开的所有文件的文件描述符。数组的下标是文件描述符,是一个整数,而数组的内容是一个指针,指向内核中所有打开的文件的列表,也就是说内核可以通过文件描述符找到对应打开的文件。
然后每个文件都有一个 inode,Socket 文件的 inode 指向了内核中的 Socket 结构,在这个结构体里有两个队列,分别是发送队列和接收队列,这个两个队列里面保存的是一个个 struct sk_buff,用链表的组织形式串起来。
sk_buff 可以表示各个层的数据包,在应用层数据包叫 data,在 TCP 层称为 segment,在 IP 层叫 packet,在数据链路层称为 frame。
为什么全部数据包只用一个结构体来描述呢?协议栈采用的是分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头,如果每一层都用一个结构体,那在层之间传递数据的时候,就要发生多次拷贝,这将大大降低 CPU 效率。
于是,为了在层级之间传递数据时,不发生拷贝,只用 sk_buff 一个结构体来描述所有的网络包,那它是如何做到的呢?是通过调整 sk_buff 中 data 的指针,比如:
- 当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。
- 当要发送报文时,创建 sk_buff 结构体,数据缓存区的头部预留足够的空间,用来填充各层首部,在经过各下层协议时,通过减少 skb->data 的值来增加协议首部。
可以从下面这张图看到,当发送报文时,data 指针的移动过程。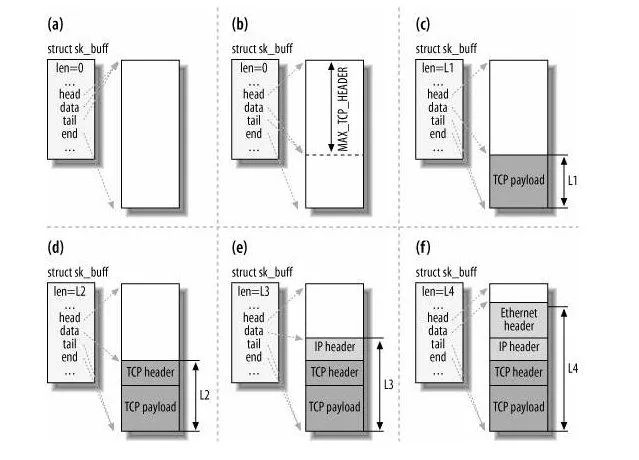
如何服务更多的用户?
前面提到的 TCP Socket 调用流程是最简单、最基本的,它基本只能一对一通信,因为使用的是同步阻塞的方式,当服务端在还没处理完一个客户端的网络 I/O 时,或者 读写操作发生阻塞时,其他客户端是无法与服务端连接的。
可如果服务器只能服务一个客户,那这样就太浪费资源了,于是要改进这个网络 I/O 模型,以支持更多的客户端。
在改进网络 I/O 模型前,先来提一个问题,服务器单机理论最大能连接多少个客户端?
TCP 连接是由四元组唯一确认的,这个四元组就是:本机IP, 本机端口, 对端IP, 对端端口。
服务器作为服务方,通常会在本地固定监听一个端口,等待客户端的连接。因此服务器的本地 IP 和端口是固定的,于是对于服务端 TCP 连接的四元组只有对端 IP 和端口是会变化的,所以最大 TCP 连接数 = 客户端 IP 数×客户端端口数。
对于 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数约为 2 的 48 次方。
这个理论值相当“丰满”,但是服务器肯定承载不了那么大的连接数,主要会受两个方面的限制:
- 文件描述符,Socket 实际上是一个文件,也就会对应一个文件描述符。在 Linux 下,单个进程打开的文件描述符数是有限制的,没有经过修改的值一般都是 1024,不过可以通过 ulimit 增大文件描述符的数目;
- 系统内存,每个 TCP 连接在内核中都有对应的数据结构,意味着每个连接都是会占用一定内存的;
那如果服务器的内存只有 2 GB,网卡是千兆的,能支持并发 1 万请求吗?
并发 1 万请求,也就是经典的 C10K 问题 ,C 是 Client 单词首字母缩写,C10K 就是单机同时处理 1 万个请求的问题。
从硬件资源角度看,对于 2GB 内存千兆网卡的服务器,如果每个请求处理占用不到 200KB 的内存和 100Kbit 的网络带宽就可以满足并发 1 万个请求。
不过,要想真正实现 C10K 的服务器,要考虑的地方在于服务器的网络 I/O 模型,效率低的模型,会加重系统开销,从而会离 C10K 的目标越来越远。
多进程模型
基于最原始的阻塞网络 I/O, 如果服务器要支持多个客户端,其中比较传统的方式,就是使用多进程模型,也就是为每个客户端分配一个进程来处理请求。
服务器的主进程负责监听客户的连接,一旦与客户端连接完成,accept() 函数就会返回一个「已连接 Socket」,这时就通过 fork() 函数创建一个子进程,实际上就把父进程所有相关的东西都复制一份,包括文件描述符、内存地址空间、程序计数器、执行的代码等。
这两个进程刚复制完的时候,几乎一摸一样。不过,会根据返回值来区分是父进程还是子进程,如果返回值是 0,则是子进程;如果返回值是其他的整数,就是父进程。
正因为子进程会复制父进程的文件描述符,于是就可以直接使用「已连接 Socket 」和客户端通信了,
可以发现,子进程不需要关心「监听 Socket」,只需要关心「已连接 Socket」;父进程则相反,将客户服务交给子进程来处理,因此父进程不需要关心「已连接 Socket」,只需要关心「监听 Socket」。
下面这张图描述了从连接请求到连接建立,父进程创建生子进程为客户服务。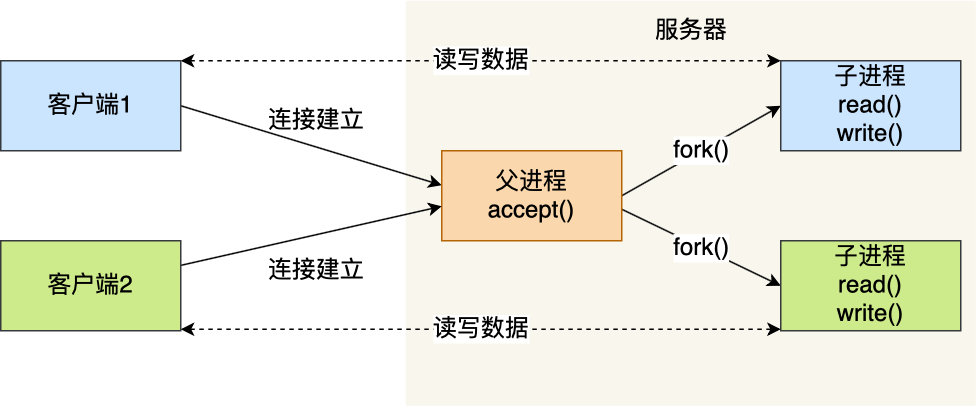
另外,当「子进程」退出时,实际上内核里还会保留该进程的一些信息,也是会占用内存的,如果不做好“回收”工作,就会变成僵尸进程,随着僵尸进程越多,会慢慢耗尽系统资源。
因此,父进程要“善后”好自己的孩子,怎么善后呢?那么有两种方式可以在子进程退出后回收资源,分别是调用 wait() 和 waitpid() 函数。
这种用多个进程来应付多个客户端的方式,在应对 100 个客户端还是可行的,但是当客户端数量高达一万时,肯定扛不住的,因为每产生一个进程,必会占据一定的系统资源,而且进程间上下文切换的“包袱”是很重的,性能会大打折扣。
进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
多线程模型
既然进程间上下文切换的“包袱”很重,那就搞个比较轻量级的模型来应对多用户的请求 —— 多线程模型。
线程是运行在进程中的一个“逻辑流”,单进程中可以运行多个线程,同进程里的线程可以共享进程的部分资源的,比如文件描述符列表、进程空间、代码、全局数据、堆、共享库等,这些共享些资源在上下文切换时是不需要切换,而只需要切换线程的私有数据、寄存器等不共享的数据,因此同一个进程下的线程上下文切换的开销要比进程小得多。
当服务器与客户端 TCP 完成连接后,通过 pthread_create() 函数创建线程,然后将「已连接 Socket」的文件描述符传递给线程函数,接着在线程里和客户端进行通信,从而达到并发处理的目的。
如果每来一个连接就创建一个线程,线程运行完后,还得操作系统还得销毁线程,虽说线程切换的上写文开销不大,但是如果频繁创建和销毁线程,系统开销也是不小的。
那么,可以使用线程池的方式来避免线程的频繁创建和销毁,所谓的线程池,就是提前创建若干个线程,这样当由新连接建立时,将这个已连接的 Socket 放入到一个队列里,然后线程池里的线程负责从队列中取出已连接 Socket 进程处理。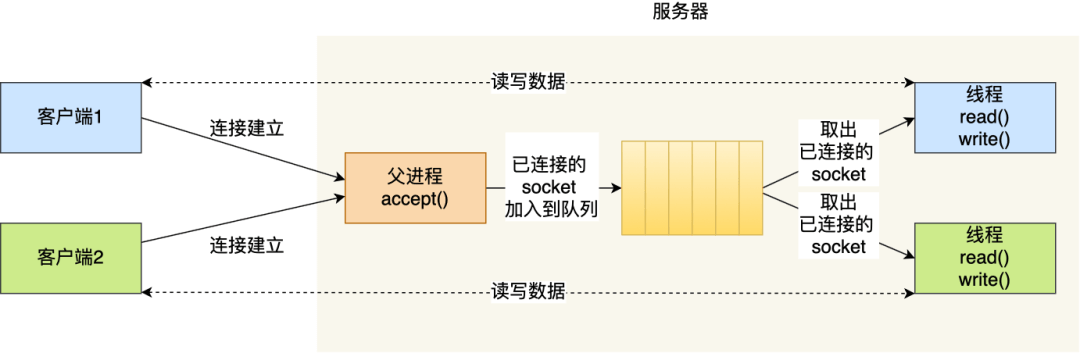
需要注意的是,这个队列是全局的,每个线程都会操作,为了避免多线程竞争,线程在操作这个队列前要加锁。
上面基于进程或者线程模型的,其实还是有问题的。新到来一个 TCP 连接,就需要分配一个进程或者线程,那么如果要达到 C10K,意味着要一台机器维护 1 万个连接,相当于要维护 1 万个进程/线程,操作系统就算死扛也是扛不住的。
I/O 多路复用
既然为每个请求分配一个进程/线程的方式不合适,那有没有可能只使用一个进程来维护多个 Socket 呢?答案是有的,那就是 I/O 多路复用技术。
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
熟悉的 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。
select/poll/epoll 这是三个多路复用接口,都能实现 C10K 吗?接下来,分别说说它们。
select/poll
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
epoll
epoll 通过两个方面,很好解决了 select/poll 的问题。
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删查一般时间复杂度是 O(logn),通过对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
从下图可以看到 epoll 相关的接口作用: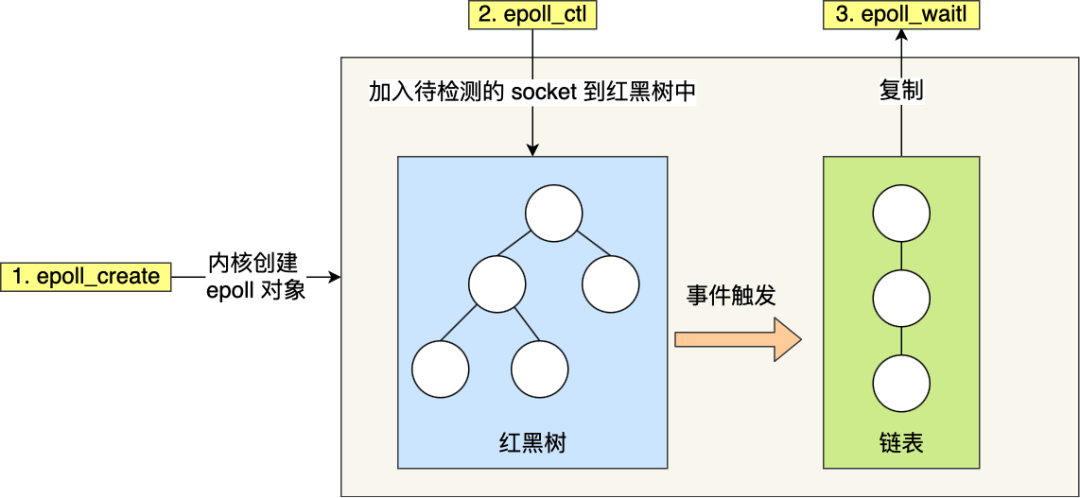
epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
插个题外话,网上文章不少说,epoll_wait 返回时,对于就绪的事件,epoll使用的是共享内存的方式,即用户态和内核态都指向了就绪链表,所以就避免了内存拷贝消耗。
这是错的!看过 epoll 内核源码的都知道,压根就没有使用共享内存这个玩意。可以从下面这份代码看到, epollwait 实现的内核代码中调用了 __put_user 函数,这个函数就是将数据从内核拷贝到用户空间。
epoll 支持两种事件触发模式,分别是**边缘触发(_edge-triggered,ET)和水平触发(level-triggered,LT)**。
这两个术语还挺抽象的,其实它们的区别还是很好理解的。
- 使用边缘触发模式时,当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用 read 函数从内核读取数据,也依然只苏醒一次,因此程序要保证一次性将内核缓冲区的数据读取完;
- 使用水平触发模式时,当被监控的 Socket 上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束,目的是告诉我们有数据需要读取;
举个例子,快递被放到了一个快递箱里,如果快递箱只会通过短信通知一次,即使一直没有去取,它也不会再发送第二条短信提醒,这个方式就是边缘触发;如果快递箱发现快递没有被取出,它就会不停地发短信通知,直到取出了快递,它才消停,这个就是水平触发的方式。
这就是两者的区别,水平触发的意思是只要满足事件的条件,比如内核中有数据需要读,就一直不断地把这个事件传递给用户;而边缘触发的意思是只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了。
如果使用水平触发模式,当内核通知文件描述符可读写时,接下来还可以继续去检测它的状态,看它是否依然可读或可写。所以在收到通知后,没必要一次执行尽可能多的读写操作。
如果使用边缘触发模式,I/O 事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,以免错失读写的机会。因此,会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。所以,边缘触发模式一般和非阻塞 I/O 搭配使用,程序会一直执行 I/O 操作,直到系统调用(如 read 和 write)返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK。
一般来说,边缘触发的效率比水平触发的效率要高,因为边缘触发可以减少 epoll_wait 的系统调用次数,系统调用也是有一定的开销的的,毕竟也存在上下文的切换。
select/poll 只有水平触发模式,epoll 默认的触发模式是水平触发,但是可以根据应用场景设置为边缘触发模式。
另外,使用 I/O 多路复用时,最好搭配非阻塞 I/O 一起使用,Linux 手册关于 select 的内容中有如下说明:
Under Linux, select() may report a socket file descriptor as “ready for reading”, while nevertheless a subsequent read blocks. This could for example happen when data has arrived but upon examination has wrong checksum and is discarded. There may be other circumstances in which a file descriptor is spuriously reported as ready. Thus it may be safer to use
O_NONBLOCKon sockets that should not block.
谷歌翻译的结果:
在Linux下,
select()可能会将一个 socket 文件描述符报告为 “准备读取”,而后续的读取块却没有。例如,当数据已经到达,但经检查后发现有错误的校验和而被丢弃时,就会发生这种情况。也有可能在其他情况下,文件描述符被错误地报告为就绪。因此,在不应该阻塞的 socket 上使用O_NONBLOCK可能更安全。
简单点理解,就是多路复用 API 返回的事件并不一定可读写的,如果使用阻塞 I/O, 那么在调用 read/write 时则会发生程序阻塞,因此最好搭配非阻塞 I/O,以便应对极少数的特殊情况。
总结
最基础的 TCP 的 Socket 编程,它是阻塞 I/O 模型,基本上只能一对一通信,那为了服务更多的客户端,需要改进网络 I/O 模型。
比较传统的方式是使用多进程/线程模型,每来一个客户端连接,就分配一个进程/线程,然后后续的读写都在对应的进程/线程,这种方式处理 100 个客户端没问题,但是当客户端增大到 10000 个时,10000 个进程/线程的调度、上下文切换以及它们占用的内存,都会成为瓶颈。
为了解决上面这个问题,就出现了 I/O 的多路复用,可以只在一个进程里处理多个文件的 I/O,Linux 下有三种提供 I/O 多路复用的 API,分别是:select、poll、epoll。
select 和 poll 并没有本质区别,它们内部都是使用「线性结构」来存储进程关注的 Socket 集合。
在使用的时候,首先需要把关注的 Socket 集合通过 select/poll 系统调用从用户态拷贝到内核态,然后由内核检测事件,当有网络事件产生时,内核需要遍历进程关注 Socket 集合,找到对应的 Socket,并设置其状态为可读/可写,然后把整个 Socket 集合从内核态拷贝到用户态,用户态还要继续遍历整个 Socket 集合找到可读/可写的 Socket,然后对其处理。
很明显发现,select 和 poll 的缺陷在于,当客户端越多,也就是 Socket 集合越大,Socket 集合的遍历和拷贝会带来很大的开销,因此也很难应对 C10K。
epoll 是解决 C10K 问题的利器,通过两个方面解决了 select/poll 的问题。
- epoll 在内核里使用「红黑树」来关注进程所有待检测的 Socket,红黑树是个高效的数据结构,增删查一般时间复杂度是 O(logn),通过对这棵黑红树的管理,不需要像 select/poll 在每次操作时都传入整个 Socket 集合,减少了内核和用户空间大量的数据拷贝和内存分配。
- epoll 使用事件驱动的机制,内核里维护了一个「链表」来记录就绪事件,只将有事件发生的 Socket 集合传递给应用程序,不需要像 select/poll 那样轮询扫描整个集合(包含有和无事件的 Socket ),大大提高了检测的效率。
而且,epoll 支持边缘触发和水平触发的方式,而 select/poll 只支持水平触发,一般而言,边缘触发的方式会比水平触发的效率高。

若有收获,就点个赞吧
0 人点赞
