一、初识Quartz
1. 概念
quartz 是一款开源且丰富特性的“任务调度库”,能够集成与任何的java 应用,下到独立应用,大到电子商业系统。quartz就是基于java实现的任务调度框架,用于执行你想要执行的任何任务。
什么是 任务调度 ?任务调度就是我们系统中创建了 N 个任务,每个任务都有指定的时间进行执行,而这种多任务的执行策略就是任务调度。
quartz 的作用就是让任务调度变得更加丰富,高效,安全,而且是基于 Java 实现的,这样子开发者只需要调用几个接口坐下简单的配置,即可实现上述需求。
2. 核心
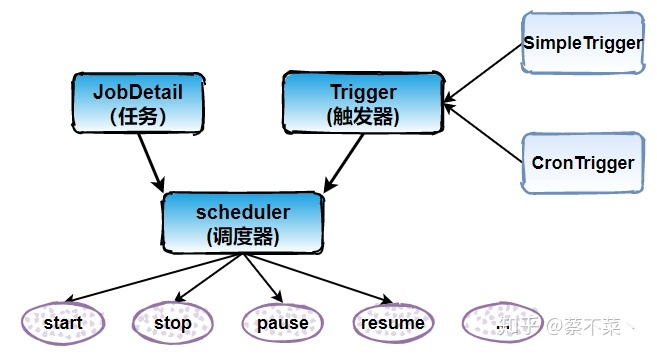
1)任务 Job
我们想要调度的任务都必须实现 org.quartz.job 接口,然后实现接口中定义的 execute( ) 方法即可
2)触发器 Trigger
Trigger 作为执行任务的调度器。我们如果想要凌晨1点执行备份数据的任务,那么 Trigger 就会设置凌晨1点执行该任务。其中 Trigger 又分为 SimpleTrigger 和 CronTrigger 两种
3)调度器 Scheduler
Scheduler 为任务的调度器,它会将任务 Job 及触发器 Trigger 整合起来,负责基于 Trigger 设定的时间来执行 Job
3. 体系结构
二、实战Quartz
上面我们大概介绍了 Quartz,那么该如何使用了,请往下看:
导入 Quartz 依赖
<!--quartz--><dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz</artifactId><version>2.3.2</version></dependency>
自定义任务
public class TestJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext) {String data = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));System.out.println("START DATA BACKUP, current time :" + data);}}
创建任务调度
public class TestScheduler {public static void main(String[] args) throws Exception {// 获取任务调度的实例Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();// 定义任务调度实例, 并与TestJob绑定JobDetail job = JobBuilder.newJob(TestJob.class).withIdentity("testJob", "testJobGroup").build();// 定义触发器, 会马上执行一次, 接着5秒执行一次Trigger trigger = TriggerBuilder.newTrigger().withIdentity("testTrigger", "testTriggerGroup").startNow().withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build();// 使用触发器调度任务的执行scheduler.scheduleJob(job, trigger);// 开启任务scheduler.start();}}/** OUTPUT:START DATA BACKUP, current time :2020-11-17 21:48:30START DATA BACKUP, current time :2020-11-17 21:48:35START DATA BACKUP, current time :2020-11-17 21:48:40START DATA BACKUP, current time :2020-11-17 21:48:45**/
通过以上示例,我们成功执行了一个任务,我们来回顾一下程序中出现的几个重要参数:
Job 和 JobDetail
JobExecutionContext
JobDataMap
Trigger
1. Job 和 JobDetail
1)Job
Job 是工作任务调度的接口,任务类需要实现该接口。该接口中定义了 execute 方法,我们需要在里面编写任务执行的业务逻辑,类似 JDK 提供的 TimeTask 类的 run方法。每次调度器执行 Job 时,在调用 execute 方法之前都会创建一个新的 Job 实例,当调用完成后,关联的 Job 对象示例会被释放,释放的实例会被垃圾回收机制回收
2)JobDetail
JobDetail 是为 Job 实例提供了许多设置属性,以及 JobDetailMap 成员变量属性,它用来存储特定 Job 实例的状态信息,调度器需要借助 JobDetail 对象来添加 Job 实例。
其中有几个重要属性:
JobDataMap jobDataMap = jobDetail.getJobDataMap();String name = jobDetail.getKey().getName();String group = jobDetail.getKey().getGroup();String jobName = jobDetail.getJobClass().getName();
两者之间的关系:
JobDetail 定义的是任务数据,而真正的执行逻辑是是在 Job 中。这是因为任务是有可能并发执行,如果 Scheduler 直接使用 Job ,就会存在对同一个 Job 实例并发访问的问题。而 采用JobDetail & Job 方式, Scheduler 每次执行,都会根据 JobDetail 创建一个新的 Job 实例,这样就可以规避并发访文的问题
2. JobExecutionContext
当 Scheduler 调用一个 Job ,就会将 JobExecutionContext 传递给 Job 的 execute() 方法。这样子在Job 中就能通过 JobExecutionContext 对象来访问到 Quartz 运行时候的环境以及 Job 本身的明细数据。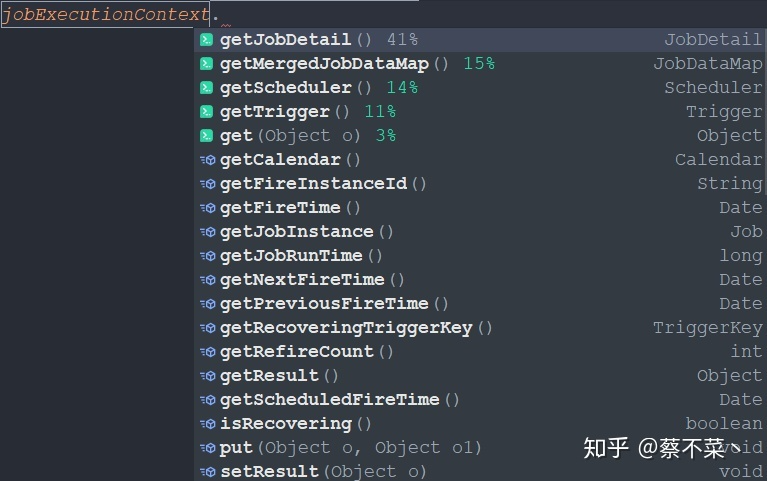
3. JobDataMap
顾名思义 JobDataMap 是一个 Map ,它实现了 JDK中的 Map 接口,可以用来存取基本数据类型,也可以用来转载任何可序列化的数据对象,当 Job 实例对象被执行时这些参数对象会传递给它。示例如下:
任务调度类:
JobDetail jobDetail = JobBuilder.newJob(TestJob.class).usingJobData("testJobDetail", "jobDetail数据存放").withIdentity("testJob", "testJobGroup").build();Trigger trigger = TriggerBuilder.newTrigger().usingJobData("testTrigger", "trigger数据存放").withIdentity("testTrigger", "testTriggerGroup").startNow().withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build();
Job 任务类:
public class TestJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext) {System.out.println(jobExecutionContext.getJobDetail().getJobDataMap().get("testJobDetail"));System.out.println(jobExecutionContext.getTrigger().getJobDataMap().get("testTrigger"));}}/** OUTPUT:jobDetail数据存放trigger数据存放**/
以上我们是通过 getJobDataMap( ) 方法来获取 JobDataMap 中的值,我们还可以使用另外一种方式来获取:
Job 任务类:
public class TestJob implements Job {private String testJobDetail;public void setTestJobDetail(String testJobDetail) {this.testJobDetail = testJobDetail;}@Overridepublic void execute(JobExecutionContext jobExecutionContext) {System.out.println(testJobDetail);}}/** OUTPUT:jobDetail数据存放**/
以上方式便是:只要我们在Job实现类中添加对应key的setter方法,那么Quartz框架默认的JobFactory实现类在初始化 Job 实例对象时回自动地调用这些 setter 方法
注: 如果遇到同名的 key,比如我们在JobDetail 中存放值的 key 与在 Trigger 中存放值的 key 相同,那么最终 Trigger 的值会覆盖掉 JobDetail 中的值,示例如下:任务调度类:两者中都存放了 key 为 testInfo 的值
JobDetail jobDetail = JobBuilder.newJob(TestJob.class).usingJobData("testInfo", "jobDetail数据存放").withIdentity("testJob", "testJobGroup").build();Trigger trigger = TriggerBuilder.newTrigger().usingJobData("testInfo", "trigger数据存放").withIdentity("testTrigger", "testTriggerGroup").startNow().withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build();
Job 任务类:会输出 Trigger 中存放的值
public class TestJob implements Job {private String testInfo;public void setTestInfo(String testInfo) {this.testInfo = testInfo;}@Overridepublic void execute(JobExecutionContext jobExecutionContext) {System.out.println(testInfo);}}/** OUTPUT:trigger数据存放**/
4. Job 的状态
如果我们有个需求是统计每个任务的执行次数,那么你会怎么做?

也许你会想到使用上面说到的 JobDataMap,那就让我们尝试下:任务调度类
// 我们在 JobDataMap 中定义了一个值为 0 的初始值JobDetail jobDetail = JobBuilder.newJob(TestJob.class).usingJobData("executeCount", 0).withIdentity("testJob", "testJobGroup").build();
Job 任务类 ```java @Slf4j public class TestJob implements Job {
private Integer executeCount;
public void setExecuteCount(Integer executeCount) {
this.executeCount = executeCount;
}
@Override public void execute(JobExecutionContext jobExecutionContext) {
String data = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));log.info("execute count: {}, current time: {}",++executeCount, data);//将累加的 count 存入JobDataMap中jobExecutionContext.getJobDetail().getJobDataMap().put("executeCount", executeCount);
} } / OUTPUT: execute count: 1, current time: 2020-11-17 22:38:48 execute count: 1, current time: 2020-11-17 22:38:52 execute count: 1, current time: 2020-11-17 22:38:57 /
按照上面的想法我们写出了这部分代码,但貌似打脸了,结果并没有按照我们预计的发展,是逻辑不对吗,貌似写的也没什么问题。这时你会不会回忆到上面我讲过的一句话:**"在调用 execute 方法之前都会创建一个新的 Job 实例"**,这就牵引出了 **Job** 状态的概念:- 无状态的 **Job**每次调用时都会创建一个新的 **JobDataMap**- 有状态的 **Job**多次 **Job** 调用可以持有一些状态信息,这些状态信息存储在 **JobDataMap** 中<br />那么问题来了,如果让 **Job** 变成有状态?这个时候我们可以借助一个注解:@PersistJobDataAfterExecution ,加上这个注解后,我们再来试下:<br />**Job 任务类:**```java@Slf4j@PersistJobDataAfterExecutionpublic class TestJob implements Job {private Integer executeCount;public void setExecuteCount(Integer executeCount) {this.executeCount = executeCount;}@Overridepublic void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {String data = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));log.info("execute count: {}, current time: {}",++executeCount, data);//将累加的 count 存入JobDataMap中jobExecutionContext.getJobDetail().getJobDataMap().put("executeCount", executeCount);}}/** OUTPUT:execute count: 1, current time: 2020-11-17 22:28:48execute count: 2, current time: 2020-11-17 22:28:52execute count: 3, current time: 2020-11-17 22:28:57**/
可以看到加了 @PersistJobDataAfterExecution ,我们已经成功达到了我们的目的。
5. Trigger
经过以上示例,我们已经大概知道了 Quartz 的组成,我们定义了任务之后,需要用触发器 Trigger 去指定 Job 的执行时间,执行间隔,运行次数等,那么 Job 与 Trigger 的结合,我们中间还需要 Scheduler 去调度,三者关系大致如下: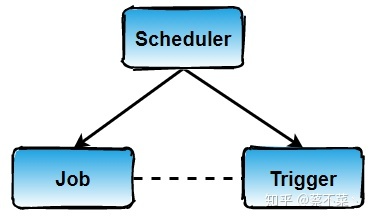
其中 Trigger 又有几种实现类如下: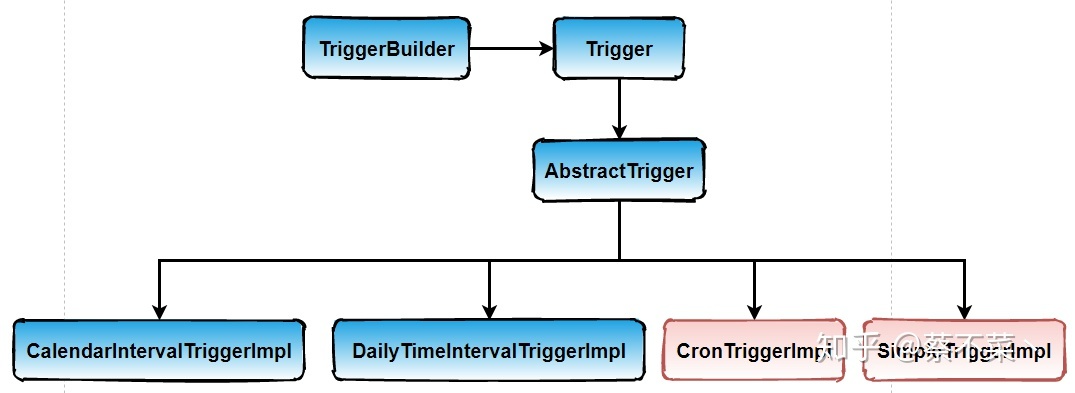
大致有四个实现类,但是我们平时用的最多的还是 CronTriggerImpl 和 SimpleTriggerImpl
我们如果想要定义任务何时执行,何时结束,我们可以这样做:
任务调度类
Date startTime = new Date();startTime.setTime(startTime.getTime() + 5000);Date endTime = new Date();endTime.setTime(startTime.getTime() + 10000);Trigger trigger = TriggerBuilder.newTrigger().usingJobData("testInfo", "trigger数据存放").withIdentity("testTrigger", "testTriggerGroup").startNow().startAt(startTime).endAt(endTime).withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build();
Job 任务类
@Slf4j@PersistJobDataAfterExecutionpublic class TestJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {Trigger trigger = jobExecutionContext.getTrigger();log.info("start time : {}, end time: {}",trigger.getStartTime(), trigger.getEndTime());}}/** OUTPUT:start time : Thu Nov 17 22:42:51 CST 2020, end time: Thu Nov 17 22:43:01 CST 2020start time : Thu Nov 17 22:42:51 CST 2020, end time: Thu Nov 17 22:43:01 CST 2020**/
通过控制台可以看到,任务执行了两次便已经停止了,因为已经超过了停止时间 Thu Nov 17 22:43:01 CST 2020
1)SimpleTrigger
我们上面看到示例,用到的都是 SimpleTrigger ,SimpleTrigger 对于设置和使用是最为简单的一种 QuartzTrigger,它是为那种需要在特定的日期/时间启动,且以一个可能的间隔时间重复执行 n 次的 Job任务 所设计的。
比如我想要在一个指定的时间段内执行一次任务,我们只需要这样写:Trigger trigger = TriggerBuilder.newTrigger().withIdentity("testTrigger", "testTriggerGroup").startAt(startTime) //自定义执行时间.build();
再者我想在指定的时间间隔内多次执行该任务,我们可以这样写:
Trigger trigger = TriggerBuilder.newTrigger().withIdentity("testTrigger", "testTriggerGroup").withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).withRepeatCount(2)) // 每5秒执行一次,连续执行3次后停止,从 0 开始计数.build();
我们来总结一下上面的示例:
SimpleTrigger具备的属性有:开始时间、结束时间、重复次数和重复的时间间隔
重复次数 的值可以为 0、正整数、或常量 SimpleTrigger.REPEAT_INDEFINITELY
重复的时间间隔属性值必须大于 0 或长整型的正整数,以 毫秒 作为时间单位,当重复的时间间隔为 0 时,意味着与 Trigger 同时触发执行
结束时间和重复次数同时存在时,以结束时间优先
2)CronTrigger
跟 SimpleTrigger 执行间隔时间触发的相比,CronTrigger 更加灵活,它是基于日历的作业调度器。使用 CronTrigger 我们可以执行某个时间点执行,例如 “每天的凌晨1点执行”、“每个工作日的 12 点执行”,也可以像 SimpleTrigger 那样执行一个开始时间和结束时间运行任务
学习 CronTrigger 之前我们得先学习 Cron 表达式
- Cron表达式
Cron表达式 是用来配置 CronTrigger 实例,它是一个由 7 个子表达式组成的字符串,每个字符都表示不同的日程细节:
Seconds:秒
Minutes:分钟
Hours:小时
Day-of-Month:月中的哪几天
Month:月
Day-of-Week:周中的哪几天
Year:年
| 字段 | 是否必填 | 允许值 | 可用特殊字符 |
|---|---|---|---|
| 秒 | 是 | 0-59 | , - * / |
| 分 | 是 | 0-59 | , - * / |
| 小时 | 是 | 0-23 | , - * / |
| 月中的哪几天 | 是 | 1-31 | , - * / ? L W C |
| 月 | 是 | 1-12 或 JAN-DEC | , - * / |
| 周中的哪几天 | 是 | 1-7 或 SUN-SAT | , - * / ? L C # |
| 年 | 否 | 不填写 或 1970-2099 | , - * / |
- 特殊符号 | 特殊符号 | 含义 | | —- | —- | | | 可用在所有字段中,表示对应时间域的每一个时刻,例如,** 在分钟字段时,表示“每分钟” | | ? | 该字符只在日期和星期字段中使用,它通常指定为“无意义的值”,相当于点位符 | | - | 表达一个范围,如在小时字段中使用“10-12”,则表示从10到12点,即10,11,12 | | , | 表达一个列表值,如在星期字段中使用“MON,WED,FRI”,则表示星期一,星期三和星期五 | | / | x/y表达一个等步长序列,x为起始值,y为增量步长值。如在分钟字段中使用0/15,则表示为0,15,30和45秒,而5/15在分钟字段中表示5,20,35,50,你也可以使用*/y,它等同于0/y | | L | 该字符只在日期和星期字段中使用,代表“Last”的意思,但它在两个字段中意思不同。L在日期字段中,表示这个月份的最后一天,如一月的31号,非闰年二月的28号;如果L用在星期中,则表示星期六,等同于7。但是,如果L出现在星期字段里,而且在前面有一个数值 X,则表示“这个月的最后X天”,例如,6L表示该月的最后星期五 | | W | 该字符只能出现在日期字段里,是对前导日期的修饰,表示离该日期最近的工作日。例如15W表示离该月15号最近的工作日,如果该月15号是星期六,则匹配14号星期五;如果15日是星期日,则匹配16号星期一;如果15号是星期二,那结果就是15号星期二。但必须注意关联的匹配日期不能够跨月,如你指定1W,如果1号是星期六,结果匹配的是3号星期一,而非上个月最后的那天。W字符串只能指定单一日期,而不能指定日期范围 | | # | 该字符只能在星期字段中使用,表示当月某个工作日。如6#3表示当月的第三个星期五(6表示星期五,#3表示当前的第三个),而4#5表示当月的第五个星期三,假设当月没有第五个星期三,忽略不触发 |
Cron表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感。
实战演习
"0 0 10,14,16 * * ?" 每天上午10点,下午2点,4点"0 0/30 9-17 * * ?" 朝九晚五工作时间内每半小时,从0分开始每隔30分钟发送一次"0 0 12 ? * WED" 表示每个星期三中午12点"0 0 12 * * ?" 每天中午12点触发"0 15 10 ? * *" 每天上午10:15触发"0 15 10 * * ?" 每天上午10:15触发"0 15 10 * * ? *" 每天上午10:15触发"0 15 10 * * ? 2005" 2005年的每天上午10:15触发"0 * 14 * * ?" 在每天下午2点到下午2:59期间的每1分钟触发"0 0/55 14 * * ?" 在每天下午2点到下午2:55期间,从0开始到55分钟触发"0 0-5 14 * * ?" 在每天下午2点到下午2:05期间的每1分钟触发"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44触发"0 15 10 ? * MON-FRI" 周一至周五的上午10:15触发"0 15 10 15 * ?" 每月15日上午10:15触发"0 15 10 L * ?" 每月最后一日的上午10:15触发"0 15 10 ? * 6L" 每月的最后一个星期五上午10:15触发"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一个星期五上午10:15触发"0 15 10 ? * 6#3" 每月的第三个星期五上午10:15触发
使用示例
Trigger trigger = TriggerBuilder.newTrigger().withIdentity("testTrigger", "testTriggerGroup").withSchedule(CronScheduleBuilder.cronSchedule("0/5 * * 6 4 ?")).build();
6. Scheduler
Quartz 是以模块的方式构建的,Job 和 Trigger 之间的结合需要靠 Scheduler。
创建
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
创建是通过 Quartz 默认的 SchedulerFactory,我们可以使用自定义参数(Properties)来创建和初始化 Quartz 调度器,配置参数一般存储在 quartz.properties 中。
我们上面是通过 scheduleJob() 方法来结合 Job和 Trigger,这个方法有个时间类型的返回值,我们可以获取到调度器开始的时间:Date date = scheduler.scheduleJob(jobDetail, trigger);
关联完任务和触发器,我们就可以启动任务调度了:
scheduler.start();
将任务调度挂起(暂停):
scheduler.standby();
将任务关闭:
shutdown(true);//表示等待所有正在执行的job执行完毕之后,再关闭Scheduler shutdown(false);//表示直接关闭Scheduler
我们再来了解下 quartz.properties 文件,先看一个示例: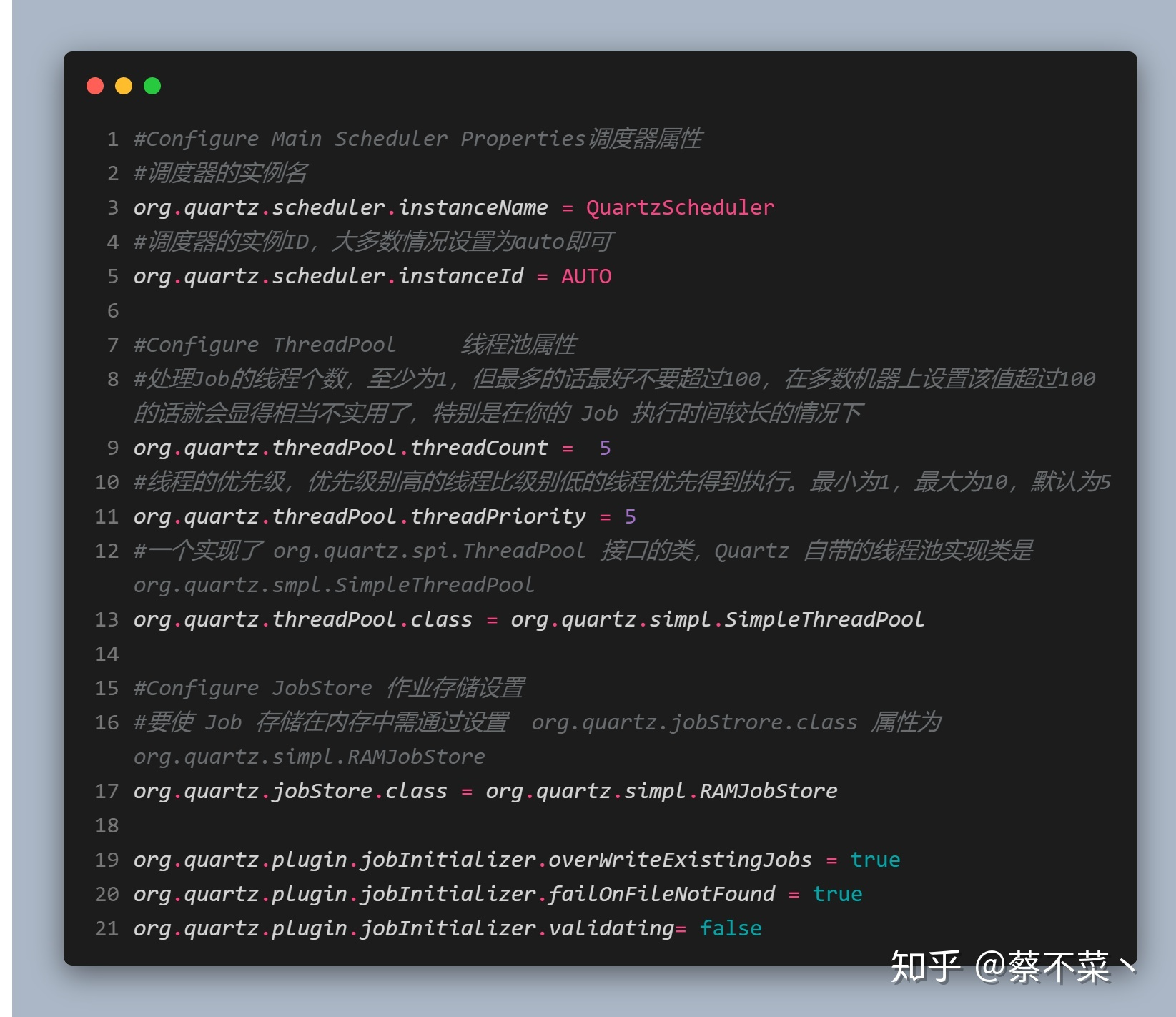
也可以编写程序代码操作quartz.properties文件的内容:public class QuartzProperties {public static void main(String[] args) {// 创建工厂实例StdSchedulerFactory factory = new StdSchedulerFactory();// 创建配置工厂的属性对象Properties props = new Properties();props.put(StdSchedulerFactory.PROP_THREAD_POOL_CLASS, "org.quartz.simpl.SimpleThreadPool"); // 线程池定义props.put("org.quartz.threadPool.threadCount", "5"); // 默认Scheduler的线程数try {// 使用定义的属性初始化工厂factory.initialize(props);Scheduler scheduler = factory.getScheduler();scheduler.start();} catch (SchedulerException e) {e.printStackTrace();}}}
通过Properties设置工厂属性的缺点在用硬编码,假如需要修改例子中线程数量,将不得不修改代码,然后重新编译,所以不推荐使用。
三、Quartz 监听器
在 Quartz 实战中我们了解到三个核心模块分别是 Job、Trigger、Scheduler,既然 Quartz中存在监听器,相应的,这三者也分别有对应的监听器。监听器的作用便是用于当任务调度中你所关注事件发生时,能够及时获取这一事件的通知
1. JobListener
任务调度中,与任务 Job 相关的事件包括: Job 开始要执行的提示,执行完成的提示,接口如下:
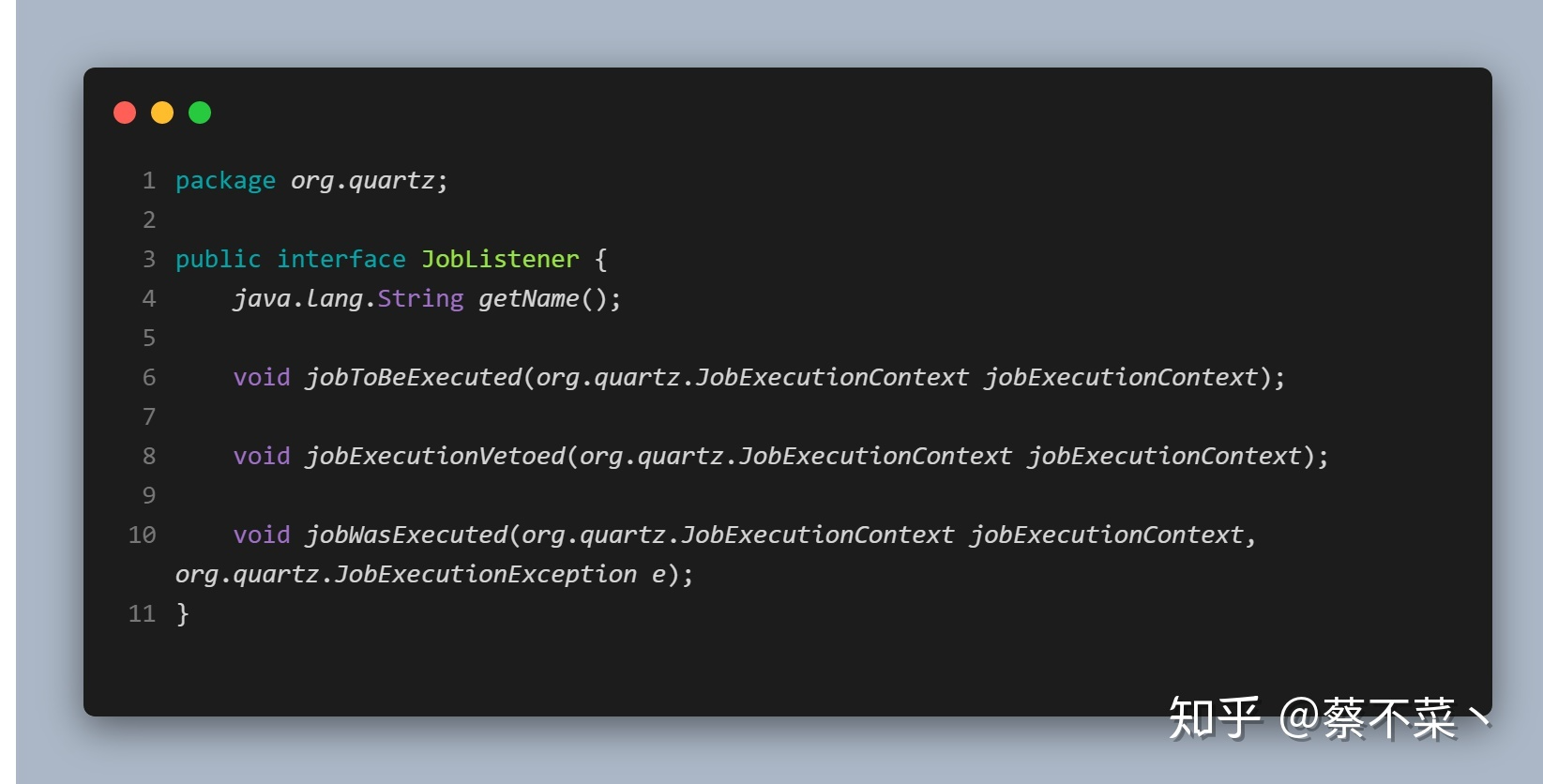
1)方法解析
getName():用于获取改JobListener 的名称
- jobToBeExecuted():Scheduler 在 JobDetail 将要被执行时调用这个方法
`jobExecutionVetoed():Scheduler 在 JobDetail 即将被执行,但又被 TriggerListener 否决时会调用该方法jobWasExecuted():Scheduler 在 JobDetail 被执行之后调用这个方法
2)示例
Job 任务类:
@Slf4j@PersistJobDataAfterExecutionpublic class TestJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext){System.out.println("TestJob 执行啦");}}
JobListener :
public class MyJobListener implements JobListener {@Overridepublic String getName() {String name = getClass().getSimpleName();System.out.println("监听器的名称是:" + name);return name;}@Overridepublic void jobToBeExecuted(JobExecutionContext context) {String jobName = context.getJobDetail().getKey().getName();System.out.println("Job的名称是:" + jobName + "\tScheduler在JobDetail将要被执行时调用这个方法");}@Overridepublic void jobExecutionVetoed(JobExecutionContext context) {String jobName = context.getJobDetail().getKey().getName();System.out.println("Job的名称是:" + jobName + "\tScheduler在JobDetail即将被执行,但又被TriggerListerner否决时会调用该方法");}@Overridepublic void jobWasExecuted(JobExecutionContext context, JobExecutionException jobException) {String jobName = context.getJobDetail().getKey().getName();System.out.println("Job的名称是:" + jobName + "\tScheduler在JobDetail被执行之后调用这个方法");}}
任务调度类:
@Slf4jpublic class TestScheduler {public static void main(String[] args) throws Exception {// 获取任务调度的实例Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();// 定义任务调度实例, 并与TestJob绑定JobDetail jobDetail = JobBuilder.newJob(TestJob.class).usingJobData("executeCount", 0).withIdentity("testJob", "testJobGroup").build();// 定义触发器, 会马上执行一次, 接着5秒执行一次Trigger trigger = TriggerBuilder.newTrigger().usingJobData("testInfo", "trigger数据存放").withIdentity("testTrigger", "testTriggerGroup").startNow().withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build();// 创建并注册一个全局的Job Listenerscheduler.getListenerManager().addJobListener(new MyJobListener(),EverythingMatcher.allJobs());// 使用触发器调度任务的执行scheduler.scheduleJob(jobDetail, trigger);// 开启任务scheduler.start();}}/** OUTPUT:监听器的名称是:MyJobListenerJob的名称是:testJob Scheduler在JobDetail将要被执行时调用这个方法TestJob 执行啦监听器的名称是:MyJobListenerJob的名称是:testJob Scheduler在JobDetail被执行之后调用这个方法**/
2. TriggerListener
任务调度中,与触发器 Trigger 相关的事件包括: 触发器触发、触发器未正常触发、触发器完成等:
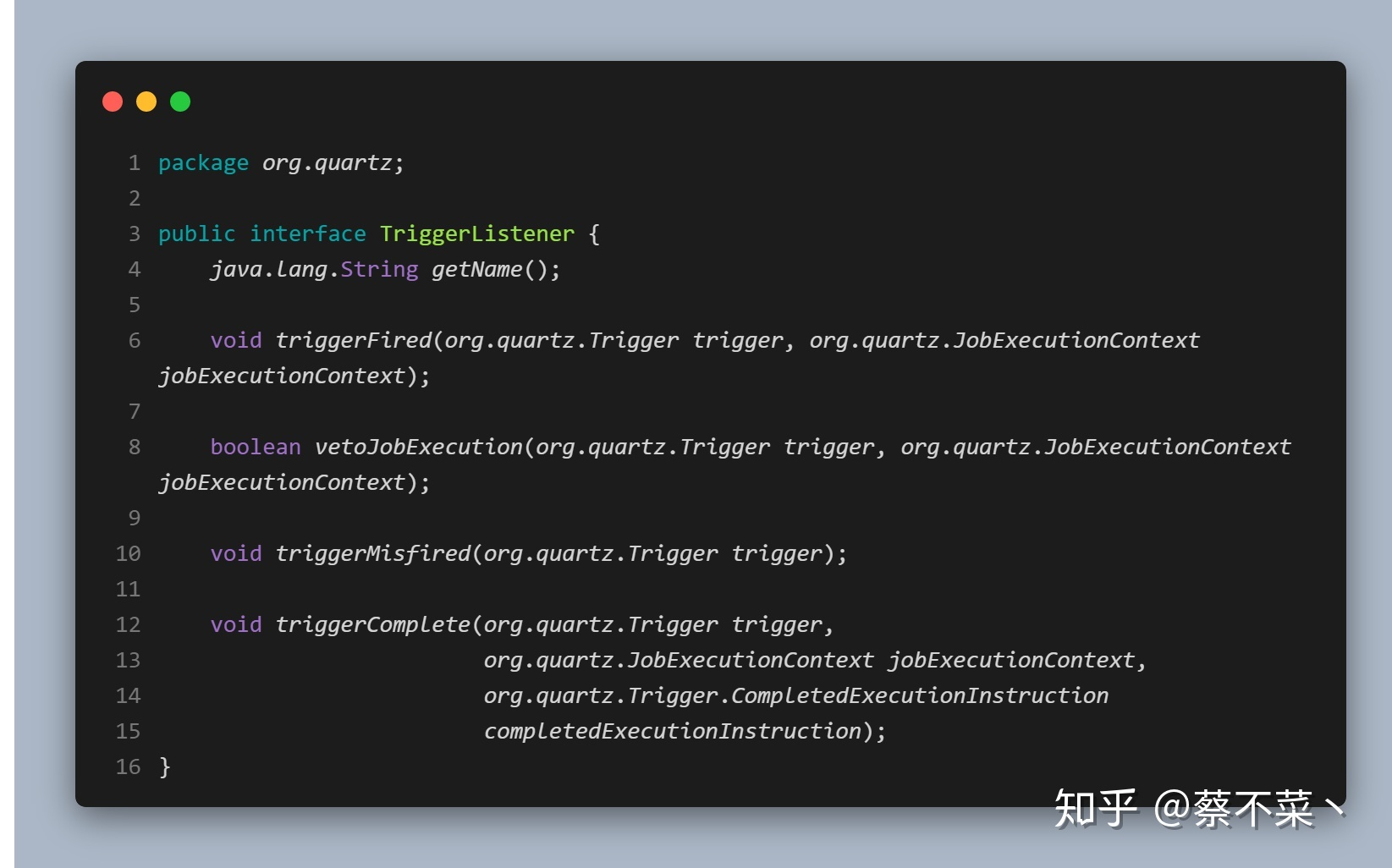
1)方法解析
getName():用于获取触发器的名称
triggerFired():当与监听器相关联的Trigger被触发,Job上的execute()方法将被执行时,Scheduler就调用该方法
vetoJobExecution():在 Trigger 触发后,Job 将要被执行时由 Scheduler 调用这个方法。TriggerListener 给了一个选择去否决 Job 的执行。假如这个方法返回 true,这个 Job 将不会为此次 Trigger 触发而得到执行
triggerMisfired():Scheduler 调用这个方法是在 Trigger 错过触发时。你应该关注此方法中持续时间长的逻辑:在出现许多错过触发的 Trigger 时,长逻辑会导致骨牌效应,所以应当保持这方法尽量的小
triggerComplete():Trigger 被触发并且完成了 Job 的执行时,Scheduler 调用这个方法。
2)示例
Job 任务类:
@Slf4j@PersistJobDataAfterExecutionpublic class TestJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext){System.out.println("TestJob 执行啦");}}
TriggerListener: ```java public class MyTriggerListener implements TriggerListener { private String name;
public MyTriggerListener(String name) {
this.name = name;
}
@Override public String getName() {
return name;
}
@Override public void triggerFired(Trigger trigger, JobExecutionContext context) {
String triggerName = trigger.getKey().getName();System.out.println(triggerName + " 被触发");
}
@Override public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context) {
String triggerName = trigger.getKey().getName();System.out.println(triggerName + " 没有被触发");return false; // true:表示不会执行Job的方法
}
@Override public void triggerMisfired(Trigger trigger) {
String triggerName = trigger.getKey().getName();System.out.println(triggerName + " 错过触发");
}
@Override public void triggerComplete(Trigger trigger, JobExecutionContext jobExecutionContext, Trigger.CompletedExecutionInstruction completedExecutionInstruction) {
String triggerName = trigger.getKey().getName();System.out.println(triggerName + " 完成之后触发");
}
}
- **任务调度类:**```java@Slf4jpublic class TestScheduler {public static void main(String[] args) throws Exception {// 获取任务调度的实例Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();// 定义任务调度实例, 并与TestJob绑定JobDetail jobDetail = JobBuilder.newJob(TestJob.class).usingJobData("executeCount", 0).withIdentity("testJob", "testJobGroup").build();// 定义触发器, 会马上执行一次, 接着5秒执行一次Trigger trigger = TriggerBuilder.newTrigger().usingJobData("testInfo", "trigger数据存放").withIdentity("testTrigger", "testTriggerGroup").startNow().withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build();// 创建并注册一个全局的Trigger Listenerscheduler.getListenerManager().addTriggerListener(new MyTriggerListener("simpleTrigger"), EverythingMatcher.allTriggers());// 使用触发器调度任务的执行scheduler.scheduleJob(jobDetail, trigger);// 开启任务scheduler.start();}}/** OUTPUT:testTrigger 被触发testTrigger 没有被触发TestJob 执行啦testTrigger 完成之后触发**/
3. SchedulerListener
SchedulerListener会在Scheduler的生命周期中关键事件发生时被调用。与Scheduler有关的事件包括:增加一个job/trigger,删除一个job/trigger,scheduler发生严重错误,关闭scheduler等。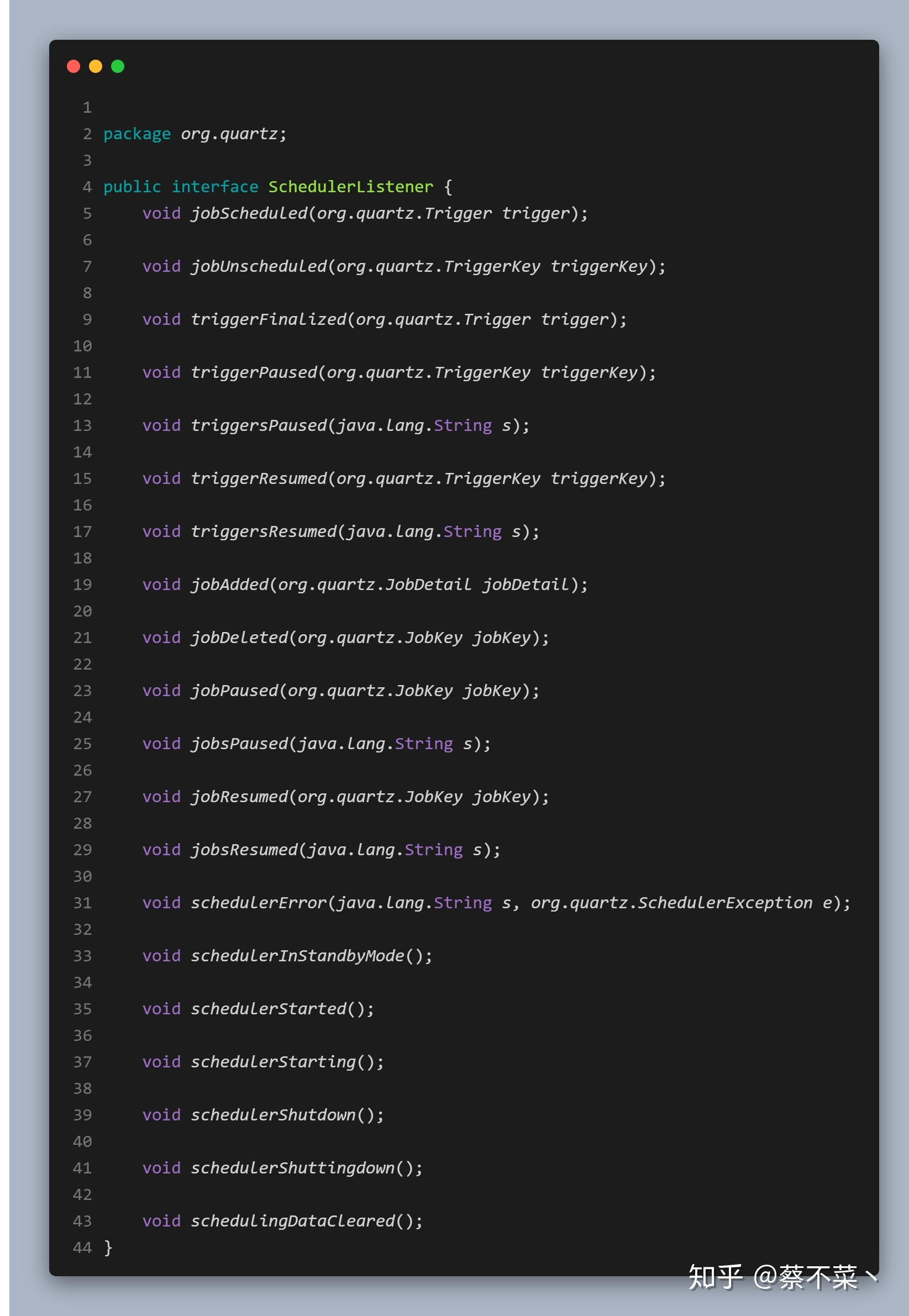
1)方法解析
- jobScheduled():用于部署JobDetail时调用
- jobUnscheduled():用于卸载JobDetail时调用
- triggerFinalized():当一个 Trigger 来到了再也不会触发的状态时调用这个方法。除非这个 Job 已设置成了持久性,否则它就会从 Scheduler 中移除。
- triggersPaused():Scheduler 调用这个方法是发生在一个 Trigger 或 Trigger 组被暂停时。假如是 Trigger 组的话,triggerName 参数将为 null。
- triggersResumed():Scheduler 调用这个方法是发生成一个 Trigger 或 Trigger 组从暂停中恢复时。假如是 Trigger 组的话,假如是 Trigger 组的话,triggerName 参数将为 null。参数将为 null。
- jobsPaused():当一个或一组 JobDetail 暂停时调用这个方法。
- jobsResumed():当一个或一组 Job 从暂停上恢复时调用这个方法。假如是一个 Job 组,jobName 参数将为 null。
- schedulerError():在 Scheduler 的正常运行期间产生一个严重错误时调用这个方法。
- schedulerStarted():当Scheduler 开启时,调用该方法
- schedulerInStandbyMode(): 当Scheduler处于StandBy模式时,调用该方法
- schedulerShutdown()):当Scheduler停止时,调用该方法
schedulingDataCleared():当Scheduler中的数据被清除时,调用该方法。
2)示例
Job 任务类:
@Slf4j@PersistJobDataAfterExecutionpublic class TestJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext){System.out.println("TestJob 执行啦");}}
SchedulerListener:
public class MySchedulerListener implements SchedulerListener {@Overridepublic void jobScheduled(Trigger trigger) {String jobName = trigger.getJobKey().getName();System.out.println(jobName + " 完成部署");}@Overridepublic void jobUnscheduled(TriggerKey triggerKey) {System.out.println(triggerKey + " 完成卸载");}@Overridepublic void triggerFinalized(Trigger trigger) {System.out.println("触发器被移除 " + trigger.getJobKey().getName());}@Overridepublic void triggerPaused(TriggerKey triggerKey) {System.out.println(triggerKey + " 正在被暂停");}@Overridepublic void triggersPaused(String triggerGroup) {System.out.println("触发器组 " + triggerGroup + " 正在被暂停");}@Overridepublic void triggerResumed(TriggerKey triggerKey) {System.out.println(triggerKey + " 正在从暂停中恢复");}@Overridepublic void triggersResumed(String triggerGroup) {System.out.println("触发器组 " + triggerGroup + " 正在从暂停中恢复");}@Overridepublic void jobAdded(JobDetail jobDetail) {System.out.println(jobDetail.getKey() + " 添加工作任务");}@Overridepublic void jobDeleted(JobKey jobKey) {System.out.println(jobKey + " 删除工作任务");}@Overridepublic void jobPaused(JobKey jobKey) {System.out.println(jobKey + " 工作任务正在被暂停");}@Overridepublic void jobsPaused(String jobGroup) {System.out.println("工作任务组 " + jobGroup + " 正在被暂停");}@Overridepublic void jobResumed(JobKey jobKey) {System.out.println(jobKey + " 正在从暂停中恢复");}@Overridepublic void jobsResumed(String jobGroup) {System.out.println("工作任务组 " + jobGroup + " 正在从暂停中恢复");}@Overridepublic void schedulerError(String msg, SchedulerException cause) {System.out.println("产生严重错误时调用: " + msg + " " + cause.getUnderlyingException());}@Overridepublic void schedulerInStandbyMode() {System.out.println("调度器在挂起模式下调用");}@Overridepublic void schedulerStarted() {System.out.println("调度器 开启时调用");}@Overridepublic void schedulerStarting() {System.out.println("调度器 正在开启时调用");}@Overridepublic void schedulerShutdown() {System.out.println("调度器 已经被关闭 时调用");}@Overridepublic void schedulerShuttingdown() {System.out.println("调度器 正在被关闭 时调用");}@Overridepublic void schedulingDataCleared() {System.out.println("调度器的数据被清除时调用");}}
任务调度类: ```java @Slf4j public class TestScheduler { public static void main(String[] args) throws Exception {
// 获取任务调度的实例Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();// 定义任务调度实例, 并与TestJob绑定JobDetail jobDetail = JobBuilder.newJob(TestJob.class).usingJobData("executeCount", 0).withIdentity("testJob", "testJobGroup").build();// 定义触发器, 会马上执行一次, 接着5秒执行一次Date endTime = new Date();endTime.setTime(endTime.getTime()+5000);Trigger trigger = TriggerBuilder.newTrigger().usingJobData("testInfo", "trigger数据存放").withIdentity("testTrigger", "testTriggerGroup").startNow().endAt(endTime) //设置了停止时间.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build();// 创建SchedulerListenerscheduler.getListenerManager().addSchedulerListener(new MySchedulerListener());// 使用触发器调度任务的执行scheduler.scheduleJob(jobDetail, trigger);// 开启任务scheduler.start();
} } / OUTPUT: testJobGroup.testJob 添加工作任务 testJob 完成部署 调度器 正在开启时调用 调度器 开启时调用 TestJob 执行啦 触发器被移除 testJob testJobGroup.testJob 删除工作任务 /
``` 通过以上三个监听器的示例,我们也可以大概了解到监听器执行的时机,具体的我们可以实际上手操练一番

若有收获,就点个赞吧
0 人点赞
