水平分库分表
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。阿粉之前趁着活动入手了2个最低配置的服务器,一个是阿里云的,一个是百度云的,只是做开发用的,虽然每次执行点东西都能让内存爆满,但是自己做开发测试啥的,也是没啥问题的,有兴趣的可以安排一下。在上面装好我们的数据库之后,我们就可以开始进行操作了。
第一步
创建数据库,我们分别在不同的两个数据库中创建相同表结构的两个表数据。
database1中,我们创建一个orderinfo的表
DROP TABLE IF EXISTS orderinfo;CREATE TABLE orderinfo (order_id BIGINT(20) PRIMARY KEY AUTO_INCREMENT ,user_id INT(11) ,product_name VARCHAR(128),COUNT INT(11));
database2中,我们创建同样的库,创建完成校验一下。
两个表的结构是一样的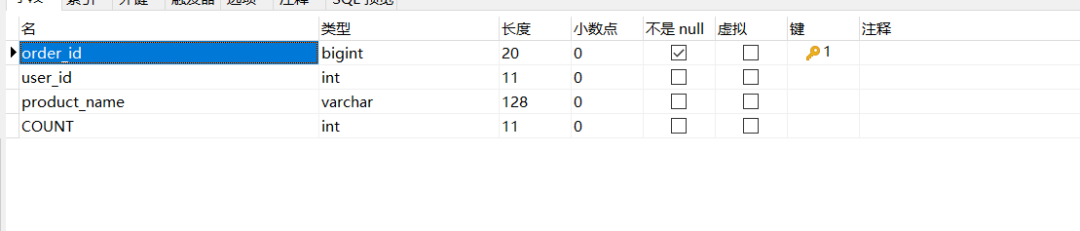
接下来就去创建我们的SpringBoot项目,这个阿粉不说了,上一篇文章已经说过了,也是需要加入相同的依赖包。
第二步
更改配置:
spring:application:name: sharding-jdbc-simplehttp:encoding:enabled: truecharset: UTF-8force: truemain:allow-bean-definition-overriding: true#定义数据源shardingsphere:datasource:names: db1,db2db1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/order?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456db2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/ordersharding?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456## 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据源,否则操作db2。sharding:tables:orderinfo:actual-data-nodes: db$->{1..2}.orderinfokey-generator:column: order_idtype: SNOWFLAKEdatabase-strategy:inline:sharding-column: user_idalgorithm-expression: db$->{user_id % 2 + 1}props:sql:show: trueserver:servlet:context-path: /sharding-jdbcmybatis:configuration:map-underscore-to-camel-case: true
我们的配置文件,在这里是通过配置对数据库的分片策略,来指定数据库进行操作。
分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据 源,否则操作db2。
这样的分库策略,直接通过 user_id 的奇偶性,来判断到底是用哪个数据源,用哪个数据库和表数据的。
接下来我们直接写Junit测试来测试一下。
@AutowiredOrderDao orderDao;@Testpublic void TestInsertShardingDao(){for (int i = 0; i < 10; i++) {orderDao.insertOrder(i,"大电视",1);}}

如果是单独看日志的话,看样子是成功了,那么我们得实际来验证一下这个内容。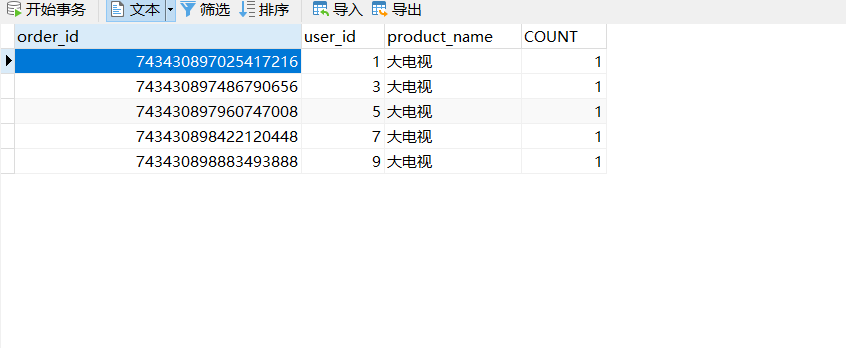
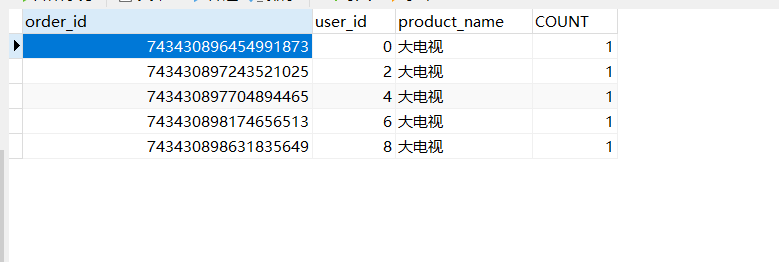
这么看下来,我们保存的数据是没问题的,从水平切分来看,我们把数据分别保存了database1 和database2 库中的 orderinfo 里面,也就是说,我们的数据算是水平切分到了不同的数据库对应的表中。
接下来我们是不是就得去执行查询了?
分库分表后的查询
我们直接查询:
@Testpublic void TestQueryShardingDao(){List<Long> ids = new ArrayList<>();ids.add(743430896454991873L);ids.add(743430897486790656L);List<Map> mapList = orderDao.findOrderByIds(ids); System.out.println(mapList);}/*** 根据ID 查询订单* */@Select({"<script>"+"select * from orderinfo p where p.order_id in " +"<foreach collection='orderIds' item='id' open='(' separator = ',' close=')'>#{id}</foreach>"+"</script>"})List<Map> findOrderByIds(@Param("orderIds") List<Long> orderIds);
我们直接看返回结果
[{user_id=0, COUNT=1, order_id=743430896454991873, product_name=大电视}, {user_id=3, COUNT=1, order_id=743430897486790656, product_name=大电视}]
这个样子看起来,我们水平分库分表拆分,是不是就完成了?
在这里,既然实战结束了,阿粉就得开始说说这个配置了。
在说配置之前,我们得先了解一下关于Sharding-JDBC的执行流程,不然我们也不知道这些配置都是干嘛用的。
当我们把SQL发送给 Sharding 之后,Sharding 会经过五个步骤,然后给我们返回接口,这五个步骤分别是:
- SQL解析
- SQL路由
- SQL改写
- SQL执行
- 结果归并
SQL解析:编写SQL查询的是逻辑表, 执行时 ShardingJDBC 要解析SQL ,解析的目的是为了找到需要改写的位置。
SQL路由: SQL的路由是指 将对逻辑表的操作,映射到对应的数据节点的过程. ShardingJDBC会获取分片键判断是否正确,正确 就执行分片策略(算法) 来找到真实的表。
SQL改写: 程序员面向的是逻辑表编写SQL, 并不能直接在真实的数据库中执行,SQL改写用于将逻辑 SQL改为在真实的数据库中可以正确执行的SQL。
SQL执行: 通过配置规则 order_$->{order_id % 2 + 1} ,可以知道当 order_id 为偶数时 , 应该向 order_1表中插入数据, 为奇数时向 order_2表插入数据。
结果归并:将所有真正执行sql的结果进行汇总合并,然后返回。
我们都知道,要是用Sharding分库分表,那么自然就会有相对应的配置,而这些配置才是比较重要的地方,而其中比较经典的就是分片策略了。
分片策略
分片策略分为分表策略和分库策略,它们实现分片算法的方式基本相同,但是在阿粉看来,好像没有太大的区别,无非一个是针对库,一个是针对表。
而一般分片策略主要是分为如下的几种:
- standard:标准分片策略
- complex:复合分片策略
- inline:行表达式分片策略,,使用Groovy的表达式.
- hint:Hint分片策略,对应HintShardingStrategy。
- none:不分片策略,对应NoneShardingStrategy。不分片的策略。
那么什么是标准的分片策略呢?
标准分片策略StandardShardingStrategy
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 操作符,都可以应用此分片策略。
也就是说,你的 SQL 语句中频繁的出现这些符号的时候,而且这个时候你还想要进行分库分表的时候,就可以采用这个策略了。
但是这个时候要谨记一些内容,那就是标准分片策略(StandardShardingStrategy),它只支持对单个分片键(字段)为依据的分库分表,并提供了两种分片算法 PreciseShardingAlgorithm(精准分片)和 RangeShardingAlgorithm(范围分片)。
在使用标准分片策略时,精准分片算法是必须实现的算法,用于 SQL 含有 = 和 IN 的分片处理;范围分片算法是非必选的,用于处理含有 BETWEEN AND 的分片处理。
复合分片策略
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片键操作。
这里要注意的就是多个分片键,也就是说,如果我们分片的话需要使用两个字段作为分片键,自定义复合分片策略。
行表达式分片策略
它的配置相当简洁,这种分片策略利用inline.algorithm-expression书写表达式。
阿粉就是使用的这个,来完成的分片,而且行表达式分片策略适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是几种分片策略中最为简单的。
但是要注意,行表达式分片策略,它只支持单分片键。
Hint分片策略
Hint分片策略(HintShardingStrategy)和其他的分片策略都不一样了,这种分片策略无需配置分片键,分片键值也不再从 SQL中解析,而是由外部指定分片信息,让 SQL在指定的分库、分表中执行。
不分片策略
不分片策略这个没啥可说的,你不分片的话,用Sharing-JDBC的话,可能就没啥意思了。毕竟玩的就是分片。
在这里,阿粉想说,没有最好的分片策略,有些公司看重学习成本,有些公司看重实际应用,只能说选择对你们公司业务最优的才是最好的。下一篇文章阿粉再来说一下这个垂直分库分表实战。希望大家点个赞,支持一波阿粉,万分感谢!
文章参考
拉勾Sharding-JDBC讲解实战

若有收获,就点个赞吧
0 人点赞
