工业界
学术界
PLOME

预训练语言模型 可以看做是macbert的进化
- PLOME模型是专门针对中文文本纠错任务构建的预训练语言模型。
- 在训练预训练语言模型时,采用基于语义混淆集的MASK策略
- 将拼音和笔画作为预训练语言模型以及模型微调的输入
- 将字符预测任务和拼音预测任务作为预训练语言模型以及模型微调的训练目标
- PLOME预训练语言模型的下游任务主要是文本纠错任务
微调和训练目标 和 预训练任务一致,都设置了字符预测和拼音预测任务;但预训练仅需要对替换字符进行预测,实际微调使用过程中需要对所有的输入字符进行预测
ErnieCSC(百度)
基于ERNIE的中文拼写纠错模型,模型已经开源在PaddleNLP的 模型库中https://bj.bcebos.com/paddlenlp/taskflow/text_correction/csc-ernie-1.0/csc-ernie-1.0.pdparams
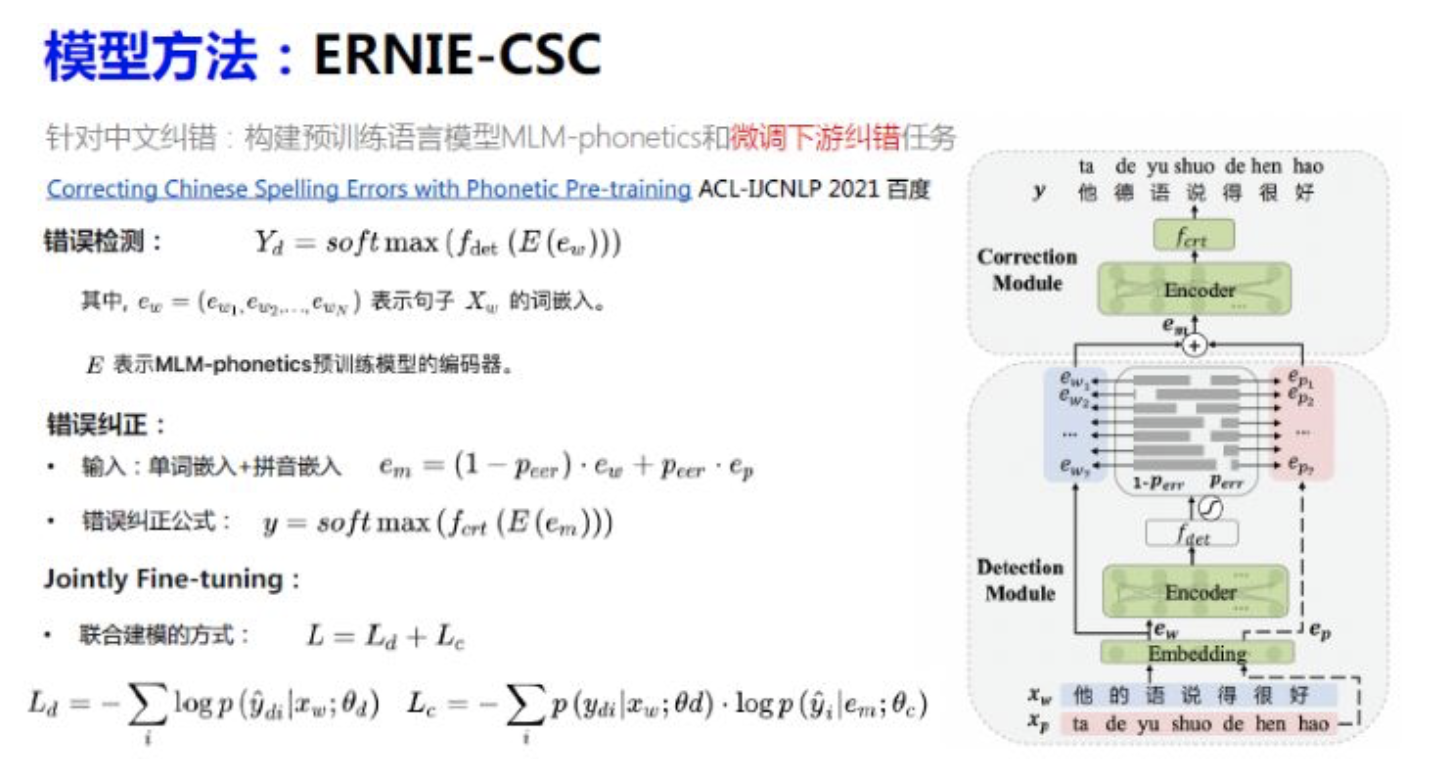
构建了一整套端到端中文文本纠错模型,包括构建预训练语言模型MLM-phonetics和微调下游纠错任务
- MLM-base 遮盖了15%的词进行预测, MLM-phonetics 遮盖了20%的词进行预测。
- MLM-base 的遮盖策略基于以下3种:[MASK]标记替换(和BERT一致)、随机字符替换(Random Hanzi)、原词不变(Same)。且3种遮盖策略占比分别为: 80% 、10%、10%。MLM-phonetics的Mask策略基于以下3种:[MASK]标记替换(和BERT一致)、字音混淆词替换(Confused-Hanzi)、混淆字符的拼音替换(Noisy-pinyin)。且这3种遮盖策略分别占比为: 40%、30%、30%。
将错误纠正任务和错误检测任务作为预训练语言模型以及模型微调的训练目标
未来方向与挑战
如果有足够的对齐语料,可以继续沿预训练模型的角度进行,Transformer的编码解码器思路,并且引入基于预训练的Seq2Seq模型,例如GPT,BART等;
- 模型需要支持热更新,支持时事热点中的新词,例如当下热点的”传闻中的成仙仙” -> “传闻中的陈芊芊”;
- 对于不等长的文本纠错缺乏可用模型;
对于复杂的句法错误以及语义中的知识性错误、逻辑性错误、表意不明还不能有效进行处理;
pycorrector
基于规则
文本预处理
初始化:
包括分词jieba(需将 自定义混淆集,专名集加入用户自定义词典)
- 加载各类词典文件
- 语言模型kenlm
错误检测
1. 自定义混淆集加入疑似错误词典
2. 专名错误检测,专名词典,包括成语、俗语、专业领域词等
- 分词
- 获得1,2,3,4gram的结果
- 词长度过滤,max_word_length: 专名词的最大长度为4; min_word_length:专名词的最小长度为2
- 与专名词典中的词计算相似度(计算两个词的拼音和字形相似度),策略是取大的作为相思分数
- 如果相似度大于>阈值,则加入疑似错误词典
3. 词错误:
分词后,过滤(数字,标点符号,英文,非中文等)字符串
if self.is_filter_token(token):continue
def is_filter_token(token):"""是否为需过滤字词:param token: 字词:return: bool"""result = False# pass blankif not token.strip():result = True# pass numif token.isdigit():result = True# pass alphaif is_alphabet_string(token.lower()):result = True# pass not chineseif not is_chinese_string(token):result = Truereturn result
将未登录词加入疑似错误词典
# pass in dictif token in self.word_freq:continuemaybe_err = [token, begin_idx + start_idx, end_idx + start_idx, ErrorType.word]
4. 字错误,语言模型检测疑似错误字
获得2-gram 和3-gram 的语言模型得分scores;
- 滑动窗口补全得分,ngram,窗口移动,前后得补全n-1个元素
- 取拼接后的n-gram平均得分— line32
取疑似错字的位置,通过平均绝对离差(MAD)或者 通过平均值上下n倍标准差之间属于正常点
if self.is_char_error_detect:try:ngram_avg_scores = []for n in [2, 3]: #选取2-gram,3-gram.scores = []# sentence 今天新情很好,句子长度为6for i in range(len(sentence) - n + 1):word = sentence[i:i + n]'''word: 今天word: 天新word: 新情word: 情很word: 很好'''score = self.ngram_score(list(word)) # kenlm加载已训练好的工具包scores.append(score)# scores=[-4.004828929901123, -5.91748571395874, -5.758666038513184, -5.612854957580566, -4.5769429206848145]if not scores:continue# 移动窗口补全得分,# ngram,窗口移动,前后得补全n-1个元素for _ in range(n - 1):scores.insert(0, scores[0])scores.append(scores[-1])# [-4.004828929901123, -4.004828929901123, -5.91748571395874, -5.758666038513184, -5.612854957580566, -4.5769429206848145, -4.5769429206848145]avg_scores = [sum(scores[i:i + n]) / len(scores[i:i + n]) for i in range(len(sentence))]ngram_avg_scores.append(avg_scores)#2-gram和3-gram# [[-4.004828929901123, -4.961157321929932, -5.838075876235962, -5.685760498046875, -5.09489893913269, -4.5769429206848145],# [-7.758430480957031, -8.252998987833658, -8.834455808003744, -8.381499767303467, -7.4339752197265625, -6.399562358856201]]if ngram_avg_scores:# 取拼接后的n-gram平均得分,2-gram和3-gramsent_scores = list(np.average(np.array(ngram_avg_scores), axis=0))# 取疑似错字信息for i in self._get_maybe_error_index(sent_scores):token = sentence[i]# pass filter wordif self.is_filter_token(token):continue# pass in stop word dictif token in self.stopwords:continue# token, begin_idx, end_idx, error_typemaybe_err = [token, i + start_idx, i + start_idx + 1,ErrorType.char]self._add_maybe_error_item(maybe_err, maybe_errors)except IndexError as ie:logger.warn("index error, sentence:" + sentence + str(ie))except Exception as e:logger.warn("detect error, sentence:" + sentence + str(e))
'''平均绝对离差(mean absolute deviation)是用样本数据相对于其平均值的绝对距离来度量数据的离散程度。平均绝对离差也称为平均离差(mean deviation)。平均绝对离差定义为各数据与平均值的离差的绝对值的平均数'''def _get_maybe_error_index(scores, ratio=0.6745, threshold=2):"""取疑似错字的位置,通过平均绝对离差(MAD):param scores: np.array:param ratio: 正态分布表参数:param threshold: 阈值越小,得到疑似错别字越多:return: 全部疑似错误字的index: list"""result = []scores = np.array(scores)if len(scores.shape) == 1:scores = scores[:, None]median = np.median(scores, axis=0) # get median of all scoresmargin_median = np.abs(scores - median).flatten() # deviation from the median# 平均绝对离差值med_abs_deviation = np.median(margin_median)if med_abs_deviation == 0:return resulty_score = ratio * margin_median / med_abs_deviation# 打平scores = scores.flatten()maybe_error_indices = np.where((y_score > threshold) & (scores < median))# 取全部疑似错误字的indexresult = [int(i) for i in maybe_error_indices[0]]return resultdef _get_maybe_error_index_by_stddev(scores, n=2):"""取疑似错字的位置,通过平均值上下n倍标准差之间属于正常点:param scores: list, float:param n: n倍:return: 全部疑似错误字的index: list"""std = np.std(scores, ddof=1)mean = np.mean(scores)down_limit = mean - n * stdupper_limit = mean + n * stdmaybe_error_indices = np.where((scores > upper_limit) | (scores < down_limit))# 取全部疑似错误字的indexresult = list(maybe_error_indices[0])return result
错误修正
自定义混淆集加入疑似错误词典
- 根据词典定义直接用正确的替换
- 专有名词
- 根据专有名词词典定义直接用正确的替换
- 字/词错误
- 生成纠错候选集,根据相同的拼音获取,根据混淆词典中定义混淆词对获取
- 通过语言模型纠正字词错误
"""通过语言模型纠正字词错误:param cur_item: 当前词:param candidates: 候选词:param before_sent: 前半部分句子:param after_sent: 后半部分句子:param threshold: ppl阈值, 原始字词替换后大于该ppl值则认为是错误:param cut_type: 切词方式, 字粒度:return: str, correct item, 正确的字词"""result = cur_itemif cur_item not in candidates:candidates.append(cur_item)ppl_scores = {i: self.ppl_score(segment(before_sent + i + after_sent, cut_type=cut_type)) for i in candidates}sorted_ppl_scores = sorted(ppl_scores.items(), key=lambda d: d[1])
基于深度学习网络
主要使用了多种深度模型应用于文本纠错任务,分别是前面模型小节介绍的macbert、seq2seq、bert、electra、transformer 、ernie-csc,各模型方法内置于pycorrector文件夹下,有README.md详细指导,各模型可独立运行,相互之间无依赖。macbert
模型简介
MacBERT 全称为 MLM as correction BERT,其中 MLM 指的是 masked language model。
paper:Revisiting Pre-trained Models for Chinese Natural Language Processing
code:https://github.com/ymcui/MacBERT tensorflow版本
以上来源:https://paperswithcode.com/paper/revisiting-pre-trained-models-for-chinese#code
本项目是 MacBERT 改变网络结构的中文文本纠错模型:“MacBERT shares the same pre-training tasks as BERT with several modifications.” —— (Cui et al., Findings of the EMNLP 2020)
模型结构
- 在通常 BERT 模型上进行了魔改,追加了一个全连接层作为错误检测即 detection, 与 SoftMaskedBERT 模型不同点在于,本项目中的 MacBERT 中,只是利用 detection 层和 correction 层的 loss 加权得到最终的 loss。不像 SoftmaskedBERT 中需要利用 detection 层的置信概率来作为 correction 的输入权重。
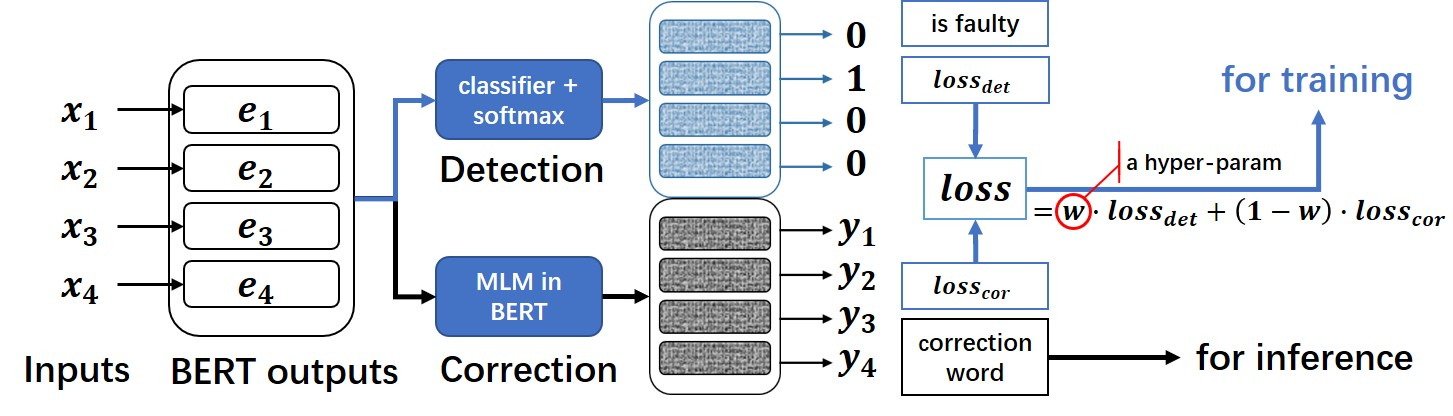
不过该模型只能处理输入输出等长的纠错任务,与后文的Soft-MASK BERT一样,具有一定局限性。
模型训练
在mask 策略上主要不同点在于:
- 和 BERT 类模型相似地,对于每个训练样本,15%的输入的word进行mask,其中 80% 的词被替换成近义词(原为[MASK])、10%的词替换为随机词,10%的词不变。
- BERT 类模型通常使用 [MASK] 来屏蔽原词,而 MacBERT 使用第三方的同义词工具来为目标词生成近义词用于屏蔽原词,特别地,当原词没有近义词时,使用随机 n-gram 来屏蔽原词;
- 使用全词屏蔽 (wwm, whole-word masking) 以及 N-gram 屏蔽策略来选择 candidate tokens 进行屏蔽;
微调:
微调的基本模型,可以自动下载hfl/chinese-macbert-base:
>>> from transformers import BertForMaskedLM>>> bert = BertForMaskedLM.from_pretrained("hfl/chinese-macbert-base")Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 659/659 [00:00<00:00, 468kB/s]Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 393M/393M [00:28<00:00, 14.4MB/s]Some weights of the model checkpoint at hfl/chinese-macbert-base were not used when initializing BertForMaskedLM: ['cls.seq_relationship.bias', 'cls.seq_relationship.weight']- This IS expected if you are initializing BertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing BertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).>>>
bert_outputs是bert 的输出,追加一个全连接(nn.Linear)得到检错概率,
class MacBert4Csc(CscTrainingModel, ABC):def __init__(self, cfg, tokenizer):super().__init__(cfg)self.cfg = cfg# cfg.MODEL.BERT_CKPT="hfl/chinese-macbert-base"self.bert = BertForMaskedLM.from_pretrained(cfg.MODEL.BERT_CKPT)self.detection = nn.Linear(self.bert.config.hidden_size, 1)self.sigmoid = nn.Sigmoid()self.tokenizer = tokenizerdef forward(self, texts, cor_labels=None, det_labels=None):if cor_labels:text_labels = self.tokenizer(cor_labels, padding=True, return_tensors='pt')['input_ids']text_labels[text_labels == 0] = -100 # -100计算损失时会忽略text_labels = text_labels.to(self.device)else:text_labels = Noneencoded_text = self.tokenizer(texts, padding=True, return_tensors='pt')encoded_text.to(self.device)bert_outputs = self.bert(**encoded_text, labels=text_labels, return_dict=True, output_hidden_states=True)# 检错概率prob = self.detection(bert_outputs.hidden_states[-1])if text_labels is None:# 检错输出,纠错输出outputs = (prob, bert_outputs.logits)else:det_loss_fct = FocalLoss(num_labels=None, activation_type='sigmoid')# pad部分不计算损失active_loss = encoded_text['attention_mask'].view(-1, prob.shape[1]) == 1active_probs = prob.view(-1, prob.shape[1])[active_loss]active_labels = det_labels[active_loss]det_loss = det_loss_fct(active_probs, active_labels.float())# 检错loss,纠错loss,检错输出,纠错输出outputs = (det_loss,bert_outputs.loss,self.sigmoid(prob).squeeze(-1),bert_outputs.logits)return outputs
模型加载
tokenizer = BertTokenizer.from_pretrained("shibing624/macbert4csc-base-chinese"�)model = BertForMaskedLM.from_pretrained("shibing624/macbert4csc-base-chinese"�)
- 当前中文拼写纠错模型效果最好的是macbert,模型名称是shibing624/macbert4csc-base-chinese
- 基础模型Models:https://huggingface.co/shibing624/macbert4csc-base-chinese 关于原macbert模型训练代码并未开源
- 但是纠错的macbert微调训练模型已开源
- 模型最后输出纬度:(batch_size,seq_length+2, vocab_size),最后输出最大词的索引,由于tokenizer.decode没有开源,不知道具体解码过程,也就是seq_length+2。
使用说明
```python from pycorrector.macbert.macbert_corrector import MacBertCorrector
nlp = MacBertCorrector(“shibing624/macbert4csc-base-chinese”).macbert_correct
i = nlp(‘今天新情很好’) print(i) ```
纠错任务测试结果
安装了pycorrect环境,做了一个简单的对比测试。
2.8G:语言模型:zh_giga.no_cna_cmn.prune01244.klm
144M语言模型:people2014corpus_chars.klm(密码o5e9)
xmnlp用的是bert (pytorch版本)的模型。
- 评估标准:纠错准召率,采用严格句子粒度(Sentence Level)计算方式,把模型纠正之后的与正确句子完成相同的视为正确,否则为错。 | | | 过纠率 | acc | precision | recall | f1 | 时间 | | —- | —- | —- | —- | —- | —- | —- | —- | | sighan_15 | rule_2.8G | 0.1257 | 0.5100 | 0.5139 | 0.1363 | 0.2154 | 790.75 s | | | rule_140M | 0.16 | 0.4827 | 0.4167 | 0.1197 | 0.1860 | 807.10 s | | | macbert | 0.1508 | 0.7900 | 0.8250 | 0.7293 | 0.7742 | 16.67s | | | xmnlp | 0.1454 | 0.5327 | 0.5759 | 0.2026 | 0.2997 | 43.77 s | | | FASPell | - | - | 0.666 | 0.591 | - | - | | corpus500 | rule_2.8G | 0.1095 | 0.4820 | 0.7381 | 0.2074 | 0.3238 | 483.01 s | | | rule_140M | 0.1194 | 0.4760 | 0.7176 | 0.2040 | 0.3177 | 501.77s | | | macbert | 0.0846 | 0.7260 | 0.9133 | 0.5987 | 0.7232 | 9.04 s | | | xmnlp | 0.1045 | 0.4560 | 0.6957 | 0.1605 | 0.2609 | 23.13 |
官方结果:
sighan_15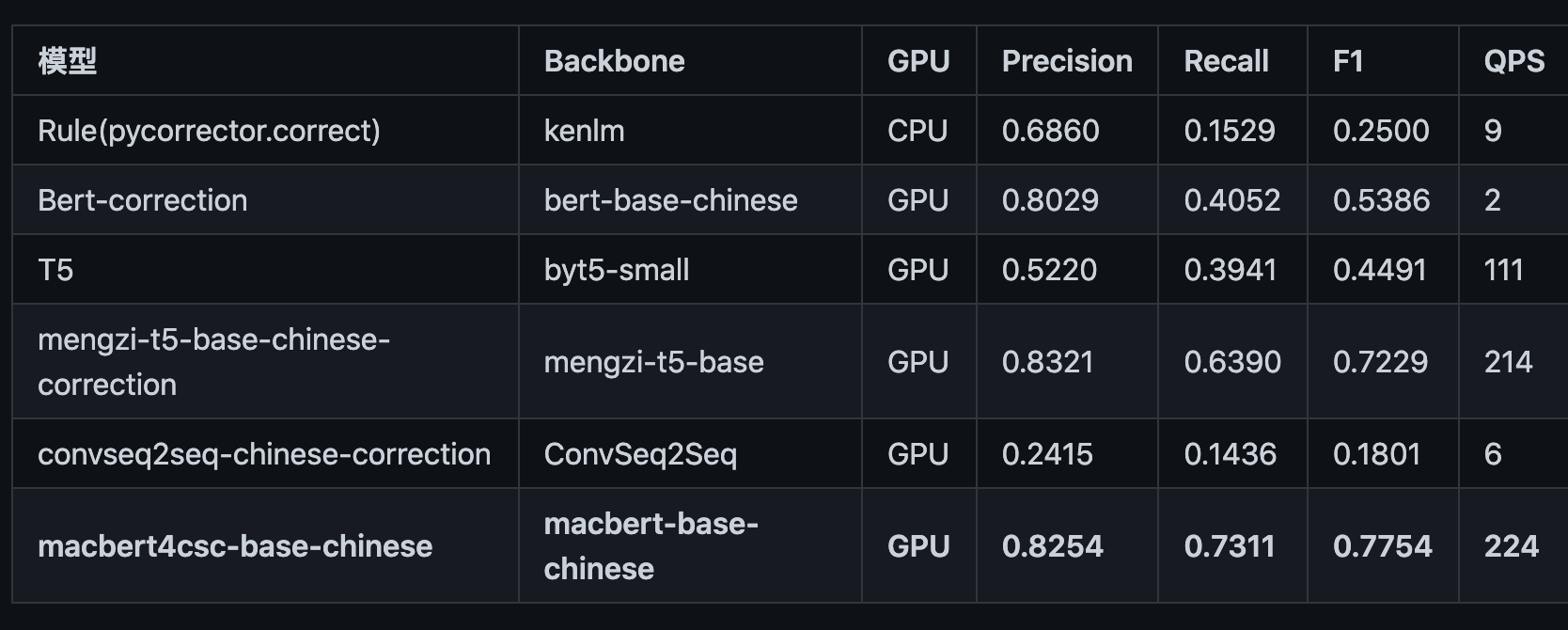

若有收获,就点个赞吧
0 人点赞
