- 最新进展
- 模型概述
- 词向量映射
- 实验结论
- 总结
- 落地导航
- 任务分支
- 层级性多元标签文本分类
- HFT-CNN: Learning Hierarchical Category Structure for Multi-label Short Text Categorization">HFT-CNN: Learning Hierarchical Category Structure for Multi-label Short Text Categorization
- NeuralClassifier: An Open-source Neural Hierarchical Multi-label Text Classification Toolkit
- Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach
- (平行性)多标签文本分类
- 层级性多元标签文本分类
- Placeholder
- 优化方法
- 问题
最新进展
文本分类一直都是研究热点,不过现在更需要针对场景细分化去做,例如多标签文本分类,分层的多标签分类(HMLTC),针对文本分类的数据增强工作。
模型概述
FastText
一般作为baseline,快速应用。 输入层采用 N-gram特征,然后映射为embedding,然后将特征映射后的向量取均值,再经过一个全连接层,最后使用 Softmax 计算每个类别的概率。 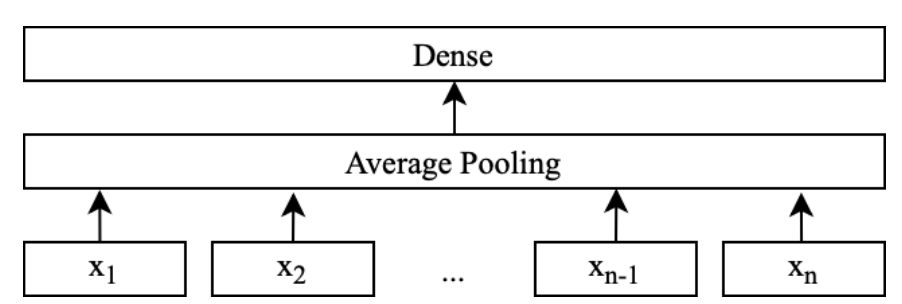
TextCNN
卷积核的大小分别是3,4,5,最后使用 Softmax 计算每个类别的概率。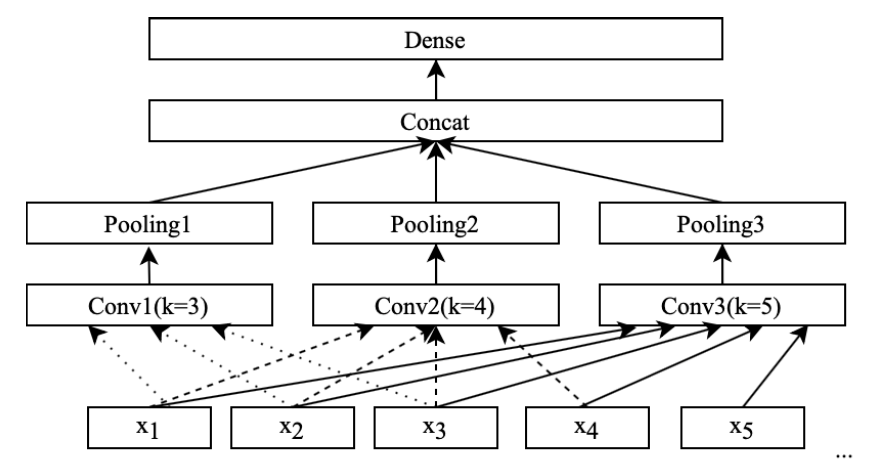
for i, filter_size in enumerate(self.filter_sizes):with tf.name_scope("conv-%s" % i):# conv layerconv = tf.layers.conv1d(embedding_inputs, self.num_filters,filter_size,padding='valid', activation=tf.nn.relu,kernel_regularizer=self.regularizer)# global max poolingpooled = tf.layers.max_pooling1d(conv, self.seq_length - filter_size + 1, 1)pooled_outputs.append(pooled)
输入是embedding_inputs=[seq_length, embedding_dim],这里conv 的size是[self.seq_length - filter_size + 1,self.num_filters],所以max-pooling 的pool_size设这个得到N(N=3)个1x1的数值,拼接成一个N维向量,作为文本的句子表示。
注意⚠️:
- kernel_size:卷积核的大小,卷积核本身应该是二维的,这里只需要指定一维,因为第二个维度即长度与词向量的长度一致,卷积核只能从上往下走,不能从左往右走,即只能按照文本中词的顺序,也是列的顺序。
- 最后一维等于self.num_filters。
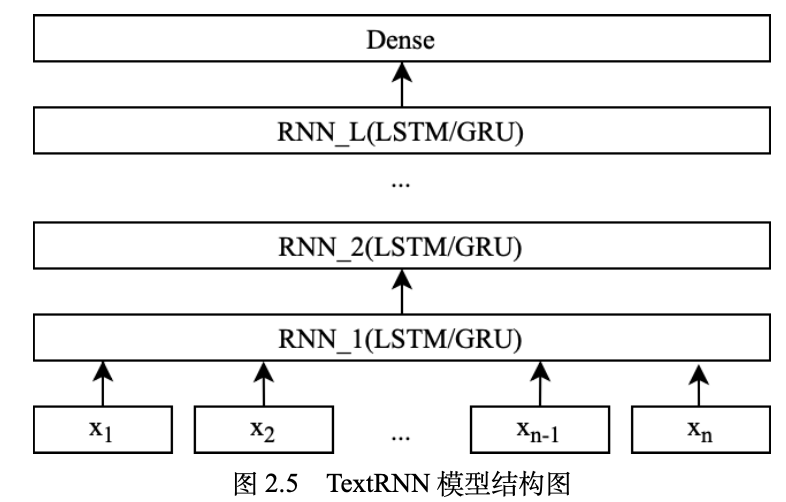
TextRNN
 ```python
def dropout(rnn_name, hidden_dim, keep_prob):
```python
def dropout(rnn_name, hidden_dim, keep_prob):if (rnn_name == 'lstm'):cell = lstm_cell(hidden_dim)else:cell = gru_cell(hidden_dim)return tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=keep_prob)
词向量映射
with tf.name_scope(“embedding”): embedding = tf.get_variable(‘embedding’, [self.vocab_size, self.embedding_dim]) embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope(“rnn”):
# 多层rnn网络cells = [dropout(self.rnn_name, self.hidden_dim, self.keep_prob)for _ in range(self.num_layers)]rnn_cell = tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True)_outputs, _ = tf.nn.dynamic_rnn(cell=rnn_cell, inputs=embedding_inputs, dtype=tf.float32)last = _outputs[:, -1, :] # 取最后一个时序输出作为结果
with tf.name_scope(“score”):
# 全连接层,后面接dropout以及relu激活fc = tf.layers.dense(last, self.hidden_dim, name='fc1')fc = tf.contrib.layers.dropout(fc, self.keep_prob)fc = tf.nn.relu(fc)# 分类器self.logits = tf.layers.dense(fc, self.num_classes, name='fc2')self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1, name="pred")
输入是embedding_inputs=[seq_length, embedding_dim],输出是[seq_length,hidden_dim],假设每一层的hidden_dim 都不一样的话,output的最后一维是最后一层的hidden_dim 。<a name="KCDwU"></a>#### BiRNN```pythondef dropout(rnn_name, hidden_dim, keep_prob):if (rnn_name == 'lstm'):cell = lstm_cell(hidden_dim)else:cell = gru_cell(hidden_dim)return tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=keep_prob)# 词向量映射with tf.name_scope("embedding"):embedding = tf.get_variable('embedding', [self.vocab_size, self.embedding_dim])embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)with tf.name_scope("rnn"):# 多层rnn网络fw_cells = [dropout(self.rnn_name, self.hidden_dim, self.keep_prob)for _ in range(self.num_layers)]bw_cells = [dropout(self.rnn_name, self.hidden_dim, self.keep_prob)for _ in range(self.num_layers)]fw_rnn_cell = tf.contrib.rnn.MultiRNNCell(fw_cells, state_is_tuple=True)bw_rnn_cell = tf.contrib.rnn.MultiRNNCell(bw_cells, state_is_tuple=True)outputs, states = tf.nn.bidirectional_dynamic_rnn(cell_fw=fw_rnn_cell, cell_bw=bw_rnn_cell,inputs=embedding_inputs,dtype=tf.float32)outputs_fw = outputs[0]outputs_bw = outputs[1]last = outputs_fw[:, -1, :] + outputs_bw[:, -1, :]with tf.name_scope("score"):# 全连接层,后面接dropout以及relu激活fc = tf.layers.dense(last, self.hidden_dim, name='fc1')fc = tf.contrib.layers.dropout(fc, self.keep_prob)fc = tf.nn.relu(fc)# 分类器self.logits = tf.layers.dense(fc, self.num_classes, name='fc2')self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1, name="pred")
RCNN
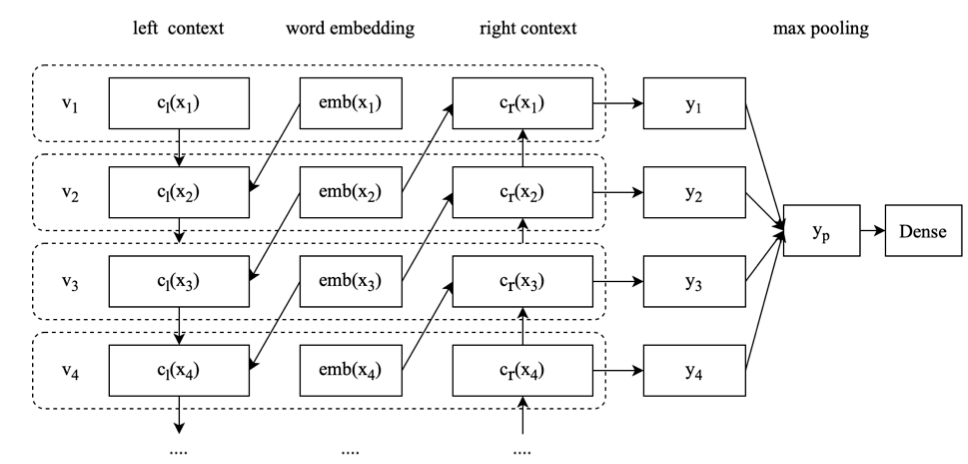
一般来说 CNN 应用于文本处理都是“卷积层 + 池化层”来对输入序列做特征提取,而这里是将卷积操作换成了双向的 RNN 结构,然后进行池化操作,该模型的结 构就变成了“双向 RNN+ 池化”,所以就是 RCNN。
def _get_cell():if self.rnn_type == "vanilla":return tf.nn.rnn_cell.BasicRNNCell(self.context_dim)elif self.rnn_type == "lstm":return tf.nn.rnn_cell.BasicLSTMCell(self.context_dim)else:return tf.nn.rnn_cell.GRUCell(self.context_dim)# 词向量映射with tf.name_scope("embedding"):embedding = tf.get_variable('embedding', [self.vocab_size, self.embedding_dim])embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)# Bidirectional(Left&Right) Recurrent Structurewith tf.name_scope("bi-rnn"):fw_cell = _get_cell()fw_cell = tf.nn.rnn_cell.DropoutWrapper(fw_cell, output_keep_prob=self.keep_prob)bw_cell = _get_cell()bw_cell = tf.nn.rnn_cell.DropoutWrapper(bw_cell, output_keep_prob=self.keep_prob)(output_fw, output_bw), states = tf.nn.bidirectional_dynamic_rnn(cell_fw=fw_cell,cell_bw=bw_cell,inputs=embedding_inputs,dtype=tf.float32)with tf.name_scope("context"):shape = [tf.shape(output_fw)[0], 1, tf.shape(output_fw)[2]]c_left = tf.concat([tf.zeros(shape), output_fw[:, :-1]], axis=1, name="context_left")c_right = tf.concat([output_bw[:, 1:], tf.zeros(shape)], axis=1, name="context_right")with tf.name_scope("word-representation"):last = tf.concat([c_left, embedding_inputs, c_right], axis=2, name="last")embedding_size = 2 * self.context_dim + self.embedding_dimwith tf.name_scope("text-representation"):fc = tf.layers.dense(last, self.hidden_dim, activation=tf.nn.relu, name='fc1')fc_pool = tf.reduce_max(fc, axis=1)with tf.name_scope("score"):# 分类器self.logits = tf.layers.dense(fc_pool, self.num_classes, name='fc2')self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1, name="pred") # 预测类别
HAN
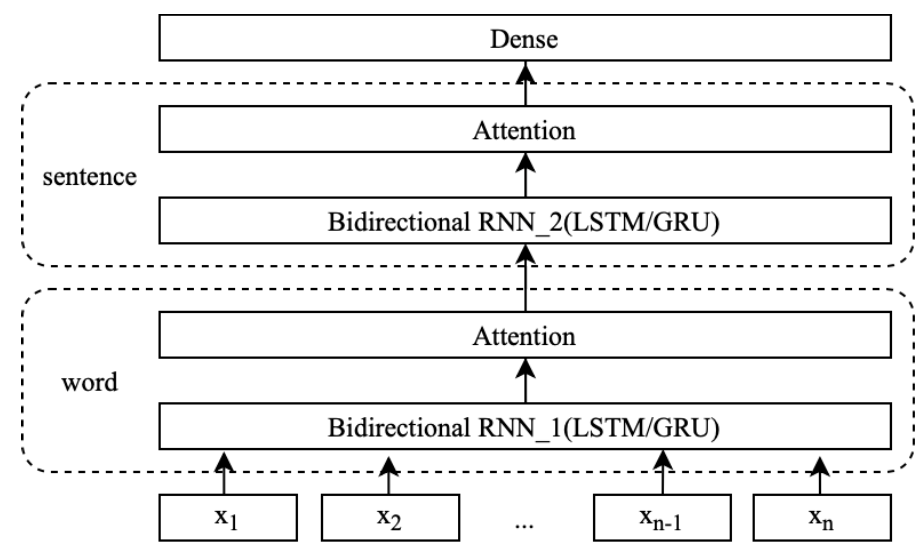
with tf.name_scope("embedding"):input_x = tf.split(self.input_x, self.num_sentences, axis=1)# shape:[None,self.num_sentences,self.sequence_length/num_sentences]input_x = tf.stack(input_x, axis=1)embedding = tf.get_variable("embedding", [self.vocab_size, self.embedding_dim])# [None,num_sentences,sentence_length,embed_size]embedding_inputs = tf.nn.embedding_lookup(embedding, input_x)# [batch_size*num_sentences,sentence_length,embed_size]sentence_len = int(self.seq_length / self.num_sentences)embedding_inputs_reshaped = tf.reshape(embedding_inputs,shape=[-1, sentence_len, self.embedding_dim])with tf.name_scope("word_vec"):(output_fw, output_bw) = _Bidirectional_Encoder(embedding_inputs_reshaped, "word_vec")# [batch_size*num_sentences,sentence_length,hidden_size * 2]word_hidden_state = tf.concat((output_fw, output_bw), 2)with tf.name_scope("word_attention"):"""attention process:1.get logits for each word in the sentence.2.get possibility distribution for each word in the sentence.3.get weighted sum for the sentence as sentence representation."""# [batch_size*num_sentences, hidden_size * 2]sentence_vec = _attention(word_hidden_state, "word_attention")with tf.name_scope("sentence_vec"):# [batch_size,num_sentences,hidden_size*2]sentence_vec = tf.reshape(sentence_vec, shape=[-1, self.num_sentences,self.context_dim * 2])output_fw, output_bw = _Bidirectional_Encoder(sentence_vec, "sentence_vec")# [batch_size*num_sentences,sentence_length,hidden_size * 2]sentence_hidden_state = tf.concat((output_fw, output_bw), 2)with tf.name_scope("sentence_attention"):# [batch_size, hidden_size * 2]doc_vec = _attention(sentence_hidden_state, "sentence_attention")
DPCNN
DPCNN 由腾讯 AI-Lab 提出,是文本分类领域深度网络的代表,文本域嵌入(Region embedding) 是对输入层常规的词向量进行推广后获得的一词或多词的区域 embedding,其实质操 作就是对输入的文本序列以 3-gram 为单位进行一组卷积操作,紧接着叠加连续的两 个卷积块,其中卷积块包含两个卷积层和一个残差网络,然后与池化层交错,使用 stride=2 进行向下采样,下采样是减少计算复杂度的关键步骤。采用下采样可以使得 模型感知到的文本片段比之前长一倍,所以可以有效的压缩句子长度,例如原本只能 捕获 3 个词语的上下文信息,经过 stride=2 池化层后能感知到的文本长度信息就会扩 展为 6 个词语,所以 DPCNN 能够克服 CNN 的缺陷,捕捉长距离依赖信息。残差结构 能有效的解决深度网络的缺陷,最后的池化层作用是将文档的数据聚合为一个向量。 在 DPCNN 中固定了 filter 的数量,进而特征图(Feature map)的个数也就固定了,在 执行上述池化操作时,许多模型都习惯性的增加特征图的数目以获取性能提升,由此 深度增加,模型总计算复杂度也随之一起增加。综上所述,DPCNN 的网络结构呈金 字塔形状的主要原因是固定特征图数量后,每当使用一个 size=3 和 stride=2 进行多次 最大池化时,每个卷积层的输出的维度会逐步减半,计算时间也大大减少。 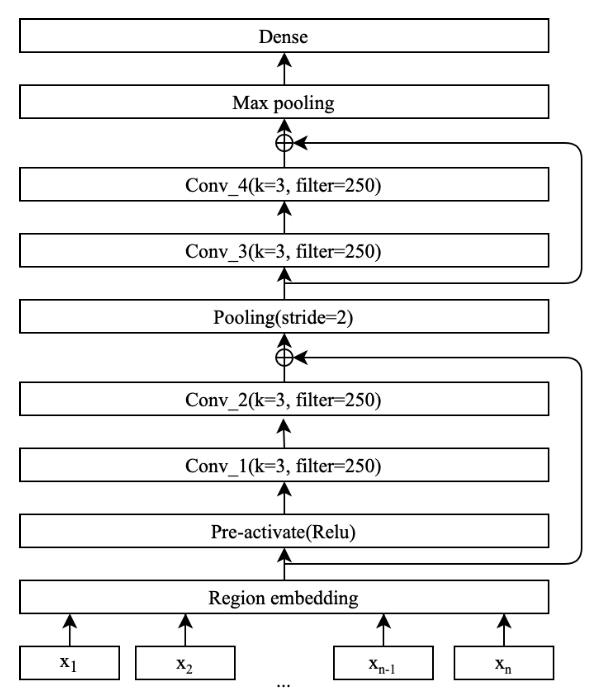
def inference(self):""":return:"""# 词向量映射with tf.name_scope("embedding"):embedding = tf.get_variable("embedding", [self.vocab_size, self.embedding_dim])embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)embedding_inputs = tf.expand_dims(embedding_inputs, axis=-1) # [None,seq,embedding,1]# region_embedding # [batch,seq-3+1,1,250]region_embedding = tf.layers.conv2d(embedding_inputs, self.num_filters,[self.kernel_size, self.embedding_dim])pre_activation = tf.nn.relu(region_embedding, name='preactivation')with tf.name_scope("conv3_0"):conv3 = tf.layers.conv2d(pre_activation, self.num_filters, self.kernel_size,padding="same", activation=tf.nn.relu)conv3 = tf.layers.batch_normalization(conv3)with tf.name_scope("conv3_1"):conv3 = tf.layers.conv2d(conv3, self.num_filters, self.kernel_size,padding="same", activation=tf.nn.relu)conv3 = tf.layers.batch_normalization(conv3)# resdulconv3 = conv3 + region_embeddingwith tf.name_scope("pool_1"):pool = tf.pad(conv3, paddings=[[0, 0], [0, 1], [0, 0], [0, 0]])pool = tf.nn.max_pool(pool, [1, 3, 1, 1], strides=[1, 2, 1, 1], padding='VALID')with tf.name_scope("conv3_2"):conv3 = tf.layers.conv2d(pool, self.num_filters, self.kernel_size,padding="same", activation=tf.nn.relu)conv3 = tf.layers.batch_normalization(conv3)with tf.name_scope("conv3_3"):conv3 = tf.layers.conv2d(conv3, self.num_filters, self.kernel_size,padding="same", activation=tf.nn.relu)conv3 = tf.layers.batch_normalization(conv3)# resdulconv3 = conv3 + poolpool_size = int((self.seq_length - 3 + 1)/2)conv3 = tf.layers.max_pooling1d(tf.squeeze(conv3, [2]), pool_size, 1)conv3 = tf.squeeze(conv3, [1]) # [batch,250]conv3 = tf.nn.dropout(conv3, self.keep_prob)with tf.name_scope("score"):# classifyself.logits = tf.layers.dense(conv3, self.num_classes, name='fc2')self.score = tf.nn.softmax(self.logits, name='score')self.y_pred_cls = tf.argmax(self.score , 1, name="pred")
Transformer
Transformer 是序列到序列的模型,在文本分类中只会用到encoder侧的网络,用最后一层的输出向量做一个分类。
Bert
应用Bert做文本分类,采用Bert 输出的[CLS]表征的向量接一个全连接,再接softMax,然后用交叉熵损失函数进行训练,做分类。Bert 的文本分类应该属于业界效果最好,应用最广的模型,且可以微调,适用于小数据量的应用场景。
实验结论
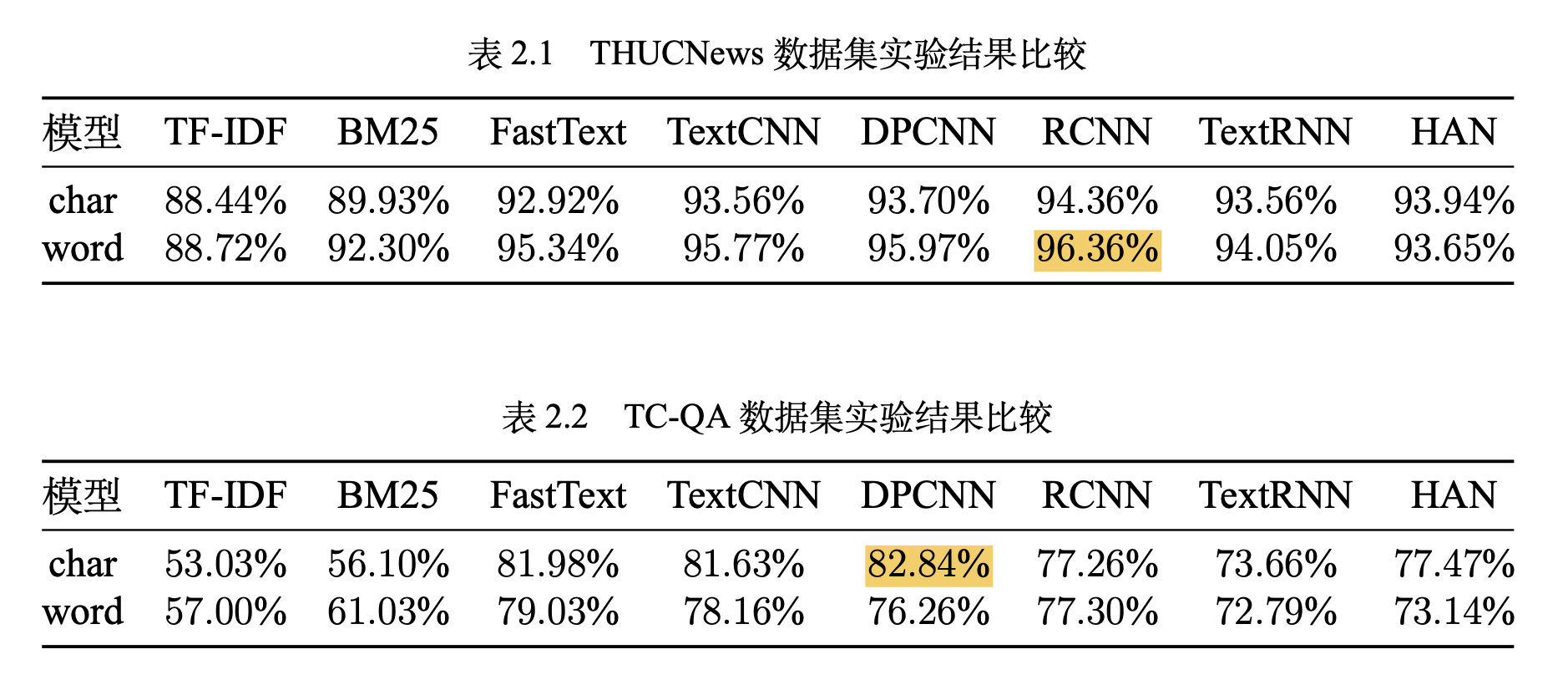
- 词嵌入向量化:word2vec, FastText等等
- 卷积神经网络特征提取:Text-CNN, Char-CNN等等
- 上下文机制:Text-RNN, BiRNN, RCNN等等
- 记忆存储机制:EntNet, DMN等等
- 注意力机制:HAN等等
训练时间
https://github.com/brightmart/text_classification
落地导航
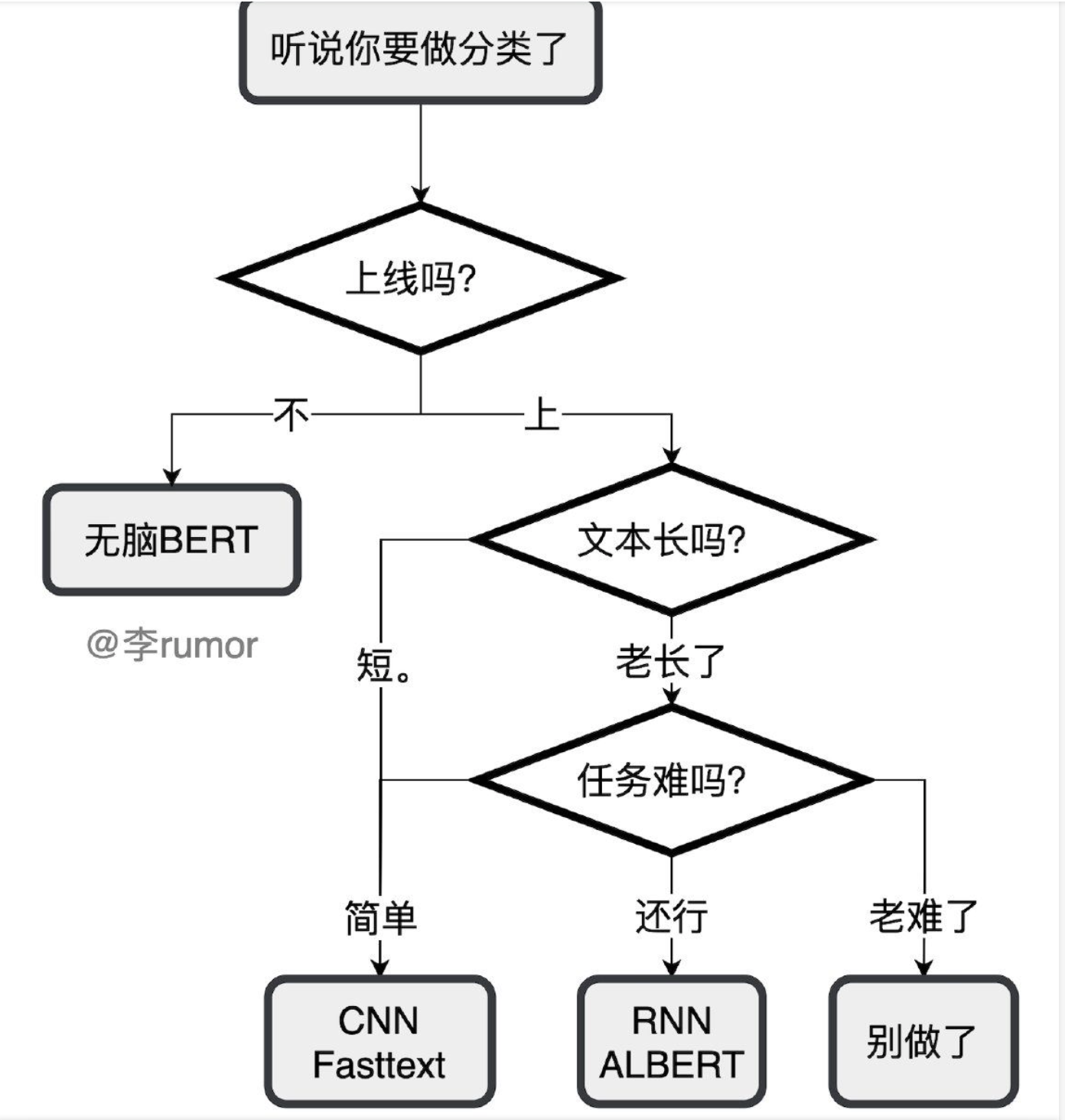
任务分支
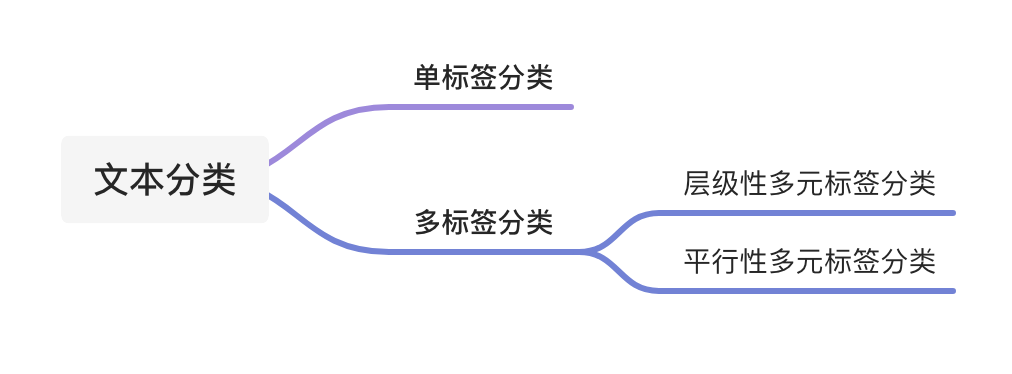
举几个应用例子,如一部电影可能是“喜剧片”,又是“爱情片”,而这电影的种类标签是平行的,没有层级结构;如一个电视产品,它属于“大家电”,也属于“家用电器”,而“大家电”标签是”家用电器”标签的子类,这产品所属种类标签是有层级结构,所以该类任务称为层级性多元标签分类。
层级性多元标签文本分类
存在的问题:
- 使用分类标签结构信息。
- 类别规模过大。
- 类别对应的训练样本数目不足且不平衡。
HFT-CNN: Learning Hierarchical Category Structure for Multi-label Short Text Categorization
code:采用一个少见的开源工具Chainer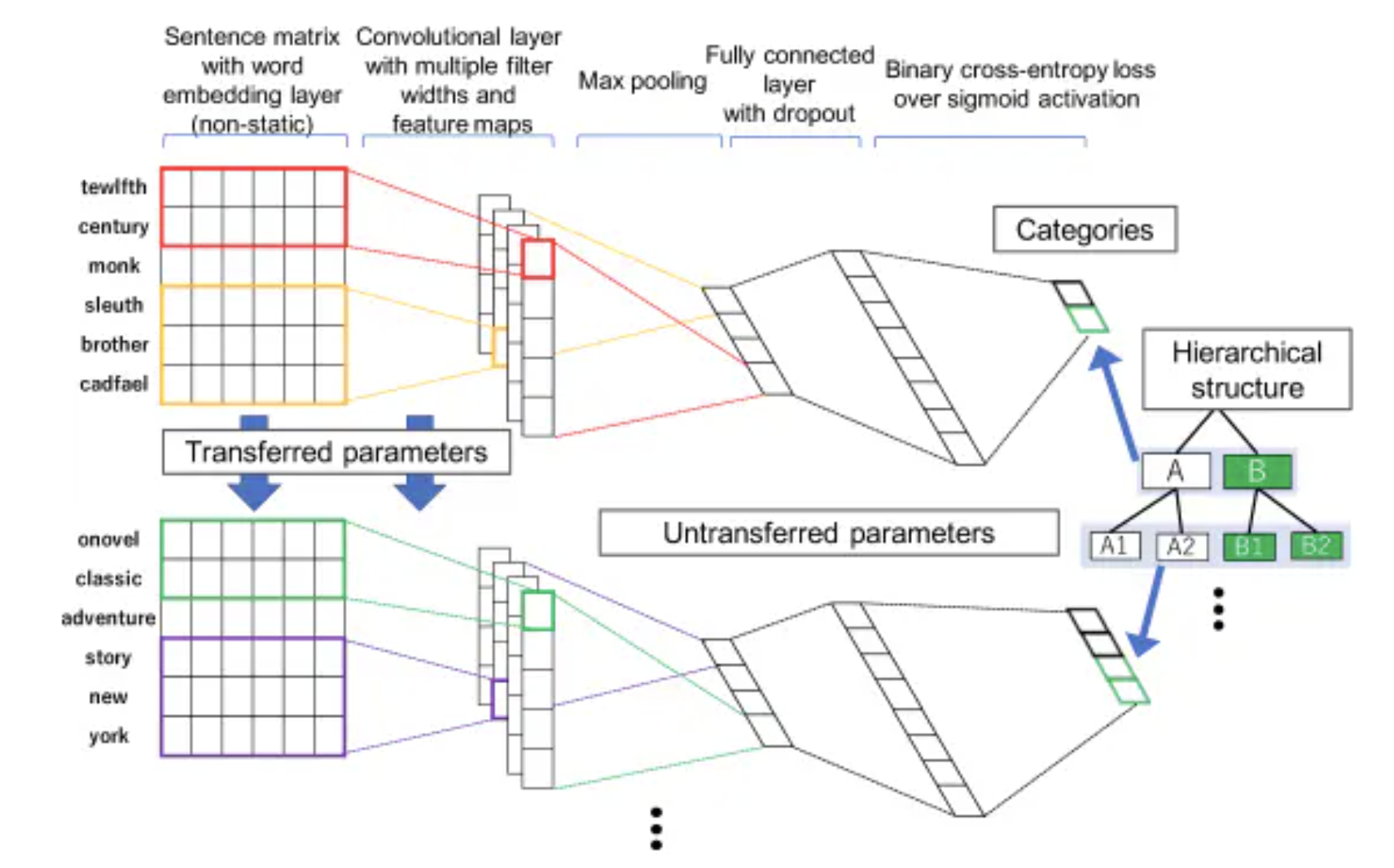
思路:
首先训练样本的顶层label(A,B),具体是在embedding层后加一个卷积层(convoluational layer),最大池化层(maxpooling layer),全连接层+dropout,最后加个sigmoid层,用的二元交叉熵(binary cross-entorpy loss)进行A,B标签预测,这一个CNN分类框架;
在预测下一层标签时(A1,A2,B1,B2),采用的仍是CNN结构,只是在embedding layer和convoluational layer继承上一层学习的结果,然后在这个基础上进行微调学习;
按照2,3步骤,遍历整个层级标签。
NeuralClassifier: An Open-source Neural Hierarchical Multi-label Text Classification Toolkit
腾讯的开源NLP项目,支持大部分的分类任务:二分类、多分类、多标签分类、层次分类。其中层次分类的方法参考【1】待学习
【1】paper:http://proceedings.mlr.press/v80/wehrmann18a/wehrmann18a.pdf
Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach
code;https://github.com/RandolphVI/Hierarchical-Multi-Label-Text-Classification
《Hierarchy-aware Label Semantics Matching Network for Hierarchical Text Classification》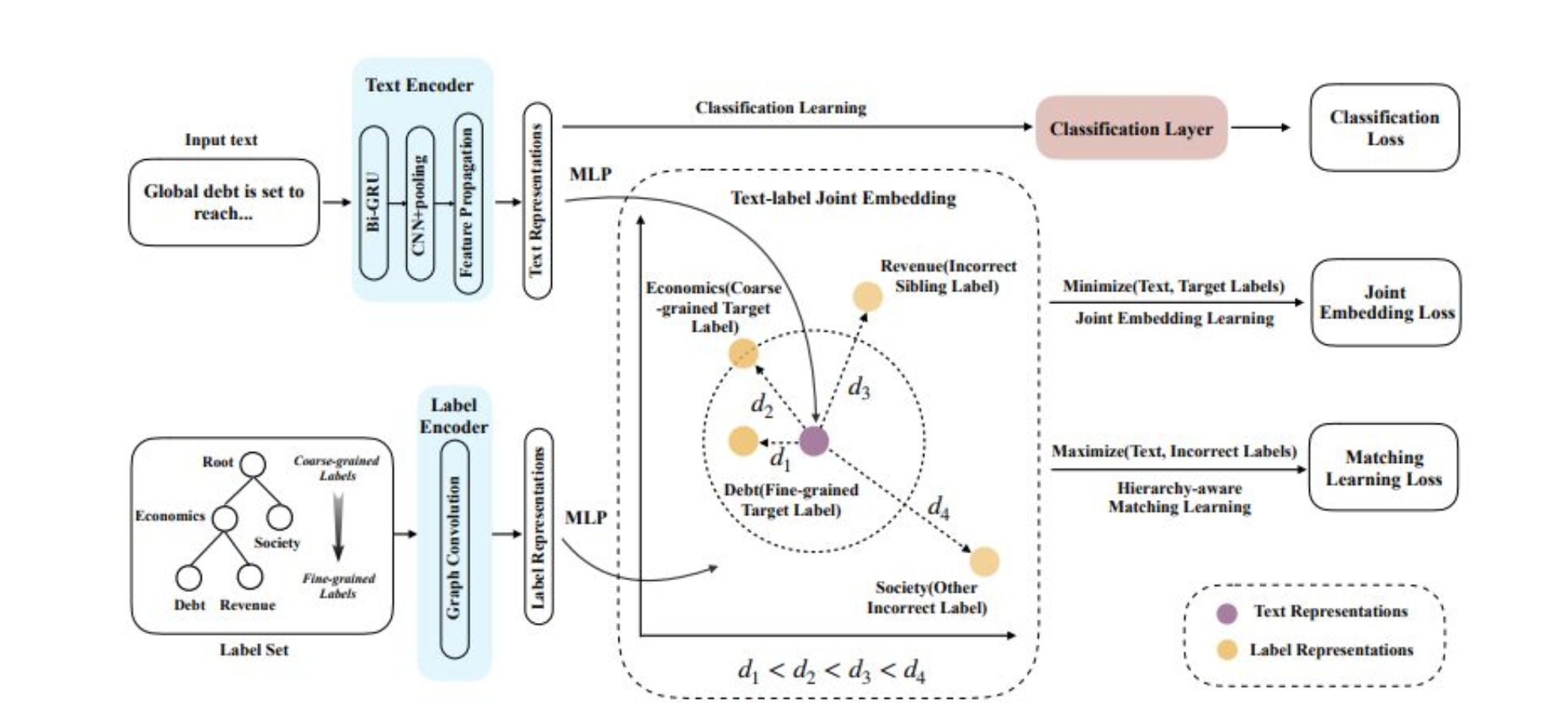
标签表征
具体是一样方式定义一个图 G=(Vl,E→,E←) ,中V_l代表labels表征向量, E→ 表示父节点到子节点的路径, E←表示子节点到父节点的路径。接着同样使用GCN网络进行表征学习: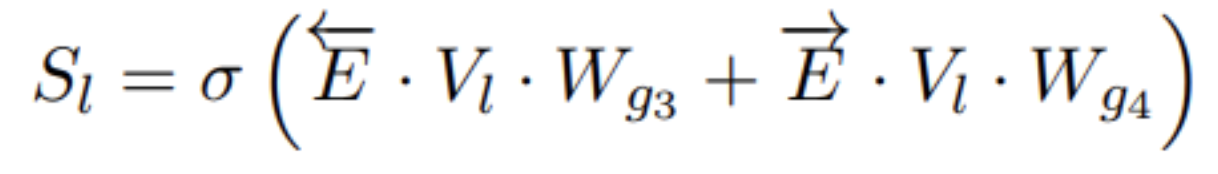
与Text Encoder中GCN不同的是,这里的两个权重维度为d_ld_l。
文本表征
具体流程为:先输入到Bi-GRU进行字的表征学习;然后使用CNN+k-maxpooling方法抽取文本特征T,对应维度为kd_cnn,k为label的数量,d_cnn为卷积后学到的特征数量;最后使用Feature Propagation模块将学习的特征与标签体系的先验信息进行交融学习,得到最终的文本表征向量S_t。
Feature Propagation模块
先利用先验知识将标签体系定义一个图——G=(Vt,E→,E←) ,其中V_t表示label节点集合,E与上述一样,路径上的值是根据数据集统计而来的先验概率,两个路径矩阵对应的维度为kk;接着将CNN网络学到的向量T通过线性转化,嵌入到向量V_t中,对应的维度为d_t,表示文本向量中对应的label节点特征信息;最后使用GCN网络学习到最终的文本表征向量S_t,计算方式如下: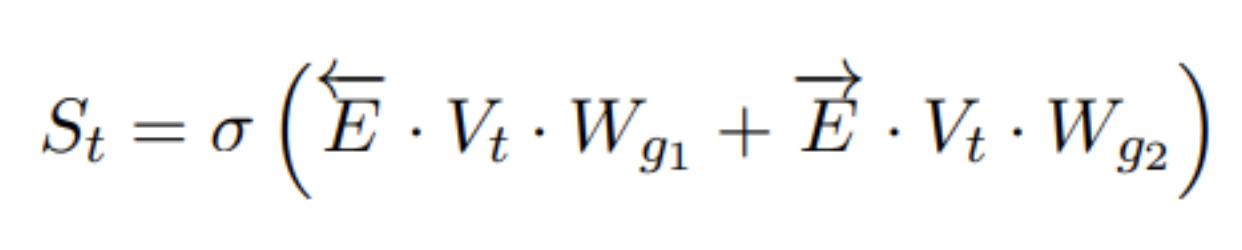
优化目标
目标1 :表征的文本语义向量与它对应的真实label表征的语义向量越近越好。
目标2 *:希望表征的文本向量不仅与对应真实label越近越好,还要与非真实label越远越好,其实就是对比损失。
目标3 :主任务目标函数,二分类交叉熵损失函数
总的优化目标是上述三者之和,再加个系数。
(平行性)多标签文本分类
3种文本多标签分类的方法:
1.改变输出概率(probabilities)的计算方式和交叉熵的计算方式
- tf.nn.sigmoid_cross_entropy_with_logits测量独立不互斥离散分类任务的概率误差,其中每个类是独立的而不是互斥的。这适用于多标签分类问题。label_size:[batchzise,lablesize]
- tf.nn.softmax_cross_entropy_with_logits测量独立互斥离散分类任务的概率误差,其中类之间是互斥的(每个条目恰好在一个类中)。这适用多分类问题。label_size:[batchzise,1]
tf.nn.sparse_softmax_cross_entropy_with_logits是tf.nn.softmax_cross_entropy_with_logits的易用版本,这个版本的logits的形状依然是[batch_size, num_classes],但是labels的形状是[batch_size, 1],每个label的取值是从[0, num_classes)的离散值,这也更加符合我们的使用习惯,是哪一类就标哪个类对应的label。
- 在简单的二进制分类中,sigmoid和softmax没有太大的区别。在多分类的情况下,sigmoid允许处理非独占标签(也称为多标签),而softmax处理独占类。
具体细节参考
ALbert做文本多标签分类任务
- 输入的input相关的embedding有三个(input_ids,input_masks,segment_ids),label是one-hot 形式,[batch_zise,num_labels]。
- 损失函数使用tf.nn.sigmoid_cross_entropy_with_logits,结果是每一个样例的Loss,最后搭配reduce_mean求平均Loss。
- self.probabilities = tf.nn.sigmoid(logits)。在文本分类中,输出概率为tf.nn.softmax(logits, axis=-1);在多标签文本分类中,输出概率为tf.nn.sigmoid(logits)。这样做的原因:在多分类的情况下,sigmoid允许处理非独占标签(也称为多标签),而softmax处理独占类。
对于多分类任务,多元分类是通过tf.argmax(logits)实现,返回的是最大的那个数值所在的label_id。多标签分类,则是判断logist某一个标签对应的维度上的值(输出概率)是否大于0.5,小于0.5时,我们认为它不能作为当前句子的输出标签;反之,如果大于等于0.5,那么它代表了当前句子的输出标签之一。 ```python
Placeholder
self.input_ids = tf.placeholder(tf.int32, shape=[None, hp.sequence_length], name='input_ids')self.input_masks = tf.placeholder(tf.int32, shape=[None, hp.sequence_length], name='input_masks')self.segment_ids = tf.placeholder(tf.int32, shape=[None, hp.sequence_length], name='segment_ids')self.label_ids = tf.placeholder(tf.float32, shape=[None,hp.num_labels], name='label_ids')# Load BERT modelself.model = modeling.AlbertModel(config=bert_config,is_training=self.is_training,input_ids=self.input_ids,input_mask=self.input_masks,token_type_ids=self.segment_ids,use_one_hot_embeddings=False)# Get the feature vector by BERToutput_layer = self.model.get_pooled_output()# Hidden sizehidden_size = output_layer.shape[-1].value #hiddensize,1with tf.name_scope("Full-connection"):output_weights = tf.get_variable("output_weights", [num_labels, hidden_size],initializer=tf.truncated_normal_initializer(stddev=0.02))output_bias = tf.get_variable("output_bias", [num_labels], initializer=tf.zeros_initializer())logits = tf.nn.bias_add(tf.matmul(output_layer, output_weights, transpose_b=True), output_bias)# Prediction sigmoid(Multi-label)self.probabilities = tf.nn.sigmoid(logits) #[num_labels]
with tf.variable_scope("Prediction"):# Predictionzero = tf.zeros_like(self.probabilities)one = tf.ones_like(self.probabilities)self.predictions = tf.where(self.probabilities < 0.5, x=zero, y=one)
```python# Loss and Optimizerif self.is_training:# Global_stepself.global_step = tf.Variable(0, name='global_step', trainable=False)per_example_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=self.label_ids,logits=logits)self.loss = tf.reduce_mean(per_example_loss)# Optimizer BERTtrain_examples = processor.get_train_examples(hp.data_dir)num_train_steps = int(len(train_examples) / hp.batch_size * hp.num_train_epochs)#num_train_steps = 10000num_warmup_steps = int(num_train_steps * hp.warmup_proportion)print('num_train_steps',num_train_steps)self.optimizer = optimization.create_optimizer(self.loss,hp.learning_rate,num_train_steps,num_warmup_steps,hp.use_tpu,Global_step=self.global_step)# Summary for tensorboardtf.summary.scalar('loss', self.loss)self.merged = tf.summary.merge_all()
2、改变输出的全连接层
- 在输出层设置多个全连接层,每一个全连接层对应一个标签。
- 损失函数为所有标签损失函数的平均值。
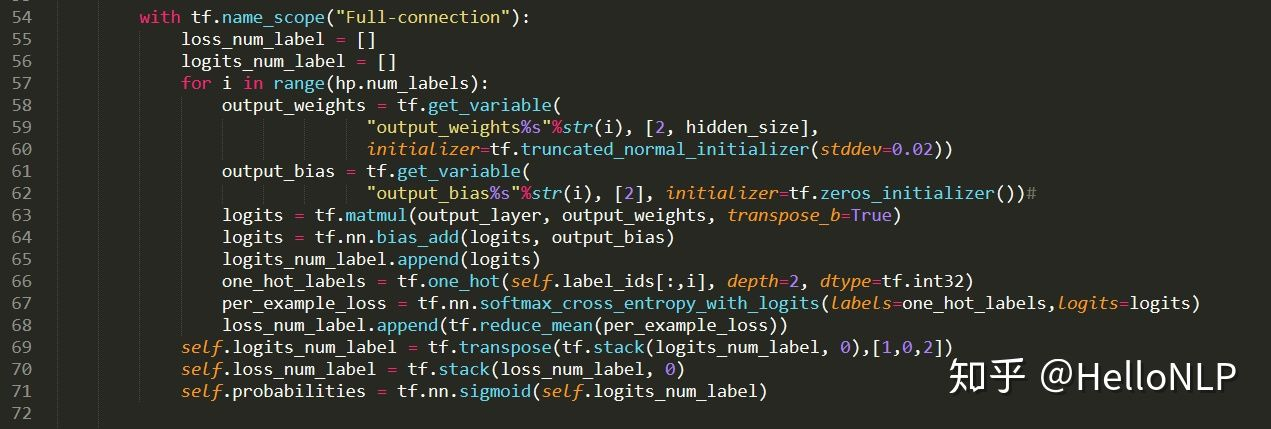
- 在计算损失值时,我们单独计算了每一个标签的损失值。
- 另外,self.probabilities在这里的维度是一个3维向量(batch_size,hp.num_labels,2),而非一个二维向量,即每一个标签都是一个二分类。

由于损失函数使用的是tf.nn.softmax_cross_entropy_with_logits,所以这里我们使用了tf.argmax来计算出预测值。另外,我们可以看出,在使用tf.argmax时,我们是对第3个维度使用了这个函数,这一点和我们平常使用的会有所区别。
3、基于Seq2Seq+Attention框架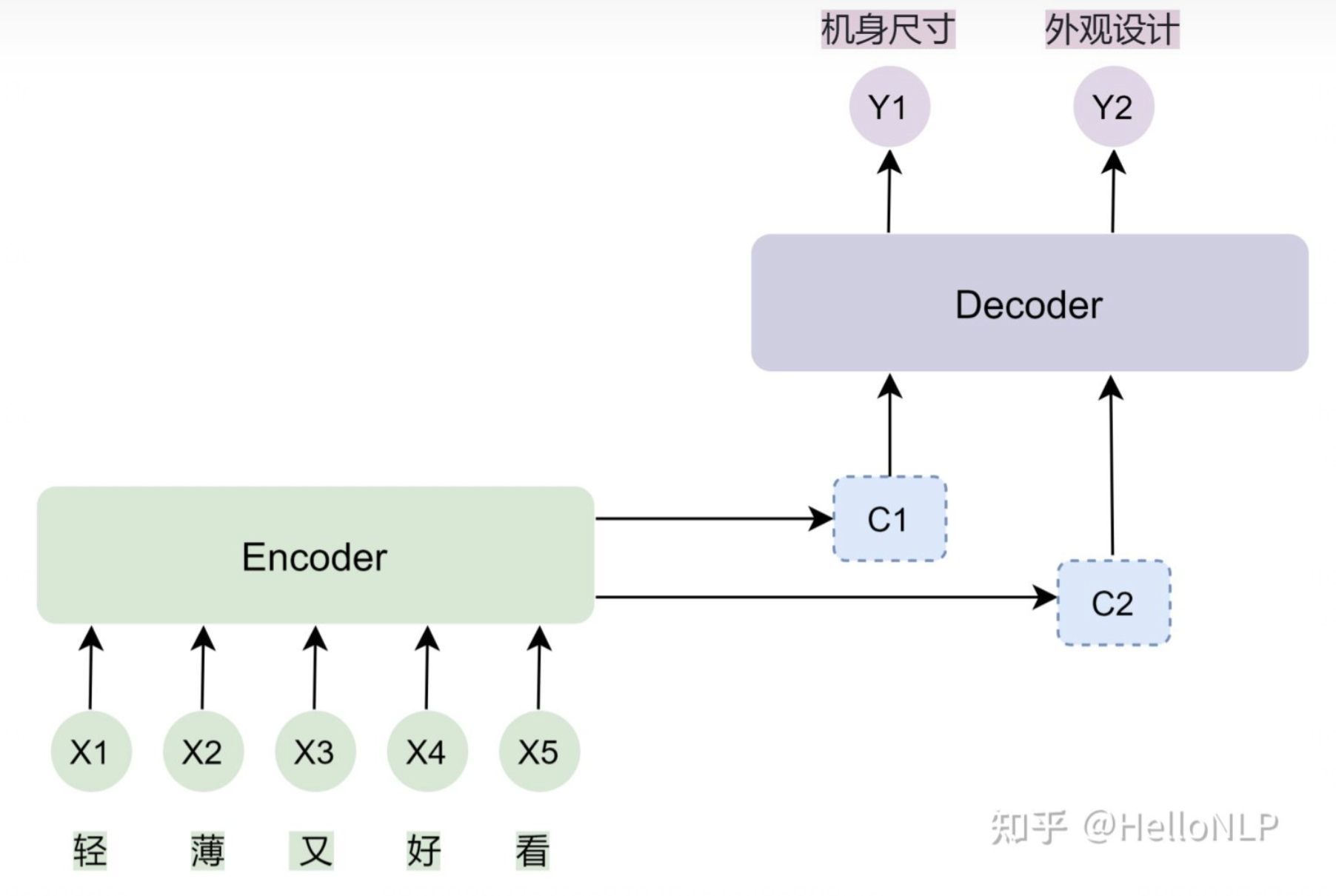
文本分类的数据增强工作
2019年EDA(Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks)论文发表于ICLR 2019,提出了四种数据增强操作:
同义词替换(通过同义词表将句子中的词语进行同义词替换)
随机交换(随机交换句子的两个词语,改变语序)
随机插入(在原始句子中随机插入,句子中某一个词的同义词)
随机删除(随机删除句子中的词语)
EMNLP2021-An Easier Data Augmentation Technique for Text Classification
主要是在原始文本中随机插入一些标点符号,具体策略是随机插入1到三分之一句子长度个数的标点符号,总共有6种。
标签千万级别的文本分类
场景:在不同的购物平台上去爬取商品的文本信息(标题,参数,描述等),不同平台上,同一个商品的文本信息可能不同,现在想把他们识别出来,归成一类。我理解这是一个文本分类的问题,但是商品种类在千万级别,如何分类
思路:针对这种large-scale text classification的场景,label space巨大,学界和工业界目前唯一的方法就是想办法做小一轮分类标签,考虑到label更新速度和人工标注的成本,不得不采用无监督的方法来获得一个分层的label space,常见的方法就是聚类,把语义相近的文本聚在一起,再分类。
优化方法
1.数据增强,如上述论文方法
2.多模型融合,但是带来的是工作量和性能的损失。
3.尽量丰富模型的输入数据的特征,一般的词向量之外,还可以添加一些关键实体,或者针对应用场景,拼接一些要素或者特征,
4.分词和字作为输入,大多数情况下是字的效果更好
5.清除脏数据
问题

若有收获,就点个赞吧
0 人点赞
