主要是识别系统act(注意对象,是系统,而非用户,用户的act是NLU勇于识别用户的意图和槽位),表明在限制条件(之前的累积目标、对话历史等)下系统要执行的动作(接下来的策略)
最新进展
模型概述
1.Value Based DPL
经典之作,2009年的研究,k近邻+ 蒙特卡罗算法+ POMDP(部分可观察马尔可夫决策过程)做DPL。
ref:k-Nearest Neighbor Monte-Carlo Control Algorithm for POMDP-based Dialogue Systems
2.Policy Based DPL
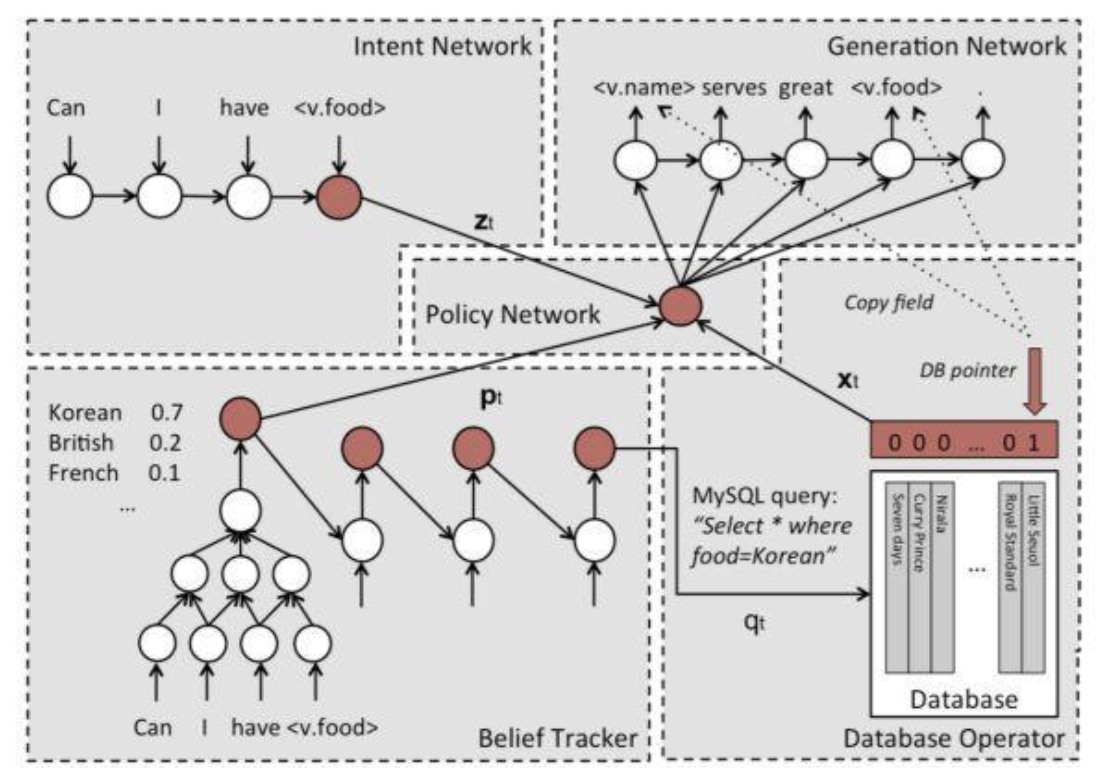
端到端任务型对话的开创性工作之一,同时也是代表性工作之一。
ref:A Network-based End-to-End Trainable Task-oriented Dialogue System
3.基于迁移学习的DPL
ref:Transfer Learning for User Adaptation in Spoken Dialogue Systems
总结:
简单总结下,目前DPL相关的论文其实在任务型对话中相对算少的,至少远远少于NLU和DST,很多方法比较久远,而最新的一些方法又容易忽略DPL(毕竟DPL相比DST更容易点),更甚至很多DPL跟DST或NLG已经joint一起训练和学习了。目前主流的方法是(深度)强化学习。
4.Actor Critic DPL
ref:Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management
5.Online Training DPL

若有收获,就点个赞吧
0 人点赞
