pagerank
PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道有哪些网页链接到网页A,也就是要首先得到网页A的入链,然后通过入链给网页A的投票来计算网页A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。那么根据以上思想,佩奇设计了下面的公式: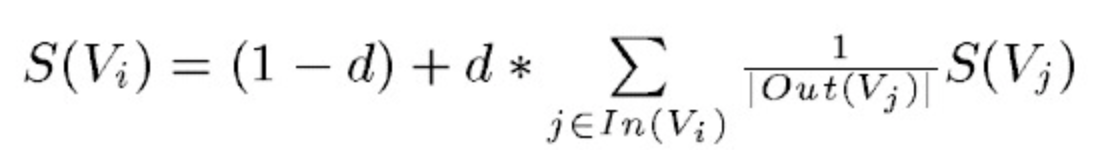
该公式中,Vi表示某个网页,Vj表示链接到Vi的网页(即Vi的入链),S(Vi)表示网页Vi的PR值,In(Vi)表示网页Vi的所有入链的集合,Out(Vj)是网页j中的链接存在的链接指向的网页的集合。|Out(Vj)|是集合中元素的个数。d表示阻尼系数,是用来克服这个公式中“d ”后面的部分的固有缺陷用的:如果仅仅有求和的部分,那么该公式将无法处理没有入链的网页的PR值,因为这时,根据该公式这些网页的PR值为0,但实际情况却不是这样,所有加入了一个阻尼系数来确保每个网页都有一个大于0的PR值,根据实验的结果,*在0.85的阻尼系数下,大约100多次迭代PR值就能收敛到一个稳定的值,而当阻尼系数接近1时,需要的迭代次数会陡然增加很多,且排序不稳定。公式中S(Vj)前面的分数指的是Vj所有出链指向的网页应该平分Vj的PR值,这样才算是把自己的票分给了自己链接到的网页。
初始化:页面i连接到页面j的概率,也就是M[i][j]。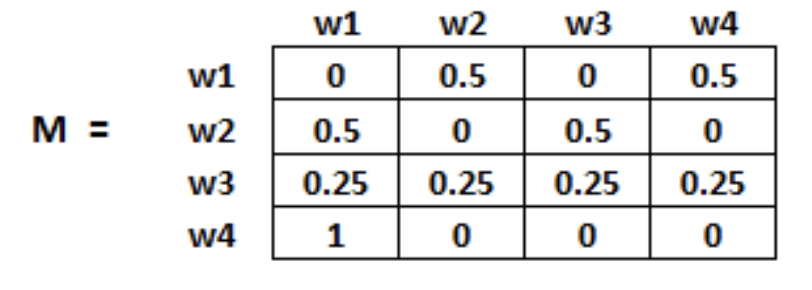
具体迭代计算参考:https://zhuanlan.zhihu.com/p/126733456
TextRank
关键词提取任务
算法详情:
1. 文本分割成单个句子,消去文本噪音(标点符号,数字,停用词等等);
2. 通过共现关系构造共现矩阵,计算相似矩阵。
3.迭代传播各节点的权重,直至收敛。
4.对节点权重进行排序,从而得到最重要的T个单词,作为候选关键词。
def word_adj_matrix(words_pro, windows, word_num, word_index):"""Adjacency Matrix:param windows::return:"""def _word_combine(words, window):"""Keyword arguments::param window:"""if window < 2: window = 2for x in range(1, window):if x >= len(words):breakwords2 = words[x:]res = zip(words, words2)for r in res:yield rmatrix = np.zeros((word_num, word_num))for words in words_pro:for w1, w2 in _word_combine(words, windows):if w1 in word_index and w2 in word_index:index1 = word_index.get(w1)index2 = word_index.get(w2)matrix[index1][index2] = 1.0matrix[index2][index1] = 1.0return matrix
关键句提取任务
算法详情:
1. 第一步是把所有文章整合成文本数据;
2. 接下来把文本分割成单个句子,消去文本噪音(标点符号,数字,停用词等等);
3. 然后,我们将为每个句子找到向量表示(词向量);
4. 计算句子向量间的相似性并存放在矩阵中;
5. 然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算;
6. 最后,一定数量的排名最高的句子构成最后的摘要。
句子向量间的相似性计算
1.通过句子中的词语共现数,计算句子相似性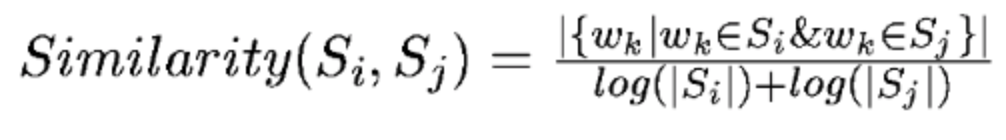
def _get_similarity(word_ls1, word_ls2):co_occur_num = len(set(word_ls1) & set(word_ls2))if abs(co_occur_num) <= 1e-12:return 0.if len(word_ls1) == 0 or len(word_ls2) == 0:return 0.denominator = math.log(float(len(word_ls1))) + math.log(float(len(word_ls2)))if abs(denominator) < 1e-12:return 0.return co_occur_num / denominator
2.各种词向量( word2vec,fasttext, glove)的加和计算相似度。
计算 textrank 分数
def cal_score(ad_matrix, alpha=0.85, max_iter=100):N = len(ad_matrix)if N == 0 :scores = dict()return scoresad_sum = ad_matrix.sum(axis=0).astype(float)ad_sum[ad_sum == 0.0] = 0.001ad_matrix = ad_matrix / ad_sumpr = np.full([N, 1], 1 / N)for _ in range(max_iter):pr = np.dot(ad_matrix, pr) * alpha + (1 - alpha)pr = pr / pr.sum()scores = dict(zip(range(len(pr)), [i[0] for i in pr]))return scores

若有收获,就点个赞吧
0 人点赞
