最新进展
在 AAAI2021 上同样涌现了许多关于机器翻译任务的研究工作,几乎所有的工作都是基于Transformer模型展开讨论。这里对机器翻译在AAAI2021上的最新研究进展进行总结:
无监督机器翻译-低资源语种翻译
无监督机器翻译同样是机器翻译中备受关注的研究热点。在现实世界中,除了部分富资源语言(如英语,汉语,德语,俄语,印地语等),更多的语言本身缺乏海量的双语语料进行监督学习。因此,如何在这种资源匮乏,甚至零资源的条件下,学习语言之间的映射是极具挑战的。目前无监督机器翻译通常采用迭代式的back-translation。此外,利用预训练的技术手段能够有效地加快模型的收敛,提高翻译的正确性。[2]通过在构造伪数据的过程中对合成的句子进行正则化约束能够有效地改善翻译的性能。
[2]Empirical Regularization for Synthetic Sentence Pairs in Unsupervised Neural Machine Translation
多语言翻译-多语种翻译
多语言模型通过一个模型实现多个语种之间的翻译能够有效降低多语言翻译部署成本。同时将一种源语言翻译成多种不同的目标语言是多语言翻译最常见的场景之一。SimNMT[3]提出了一种同步交叉交互解码器,即在每个目标语生成时,可以依赖未来的信息,以及其他目标语言的历史和未来的上下文信息,充分利用语言内与语言间的信息。
[3]Synchronous Interactive Decoding for Multilingual Neural Machine Translation
语音翻译-语音到文本的翻译
语音翻译(Speech-to-text)直接将源语的语音翻译成目标语言的文本。传统方法中,采用语音识别和机器翻译级联的方法来解决这一问题。但是具有延迟高,占用存储大,以及容易产生错误累积的问题,很多工作开始关注直接使用端到端的语音到文本的模型来解决这一问题。对于跨模态之间的语言映射,为了让单一的模型充分学习模态之间的关联信息往往需要引入更多的跨模态和跨语言的特征,造成了沉重的负担,同时单纯的用于端到端模型的语音到文本数据较少,无法充分利用语言识别和机器翻译的数据。为了解决这些问题,COSTT[4]作为一种通用的框架同时结合了级联模型与端到端模型的优点,能够更好地利用大规模双语平行语料,在多个测试集上取得了最优的效果。
[4]Consecutive Decoding for Speech-to-text Translation
领域适应-微调
在神经机器翻译中,通过微调来做领域的迁移是一种常见的方法。但是,无约束的微调需要非常仔细的超参数调整,否则很容易在目标域上出现过拟合,导致在通用领域上的性能退化。PRUNE-TUNE[5]是一种基于渐变修剪的领域适应算法。它学习微小的特定于领域的子网以进行调优,通过调整它相应的子网来适应一个新的领域。有效缓解了在微调过中的过拟合和退化问题。
[5]Finding Sparse Structure for Domain Specific Neural Machine Translation
解码加速-轻量模型/非自回归解码
过参数化的(超大规模)模型能够有效提升神经机器翻译的性能,但是庞大的存储开销和高昂的计算复杂度使得这类模型无法直接部署到边缘设备(如手机,翻译笔,离线翻译机等)上。早期为了提高模型对未登录词的覆盖度往往使用更大的词表,同时增大了词嵌入矩阵的存储开销,以及构建词表上概率分布时对计算资源的消耗。针对该问题,Partial Vector Quantization[8]提出了一种部分矢量量化的方法,通过压缩词嵌入降低softmax层的计算复杂度,同时使用查找操作来替换softmax层中的大部分乘法运算,在保障翻译质量的同时大大减少了词嵌入矩阵的参数和softmax层的计算复杂度。
GPKD[9]中提出一种基于群体置换的知识蒸馏方法将深层模型压缩为浅层模型,该方法可以分别应用与编码端与解码端达到模型压缩和解码加速的目的。文中探讨了一种深编码器-浅解码器的异构网络, 其既能保证翻译的准确度,同时满足工业生产的推断时延需求。此外采用子层跳跃的正则化训练方法缓解随着网络加深带来的过拟合问题。
此外,沿着减少解码端计算复杂度的研究方向,例如Averaged Attention Network(ACL2018)和Sharing Attention Network(IJCAI2019),Compressed Attention Network[10]采取压缩子层的方式,将解码器每一层中分离的多个子层压缩成一个子层,进而简化解码端的计算复杂度,达到解码加速的目的。
[8]Accelerating Neural Machine Translation with Partial Word Embedding Compression [9]Learning Light-Weight Translation Models from Deep Transformer [10]An Efficient Transformer Decoder with Compressed Sub-layers
评测方法及应用
除了针对机器翻译系统的研究外,如何有效的评估机器翻译系统的性能也是一个重要的研究方向。通常情况下我们使用BLEU作为译文质量评估的常用指标,但是在很多应用场景中,并没有可以对比的参考译文。机器翻译质量评估(QE)便是在不依赖任何参考译文的情况下预测机器翻译质量的一项任务。在QE任务中,通常使用预测器-估计器框架(Predictor-Estimator)。使用预训练的预测器作为特征提取器,再通过评估器对译文进行评估。但是预测器和估计器在训练数据和训练目标上都存在差距,这使得QE模型不能更直接地从大量平行语料库中受益。DirectQE[12]中提出了一个新框架,通过生成器在构造QE伪数据,使用额外的探测器在生成的数据上进行训练,并为QE任务设定了新的学习目标,将原本分离的过程进行整合。
[12] DirectQE: Direct Pretraining for Machine Translation Quality Estimation
挑战
- 漏译
- 数据稀疏
- 引入知识-就是新词引入
- 融合知识
- 语篇翻译
模型概述
机器翻译是经典的采用seq2seq框架的模型,基于RNN的Seq2seq框架
基于Transformer的Seq2seq框架
详解查看Transformerdetails
beam search
在解码decode截断,使用贪心策略,每次用当前输出最大的概率预测词作为下一个预测结果。但是解码过程中只要有一步出错,会导致错误累积越多,越后的解码离正确的越远,这也就是beam search搜索出现的原因,在beam search中,解码截断的每个step提供会保留多个选择,最终选择最好的一个序列。
我们希望找到一个最大的p ( y ∣ x ) p(y|x)p(y∣x),其中p ( y ∣ x ) p(y|x)p(y∣x)的计算形式如下: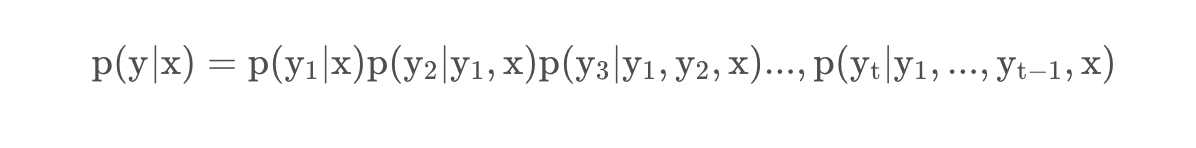
而beam search在解码的每一步只需要保留k 个最大概率的翻译序列部分。k 是beam size,虽然没法保证全局的最优,但是却十分高效。
attention
attention的核心思想是在decoder解码的每一个step,关注源目标句子最相关的部分,这部分叫做context向量,在解码的每一个步骤,context向量都是动态计算出来的,主要是通过decoder阶段上一个时刻step (或者当前step) RNN的hidden向量与encoder的所有step的hidden 向量计算attention权重,然后得到加权后的context向量。
在Seq2Seq结构中,encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由Decoder解码。由于context包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个Context可能存不下那么多信息,就会造成精度的下降。除此之外,如果按照上述方式实现,只用到了编码器的最后一个隐藏层状态,信息利用率低下。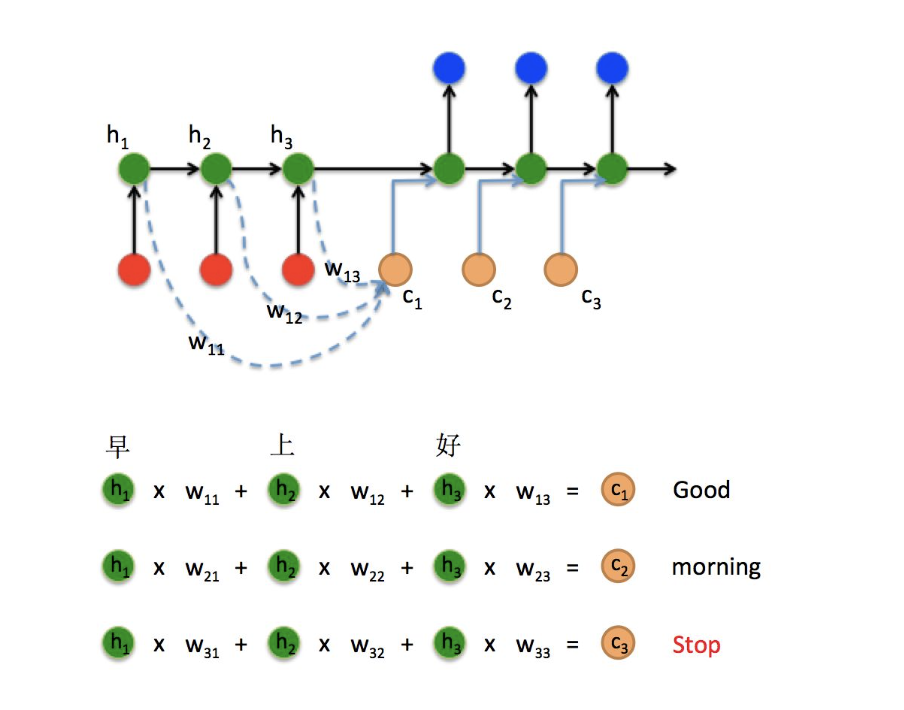

attention公式:https://zhuanlan.zhihu.com/p/51383402
资源记录
- Hugging Face (抱抱脸)标星 26.9k 的 Transformer 项目。在最新更新的版本里,抱抱脸发布了 1008 种模型,正式涉足机器翻译领域。
code:https://github.com/huggingface/transformers
- 机器翻译界的BERT
EMNLP2020的一篇关于多语言翻译新范式的工作multilingual Random Aligned Substitution Pre-training (mRASP),核心思想就是打造“机器翻译界的BERT”,通过预训练技术再在具体语种上微调即可达到领先的翻译效果,其在32个语种上预训练出的统一模型在47个翻译测试集上取得了全面显著的提升。
code:https://github.com/linzehui/mRASP.git

若有收获,就点个赞吧
0 人点赞
