概述
Attention机制的核心在于对一个序列数据进行聚焦,这个聚焦是通过一个概率分布来实现的。这种机制其实有很强的普适性,可以用在各个方面。
在NLP中,有三个关键术语,
- Query:问句,简称Q,如“小明喜欢什么颜色的衣服?”
- Key:问句的关键词,简称K,类似搜索引擎的关键字,用于检索,如“小明 喜欢 颜色 衣服”
- Value:问题对应的答案,简称V,如“小明喜欢红色衣服”
Attention在各任务中的应用:
原理解释
各类attention有很多,但总体的建模方式如下:
- 相似度计算:query 和 key 进行相似度计算,得到权值(概率)。
- 归一化:将权值通过softmax进行归一化,得到直接可用的权重
- 加权求和:将权重和 value 进行加权求和
其中相似度计算的变种有很多,👇计算相似度的过程也有很多场景会称之为对齐模型,常见如下:
- dot:点积,点积的形式一半要求相乘的两个矩阵长度相同,另外一种变形就是点积之后加一个缩放因子(transform中的形式);
- general:常用于输入输出维度不对等,使用中间矩阵相乘将其对齐,Wa是可训练的权重矩阵;
- concat:二者进行拼接后,使用 tanh 函数进行激活。va和Wa都是可以训练的参数。也就是另外一种叫法,加性attention,tanh里面的内容还可以是W1ht+W2hs,本质上没什么区别。另外的三种是乘法attention。乘法attention的
- cosine:
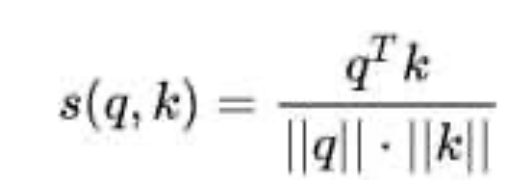 。
。


假设eij=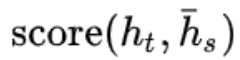 ,e**ij**表示decoder端生成位置i的词时,有多少程度受encoder端的位置j的词影响。
,e**ij**表示decoder端生成位置i的词时,有多少程度受encoder端的位置j的词影响。
参考:
attention分类
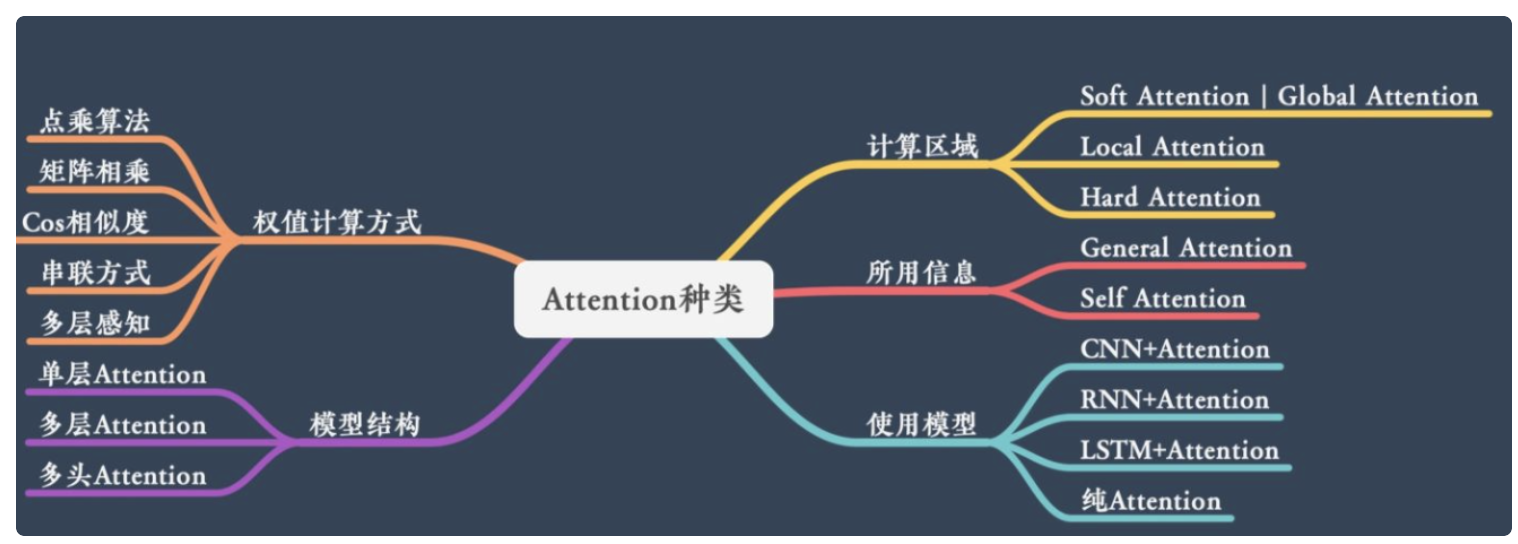
根据attention计算区域,可分成 soft attention 、hard attention、local attention
1)soft attention :对所有 key 求权重概率,每个 key 都有一个对应的权重,是一种全局的计算方式。这种方式参考所有 key 的内容,在进行加权,但是计算量大。
2)hard attention: 直接精准定位到某个 key ,其余 key 不管,相当于这个 key 的概率是1,其余key 的概率是0
计算区域
1)local attention :对一个窗口区域进行计算,有位置变量 pt 和窗口大小D,其中 pt 有两种,一种是固定的,一种是根据decoder 的hidden层预测的。以pt 这个点为中心可以得到一个窗口区域,在这个小区域内用 softmax 方式计算attention.
2)global attention :Global Attention考虑当前的目标解码隐层状态和所有编码隐层状态(hidden state),来得到 ct ,缺点是计算时的花销太大,每次解码目标词,都要计算所有的编码隐层向量,在翻译或处理长文本序列时计算代价高。
global attention 应用更广:
1、当encoder句子不是很长时,相对Global Attention,计算量并没有明显减小。
2、位置向量pt的预测并不非常准确,这就直接计算的到的local Attention的准确率。
所用信息
要计算一段原文的attention,那么所用信息包括内部信息和外部信息,内部信息:原文本身的信息,外部信息:除原文以外的额外信息。
General attention
用的是外部信息,常用于需要构建两段文本关系的任务,query 一般包含额外信息,根据外部query 对原文进行对齐。得到的结果是源端的每个词与目标端每个词之间的依赖关系。
Self-attention
只是用内部信息。key,value,query 只和输入原文有关,在self attention中,key=value=query。获得源端或目的端各自的词与词的依赖关系。
具体过程就是:将输入经过三个不同权重的权重矩阵,进行线性变化的到Q,K,V,将Q,K 点乘,得到输入Input词与词之间的依赖关系,再进行尺度变化,掩码(在decoder 保证句子中当前词不受后边词影响,在encoder中是为了在一个batch 计算中,避免把注意力关注到用于补全长度时padding的文本上),softmax
https://www.yuque.com/caserwin/dbbzw2/th3bwc#sOwcD
缩放点击注意力机制,self-attention 就是采用了Scaled Dot-Product 的形式。
另外一种就是additive attention ,区别就在于, Dot-Product attention要求K,Q长度一致,additive attnetion 长度可以不一致。
Multi-Head attention
每一个Multi-Head Attention单元由多个结构相似的Scaled Dot-Product Attention单元组成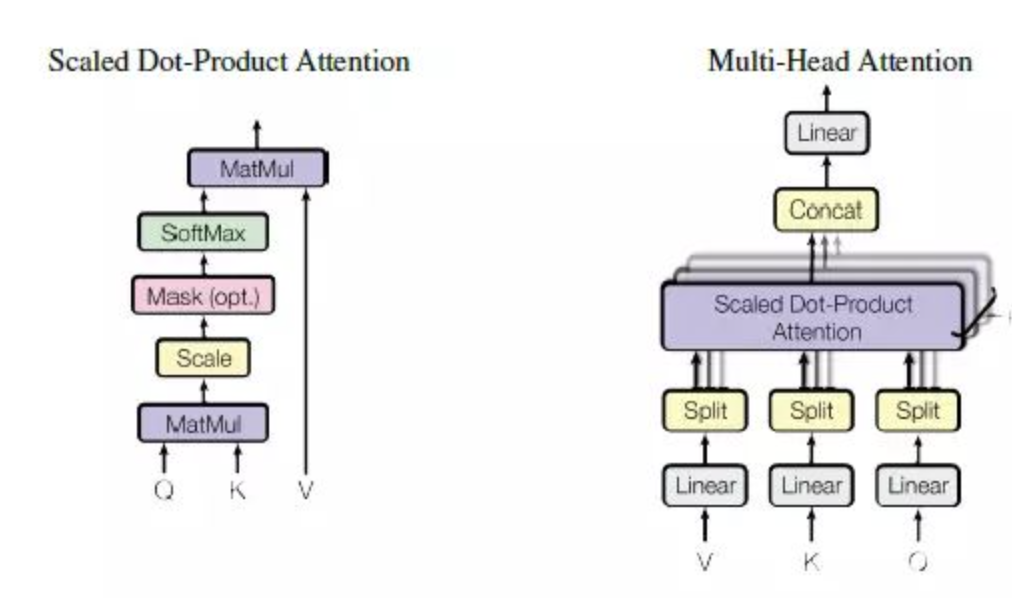

结构层次
1)单层attention:用一个query 对一段原文进行一次 attention。
2)多层attention:一般用于文本具有层次关系的模型,假设把一个document 划分成多个句子,在第一层,分别对每个句子使用attention计算出一个句向量,在第二层,对所有句向量做attention计算出一个文档向量,再用这个文档向量做任务。也就是word sttention 和sentence attention。
3)多头attention(multi-head attention):用多个query对一段原文进行多次attention ,每个query都关注到原文的不同部分,相当于重复做多次单层attention。
模型方面
CNN+attention:
CNN本身的卷积操作就可以提取重要特征,和attention思想相同,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。Max Pooling直接提取数值最大的特征,也像是hard attention 的思想。
CNN上加Attention可以加在这几方面:
a. 在卷积操作前做attention,比如在文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
b. 在卷积操作后做attention,对两段文本的卷积层的输出做attention,作为pooling层的输入。
c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
RNN+attention
LSTM/GRU内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
常用方式有:
a. 直接使用最后的hidden state(可能会损失前文信息,难以表达全文)
b. 对所有step下的hidden state 等权平均(对所有step一视同仁)
c. 对所有step 的hidden state 进行加权,把注意力集中到整段文本中比较重要的hidden state 信息,性能比前面两种好一点,但是要小心过拟合,还增加了计算量。
更近一步的,还有结合LSTM的Attention over attention,典型的模型结构如文本分类中的HAN模型。分别在word-level 和 document-level计算权重信息。
Transform-纯attention
主要采用一种自注意力机制的深度学习模型,这一机制可以按输入数据各部分重要性的不同而分配不同的权重。
问题
1.Attention是如何利用中间的输出的,在encoder-decoder 中:
参考机器翻译中的attention
2.为什么要引入self-attention
rnn的训练速度会受到时序结构的影响,Attention模型本身可以看到全局的信息,可以使训练并行化,
3.attention比LSTM好的点
LSTM本身有门机制,就是一种attention的思想,也可以捕捉长依赖信息,但是需要一步一步去捕捉序列信息,attention在捕捉全局信息的同时可以并行计算,所以这是attention的优点。
2.https://www.yuque.com/liwenju/kadtqt/ulavrv#ositsv中的self-attention和transformer里的self attention不一样。
4.你怎么看attention
attention对于序列数据可以聚焦序列中的重要信息,这种关注是通过权重矩阵来实现的,在encoder -decoder 的结构中能够提升效果,在各种任务中具有很好的普适性,应用比较广泛。
5.self attention, soft-attention, hard-attention, 具体用什么attention和什么有关分别适用的场合是什么
6.有没有需要掌握的公式
计算对齐函数(相似度矩阵)的三种方法:点乘,矩阵映射,concat
缩放点成注意力的公示:注意是:QKT
7.为什么叫做对齐函数/模型
其实就是相似度的计算方式,为什么包含对齐的含义呢,是因为eij表示一个对齐模型,用于衡量encoder端的位置j个词,对于decoder端的位置i个词的对齐程度(影响程度),也就是decoder端生成位置i的词受encoder位置j的词的影响程度。

若有收获,就点个赞吧
0 人点赞
