https://www.yuque.com/yahan/mztcmb/qc76a5#a3OyE
bert有两个阶段:预训练(Pre-training)和微调(Fine-tuning)
预训练模型
关于NLP领域的预训练发展史,张俊林博士写过一篇很详实的介绍
张俊林. 从Word Embedding到BERT模型—自然语言处理中的预训练技术发展史. https://zhuanlan.zhihu.com/p/49271699
word2vec:无法解决多义词的问题
ELMO(2018):双向bi-LSTM,解决多义词,但是抽取器选的不好(transformer(2017)远好于Bilstm)
GPT:单向transformer(并行+抽取能力强),缺点非双向(Bert出来之后的缺点显现)
Bert预训练
任务一:masked language model
就是随机遮盖或替换一句话里面的任意字或词,然后让模型通过上下文预测那一个被遮盖或替换的部分,之后做 Loss 的时候也只计算被遮盖部分的 Loss,这其实是一个很容易理解的任务,实际操作如下:
1. 随机把一句话中 15% 的 token(字或词)替换成以下内容:
a.这些 token 有 80% 的几率被替换成 [MASK],例如 my dog is hairy→my dog is [MASK]
b.有 10% 的几率被替换成任意一个其它的 token,例如 my dog is hairy→my dog is apple
c.有 10% 的几率原封不动,例如 my dog is hairy→my dog is hairy
2.之后让模型预测和还原被遮盖掉或替换掉的部分,
计算损失的时候,只计算在第 1 步里被随机遮盖或替换的部分,其余部分不做损失,其余部分无论输出什么东西,都无所谓
任务二:next sentence prediction
选择一些句子对 A 与 B,其中50% 的数据 B 是 A 的下一条句子,剩余 50% 的数据B 是语料库中随机选择的,学习其中的相关性,添加这样的预训练的目的是为了理解两个句子之间的关系。添加了两个特殊的Token,分别是[CLS]和[SEP]。
Bert 输入:
Token Embedding 就是正常的词向量,即 PyTorch 中的 nn.Embedding()
Segment Embedding 的作用是用 embedding 的信息让模型分开上下句,我们给上句的 token 全 0,下句的 token 全 1。
Position Embedding 和 Transformer 中的不一样,不是三角函数,而是学习出来的。
Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,但是后续一些新的研究[15]发现,去掉NSP任务之后模型效果没有下降甚至还有提升。我们在预训练过程中也发现NSP任务的准确率经过1-2个Epoch训练后就能达到98%-99%,去掉NSP任务之后对模型效果并不会有太大的影响。
[15] Liu, Yinhan, et al. “Roberta: A robustly optimized BERT pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
Multi-Task Learning
BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加,例如
任务一,因为它是一个词典大小 |V| 上的多分类问题,所用的损失函数叫做负对数似然函数(且是最小化,等价于最大化对数似然函数)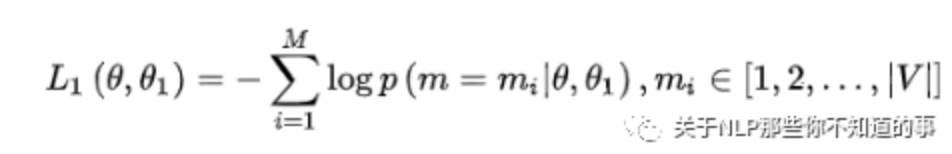
任务二,在句子预测任务中,也是一个分类问题的损失函数: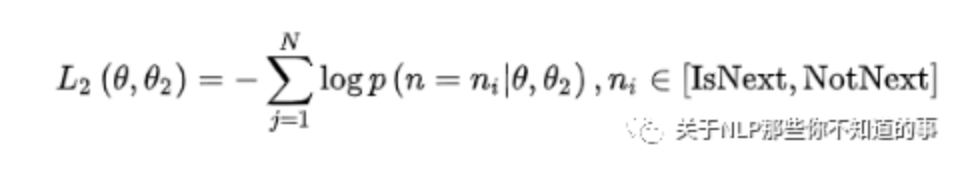
- 两个任务联合学习的损失函数是:
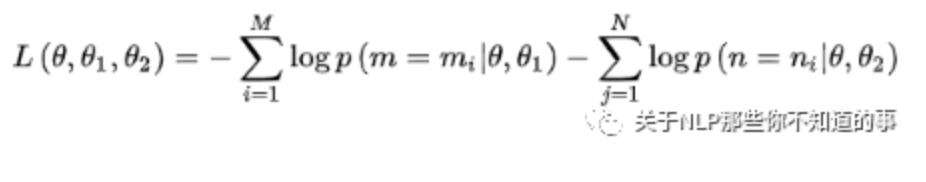
Input:[CLS] calculus is a branch of math [SEP] panda is native to [MASK] central china [SEP]Targets: false, south----------------------------------Input:[CLS] calculus is a [MASK] of math [SEP] it [MASK] developed by newton and leibniz [SEP]Targets: true, branch, was
Bert参数
 :transformer层12,隐藏层大小768,多头注意力个数12,总共1.1亿参数
:transformer层12,隐藏层大小768,多头注意力个数12,总共1.1亿参数 :transformer层24,隐藏层大小1024,多头注意力个数16,总共3.4亿参数
:transformer层24,隐藏层大小1024,多头注意力个数16,总共3.4亿参数
Bert输入的长度限制是512,这个12层指的是encoder中block的个数。
数据&算力
Google发布的英文BERT模型使用了BooksCorpus(800M词汇量)和英文Wikipedia(2500M词汇量)进行预训练,所需的计算量非常庞大。BERT论文中指出,Google AI团队使用了算力强大的Cloud TPU进行BERT的训练,BERT Base和Large模型分别使用4台Cloud TPU(16张TPU)和16台Cloud TPU(64张TPU)训练了4天(100万步迭代,40个Epoch)。但是,当前国内互联网公司主要使用Nvidia的GPU进行深度学习模型训练,因此BERT的预训练对于GPU资源提出了很高的要求。
Bert 微调
一般流程
1.下载预训练模型
预训练需要巨大的计算资源,所以google 提供了预训练的模型,获取途径:
https://blog.csdn.net/jiaowoshouzi/article/details/89388794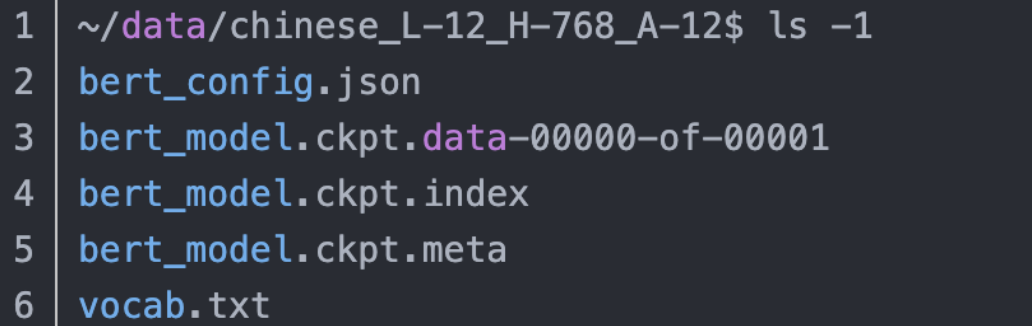
vocab.txt:模型的词典
bert_config.json :是bert的配置(超参数),比如网络的层数,通常不需要修改,但是会经常用到。
bert_model.ckpt*:是预训练好的模型的checkpoint
2.修改数据读入
修改 processor 字典,注意开源的bert 项目输入最大长度限制在512.
3.分析任务类型
run_classifier.py可以用于微调
def get_masked_lm_output(): 计算masked language model这一任务的loss
def get_next_sentence_output(): 计算next sentence prediction这一任务的lossdef get_sequence_output(): def get_sequence_output: 实际上获取的是encoder端最后一层编码层的特征向量。
with tf.variable_scope("encoder"):# This converts a 2D mask of shape [batch_size, seq_length] to a 3D# mask of shape [batch_size, seq_length, seq_length] which is used# for the attention scores.attention_mask = create_attention_mask_from_input_mask(input_ids, input_mask)# Run the stacked transformer.# `sequence_output` shape = [batch_size, seq_length, hidden_size].self.all_encoder_layers = transformer_model(input_tensor=self.embedding_output,attention_mask=attention_mask,hidden_size=config.hidden_size,num_hidden_layers=config.num_hidden_layers,num_attention_heads=config.num_attention_heads,intermediate_size=config.intermediate_size,intermediate_act_fn=get_activation(config.hidden_act),hidden_dropout_prob=config.hidden_dropout_prob,attention_probs_dropout_prob=config.attention_probs_dropout_prob,initializer_range=config.initializer_range,do_return_all_layers=True)self.sequence_output = self.all_encoder_layers[-1]
def get_pooled_output():实际上获取的是[CLS]这个token对应的向量,把它作为整个句子的特征向量。
with tf.variable_scope("pooler"):# We "pool" the model by simply taking the hidden state corresponding# to the first token. We assume that this has been pre-trainedfirst_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)self.pooled_output = tf.layers.dense(first_token_tensor,config.hidden_size,activation=tf.tanh,kernel_initializer=create_initializer(config.initializer_range))
# for classification task# [batch_size, hidden_size]output_layer = model.get_pooled_output()# for seq2seq or ner task to get token-level output# [batch_size, seq_length, hidden_size]output_layer = model.get_sequence_output()
四类任务
任务1:句子分类
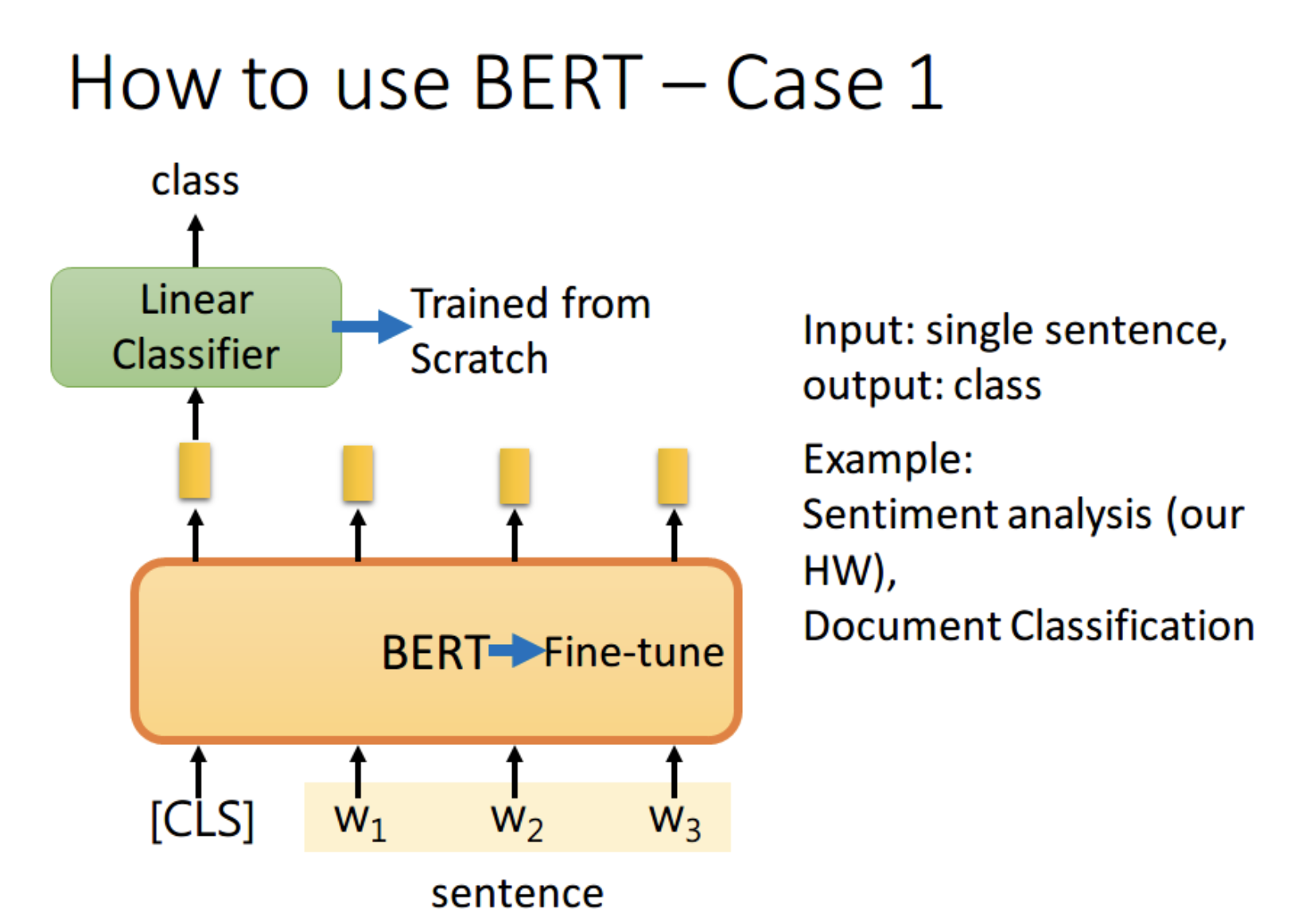
一般是选用get_pooled_output()获得[CLS]这个token对应的向量,扔给线性分类器,让其 predict 一个 class 即可。
当然也可以将所有词的 output 进行 concat,作为最终的 output。
任务2:序列标注
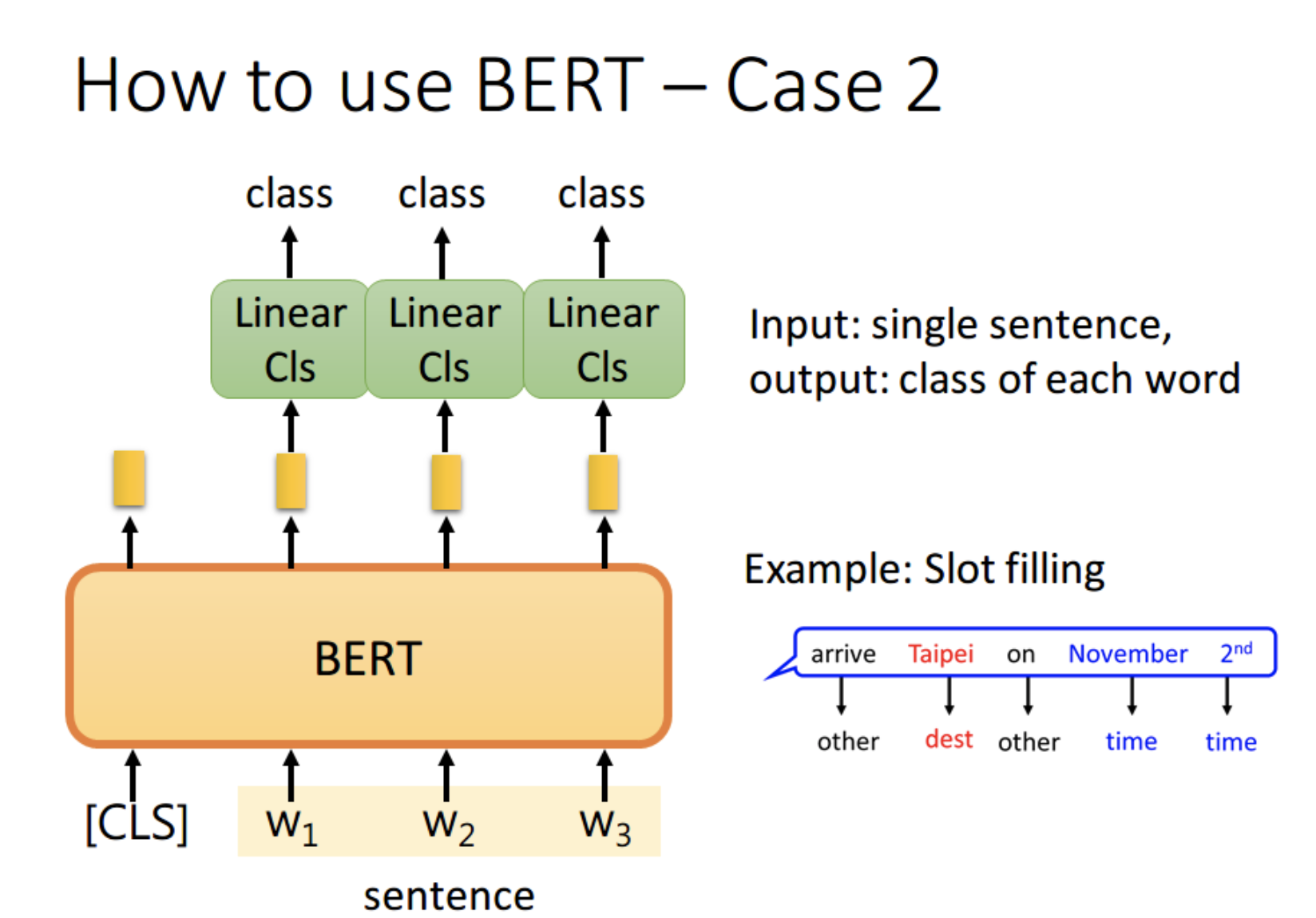
比如Slot Filling任务,句子中各个字对应位置的 output 分别送入不同的 Linear,预测出该字的标签。
其实这本质上还是个分类问题,只不过是对每个字都要预测一个类别。
任务3:自然语言推理
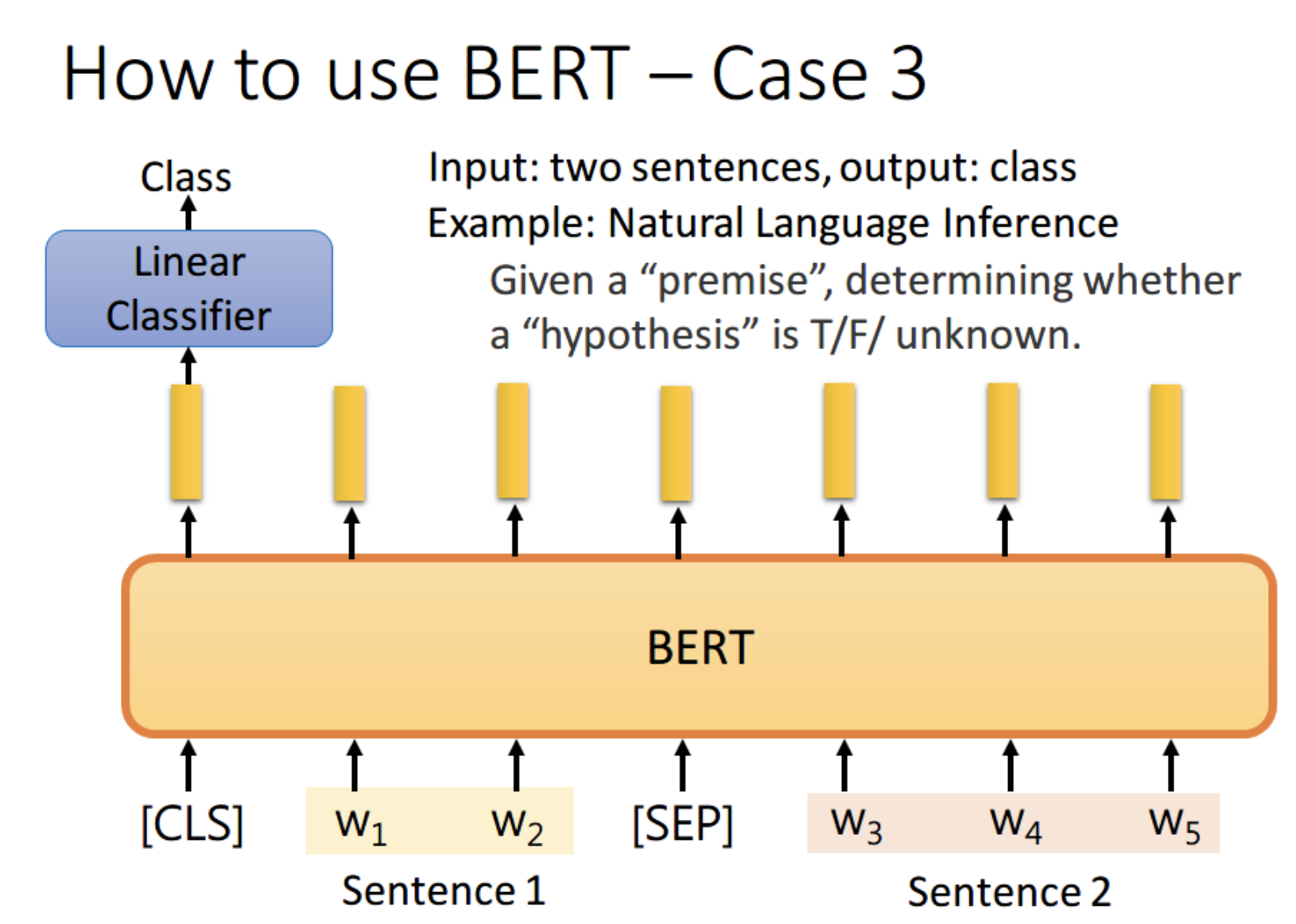
如果现在的任务是 NLI(自然语言推理)。即给定一个前提,然后给出一个假设,模型要判断出这个假设是 正确、错误还是不知道。这本质上是一个三分类的问题,和 Case 1 差不多,对 [CLS] 的 output 进行预测即可。
任务4:问答任务
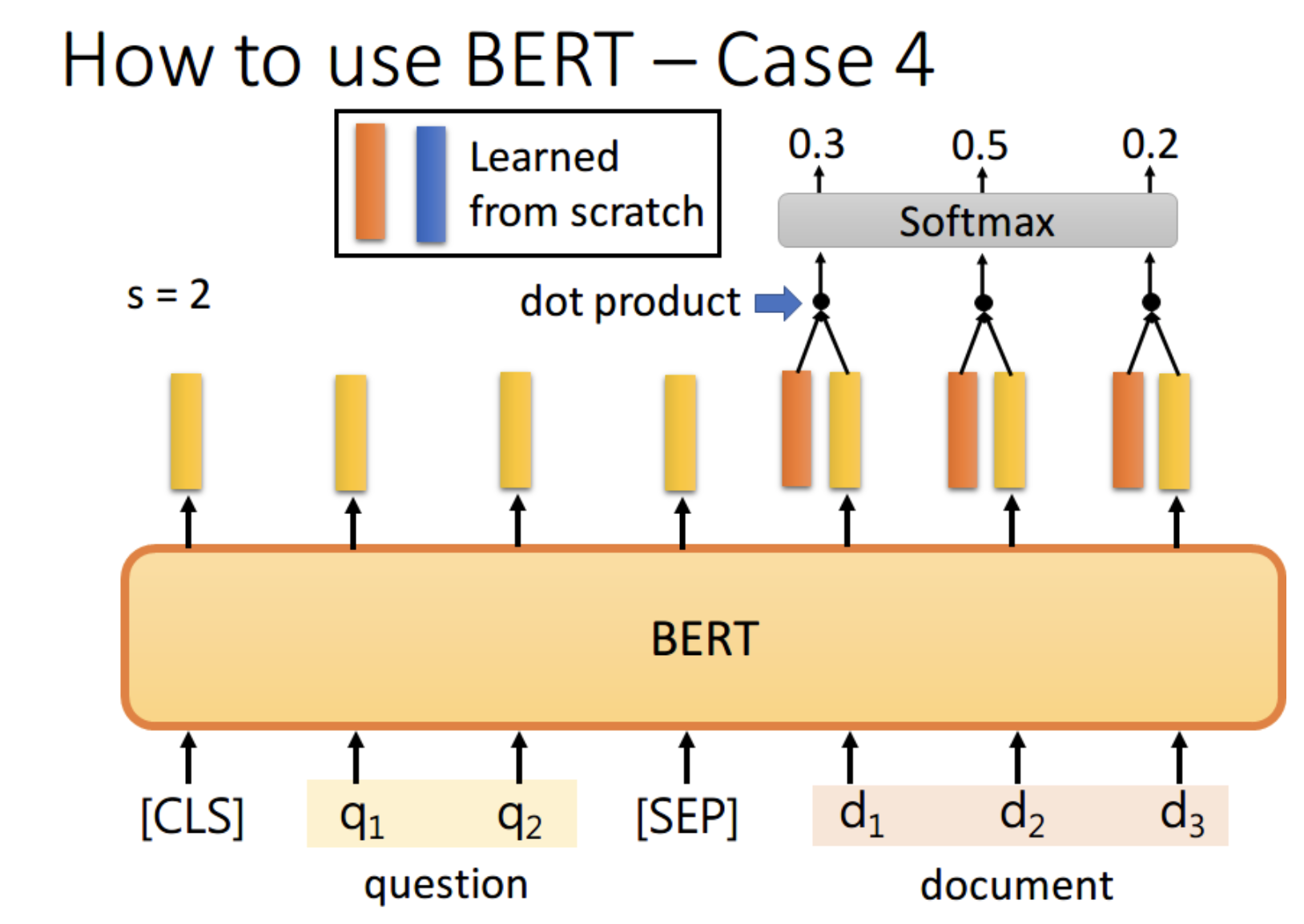
首先将问题和文章通过 [SEP] 分隔,送入 BERT 之后,得到上图中黄色的输出。
此时我们还要训练两个 vector,即上图中橙色和黄色的向量。
首先将橙色和所有的黄色向量进行 dot product,
然后通过 softmax,看哪一个输出的值最大,
例如上图中 d2 对应的输出概率最大,那我们就认为 s=2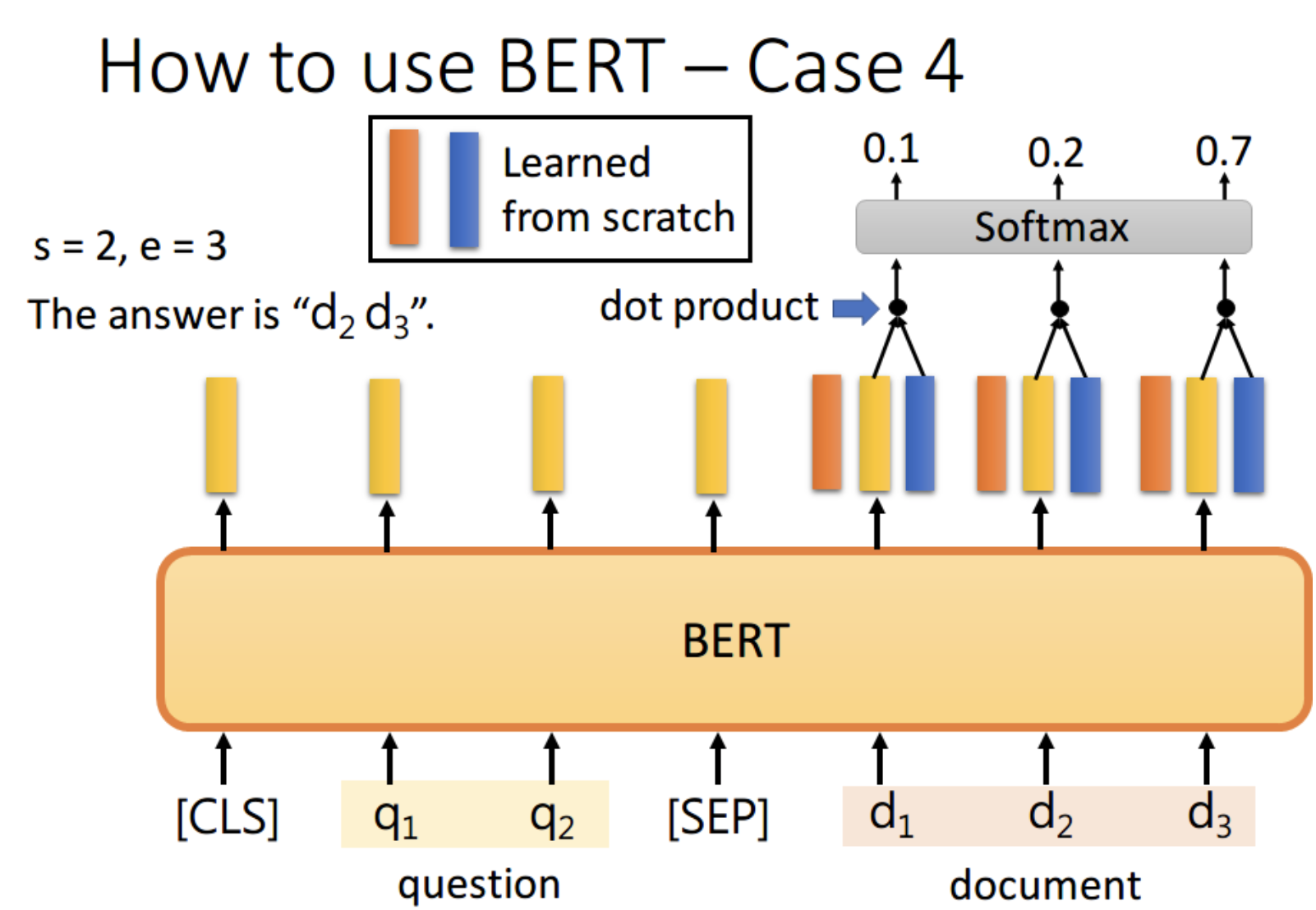
同样地,我们用蓝色的向量和所有黄色向量进行 dot product,
最终预测得 d3 的概率最大,因此 e=3。最终,答案就是 s=2,e=3
你可能会觉得这里面有个问题,假设最终的输出 s>e 怎么办,那不就矛盾了吗?其实在某些训练集里,有的问题就是没有答案的,因此此时的预测搞不好是对的,就是没有答案
任务5:生成类任务
我们知道Bert的MLM机制跟生成任务的目标并不一致,生成任务是根据前面的词来预测当前词,但是Bert是根据所有上下文来预测被mask掉的词,导致Bert并不适合做文本生成的任务。要将Bert应用到文本生成的任务,需要对Bert的结构做相应的调整适配才可以,这里的调整其实也只是对mask矩阵的调整而已,可以通过mask矩阵使得当前词的预测时只看得到前文,看不到后文,这样就能用Bert来做文本生成的任务了,这也就是UNILM的做法。 在训练跟推理时,通过mask矩阵的设置,使得当前词只看到前文内容,看不到后文内容,不断生成当前位置的词,直到预测的词是[CLS]就停止生成。
实战任务
1.文本相似度

def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,labels, num_labels, use_one_hot_embeddings):"""建立微调模型:param is_training: 训练还是测试:param input_ids: 输入句子中每个字的索引列表:param input_mask: 字的屏蔽列表:param segment_ids: 分段列表,第一个句子用0表示,第二个句子用1表示,[0,0,0...,1,1,]:param labels: 两个句子是否相似,0:不相似,1:相似:param num_labels: 多少个样本,多少个标签:param use_one_hot_embeddings::return:"""model = modeling.BertModel(config=bert_config,is_training=is_training,input_ids=input_ids,input_mask=input_mask,token_type_ids=segment_ids,use_one_hot_embeddings=use_one_hot_embeddings)# If you want to use the token-level output, use model.get_sequence_output()output_layer = model.get_pooled_output() #【batchsize,selength,hiddensize】hidden_size = output_layer.shape[-1].valueoutput_weights = tf.get_variable("output_weights", [num_labels, hidden_size],initializer=tf.truncated_normal_initializer(stddev=0.02))output_bias = tf.get_variable("output_bias", [num_labels], initializer=tf.zeros_initializer())with tf.variable_scope("loss"):if is_training:# I.e., 0.1 dropoutoutput_layer = tf.nn.dropout(output_layer, keep_prob=0.9)# transpose_b=True,在乘积之前先将第二个矩阵转置logits = tf.matmul(output_layer, output_weights, transpose_b=True)logits = tf.nn.bias_add(logits, output_bias)probabilities = tf.nn.softmax(logits, axis=-1)# 使用softmax losss 作为损失函数log_probs = tf.nn.log_softmax(logits, axis=-1)one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)loss = tf.reduce_mean(per_example_loss)return (loss, per_example_loss, logits, probabilities)
2.语言模型
输入:
模型理解INFO:tensorflow:*** Example ***INFO:tensorflow:tokens: [CLS] i 觉 得 [UNK] u [MASK] 非 [MASK] 位 i 风 格 较 ##by 哦 个 驅 色 哦 i 多 发 [MASK] 个 v 二 哥 i 文 件 哦 i 怪 [MASK] 决 斗 盘 可 加 热 管 [MASK] u [MASK] [MASK] 文 集 狗 哥 [SEP] [MASK] [UNK] 奇 偶 均 衡 能 否 v 不 。 极 [MASK] 疯 狂 减 肥 的 人 能 否 打 开 v 高 科 技 就 而 [MASK] 就 [UNK] 哦 冏 结 构 i 恶 如 桂 萼 黑 人 牙 膏 [UNK] u 我 也 【 发 票 未 开 [MASK] 俄 日 [MASK] 件 二 我 就 佛 i 额 [MASK] 阶 [MASK] 感 v [MASK] 我 为 [MASK] 军 方 [SEP]INFO:tensorflow:input_ids: 101 151 6230 2533 100 163 103 7478 103 855 151 7599 3419 6772 8684 1521 702 7705 5682 1521 151 1914 1355 103 702 164 753 1520 151 3152 816 1521 151 2597 103 1104 3159 4669 1377 1217 4178 5052 103 163 103 103 3152 7415 4318 1520 102 103 100 1936 981 1772 6130 5543 1415 164 679 511 3353 103 4556 4312 1121 5503 4638 782 5543 1415 2802 2458 164 7770 4906 2825 2218 5445 103 2218 100 1521 1087 5310 3354 151 2626 1963 3424 5861 7946 782 4280 5601 100 163 2769 738 523 1355 4873 3313 2458 103 915 3189 103 816 753 2769 2218 867 151 7583 103 7348 103 2697 164 103 2769 711 103 1092 3175 102INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1INFO:tensorflow:masked_lm_positions: 6 8 14 17 23 34 42 44 45 46 51 63 80 105 108 116 118 121 124 0INFO:tensorflow:masked_lm_ids: 5445 1392 711 5106 1126 1077 100 702 782 3152 2533 2428 1400 163 7353 1912 5277 8024 862 0INFO:tensorflow:masked_lm_weights: 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0INFO:tensorflow:next_sentence_labels: 1
最后total_loss用于训练,masked_lm_example_loss用于计算最终语言模型的PPL。
total_loss,masked_lm_example_loss = get_masked_lm_output(bert_config, model.get_sequence_output(), model.get_embedding_table(),masked_lm_positions, masked_lm_ids) #(-1,20)def get_masked_lm_output(bert_config, input_tensor, output_weights, positions, #positions (-1,20)label_ids):"""Get loss and log probs for the masked LM."""input_tensor = gather_indexes(input_tensor, positions)with tf.variable_scope("cls/predictions"):# We apply one more non-linear transformation before the output layer.# This matrix is not used after pre-training.with tf.variable_scope("transform"):input_tensor = tf.layers.dense(input_tensor,units=bert_config.hidden_size,activation=modeling.get_activation(bert_config.hidden_act),kernel_initializer=modeling.create_initializer(bert_config.initializer_range))input_tensor = modeling.layer_norm(input_tensor)# The output weights are the same as the input embeddings, but there is# an output-only bias for each token.output_bias = tf.get_variable("output_bias",shape=[bert_config.vocab_size],initializer=tf.zeros_initializer())logits = tf.matmul(input_tensor, output_weights, transpose_b=True)logits = tf.nn.bias_add(logits, output_bias)log_probs = tf.nn.log_softmax(logits, axis=-1)label_ids = tf.reshape(label_ids, [-1])one_hot_labels = tf.one_hot(label_ids, depth=bert_config.vocab_size, dtype=tf.float32)per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1])total_loss = tf.reduce_mean(per_example_loss)loss = tf.reshape(per_example_loss, [-1, tf.shape(positions)[1]],name="masked_lm_example_loss") #[-1,20]# TODO: dynamic gather from per_example_lossreturn total_loss,loss
3.语义搜索-SentenceBert
由于bert模型规定,在计算语义相似度时,需要将两个句子同时进入模型,进行信息交互,这造成大量的计算开销。例如,有10000个句子,我们想要找出最相似的句子对,需要计算(100009999/2)次,需要大约65个小时。BERT 不适合语义相似度搜索,同样也不适合无监督任务,例如聚类。
解决聚类和语义搜索的一种常见方法是将每个句子映射到一个向量空间,使得语义相似的句子很接近。利用bert,通常获得*句子向量的方法有两种:
- 计算所有 Token 输出向量的平均值
- 使用 [CLS] 位置输出的向量
采用sentence-Bert 可以解决这种问题,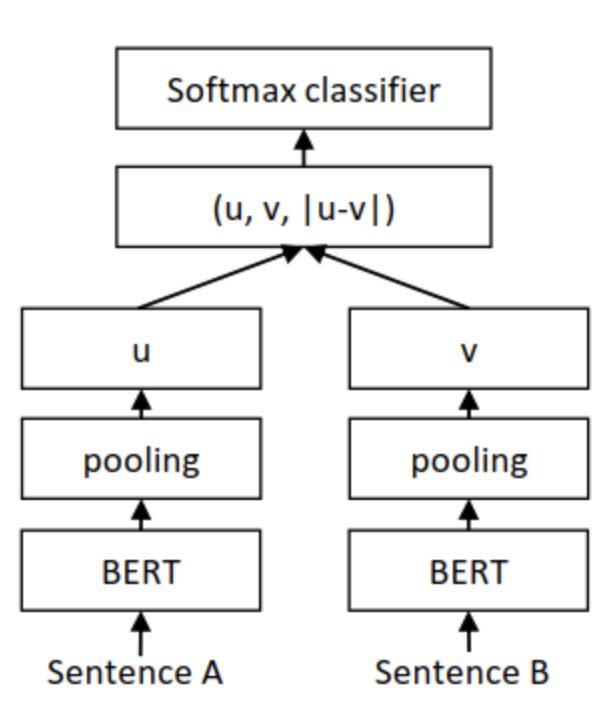
分别获得两句话的句子向量 u 和 v ,并将u 、 v和二者按位求差向量 |u−v|进行拼接,再将拼接好的向量乘上一个可训练的权重 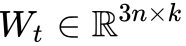 :
:
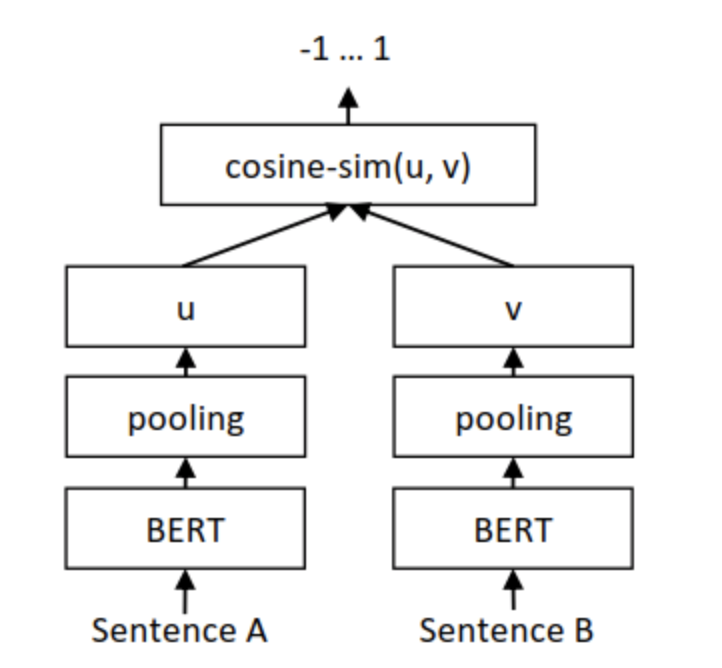
两个句子 embedding 向量  的余弦相似度计算结构如下所示,损失函数为 MSE(mean squared error)。
的余弦相似度计算结构如下所示,损失函数为 MSE(mean squared error)。
速度快的原因:知识库句子,预先离线编码好,成为句向量。然后一个查询过来,只需要对查询做一次编码(走一次bert)。之后就可以向量点乘(时间很快),获取排序结果了。bert 不能这么可以这么做,但是效果不好。
优点:重点是效果好、上线快,创新性一般。
Roberta
paper:A Robustly Optimized BERT Pretraining Approach
模型说明:
将静态mask改为动态mask
原Bert:对这15%的Tokens进行(1)80%的时间替换成[MASK];(2)10%的时间不变;(3)10%的时间替换成其他词。但整个训练过程,这15%的Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了。这就叫做静态Masking。 RoBERTa:一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。
数据量
RoBERTa 采用 160 G 训练文本,远超 BERT 的 16G 文本
句子任务修改
原Bert:为了捕捉句子之间的关系,使用了NSP任务进行预训练,就是输入一对句子A和B,判断这两个句子是否是连续的。在训练的数据中,50%的B是A的下一个句子,50%的B是随机抽取的。 RoBERTa:去除了NSP,每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做(FULL - SENTENCES),而原来的Bert每次只输入两个句子。实验表明在MNLI这种推断句子关系的任务上RoBERTa也能有更好性能。
巨型batchsize
原Bert-base:batch size是256,训练1M个steps, RoBERTa:batch size为8k
Albert
- 参数对比

- 词向量矩阵的分解
在bert以及诸多bert的改进版中,embedding size都是等于hidden size的,这不一定是最优的。因为bert的token embedding是上下文无关的,而经过multi-head attention+ffn后的hidden embedding是上下文相关的,bert预训练的目的是提供更准确的hidden embedding,而不是token embedding,因此token embedding没有必要和hidden embedding一样大。albert将token embedding进行了分解,首先降低embedding size的大小,然后用一个Dense操作将低维的token embedding映射回hidden size的大小。bert的embedding size=hidden size,因此词向量的参数量是vocab size hidden size,进行分解后的参数量是vocab size embedding size + embedding size * hidden size,只要embedding size << hidden size,就能起到减少参数的效果。
- 参数共享
bert的12层transformer encoder block是串行在一起的,每个block虽然长得一模一样,但是参数是不共享的。albert将transformer encoder block进行了参数共享,这样可以极大地减少整个模型的参数量。
- sentence order prediction(SOP)
在auto-encoder的loss之外,bert使用了NSP的loss,用来提高bert在句对关系推理任务上的推理能力。而albert放弃了NSP的loss,使用了SOP的loss。NSP的loss是判断segment A和segment B之间的关系,其中0表示segment B是segment A的下一句,1表示segment A和segment B来自2篇不同的文本。SOP的loss是判断segment A和segment B的的顺序关系,0表示segment B是segment A的下一句,1表示segment A是segment B的下一句。
部署-tensorserving
参考:《Estimator工程实现》系列三: SavedModel模型保存导出示https://www.jianshu.com/p/72058da4d7f7
此处是文本相似度的tensorserving 导出样例
def export(self):def serving_input_fn():label_ids = tf.placeholder(tf.int32, [None], name='label_ids')input_ids = tf.placeholder(tf.int32, [None, args.max_seq_len], name='input_ids')input_mask = tf.placeholder(tf.int32, [None, args.max_seq_len], name='input_mask')segment_ids = tf.placeholder(tf.int32, [None, args.max_seq_len], name='segment_ids')input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({'label_ids': label_ids,'input_ids': input_ids,'input_mask': input_mask,'segment_ids': segment_ids,})()return input_fn#self.estimator._export_to_tpu = Falseself.estimator.export_savedmodel(args.export_dir, serving_input_fn) # tf.estimator.Estimator.export_savedmodel
saved_model_cli show --dir 1587448984/ --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:signature_def['serving_default']:The given SavedModel SignatureDef contains the following input(s):inputs['input_ids'] tensor_info:dtype: DT_INT32shape: (-1, 128)name: input_ids_1:0inputs['input_mask'] tensor_info:dtype: DT_INT32shape: (-1, 128)name: input_mask_1:0inputs['label_ids'] tensor_info:dtype: DT_INT32shape: (-1)name: label_ids_1:0inputs['segment_ids'] tensor_info:dtype: DT_INT32shape: (-1, 128)name: segment_ids_1:0The given SavedModel SignatureDef contains the following output(s):outputs['output'] tensor_info:dtype: DT_FLOATshape: (-1, 2)name: loss/Softmax:0Method name is: tensorflow/serving/predict
docker pull tensorflow/serving
docker run -t —rm -h bertsimlarity -p 8500:8500 -v /**/export_model:/models/bertsimlarity —privileged —name bert_simlarity -e MODEL_NAME=bertsimlarity tensorflow/serving
Bert 加速
模型蒸馏
当你按照标准流程做了蒸馏,但是效果不理想,现在该怎么办?
- Better Teacher, Bert Student:想办法提升教师模型的效果,最简单粗暴的,比如多模型ensemble在一起;
- 用better teacher在无标注数据生成伪标签应该会有用的 。
- 不要放弃标注数据:只用soft-label,小模型大概率会跑偏。训练教师模型的标注数据,一定要混在每一个batch里;
- 隐层逼近不适合简单模型:进行隐层(中间层)的输出逼近,只适合同类模型,比如从12层BERT到4层BERT。千万不要在BERT往CNN迁移的时候,加入奇奇怪怪的学习目标;
- 蒸馏数据的质和量:如果标注数据足够多足够好,根本没有必要做蒸馏。蒸馏的本质就是借助表现能力更强的教师模型,来生成大量的伪数据(即soft-label)。关于数据,第一要义是保证数量(至少10万吧),第二要义是控制来源(蒸馏数据和测试用数据需要“同分布”),第三要义是标签均衡(教师模型输出的得分,从0.01~0.99都要有,比例相差不能悬殊);
- 参数控制:标准流程里的参数配置,并不一定适合你的应用场景。比如,引入Temperature因子是为了拉开教师模型输出分数的分布区间,但如果你的模型分布已经很散了,不用也未尝不可;
- 心理预期:实操中不要太指望,学生模型可以追平教师模型。
模型压缩
模型压缩的手段通常有剪枝(pruning)和量化(Quantization)
- 剪枝即从模型中删除一些不重要或不太重要的权重(有时会是神经元),从而产生稀疏的权重矩阵(或较小的图层)。甚至还有一些研究直接去除掉与 Transformer 的注意力头相对应的整个矩阵。
量化会降低模型权重的数值精度。通常情况下,使用 FP32(32 位浮点)来训练模型,然后可以将其量化为 FP16(16 位浮点),INT8(8 位整数),甚至将其量化为 INT4 或 INT1。于是模型尺寸将随之减小 2 倍、4 倍、8 倍或 32 倍。这称为 post-training quantization。
扩展
美团BERT(MT-BERT)
开启混合精度实现训练加速;
- 在通用中文语料基础上加入大量美团点评业务语料进行模型预训练,完成领域迁移;
- 预训练过程中尝试融入知识图谱中的实体信息;
- 通过在业务数据上进行微调,支持不同类型的业务需求。
注:混合精度训练指的是FP32和FP16混合的训练方式,使用混合精度训练可以加速训练过程并且减少显存开销,混合精度虽然会损失一定的表示精度,但无论在参数的存储空间上还是在计算量(FPU计算次数)上都会带来极大的改进。
问题
1.Bert的具体网络结构,以及训练过程,Bert为什么火,它在什么的基础上改进了些什么?
bert是一个预训练的语言模型,用了transformer的encoder侧的网络,作为一个文本编码器,使用大规模数据进行预训练,预训练主要用了两个无监督的任务训练,使用两个loss,一个是mask LM,遮蔽掉源端的一些字(可能会被问到mask的具体做法,15%概率mask词,这其中80%用[mask]替换,10%随机替换一个其他字,10%不替换,至于为什么这么做,那就得问问BERT的作者了{捂脸}),然后根据上下文去预测这些字,一个是next sentence,判断两个句子是否在文章中互为上下句,然后使用了大规模的语料去预训练。 基本原来就是两个子任务 MLM和NSP。 主要是在GPT的基础上,将单向transformer改成双向,自然效果就会变好。
2.Bert如何应用transformer
1.transformer encoder侧的网络,12层的transformer encoder层,这个12层指的是encoder中block的个数,在encoder的输出后连接分类层:MLM模型直接预测token,NSP预测是不是下一句。 2.输入除了Token Embedding和Position Embedding之外,还有segment Embedding,其中Position Embedding又有所不同,Bert 中Position 也有参数,但是transformer是采用sin cos函数标记位置的。
3.简要描述Masked LM
概述:一种有效的无监督训练方法,把一句话中的词汇进行Mask ,然后去预测这个词 详细:在bert 里面,Mask掉15%的词汇,其中80%替换成[MASK],10%替换成随机的一个词,10% 不变。 看法:MLM可以看作是一种引入噪声的手段,增强模型的泛化能力,所以比较有效 好处:无监督,增强模型泛化能力,任何词都会被预测,双向强迫文本记忆上下文信息,获得词的表示。
4.简要描述Next Sentence Prediction
判断两个句子是否是连续的 一个任务,随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
5.EMLo、GPT、Bert区别
在它之前是GPT,GPT是一个单向语言模型的预训练过程,它和gpt的区别就是bert为啥叫双向 bi-directional,更适用于文本生成,通过前文去预测当前的字。 特征提取器:
- EMLo采用LSTM进行提取,GPT和BERT则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM。
- EMLo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和BERT中的Transformer可采用多层,并行计算能力强。
单/双向语言模型:
- GPT采用单向语言模型,EMLo和BERT采用双向语言模型。但是EMLo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比BERT一体化融合特征方式弱。
GPT和BERT都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用encoder部分,self-attention 中mask掉当前位置后面的的信息,所以是单向的;训练的过程也非常简单,就是将 n 个词的词嵌入加上位置嵌入,然后输入到 Transformer 中,n 个输出分别预测该位置的下一个词。bert的双向语言模型则采用encoder部分,区别在于self-attention 的时候采用了每个词两侧的语义信息,bert 训练任务也不一样。
6.Bert两个任务的损失函数
负对数似然函数
7.如何优化BERT效果
性能优化
- 增加语料
- 知识融入,美团的MT-bert增加了和业务相关的实体
- 领域自适应,加入领域数据继续训练
加速优化
- 混合精度实现训练加速,Google应该用的是FP32,美团是FP32和FP16的混合:美团的一篇论文实验结果证明:并没有影响效果,反而训练速度提升了2倍多。
8.BERT优缺点
最好是能和具体的另外一个模型做比较,比如ELMO,GPT等预训练模型 优点:
- 并发—BERT相较于原来的RNN、LSTM可以做到并发执行,同时提取词在句子中的关系特征在多个不同层次提取关系特征,进而更全面反映句子语义
- 相较于word2vec,强迫文本记忆上下文信息,其又能根据句子上下文获取词义,从而避免歧义出现
缺点:
- 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
9.Bert 的双向体现在哪
一方面是self-attention中没有mask 掉后面的信息,另外一方面是训练任务MLM。 双向的核心是self-attention,mask(MLM)+attention,mask的word结合全部其他左右两侧文本encoder word的信息。
10.手写一个multi-head attention
tf.multal(tf.nn.softmax(tf.multiply(tf.multal(q,k,transpose_b=True),1/math.sqrt(float(size_per_head)))),v)
11.Bert 文本预处理句子长度是多少,为什么
最大长度限制是512,为什么是512 论文中说到是最佳计算效率。
12.如何消除最长限制
办法之一便是重新初始化一个更大的位置词表,然后将前512个向量用预训练模型中的进行替换,余下的通过在下游任务中微调或语料中训练得到即可。
13.为什么[CLS]可以代表整个句子的语义
这么说是不准确的,在预训练结束之后,CLS的输出向量并不能说代表了整个句子的语义信息。CLS这个向量用在NSP这个任务中是一个二分类任务,与编码的整个句子的语义信息差的远,所以大家都会发现一个问题:如果用CLS整个输出向量去做无监督文本相似度任务的时候效果特别差。 被当作可以代表整个句子的语义其实是因为 BERT做分类任务的时候用它来接一个二分类器,所以给人的感觉是它含有整句话的完整信息。但它的使命其实就只是为了分类而生。
14.Bert 三个Embedding为什么可以相加
三个 Embedding相加也看作是一种特征融合。将token,position,segment三者都用one hot表示,然后concat起来,然后才去过一个单层全连接,等价的效果就是三个Embedding相加。
ref:
https://www.yuque.com/yahan/mztcmb/qc76a5#a3OyE
bert 面试题 https://www.yuque.com/lunaticbg/fasntn/hu4mf8#svchh

若有收获,就点个赞吧
0 人点赞
