调试处理(Tuning process)
从学习速率𝑎到 **Momentum **(动量梯度下降法)的参数𝛽。如果使用 **Momentum **或 **Adam **优化算法的参数,𝛽1,𝛽2和𝜀, 也许你还得选择层数,也许你还得选择不同层中隐藏单元的数量,也许你还想使用学习率衰减。接着,当然你可能还需要选择 **mini-batch **的大小。

最重要的参数是学习率𝑎,然后其次是黄色圈起来的超参数,然后是紫色圈住的那些。当应用 Adam 算法时,基本从不调试𝛽1,𝛽2和𝜀,总是选定其分别为 0.9,0.999 和10−8。但这不是严格且快速的标准,其它深度学习 的研究者可能会很不同意我的观点或有着不同的直觉。
在深度学习领域,我推荐你采用下面的做法,随机选择点,可以选择同等数量的点,25 个点,接着,用这些随机取的点试验超参数的效果。之所以这么做是因为,对于你要解决的问题而言,你很难提前知道哪个超参数最重要。
假设是两个超参数,𝑎和𝜀:如果随机取值,可以试验到 25 个独立的𝑎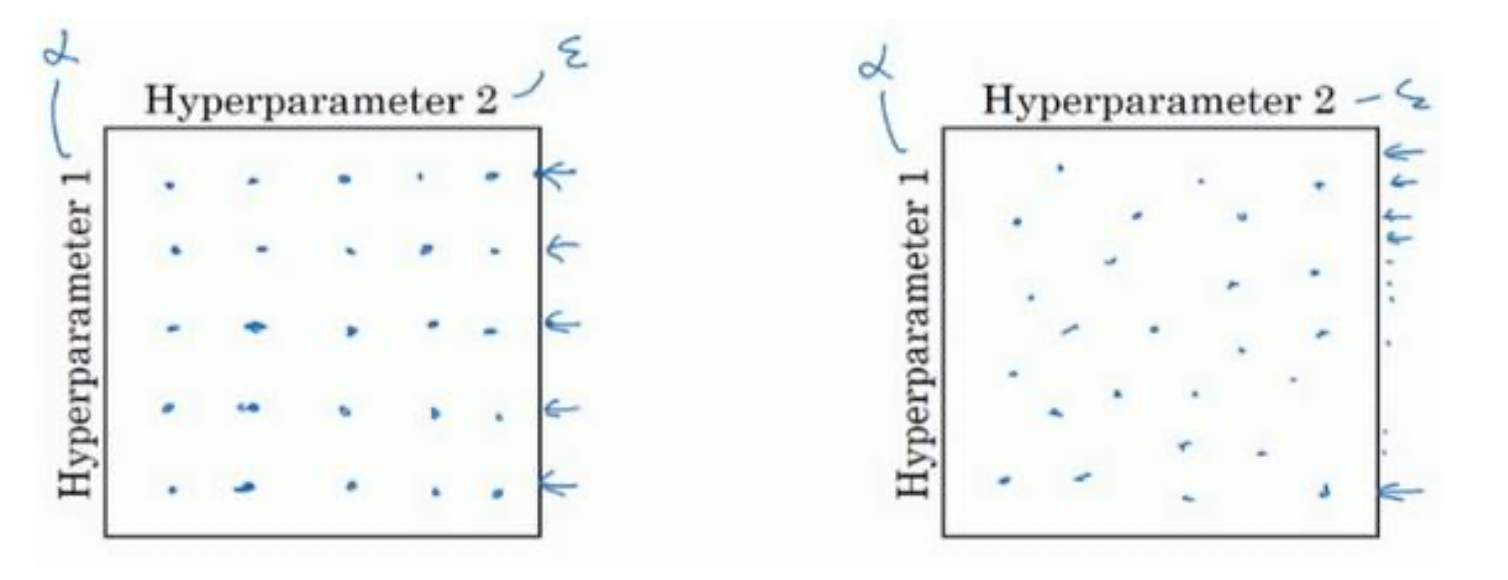
当你给超参数取值时,另一个惯例是采用由粗糙到精细的搜索策略。也许你会发现效果最好的某个点或某个区域,也许这个点周围或这个区域的其他一些点效果也很好,那在接下来要做的是放大这块小区域(小蓝色方框内)。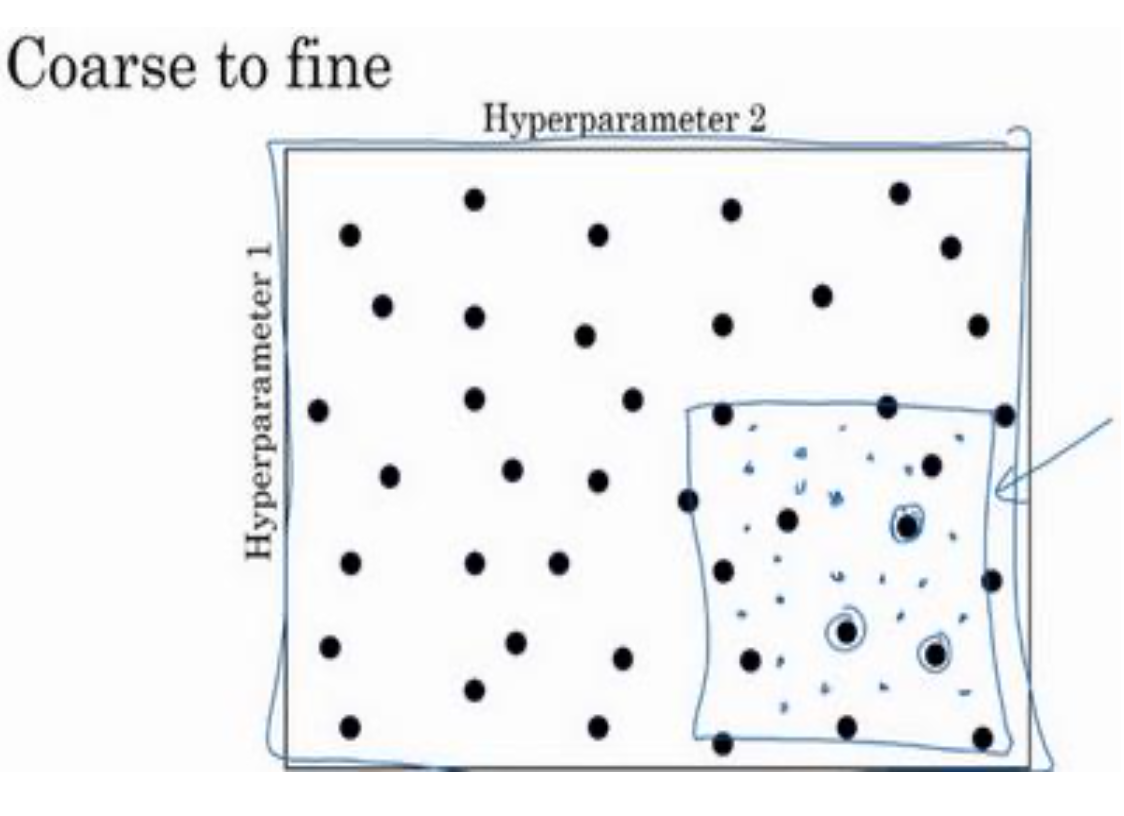
为超参数选择合适的范围
用线性轴取值不是很好的办法,可以换成对数轴。<br /> 关于如何搜索超参数的问题,通常采用的 两种重要但不同的方式。<br /> 一种是你照看一个模型,通常是有庞大的数据组,但没有许多计算资源或足够的 **CPU **和 **GPU **的前提下,基本而言,你只可以一次负担起试验一个模型或一小批模型,在这种情况下, 即使当它在试验时,你也可以逐渐改良。比如,第 0 天,你将随机参数初始化,然后开始试 验,然后你逐渐观察自己的学习曲线,也许是损失函数 J,或者数据设置误差或其它的东西, 在第 1 天内逐渐减少,那这一天末的时候,你可能会说,看,它学习得真不错。我试着增加一点学习速率,看看它会怎样,也许结果证明它做得更好,那是你第二天的表现。两天后, 你会说,它依旧做得不错,也许我现在可以填充下 **Momentum **或减少变量。然后进入第三天,每天你都会观察它,不断调整参数。也许有一天,你会发现你的学习率太大了, 所以你可能又回归之前的模型,像这样,但你可以说是在每天花时间照看此模型,即使是它 在许多天或许多星期的试验过程中。所以这是一个人们照料一个模型的方法,观察它的表现,** 耐心地调试学习率,但那通常是因为你没有足够的计算能力,不能在同一时间试验大量模型时才采取的办法**。<br /> 另一种方法则是同时试验多种模型,你设置了一些超参数,尽管让它自己运行,或者是一天甚至多天,然后你会获得像这样的学习曲线,这可以是损失函数 J 或实验误差或损失或数据误差的损失,但都是你曲线轨迹的度量。用这种方式可以试验许多不同的参数设定,然后最后快速选择工作效果最好的那个。在这个例子中,也许这条看起来是最好的(下方绿色曲线)。<br />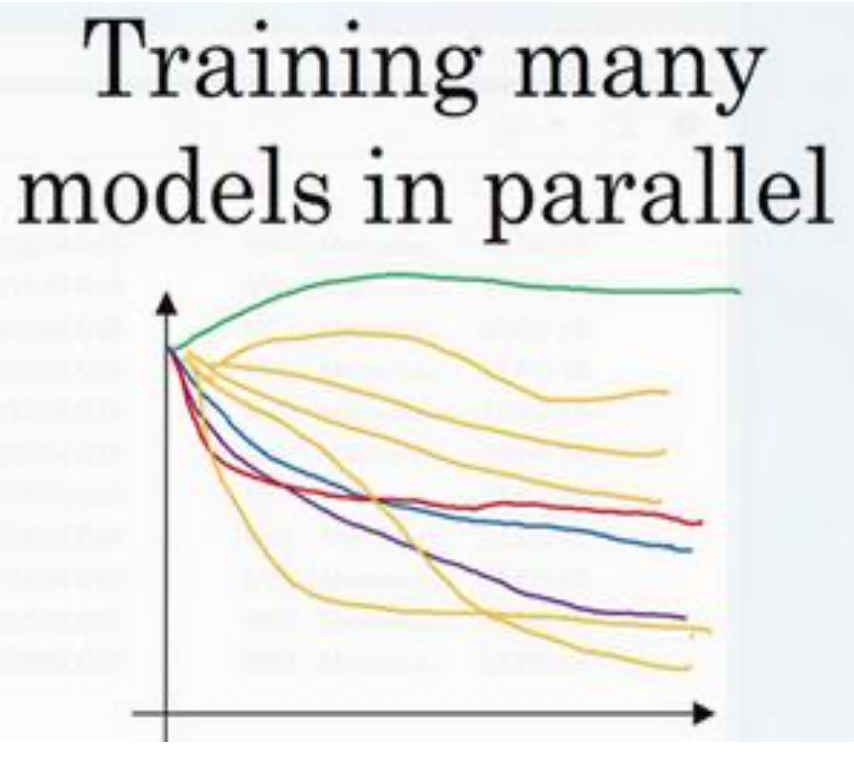

若有收获,就点个赞吧
0 人点赞
