Loss Function(损失函数)
逻辑回归的输出函数:
为了让模型通过学习调整参数,需要给予一个𝑚样本的训练集,这会让你在训练集上 找到参数𝑤和参数𝑏,,来得到你的输出。𝑦^ 对训练集的预测值,我们将它写成𝑦,我们更希望它会接近于训练集中的𝑦值,为了对上面的公式更详细的介绍,我们需要说明上面的定义是对一个训练样本来说的,这种形式也使用于每个训练样本,我们使用这些带有圆括号的上标来区分索引和样本,训练样本𝑖所对应 的预测值是𝑦^(𝑖),是用训练样本的𝑤𝑇𝑥(𝑖) + 𝑏然后通过 sigmoid 函数来得到,也可以把𝑧定义为 𝑧(𝑖) = 𝑤𝑇𝑥(𝑖) + 𝑏,我们将使用这个符号(𝑖)注解,上标(𝑖)来指明数据表示𝑥或者𝑦或者𝑧或者其 他数据的第𝑖个训练样本,这就是上标(𝑖)的含义。(i)就是单个样本的表示方法。
公式表示:Loss function:𝐿(𝑦 , 𝑦^).
在逻辑回归中用到的损失函数是:
𝐿(𝑦 , 𝑦^) = −𝑦log(𝑦^) − (1 − 𝑦)log(1 − 𝑦^)
Q:为什么不用平方差或平方差的一半
A:一般我们用预 测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为 当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是我们在逻辑回归模型中会定义另外一个损失函数。
Cost Function(代价函数)
损失函数是在单个训练样本中定义的,它衡量的是算法在单个训练样本中表现如何,为了衡量算法在全部训练样本上的表现如何,我们需要定义一个算法的代价函数,算法的代价函数是对𝑚个样本的损失函数求和然后除以𝑚:
损失函数只适用于像这样的单个训练样本,而代价函数是参数的总代价,所以在训练逻 辑回归模型时候,我们需要找到合适的𝑤和𝑏,来让代价函数 𝐽 的总代价降到最低。结果表明逻辑回归可以看做是一个非常小的神经网络。
注:在大部分语境情况下,代价函数和损失函数,是一样的。
logistic 损失函数的解释
𝑦^表示给定输入x ,输出为正真标签 y 的概率,对于单一样本来说,我们期望如下:
上述的两个条件概率公式可以合并成如下公式:
两侧同时log(log函数好单调递增),
𝑙𝑜𝑔(𝑝(𝑦^|𝑥))=
将𝐿(𝑦 , 𝑦^)=-𝑙𝑜𝑔(𝑝(𝑦^|𝑥)),就将最小化损失函数与最大化条件概率的对数 𝑙𝑜𝑔(𝑝(𝑦|𝑥)) 关联起来了,因此这就是单个训练样本的损失函数表达式。
对于m 个样本来说,假设所有的训 练样本服从同一分布且相互独立,也即独立同分布的,所有这些样本的联合概率就是每个样本概率的乘积: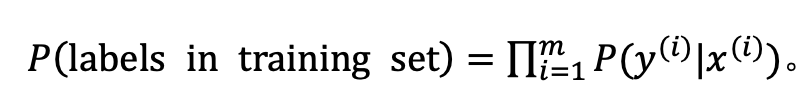
这个概率最大化等价于令其对数最大化,在等式两边取对数: 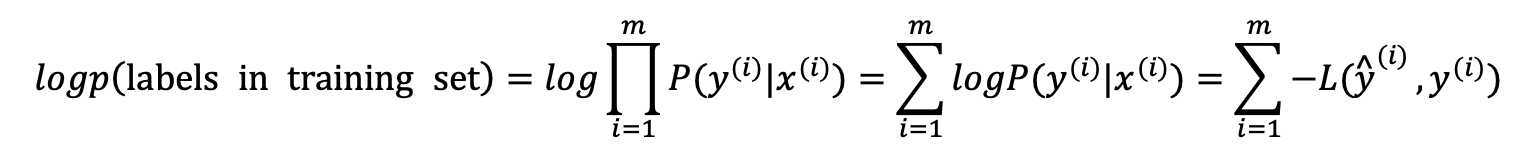
备注:最大似然估计:即求出一组参数,使这个式子取最大值。
由于训练模型时,目标是让成本函数最小化,所以我们不是直接用最大似然概率,要去掉这里的负号,最后为了方便,可以对成本函数进行适当的缩放,我们就在前面加一个额外的常数因子 1/m,即:
Gradient Descent(梯度下降)

在这个图中,横轴表示你的空间参数𝑤和𝑏,在实践中,𝑤可以是更高的维度,但是为了 更好地绘图,我们定义𝑤和𝑏,都是单一实数,代价函数(成本函数)𝐽(𝑤, 𝑏)是在水平轴𝑤和 𝑏上的曲面,因此曲面的高度就是𝐽(𝑤, 𝑏)在某一点的函数值。我们所做的就是找到使得代价函数(成本函数)𝐽(𝑤, 𝑏)函数值是最小值,对应的参数𝑤和𝑏。如图红色箭头所指。

可以用如图那个小红点来初始化参数𝑤和𝑏,也可以采用随机初始化的方法,对于逻辑 回归几乎所有的初始化方法都有效,因为代价函数是凸函数,无论在哪里初始化,应该达到同一 点或大致相同的点。 ——》
——》 ——》
——》
迭代就是不断重复做如图的公式, : =表示更新参数,
𝑎 表示学习率(learning rate),用来控制步长(step),即向下走一步的长度𝑑𝐽(𝑤) / 𝑑𝑤是函数𝐽(𝑤)对𝑤 求导(derivative)。
假定代价函数(成本函数)𝐽(𝑤) 只有一个参数𝑤,即用一维曲线代替多维曲线,这样可以更好画出图像。
if 𝑑𝐽(𝑤) / 𝑑𝑤>0 , w⬅️;
if 𝑑𝐽(𝑤) / 𝑑𝑤<0 , w➡️;

所以最终他们都向𝐽(𝑤)最小的点走,对应的𝑤就是最优参数。
Q:梯度的含义
A:首先,代价函数是一个凸函数,梯度就是通过寻找斜率下降的方式,来找代价函数的最小值,也就是参数的最优解,参数每次更新都通过减去步长(也就是学习率)乘以斜率来向代价函数的全局最优解靠近。斜率为正,向左移动,斜率为负,向右移动。
小写字母𝑑 用在求导数(derivative),即函数只有一个参数,偏 导数符号𝜕 用在求偏导(partial derivative),即函数含有两个以上的参数。好的符号表达可以辅助我们更好的理解公式和概念。

若有收获,就点个赞吧
0 人点赞
