dropout 正则化
假设在训练图一这样的一个神经网络,且它存在过拟合,这就是 **dropout **所要处理的,我们复制这个神经网络,**dropout **会遍历网络的每一层,并设置消除神经网络中节点的概率。假设网络中的每一层,每个节点得以保留和消除的概率都是 0.5,设置完节点概率,我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络,如图二然后用 **backprop **方法进行训练。<br />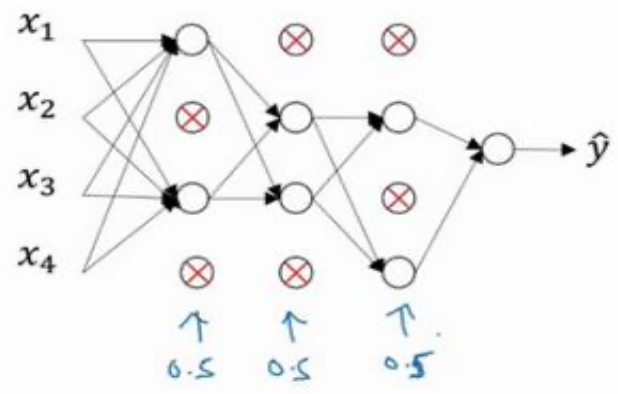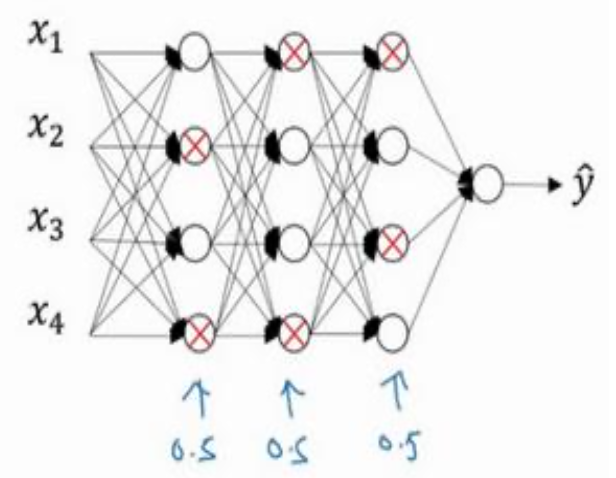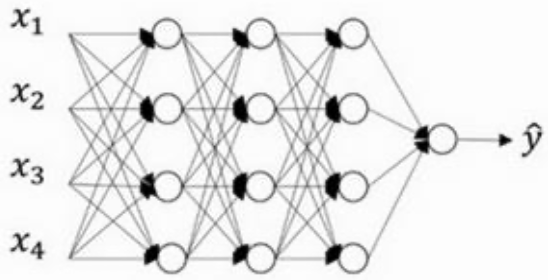<br />图一 图二 图三<br /> 其内涵就是我们针对每个训练样本训练规模极小的网络(图三),每个节点都根据不完全一样的训练样本得到训练,有点提升每个节点学习的泛化能力那味。
如何实施 dropout
tips:
1.如果发现某些层比其它层更容易发生过拟合,可以把某些层的 keep-prob 值设置得比其它层更低,缺点是为了使用交叉验证,要搜索更多的超级参数
2.是在一些层上应用 dropout,而有些层不用 dropout,应用 dropout 的层只含有一个超级参 数,就是 keep-prob。
3.dropout 在数据量少的情况下应用较多一点
问题
Q:drop和L2正则的区别
dropout 的功能类似于𝐿2正则化,与𝐿2正则化不同的是应用方式不同,dropout更适用于不同的输入范围。

若有收获,就点个赞吧
0 人点赞
