深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是 准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者 获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。
L2 正则化
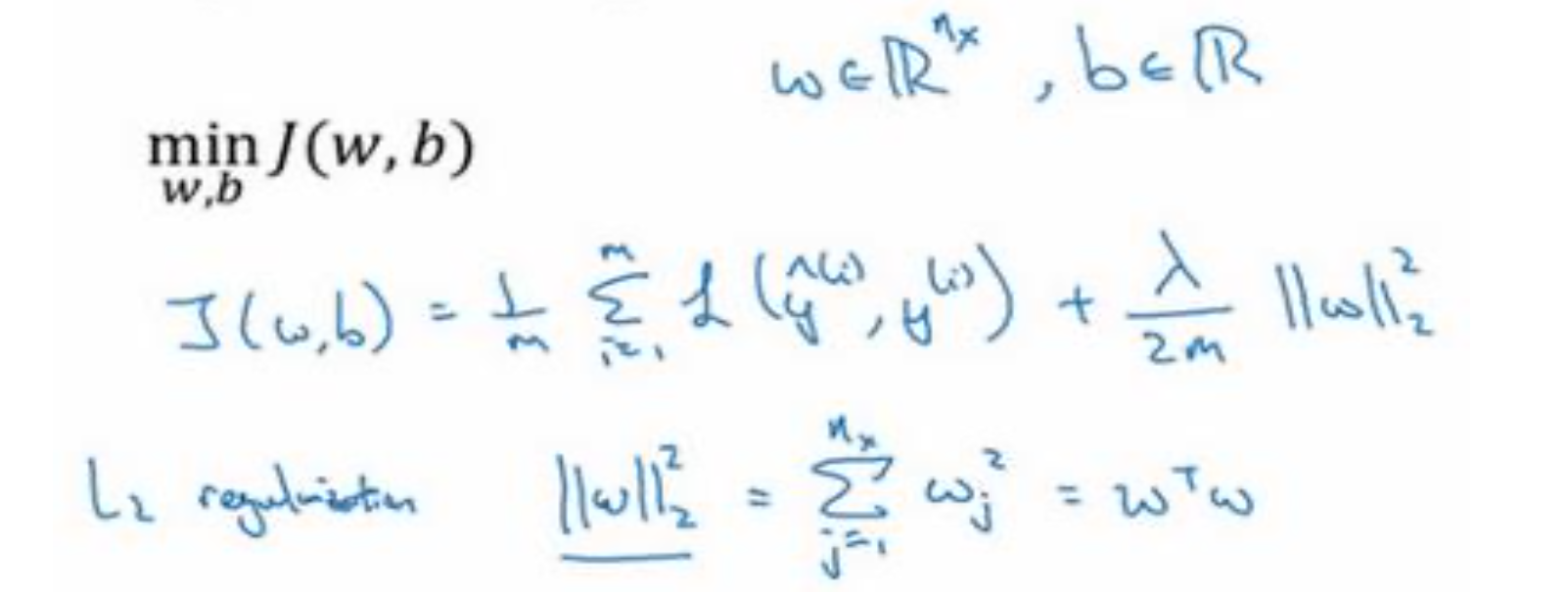
2𝑚/𝜆 乘以𝑤范数的平方,𝑤欧几里德范数的平方等于𝑤 (𝑗 值从 1 到𝑛𝑥 )平方的和,也可表示为𝑤𝑇𝑤,也就是向量参数𝑤 的欧几里德范数(2 范数)的平方,此方法称为𝐿2正则化。因为这里用了欧几里德法线,被称为向量参数𝑤的𝐿2范数。
如何实现

我们看下求和公式的具体参数,第一个求和符号其值𝑖从1到𝑛[𝑙−1],第二个其𝐽值从1到 𝑛[𝑙],因为𝑊是一个𝑛[𝑙] × 𝑛[𝑙−1]的多维矩阵,𝑛[𝑙]表示𝑙 层单元的数量,𝑛[𝑙−1]表示第𝑙 − 1层隐藏单元的数量。
该矩阵范数被称作“弗罗贝尼乌斯范数”,用下标𝐹标注,它表示一个矩阵中所有元素的平方和。
如何梯度下降

用 backprop 计算出𝑑𝑊的值,backprop 会给出𝐽对𝑊的偏导数,实际上是𝑊[𝑙],把𝑊[𝑙]替 换为𝑊[𝑙]减去学习率乘以𝑑𝑊。既然已经增加了这个正则项,现在我们要做的就 是给𝑑𝑊加上这一项𝜆 𝑊[𝑙],
该正则项说明,不论𝑊 [𝑙] 是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W 乘以(1 − 𝑎𝜆/m )倍的权重,矩阵𝑊减去𝛼𝜆/m 倍的它,也就是用这个系数(1 − 𝑎𝜆/m )乘以矩阵𝑊,该系数小于 1,因此𝐿2范数正则化也被称为“权重衰减”,因为它就像一般的梯度下降,𝑊被更新为少了𝑎乘以*backprop 输出的最初梯度值,同时𝑊也乘以了这个系数,这个系数小于 1,因此𝐿2正则化也被称为“权重衰减”。
L1 正则化

而是正则项 𝜆/𝑚 乘以 ,
, 也被称为参数𝑤向量的𝐿1范数,无论分母是𝑚还是2𝑚,它都是一个比例常量。
也被称为参数𝑤向量的𝐿1范数,无论分母是𝑚还是2𝑚,它都是一个比例常量。
为什么正则化有利于防止过拟合
可以想象一个过拟合的神经网络,它的网络结构又深又大,代价函数如下:
其通过梯度下降更新参数:
理解一:从梯度下降的角度
直观理解就是𝜆增加到足够大(接近1的做够大,而非接近正无穷的足够大),𝑊会接近于 0,实际上是不会发生这种情况的,我们尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,我们直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合,因此我不确定这个直觉经验是否有用,不过在编程中执行正则化时, 你实际看到一些方差减少的结果。
理解二:从激活函数的角度
如果正则化参数变得很大,参数𝑊很小,𝑧也会相对变小,此时忽略𝑏的影响,实际上,当𝑧的取值范围很小,这个激活函数,也就是曲线函数𝑡𝑎𝑛h会相对呈线性,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,并不是一个极复杂,高度非线性函数,不会过度拟合数据集的非线性决策边界(如下图),不会发生过拟合。

若有收获,就点个赞吧
0 人点赞
