归一化网络的激活函数(Normalizing activations in a network)
如果你想训练这些参数,比如𝑤[3],𝑏[3],那归一化𝑎[2]的平均值和方差岂不是很好? 以便使𝑤[3],𝑏[3]的训练更有效率。<br />复习:[https://www.yuque.com/dengxiaotian0212/klyctg/wc8oai](https://www.yuque.com/dengxiaotian0212/klyctg/wc8oai)<br /><br />也可以归一化经过激活函数之后的结果,如图所示:<br />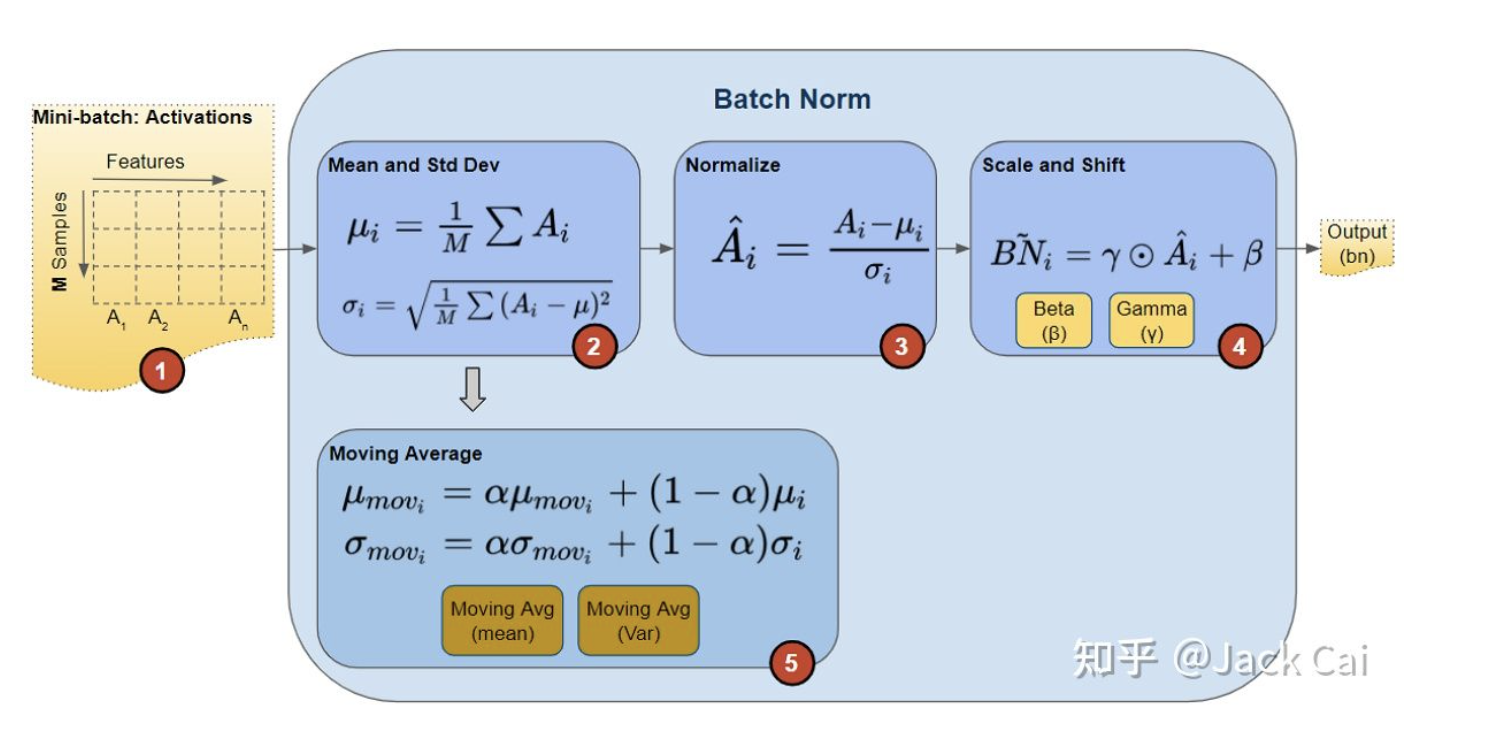<br /> 深度学习文献中有一些争论,关于在激活函数之前是否应该将值𝑧[l]( 𝑧[2] )归一化,或是否应该在应用激活函数𝑎[l]( a[2] )后再规范值。实践中,经常做的是归一化𝑧[l],(也可以归一化激活函数之后的结果)所以这就是我介绍的版本,我推荐其为默认选择,那下面就是 **Batch **归一化的使用方法。<br />
1.Batch 归一化的作用是它适用的归一化过程,不只是输入层,甚至同样适用于神经网络中的深度隐藏层。
2.训练输入和这些隐藏单元值的归一化的一个区别是,隐藏单元值也许不是必须是平均值 0 和方差 1。比如,如果你有 sigmoid 激活函数,你不想让你的值总是全部集中在这里(线性区),你想使它们有更大的方差,或不是 0 的平均值,以便更好的利用非线性的 sigmoid 函数。
将 Batch Norm 拟合进神经网络

如图,需要强调的是 Batch 归一化是发生在计算𝑧和𝑎之间的,batch norm 中的𝛽[1],𝛽[2]和优化算法adam,Momentum中的𝛽不同。优化算法中的𝛽是超参数。batch norm 中的𝛽[1],𝛽[2]中的参数需要梯度下降法更新,即更新参数𝛽为𝛽[𝑙] = 𝛽[𝑙] − 𝛼𝑑𝛽[𝑙]。
tf.nn.batch_normalization
Batch Norm 的作用
1.加快收敛速度
由于x被标准化了,所以关于w的损失函数的几何表示是一个比较均衡的几何体, 在随机梯度下降过程中能更快地走到最优点。
2. 能够提高模型的精度
3.能解决梯度消失问题
BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了权重参数放大缩小带来的影响,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
4. 能提高模型的泛化能力
Batch Norm 为什么奏效?
1.归一化输入特征值𝑥(包括隐藏层输入),使其均值为 0,方差 1。加速学习
2.轻微正则化作用,缩放过程 从𝑧 [𝑙] 到𝑧̃ [𝑙] ,过程也有一些噪音,所以和 dropout 相似,它往每个隐藏层的激活值上增加了噪音,dropout 有增加噪音的作用,它使一个隐藏的单元以一定的概率乘以 0,以一定的概率乘以 1。
测试时的 Batch Norm
这个时候只有一个样本,我们就没有办法获取均值和方差,就没有办法进行测试。为了解决这个问题,该算法是利用训练集均值和方差来代替。假设训练过程中每个mini-batch的均值和方差为 和
和 。
。

若有收获,就点个赞吧
0 人点赞
