了解python中的广播机制,有助于我们理解代码中向量维度的变化。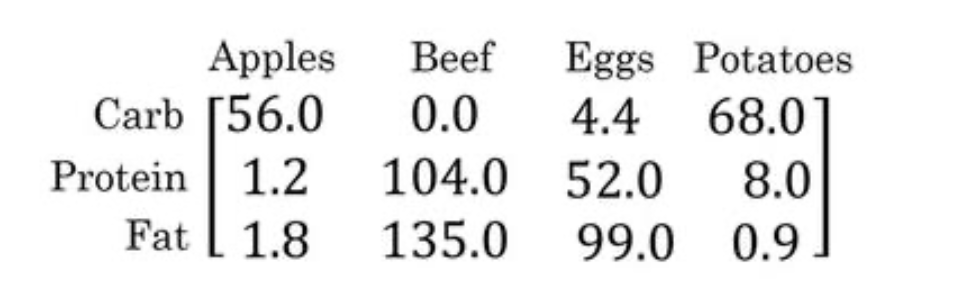
现在计算苹果中的碳水化合物卡路里百分比含量,首先计算苹果(100g)中三种营养成分卡路里总和 56+1.2+1.8 = 59,然后用 56/59 = 94.9%算出结果。
对于其他食物,计算方法类似。首先,按列求和,计算每种食物中(100g)三种营养成 分总和,然后分别用不用营养成分的卡路里数量除以总和,计算百分比。
那么,能否不使用 for 循环完成这样的一个计算过程呢?
sum(axis=)
>>> A=np.array([[56,0,4.4,68],[1.2,104,52,8],[1.8,135,99,0.9]])>>> Aarray([[ 56. , 0. , 4.4, 68. ],[ 1.2, 104. , 52. , 8. ],[ 1.8, 135. , 99. , 0.9]])
>>> cel=A.sum(axis=0)>>> celarray([ 59. , 239. , 155.4, 76.9])>>> percentage=100*A/cel.reshape(1,4)>>> percentagearray([[94.91525424, 0. , 2.83140283, 88.42652796],[ 2.03389831, 43.51464435, 33.46203346, 10.40312094],[ 3.05084746, 56.48535565, 63.70656371, 1.17035111]])
axis用来指明将要进行的运算 是沿着哪个轴执行,在 numpy 中,0 轴是垂直的,也就是列,而 1 轴是水平的,也就是行。
numpy广播
技术上来讲,其实并不需要再将矩阵cel reshape(重塑)成 1 × 4,因为矩阵cel本身已经是 1 × 4了。但是当我们写代码时不确定矩阵维度的时候,通 常会对矩阵进行重塑来确保得到我们想要的列向量或行向量。重塑操作 reshape 是一个常量时间的操作,时间复杂度是𝑂(1),它的调用代价极低。
𝑚×𝑛 的矩阵和 1×𝑛 的矩阵相加,在执行加法操作时,其实是将 1 × 𝑛 的矩阵复制成为 𝑚 × 𝑛 的矩阵,然后两 者做逐元素加法得到结果。
这里相当于是一个 𝑚 × 𝑛 的矩阵加上一个 𝑚 × 1 的矩阵。在进行运算时,会先将 𝑚 × 1 矩阵水平复制 𝑛 次,变成一个 𝑚 × 𝑛 的矩阵,然后再执行逐元素加法。
>>> anparray([[1, 2, 3],[4, 5, 6]])>>> anp+np.array([1000])array([[1001, 1002, 1003],[1004, 1005, 1006]])
加减乘除都适用,先扩展再运算。

若有收获,就点个赞吧
0 人点赞
