
Mini-batch 梯度下降

使用 batch 梯度下降法时,每次迭代你都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数𝐽是迭代次数的一个函数,它应该会随着每次迭代而减少,如果𝐽在某次迭代中增加了,那肯定出了问题,也许学习率太大。
使用 mini-batch 梯度下降法,如果你作出成本函数在整个过程中的图,则并不是每次迭 代都是下降的,走向朝下,但有更多的噪声。
指数加权平均数(exponentially weighted averages)
平均数求法:比如我们现在有100天的温度值,要求这100天的平均温度值:24,25,24,26,34,28,33,33,34,35……….32。
我们直接可以用公式: ,通过上面的公式就可以直接求出10天的平均值。
,通过上面的公式就可以直接求出10天的平均值。
指数加权平均:
我们现在直接给出公式: 
其中  ,
,  ,
,  。
。
本质就是以指数式递减加权的移动平均。各数值的加权而随时间而指数式递减,越近期的数据加权越重,但较旧的数据也给予一定的加权。
我们可以看到指数加权平均的求解过程实际上是一个递推的过程,那么这样就会有一个非常大的好处,每当我要求从0到某一时刻n的平均值的时候,我并不需要像普通求解平均值的作为,保留所有时刻的值,求和除以n。而是只需要保留0到(n-1)时刻的平均值和n时刻的温度值即可。也就是每次只需要保留常数值,然后进行运算即可,这对于深度学习中的海量数据来说,是一个很好的减少内存和空间的做法。
指数加权平均的偏差修正(Bias correction)
这个(红色)曲线对应𝛽的值为 0.9,这个(绿色)曲线对应的𝛽=0.98,如果你执行写在这里的公式,在𝛽等于 0.98 的时候,得到的并不是绿色曲线,而是紫色曲线, 你可以注意到紫色曲线的起点较低,我们来看看怎么处理。<br />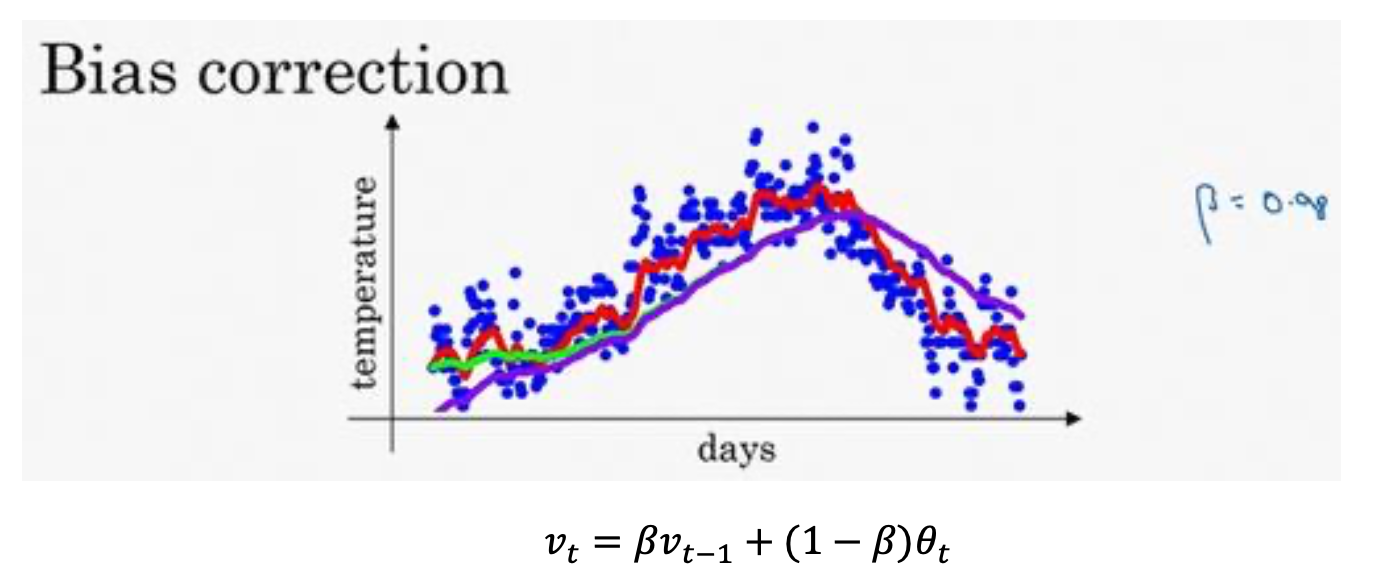<br /> 主要原因:计算移动平均数的时候,初始化𝑣0 = 0,𝑣1 = 0.98𝑣0 + 0.02𝜃1,但是𝑣0 = 0,所以这部 分没有了(0.98𝑣0),所以𝑣1 = 0.02𝜃1,所以如果一天温度是 40 华氏度,那么𝑣1 = 0.02𝜃1 = 0.02 × 40 = 8,因此得到的值会小很多,所以第一天温度的估测不准。<br /> 有个办法可以修改这一估测,让估测变得更好,更准确,特别是在估测初期,也就是不 用𝑣 ,而是用 𝑣𝑡 ,t 就是现在的天数。举个具体例子,当𝑡 = 2时,1 − 𝛽𝑡 = 1 − 0.982 = 0.0396,因此对第二天温度的估测变成了 𝑣2 = 0.0196𝜃1+0.02𝜃2,也就是𝜃1和𝜃2的加权平均数,并去除了偏差。你会发现随着𝑡增加,𝛽𝑡接近于 0,所以当𝑡很大的时候,偏差修正几乎没有作用, 因此当𝑡较大的时候,紫线基本和绿线重合了。不过在开始学习阶段,你才开始预测热身练 习,偏差修正可以帮助你更好预测温度,偏差修正可以帮助你使结果从紫线变成绿线。
Momentum(动量梯度下降法)
基本的想法就是计算梯度的指数加权平均数(exponential moving average),并利用该梯度更新权重。运行速度几乎总是快于标 准的梯度下降算法,<br />
RMSprop
Adam
RMSprop 以及 Adam 优化算法,就是少有的经受住人们考验的两种算法,已被证明适用于不 同的深度学习结构,Adam 优化算法基本上就是将 Momentum 和 RMSprop 结合在一起,那么来看看如何使 用 Adam 算法。
像RMSprop 一样存储了过去梯度的平方v的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 vdw,vdb 的指数衰减平均值。
𝛽1常用的缺省值为 0.9,超参数𝛽2推荐使用 0.999。
学习率衰减(Learning rate decay)
公式1: ,decay-rate称为衰减率,epoch-num 为代数,𝛼0为初始学习率。
,decay-rate称为衰减率,epoch-num 为代数,𝛼0为初始学习率。
公式2: ,指数衰减。
,指数衰减。
公式3: ,t为 mini-batch 的数字。
,t为 mini-batch 的数字。
局部最优的问题(The problem of local optima)
鞍点:有些方向的曲线会这样 向上弯曲,另一些方向曲线向下弯,而不是所有的都向上弯曲,因此在高维度空间,你更可 能碰到鞍点。这里导数为 0。
对于高维的空间,如何做出平稳段,突破鞍点,这就是优化算法所面临的问题。

若有收获,就点个赞吧
0 人点赞
