
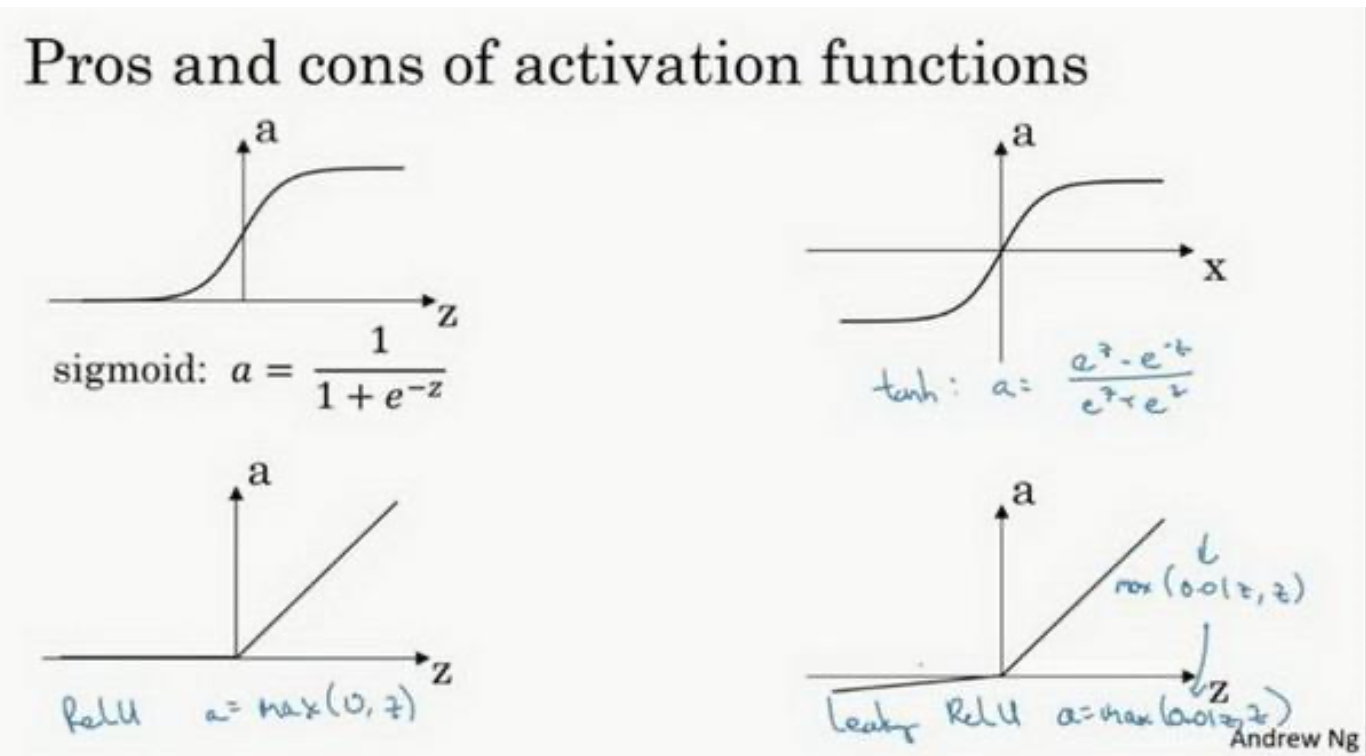
 sigmoid
sigmoid

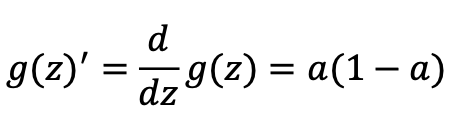 z=0,a=1/2, g’(z)=1/4
z=0,a=1/2, g’(z)=1/4
tanh
值域是位于+1 和-1 之间
导数: ->
->
在讨论优化算法时,有一点要说明:我基本已经不用 sigmoid 激活函数了,tanh 函数在 所有场合都优于 sigmoid 函数,对隐藏层使用 tanh 激活函数。但有一个例外:在二分类的问题中,对于输出层,因为𝑦的值是 0 或 1,所以想让𝑦^ 的数值介于 0 和 1 之间,而不是在-1 和+1 之间。所以需要使用 sigmoid 激活函数。
sigmoid 函数和 tanh 函数两者共同的缺点是,在𝑧特别大或者特别小的情况下,导数的 梯度或者函数的斜率会变得特别小,最后就会接近于 0,导致降低梯度下降的速度。
ReLu


Leaky ReLU

优缺点
1.在𝑧的区间变动很大的情况下,激活函数的导数或者激活函数的斜率都会远大于0,在程序实现就是一个 if-else 语句,而 sigmoid 函数需要进行浮点四则运算,在实践中, 使用 ReLu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。
2.sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和 Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。(同时应该注 意到的是,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性, 而 Leaky ReLu 不会有这问题)
为什么需要非线性激活函数
如果用线性激活函数或者叫恒等激励函数,隐层一点用也没有,因为这两个线性函数的组合本身就是线性函数,那么神经网络只是把输入线性组合再输出。所以除非你引入非线性,否则你无法计算更有趣的函数,即使你的网络层数再多也不行;唯一可以用线性激活函数的通常就是输出层;
只有一个 地方可以使用线性激活函数———𝑔(𝑧) = 𝑧,就是你在做机器学习中的回归问题。

若有收获,就点个赞吧
0 人点赞
