通过kubectl执行autoscale命令kubectl autoscale deployment nginx-deployment --cpu-percent=30 --min=7 --max=8后,HorizontalController会接收到HorizontalPodAutoscaler新增消息,最终会执行HorizontalController.reconcileAutoscaler方法。该方法是控制器的核心逻辑,其执行过程如下:
- 通过
hpa的属性获取对应资源(可以是Deployment也可以是其他)的Scale中的分片数信息; - 进行逻辑判断:
- 若当前分片数为0但最小分片数不为0,则不进行自动扩容;
- 若当前分片数大于
hpa定义的最大分片数则将目标分片数(desiredReplicas)设置成最大分片数; - 若当前分片数小于
hpa定义的最小分片数则将目标分片数设置成该最小分片数; - 都不满足的话则执行第三步跟据
Metrics信息计算需要部署的分片数
- 执行
HorizontalController.computeReplicasForMetrics方法计算目标分片数:- 定义
hpa时可以定义多个指标维度的扩缩容策略,比如cpu等。因此这里会按每个指标信息依次计算目标分片数,最后取最大值作为最终的目标值; - 对于指标(
MetricSpec),k8s对齐进行了分类,主要分为四类,没类的计算方式也不同:- Object: 描述
k8s对象,如hits-per-second; - Pods: 描述目标中每个
Pod信息,如transactions-processed-per-second,而这些值在比较前会进行求平均; - Resource:是
k8s中一个知名度量信息,在request和limit中进行定义的资源; - External:拓展指标信息,来自于
k8s集群之外的信息。- 下面以
Resource为例,来讲解其计算过程(HorizontalController.computeStatusForResourceMetric):
- 下面以
- 最终调用的是
ReplicaCalculator分片计算器的GetRawResourceReplicas方法; - 首先,通过
metricsClient查询每个Pod的Metrics信息; - 进行以下条件判断和计算目标分片数
- 首先计算当前测量的
metric的平均值和目标值的比例(usageRatio); - 若没有未就绪的
pod且当前指标大于目标值时:- 当差值在10%(默认
可容忍值)之内,则直接返回原值; - 若大于10%时,则返回分片数:
usageRatio乘以当前Pod数;
- 当差值在10%(默认
- 如有
Pod未收集到指标信息- 当
usageRatio小于0,将未收集到的指标设置零时为目标值; - 若
usageRatio大于0,将未收集的指标设置零时为0;- 当
usageRatio大于0,将所有未就绪的Pod指标设置为0 - 对修改过的数据重新计算
usageRatio; - 当新的
usageRatio<1.1(0.1是容忍度)或者oldUageRatio<1&&newUsageRatio>1或者oldUageRatio>1&&newUsageRatio<1时,直接返回原值; - 否则返回
newUsageRatio乘以所有pod数量(也及以newUsageRatio比例来扩容)
- 当
- 当
- 首先计算当前测量的
- 并不是计算出来就用这个值,还需要对伸缩速率做一次调整(
normalizeDesiredReplicas):- 根据历史值来调整该值(
stabilizeRecommendation):HPA中保存每次计算结果和时间戳,timestampedRecommendation;HPA启动时会设置一个窗口期downscaleStabilisationWindow(默认5min)- 找到窗口期之内历史计算结果,若历史推荐分片数比当前推荐的大,则覆盖当前的
- 速率限制(
convertDesiredReplicasWithRules)- 防止扩容过快,限制最大不能超过当前实例数的两倍;
- 获取目标分片数时,若与原值不相等则通过
Scales接口将分片数修改成目标值(实际,Scales只是一个包装,其实质是更新Deployment的Replica只) - 当
DeploymentController接收到更新后,就会引发其扩缩容操作
- 获取目标分片数时,若与原值不相等则通过
- 防止扩容过快,限制最大不能超过当前实例数的两倍;
- 根据历史值来调整该值(
- Object: 描述
- 定义
到此,HPA的单次操作执行流程就介绍完了,下面以一张图来简要描述该过程: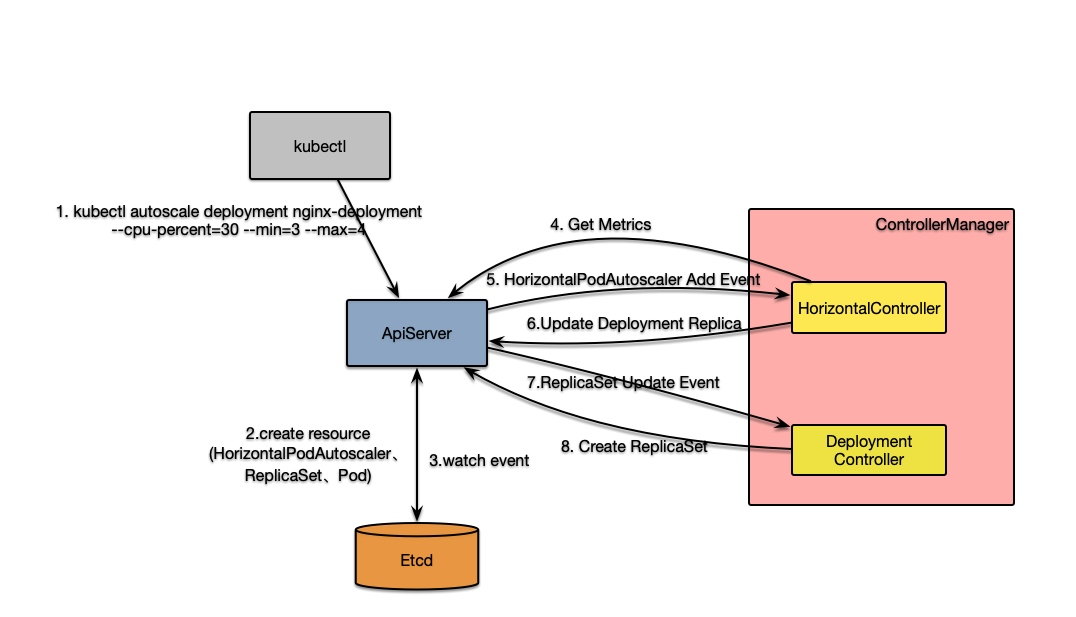

若有收获,就点个赞吧
0 人点赞
