runc
runc is a command-line based tool for creating and managing containers. So similar with docker, runc can also create a container by itself.
How to use
Follow Using runc, it is easy use. When generating spec, use
runc spec --rootless
Is usernamespace used?
runc spec --rootless will generate config.json containing the following info, in which we can see user namespace is used.
"linux": {"uidMappings": [{"containerID": 0,"hostID": 1001,"size": 1}],"gidMappings": [{"containerID": 0,"hostID": 1001,"size": 1}],"namespaces": [{"type": "pid"},{"type": "ipc"},{"type": "uts"},{"type": "mount"},{"type": "user"}],......}
gVisor
Enable Debugging
gvisor github README contains instructions to enable debugging.
Is usernamespace used?
runsc.log.20181125-211542.834804.create log shows that
I1125 21:15:42.852862 31818 x:0] Sandbox will be started in new mount, IPC and UTS namespacesI1125 21:15:42.852881 31818 x:0] Sandbox will be started in the current PID namespaceI1125 21:15:42.852895 31818 x:0] Sandbox will be started in the container's network namespace: {Type:network Path:}I1125 21:15:42.852916 31818 x:0] Sandbox will be started in new user namespaceI1125 21:15:42.853051 31818 x:0] Sandbox will be started in minimal chroot
By trace the log, we can find that in runsc/sandbox/sandbox.go, UserNameSpace is used.
How ptrace works
Intercepting and Emulating Linux System Calls with Ptrace gives a good explaination of how ptrace works. The code is https://github.com/skeeto/ptrace-examples.
In addition, when running ./example, it will show XPledge failed: Function not implemented, because it cannot find xpledge(arg), which is syscall(10000, arg), system call 10000 does not exist.
However, when running ./xpledge ./example, xpledge works and open system call is blocked. The example process is traced by xpledge process. xpledge process gets the syscall number from regs.orig_rax,
/* Special handling per system call (entrance) */switch (regs.orig_rax) {case SYS_exit:exit(regs.rdi);case SYS_exit_group:exit(regs.rdi);case SYS_xpledge:set_xpledge(regs.rdi);break;}
SYS_xpledge case handles the syscall 10000, then when syscall return, it replaces the return value to 0 by
/* Special handling per system call (exit) */switch (regs.orig_rax) {case -1:if (ptrace(PTRACE_POKEUSER, pid, RAX * 8, -EPERM) == -1)FATAL("%s", strerror(errno));break;case SYS_xpledge:if (ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0) == -1)FATAL("%s", strerror(errno));break;}
If above code is removed, ./xpledge ./example will also show XPledge failed: Function not implemented, same with ./example.
From user mode linux (UML), “UML uses ptrace() and PTRACE_SYSCALL to catch system calls. But, in this way, you can’t remove the real system call, only monitor it. UML, to avoid the real syscall and emulate it, replaces the real syscall by a call to getpid(). This method generates two context-switches instead of one.”, we know that
- ptrace cannot avoid syscall totally, it must call one, such as getpid()
PTRACE_SYSCALLstops at system call entry and exit, introduces 3 context switches.PTRACE_SYSEMUstops only once, introduces 2 context switches.How gvisor uses ptrace
This is straight forward, sentry process acts as tracer while application process is the tracee. Application process system call will stop by PTRACE and wait for sentry to handle. Sentry can emulate the system call, replace the real system with getpid(), and return.How KVM works
Using the KVM API briefly goes through a small example kvmtest.c to show how KVM work.
kvm-hello-world is also a minimal KVM example.
In short, /dev/kvm dev files provides commands to create and copy code to the vm. The vm will directly run on host machine.How gvisor uses KVM
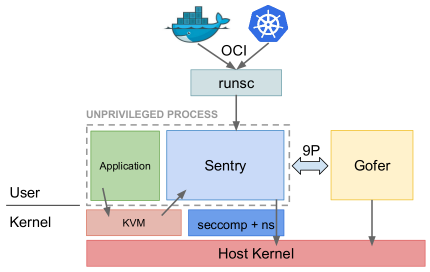
This figure is from the presentation of Dawn Chen and Zhengyu He.
From How gvisor trap to syscall handler in kvm platform, “On the KVM platform, system call interception works much like a normal OS. When running in guest mode, the platform sets MSR_LSTAR to a system call handler sysenter, which is invoked whenever an application (or the sentry itself) executes a SYSCALL instruction.” ```Application —> Guest Ring 3
GUESTSentry (ring0) --> Guest Ring 0
HOST
Sentry (kvm) --> Host Ring 3-------------Host kernel --> Host Ring 0
1. How are application system calls trapped into Sentry (ring0) on GUEST?<br />Application runs in guest ring 3, and sentry runs in guest ring 0. MSR_LSTAR is configured, so that syscall in ring3 will trap into ring 0 automatically.<br />1. How are Sentry system calls trapped into host kernel?<br />From [How gvisor trap to syscall handler in kvm platform](https://groups.google.com/forum/#!msg/gvisor-users/15FfcCilupo/9ARSLnH3BQAJ), “Note that the SYSCALL instruction (Wenbo: in sentry guest ring 0) works just fine from ring 0, it just doesn’t perform a ring switch since you’re already in ring 0 (guest). Yup, the syscall handler executes a HLT, which is the trigger to switch back to host mode. To see the host/guest transition internals take a look at bluepill() (switch to guest mode) and redpill() (switch to host mode) in platform/kvm. The control flow is bit hard to follow. At a high level it goes: bluepill() -> execute CLI (allowed if already in guest mode, or …) -> SIGILL signal handler -> bluepillHandler() -> KVM_RUN with RIP @ CLI instruction -> execute CLI in guest mode, bluepill() returns”<br />[谷歌新作gVisor:VM容器融合技术已经到来](https://mp.weixin.qq.com/s?__biz=MzIzNjUxMzk2NQ==&mid=2247489400&idx=1&sn=4f099bdfb41e046f430acb135d0817eb&chksm=e8d7e8badfa061acd9192cb34129d8ed52343bf93eacfdb065def7aeaafa3e8814d64f5d9dc0&mpshare=1&scene=1&srcid=0606UOl35H7zKWsKw8mb8Bh1&pass_ticket=Qfl2R7tSo7pzU2zT13kElc4t25g1FLglN07rolsYu2Oh2D4EB1H6CT97Y6fhfMEY#rd) is also a good technical introduction for gvisor.<a name="enable-kvm-on-ubuntu-1804"></a>#### Enable KVM on Ubuntu 18.04[install-configure-kvm-ubuntu-18-04-server](https://www.linuxtechi.com/install-configure-kvm-ubuntu-18-04-server/) gives good instructions, run
sudo apt install cpu-checker sudo kvm-ok ``` May need to enable VT in BIOS, on Thinkpad X1, use F1 or F2 to enter BIOS, VT is under Security
gvisor Security issues
Containerize Linux Kernel analysed the gvisor security problems.
- No kernel page table isolation. Now all sentry kernel is mapped into app’s kernel address. Easy to fix
Sentry ring 0 and Sentry are the same, only sentry, which allows code jumping to each other and there is no vm-isolation. Should utilize kvmk isolation.
gvisor CVEs
NCC groups 11.7 Unikernels and Microhypervisors and Hybrid Models
gvisor kernel hardening
Buffer overflow, Go checks for bounds in strings, arrays and slices so it is not vulnerable as long as you are not playing around with unsafe package..
- Kernel Control Flow Integrity protection, including function pointer and return address protection.
- copy_to/from_user, addr limit
- User space ASLR, kernel space ASLR.
- SMAP and SMEP, X-only memory, kernel code protection
-
Kata Container
kata container is OCI interface backed by VM solution. Based on traditional VM solutions, each container is a virtual machine.
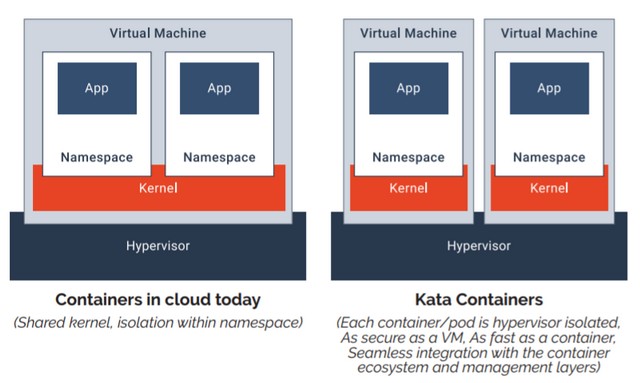
Kata Containers and gVisor a Quantitative Comparison was presented on OpenStack summit in berlin (Nov 2018).
The summary is Kata and gvisor share similar performance.
- Kata is based on Linux kernel, support more system calls, therefore, better compatibility.
Another gvisor and kata container comparison is Containerize Linux Kernel.
KVM on ARM
Kernel KVM code go through is in KVM Internal: How a VM is Created?. From Paper Optimizing the Design and Implementation of the Linux ARM Hypervisor.
Virtualization Host Extensions (VHE) on ARMv8.1
Reference is Optimizing the Design and Implementation of KVM/Arm
- HCR_EL2.E2H enables and disables VHE
- Run host kernel on EL2, no stage 2 translation table overhead
- Reduce hypercall overhead

若有收获,就点个赞吧
0 人点赞
