kube-apiserver的任务
我们通常使用kubectl命令删除Pod,或者通过http协议直接调用apiserver暴露的接口去删除Pod。所以,删除Pod的起源肯定在apiserver这儿。
在之前分析kube-apiserver部分有分析到,kube-apiserver的http处理架构使用的是go-restful。其中,对于删除,调用的自然是DELETE接口。方法如下(位于kubernetes/staging/src/k8s.io/apiserver/pkg/endpoints/install.go下的registerResourceHandlers方法)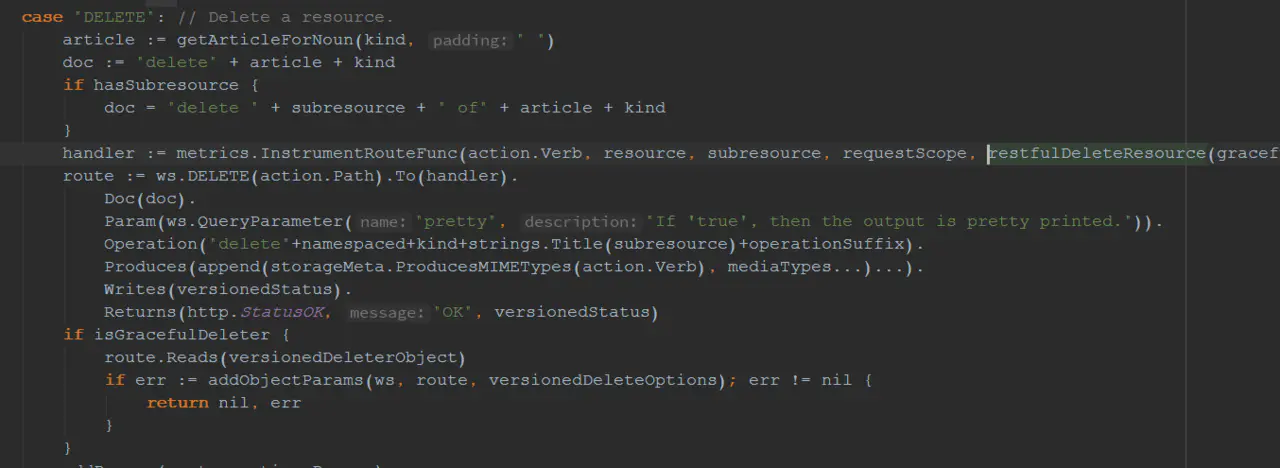 该方法最终的处理handler为
该方法最终的处理handler为restfulDeleteResource
restfulDeleteResource继续封装handler,调用了DeleteResource方法。DeleteResource方法很长,但最终调用的还是DELETE方法,如下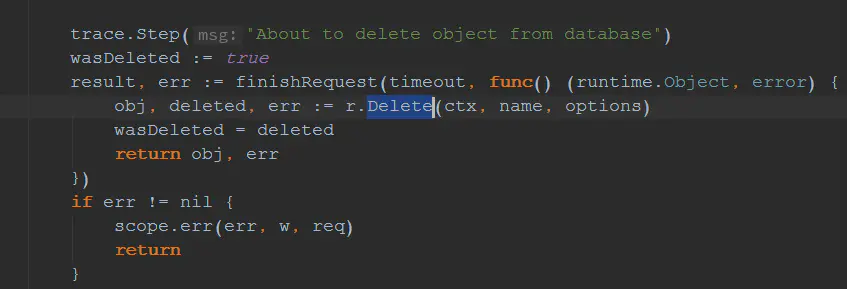
DELETE方法位于staging/src/k8s.io/apiserver/pkg/registry/generic/registry/store.go下。在DELETE方法中,最主要的是updateForGracefulDeletionAndFinalizers方法,该方法的主要作用就是用来改变Pod的一些内部信息,其实就是改变Pod的两个字段:DeletionTimestamp以及DeletionGracePeriodSeconds,调用的是BeforeDelete方法 通过比对工具也可以发现,主要的字段改变如下
通过比对工具也可以发现,主要的字段改变如下
核心是rest.BeforeDelete判断,来决定是否执行graceful delete。而BeforeDelete是根据 DeleteStrategy来判断的:
实现了RESTGracefulDeleteStrategy的只有podStrategy。
同时,在store.go的Delete中,还会根据graceful || pendingFinalizers || shouldUpdateFinalizers 这三个条件来判断是否可以立即删除
例如 Finalizers处理的函数是:updateForGracefulDeletionAndFinalizers,也会设置deletionTimestamp
kubelet的任务
通过之前分析过kubelet的代码得知,kubelet一直在通过listwatch监听apiserver的变化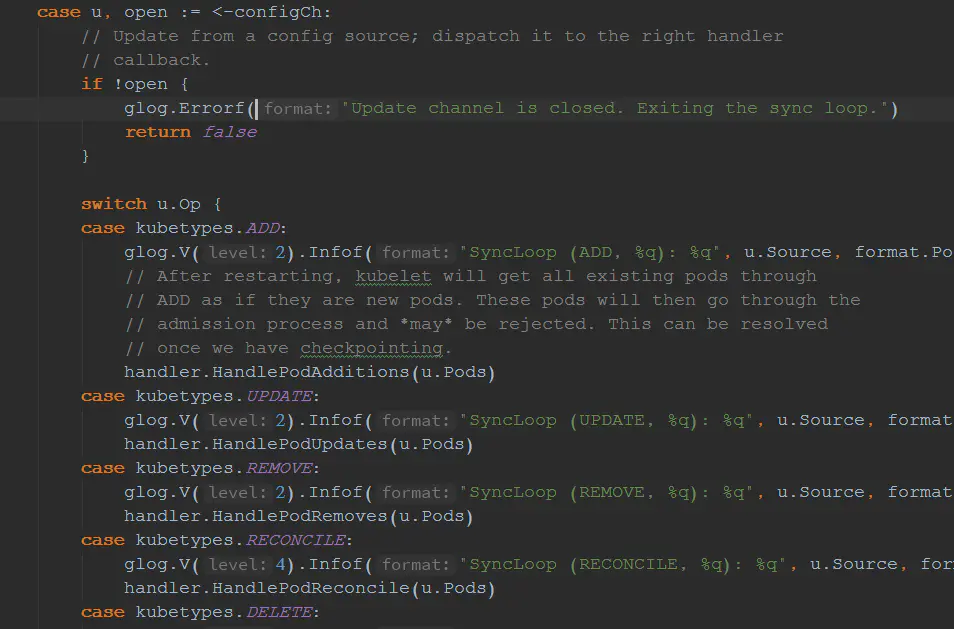 如图,监听到相应的变化之后,调用相应的处理逻辑。同时,kubelet还启动了一个goroutine:statusManager
如图,监听到相应的变化之后,调用相应的处理逻辑。同时,kubelet还启动了一个goroutine:statusManager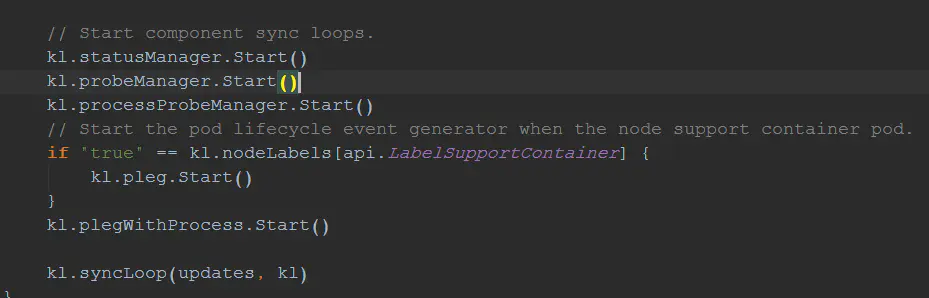 在syncLoop之前调用了statusManager的start方法启动statusManager。
在syncLoop之前调用了statusManager的start方法启动statusManager。
start方法如下: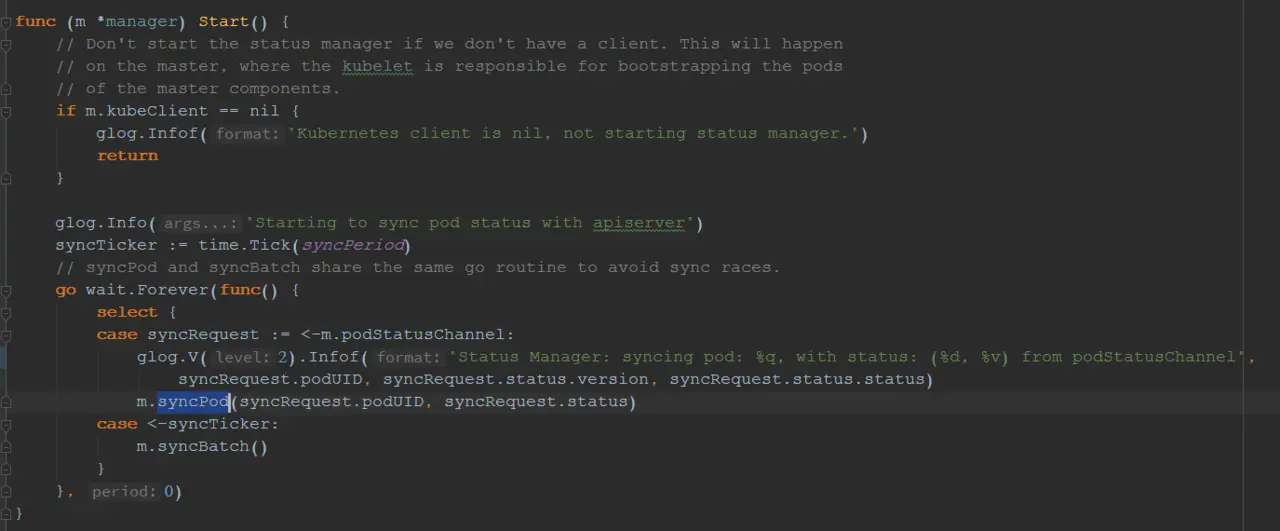 主要的任务就是通过监听事件的变化,调用syncPod方法。在syncPod方法有下面一段代码
主要的任务就是通过监听事件的变化,调用syncPod方法。在syncPod方法有下面一段代码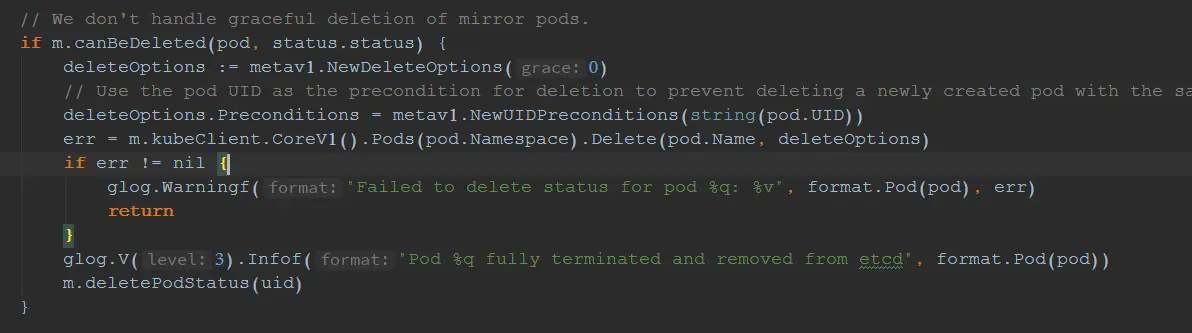 我们发现,kubelet又去调用了一次DELETE接口,这是为什么呢?不是已经删除了吗?别急,这才是我们要分析的DELETE操作最核心的部分。
我们发现,kubelet又去调用了一次DELETE接口,这是为什么呢?不是已经删除了吗?别急,这才是我们要分析的DELETE操作最核心的部分。
深层分析
我们知道,Pod的删除如果不去强制删除,则其实是一个优雅的删除,也就是一个graceful的删除。默认情况下,这个优雅的时间是30s,也就是grace-period的时间。在kube-apiserver的任务中,通过updateForGracefulDeletionAndFinalizers方法为Pod设置了DeletionTimestamp和DeletionGracePeriodSeconds两个字段,此时Pod定义为graceful的状态。回到代码处,调用完updateForGracefulDeletionAndFinalizers方法后,下面有一个判断的语句 很显然,因为我们是优雅删除,所以deleteImmediately字段false,删除到此结束。是不是与我们想象的完全不一样?
很显然,因为我们是优雅删除,所以deleteImmediately字段false,删除到此结束。是不是与我们想象的完全不一样?
没错,实际情况的确是这样,每次删除的时候,apiserver的处理逻辑到此就中断了。接下来就要重新认识kubelet了。
Kubelet在调用apiserver的删除接口的时候,提前会有一个判断,调用链为canBeDeleted-->PodResourcesAreReclaimed。在PodResourcesAreReclaimed方法内,主要的任务就是判断Pod内的资源是否已经完全关闭和清理,包括containers、processes、volumes以及cgroup sandbox资源。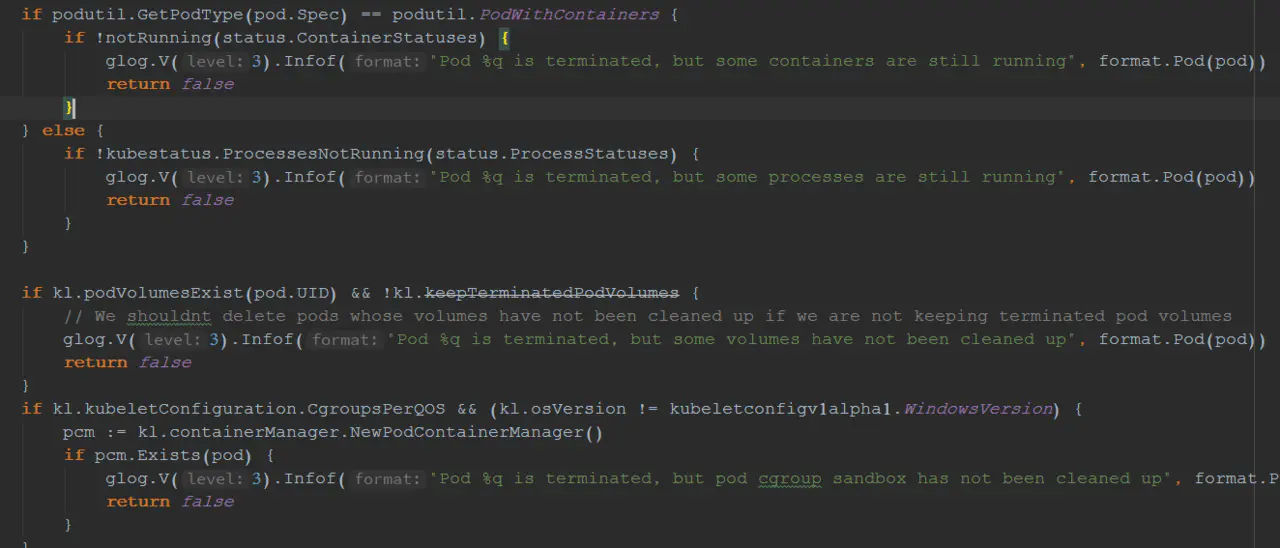 当所有的资源都清理干净之后,此时
当所有的资源都清理干净之后,此时canBeDeleted方法返回true,kubelet调用apiserver的delete接口再次删除Pod。不过,与优雅删除不同的是,这次调用,多了一个deleteOptions字段 意思很好理解,就是设置grace-period字段为0,表示这次是强制删除Pod。因此,apiserver会再次收到DELETE的请求,继续执行DELETE handler的流程。与第一次不同的时,这次是强制删除Pod,所以会执行完整的过程,apiserver去etcd删除最终的Pod信息。
意思很好理解,就是设置grace-period字段为0,表示这次是强制删除Pod。因此,apiserver会再次收到DELETE的请求,继续执行DELETE handler的流程。与第一次不同的时,这次是强制删除Pod,所以会执行完整的过程,apiserver去etcd删除最终的Pod信息。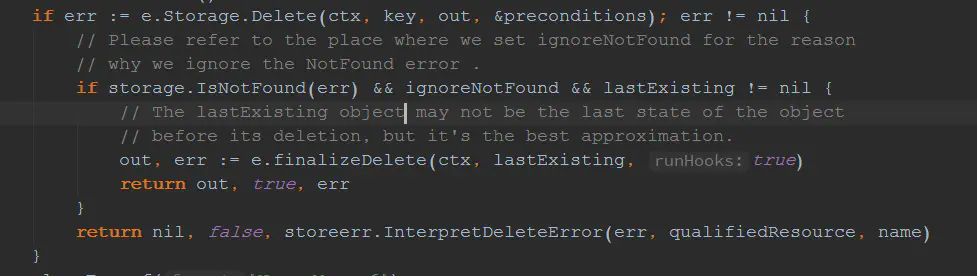 kubelet接收到事件变化之后,转化为REMOVE事件,完成Pod的最终清理工作。至此,Pod删除流程结束。
kubelet接收到事件变化之后,转化为REMOVE事件,完成Pod的最终清理工作。至此,Pod删除流程结束。
总结
优雅删除Pod时:
1、apiserver handler执行了两次,第一次主要是修改Pod信息,设置DeletionTimestamp和DeletionGracePeriodSeconds信息,第二次去数据库etcd删除Pod信息;
2、kubelet通过检测到Pod内的资源已经完全释放之后,触发了第二次删除事件,且是强制删除Pod;
3、kubelet的DELETE操作其实监听到的是Pod的更新事件,Pod删除之后,执行的是REMOVE操作;
4、处理流程为:客户端请求删除Pod-->apiserver更新Pod信息-->kubelet优雅释放Pod资源-->kubelet请求删除Pod-->apiserver删除etcd中Pod信息-->kubelet完成最终Pod的资源清理。

若有收获,就点个赞吧
0 人点赞
