为了降低 Pod 的管理开销,提升 Kubelet 的性能和可扩展性,引入了 PLEG,改进了之前的工作方式:
- 减少空闲期间的不必要工作(例如 Pod 的定义和容器的状态没有发生更改)。
- 减少获取容器状态的并发请求数量。
整体的工作流程如下图所示,虚线部分是 PLEG 的工作内容。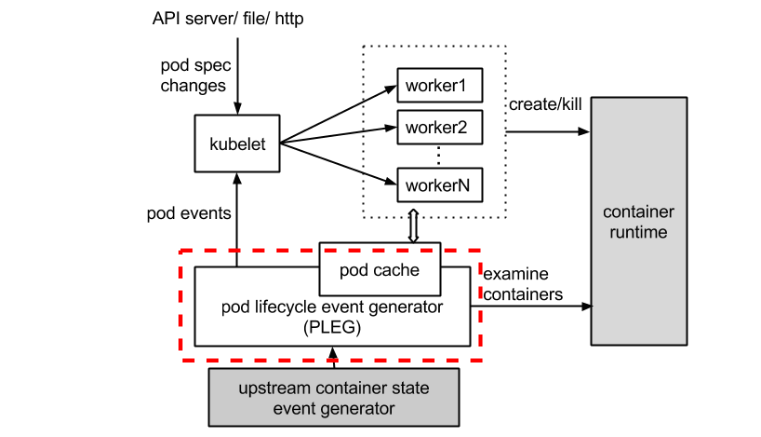
Healthy() 函数会以 “PLEG” 的形式添加到 runtimeState 中,Kubelet 在一个同步循环(SyncLoop() 函数)中会定期(默认是 10s)调用 Healthy() 函数。Healthy() 函数会检查 relist 进程(PLEG 的关键任务)是否在 3 分钟内完成。如果 relist 进程的完成时间超过了 3 分钟,就会报告 PLEG is not healthy。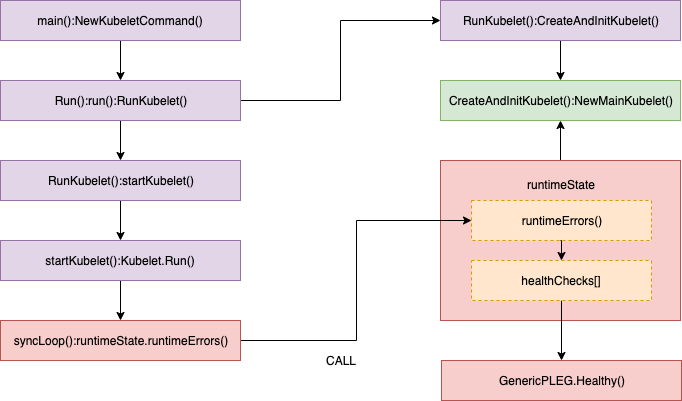
深入解读 relist 函数
上文提到 healthy() 函数会检查 relist 的完成时间,但 relist 究竟是用来干嘛的呢?解释 relist 之前,要先解释一下 Pod 的生命周期事件。Pod 的生命周期事件是在 Pod 层面上对底层容器状态改变的抽象,使其与底层的容器运行时无关,这样就可以让 Kubelet 不受底层容器运行时的影响。
type PodLifeCycleEventType stringconst (ContainerStarted PodLifeCycleEventType = "ContainerStarted"ContainerStopped PodLifeCycleEventType = "ContainerStopped"NetworkSetupCompleted PodLifeCycleEventType = "NetworkSetupCompleted"NetworkFailed PodLifeCycleEventType = "NetworkFailed")// PodLifecycleEvent is an event reflects the change of the pod state.type PodLifecycleEvent struct {// The pod ID.ID types.UID// The type of the event.Type PodLifeCycleEventType// The accompanied data which varies based on the event type.Data interface{}}
以 Docker 为例,在 Pod 中启动一个 infra 容器就会在 Kubelet 中注册一个 NetworkSetupCompleted Pod 生命周期事件。
那么 PLEG 是如何知道新启动了一个 infra 容器呢?它会定期重新列出节点上的所有容器(例如 docker ps),并与上一次的容器列表进行对比,以此来判断容器状态的变化。其实这就是 relist() 函数干的事情,尽管这种方法和以前的 Kubelet 轮询类似,但现在只有一个线程,就是 PLEG。现在不需要所有的线程并发获取容器的状态,只有相关的线程会被唤醒用来同步容器状态。而且 relist 与容器运行时无关,也不需要外部依赖,简直完美。
下面我们来看一下 relist() 函数的内部实现。
relist 函数第一步就是记录 Kubelet 的相关指标(例如kubelet_pleg_relist_latency_microseconds),然后通过 CRI 从容器运行时获取当前的 Pod 列表(包括停止的 Pod)。该 Pod 列表会和之前的 Pod 列表进行比较,检查哪些状态发生了变化,然后同时生成相关的 Pod 生命周期事件和更改后的状态。
完整的流程如下图所示: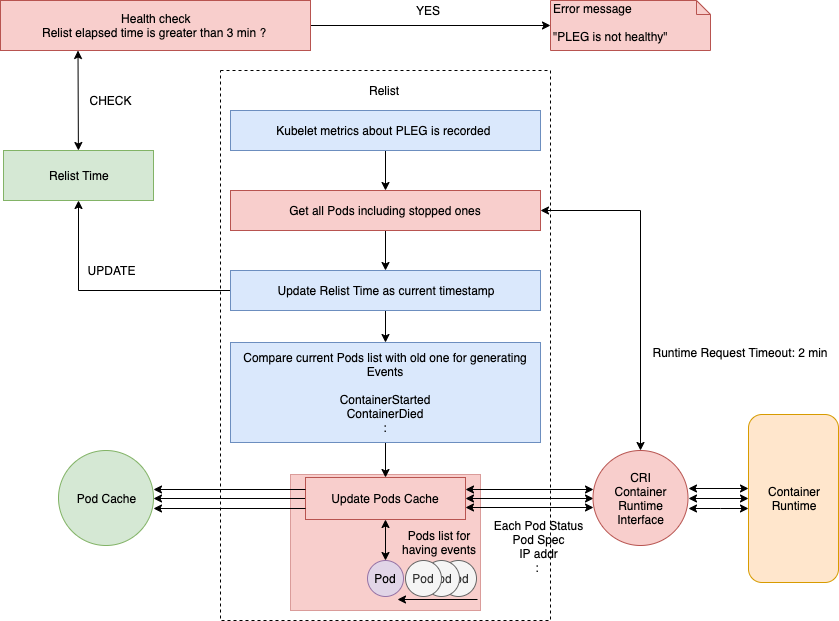
其中 generateEvents() 函数(computeEvents() 函数会调用它)用来生成相应的 Pod 级别的事件(例如 ContainerStarted、ContainerDied 等等),然后通过 updateEvents() 函数来更新事件。
updateCache() 将会检查每个 Pod,并在单个循环中依次对其进行更新。因此,如果在同一个 relist 中更改了大量的 Pod,那么 updateCache 过程将会成为瓶颈。
最后,更新后的 Pod 生命周期事件将会被发送到 eventChannel。eventChannel 对应的就是kubelet syncLoop的PLEG事件channal

若有收获,就点个赞吧
0 人点赞
