做深度学习时,最麻烦的一件事情就是等待,等待训练过程的结束往往要耗费大量时间,如果我们曾经训练过某个模型,下次使用时又需要重新训练一遍,为此不得不再等上好久,这部分等待时间是毫无意义的。因此训练过模型之后,及时地添加代码然后保存模型就可以节省很多时间,下一次要用到模型的时候,直接加载即可。
直接保存/加载模型本身


下面以利用内置数据集一览Pytorch实现图像识别为例,展示模型保存和模型加载的用法。
保存模型
# ...模型训练完成torch.save(model, '/mnt/main/pkl_checkpoint_file/plain_CNNet.pkl') #保存速度很慢
加载模型并测试
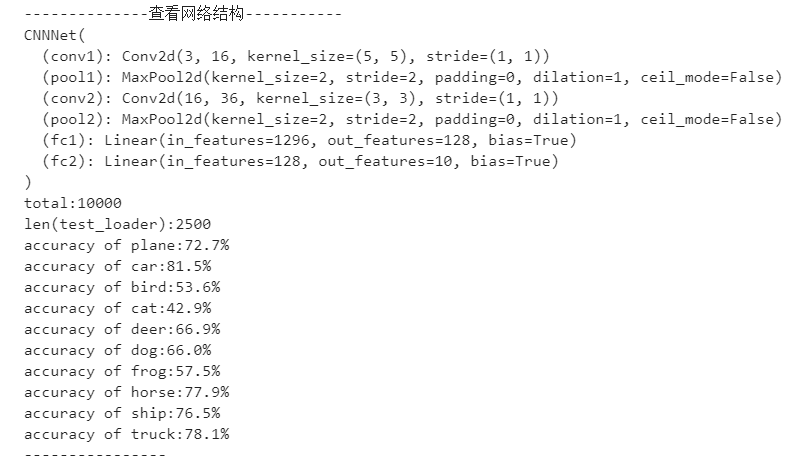
# 导入模块和加载数据集部分略model = torch.load('/mnt/main/pkl_checkpoint_file/plain_CNNet.pkl')model = model.to(device)print('--------------查看网络结构-----------')print(model)#测试模型eval_loss = 0eval_acc = 0class_correct = list(0. for i in range(10))class_total = list(0. for i in range(10))total = 0model.eval()with torch.no_grad():for img, label in test_loader:img, label = img.to(device), label.to(device)out = model(img)#计算损失值loss = criterion(out,label)eval_loss += loss.item()#计算准确率_, pred = out.max(1)#print("len(label):{}".format(len(label)))num_correct += (pred == label).sum()c = (pred == label).squeeze()acc = num_correct/len(label)eval_acc += acctotal += label.size(0)#计算各类别准确率for i in range(4):class_correct[label[i]] += c[i].item()class_total[label[i]] += 1eval_losses.append(eval_loss/total)eval_acces.append(eval_acc/total)print("total:{}".format(total))print("len(test_loader):{}".format(len(test_loader)))for i in range(10):print("accuracy of {}:{}%".format(classes[i],100*class_correct[i]/class_total[i]))print("----------------")
输出结果

保存/加载模型的参数
这种只保存参数未保存结构的方法的优点就是保存、加载都很快。但是由于没有保存结构,因此加载之前还是需要先定义一下结构。加载的时候,是把参数加载到空的网络之中。
示例:(莫烦习惯用这个)
torch.save(net1.state_dict(),'net_params.pkl')net2 = torchvision.models.resnet18()net2.load_state_dict(torch.load('net_params.pkl'))
下面同样以利用内置数据集一览Pytorch实现图像识别为例,展示只保存模型参数和加载模型参数的用法。
保存模型参数
# ...模型训练完成torch.save(model.state_dict(),'/mnt/main/pkl_checkpoint_file/plain_CNNet_params.pkl') #保存速度极快
加载模型参数
# 导入模块和加载数据集部分略#定义网络结构class CNNNet(nn.Module):def __init__(self):super(CNNNet, self).__init__()self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)self.conv2 = nn.Conv2d(in_channels=16,out_channels=36,kernel_size=3,stride=1)self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)#self.aap = nn.AdaptiveAvgPool2d(1)self.fc1 = nn.Linear(1296,128)self.fc2 = nn.Linear(128,10)#self.fc3 = nn.Linear(36,10)def forward(self,x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2(x)))#x = self.aap(x)#x = x.view(x.shape[0],-1)#x = self.fc3(x)x = x.view(-1,36*6*6)#print("x.shape:{}".format(x.shape))x = F.relu(self.fc2(F.relu(self.fc1(x))))return xmodel2 = CNNNet()model2 = model2.to(device)print('--------------查看网络结构-----------')print(model2)model2.load_state_dict(torch.load('/mnt/main/pkl_checkpoint_file/plain_CNNet_params.pkl'))#测试模型eval_loss = 0eval_acc = 0class_correct = list(0. for i in range(10))class_total = list(0. for i in range(10))total = 0model2.eval()with torch.no_grad():for img, label in test_loader:img, label = img.to(device), label.to(device)out = model2(img)#计算损失值loss = criterion(out,label)eval_loss += loss.item()#计算准确率_, pred = out.max(1)#print("len(label):{}".format(len(label)))num_correct += (pred == label).sum()c = (pred == label).squeeze()acc = num_correct/len(label)eval_acc += acctotal += label.size(0)#计算各类别准确率for i in range(4):class_correct[label[i]] += c[i].item()class_total[label[i]] += 1eval_losses.append(eval_loss/total)eval_acces.append(eval_acc/total)print("total:{}".format(total))print("len(test_loader):{}".format(len(test_loader)))for i in range(10):print("accuracy of {}:{}%".format(classes[i],100*class_correct[i]/class_total[i]))print("----------------")
输出结果
[

若有收获,就点个赞吧
0 人点赞
