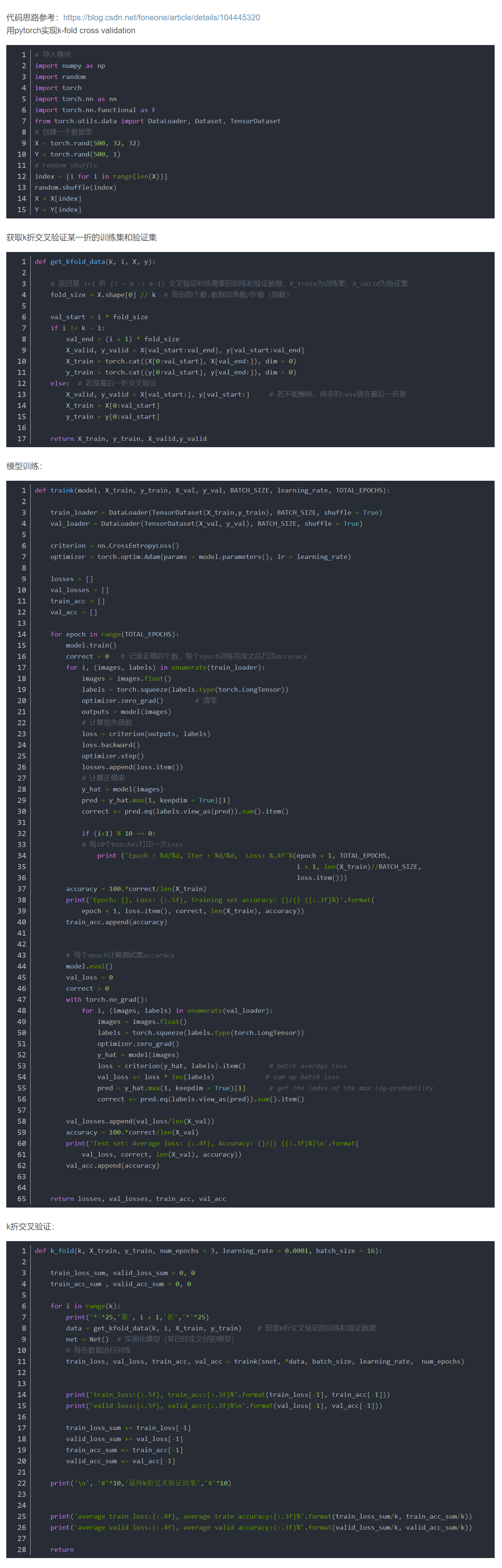
实例:
# 导入模块import numpy as npimport randomimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.data import DataLoader, Dataset, TensorDatasetfrom torchvision import modelsnet = models.resnet18(pretrained=True)# 创建一个数据集X = torch.rand(500,3, 32, 32)Y = torch.rand(500, 1)# random shuffleindex = [i for i in range(len(X))]random.shuffle(index)X = X[index]Y = Y[index]def get_kfold_data(k, i, X, y):# 返回第 i+1 折 (i = 0 -> k-1) 交叉验证时所需要的训练和验证数据,X_train为训练集,X_valid为验证集fold_size = X.shape[0] // k # 每份的个数:数据总条数/折数(组数)val_start = i * fold_sizeif i != k - 1:val_end = (i + 1) * fold_sizeX_valid, y_valid = X[val_start:val_end], y[val_start:val_end]X_train = torch.cat((X[0:val_start], X[val_end:]), dim=0)y_train = torch.cat((y[0:val_start], y[val_end:]), dim=0)else: # 若是最后一折交叉验证X_valid, y_valid = X[val_start:], y[val_start:] # 若不能整除,将多的case放在最后一折里X_train = X[0:val_start]y_train = y[0:val_start]return X_train, y_train, X_valid, y_validdef traink(model, X_train, y_train, X_val, y_val, BATCH_SIZE, learning_rate, TOTAL_EPOCHS):train_loader = DataLoader(TensorDataset(X_train, y_train), BATCH_SIZE, shuffle=True)val_loader = DataLoader(TensorDataset(X_val, y_val), BATCH_SIZE, shuffle=True)criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(params=model.parameters(), lr=learning_rate)losses = []val_losses = []train_acc = []val_acc = []for epoch in range(TOTAL_EPOCHS):model.train()correct = 0 # 记录正确的个数,每个epoch训练完成之后打印accuracyfor i, (images, labels) in enumerate(train_loader):images = images.float()labels = torch.squeeze(labels.type(torch.LongTensor))optimizer.zero_grad() # 清零outputs = model(images)# 计算损失函数loss = criterion(outputs, labels)loss.backward()optimizer.step()losses.append(loss.item())# 计算正确率y_hat = model(images)pred = y_hat.max(1, keepdim=True)[1]correct += pred.eq(labels.view_as(pred)).sum().item()if (i + 1) % 10 == 0:# 每10个batches打印一次lossprint('Epoch : %d/%d, Iter : %d/%d, Loss: %.4f' % (epoch + 1, TOTAL_EPOCHS,i + 1, len(X_train) // BATCH_SIZE,loss.item()))accuracy = 100. * correct / len(X_train)print('Epoch: {}, Loss: {:.5f}, Training set accuracy: {}/{} ({:.3f}%)'.format(epoch + 1, loss.item(), correct, len(X_train), accuracy))train_acc.append(accuracy)# 每个epoch计算测试集accuracymodel.eval()val_loss = 0correct = 0with torch.no_grad():for i, (images, labels) in enumerate(val_loader):images = images.float()labels = torch.squeeze(labels.type(torch.LongTensor))optimizer.zero_grad()y_hat = model(images)loss = criterion(y_hat, labels).item() # batch average lossval_loss += loss * len(labels) # sum up batch losspred = y_hat.max(1, keepdim=True)[1] # get the index of the max log-probabilitycorrect += pred.eq(labels.view_as(pred)).sum().item()val_losses.append(val_loss / len(X_val))accuracy = 100. * correct / len(X_val)print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.3f}%)\n'.format(val_loss, correct, len(X_val), accuracy))val_acc.append(accuracy)return losses, val_losses, train_acc, val_accdef k_fold(k, X_train, y_train, num_epochs=3, learning_rate=0.0001, batch_size=16):train_loss_sum, valid_loss_sum = 0, 0train_acc_sum, valid_acc_sum = 0, 0for i in range(k):print('*' * 25, '第', i + 1, '折', '*' * 25)data = get_kfold_data(k, i, X_train, y_train) # 获取k折交叉验证的训练和验证数据#net = net() # 实例化模型(某已经定义好的模型)# 每份数据进行训练train_loss, val_loss, train_acc, val_acc = traink(net, *data, batch_size, learning_rate, num_epochs)print('train_loss:{:.5f}, train_acc:{:.3f}%'.format(train_loss[-1], train_acc[-1]))print('valid loss:{:.5f}, valid_acc:{:.3f}%\n'.format(val_loss[-1], val_acc[-1]))train_loss_sum += train_loss[-1]valid_loss_sum += val_loss[-1]train_acc_sum += train_acc[-1]valid_acc_sum += val_acc[-1]print('\n', '#' * 10, '最终k折交叉验证结果', '#' * 10)print('average train loss:{:.4f}, average train accuracy:{:.3f}%'.format(train_loss_sum / k, train_acc_sum / k))print('average valid loss:{:.4f}, average valid accuracy:{:.3f}%'.format(valid_loss_sum / k, valid_acc_sum / k))returnk_fold(10, X, Y, num_epochs=3, learning_rate=0.0001, batch_size=16)

若有收获,就点个赞吧
0 人点赞
