CrawlSpider
创建项目
# 进入文件夹 cd命令cd C:\Users\41999\Documents\PycharmProjects\Python\TZ—Spyder\第六节Scrapy(三)# 查看命令scrapy genspider# 罗列所有模板scrapy genspider -l# 选择模板并且创建scrapy genspider -t crawl zh xxx.com
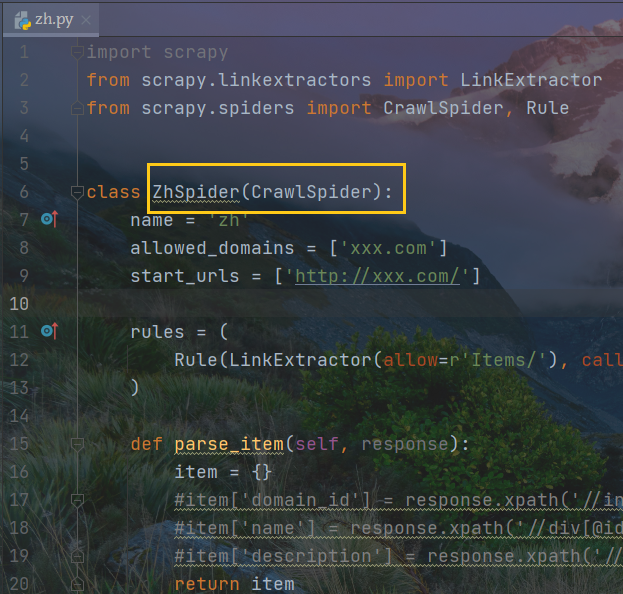
Rule讲解
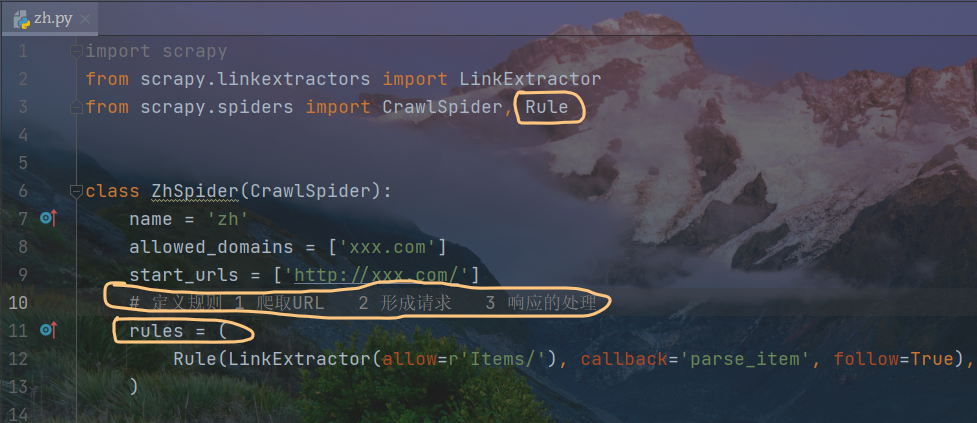
定义规则
1 爬取URL
2 形成请求
3 响应的处理
方法描述
rule处理响应数据response, Extractor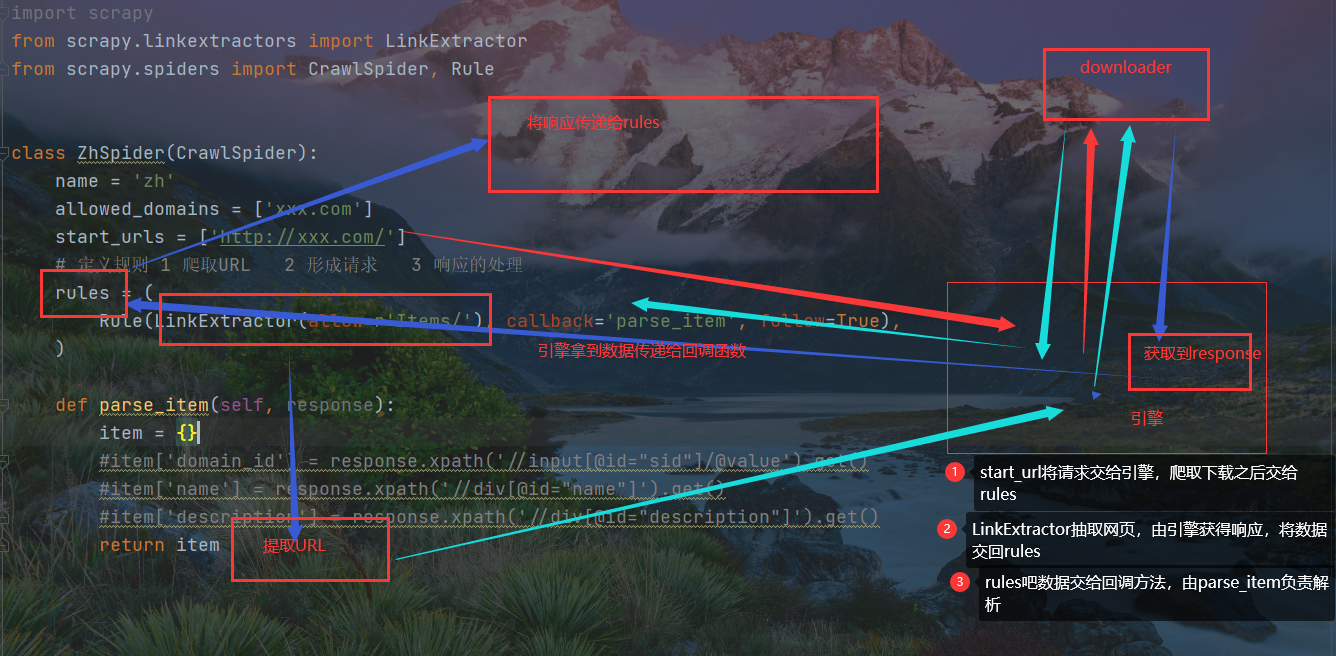
follow影响链接的去向
案例实践
对网站的分析
四个主要的网页对象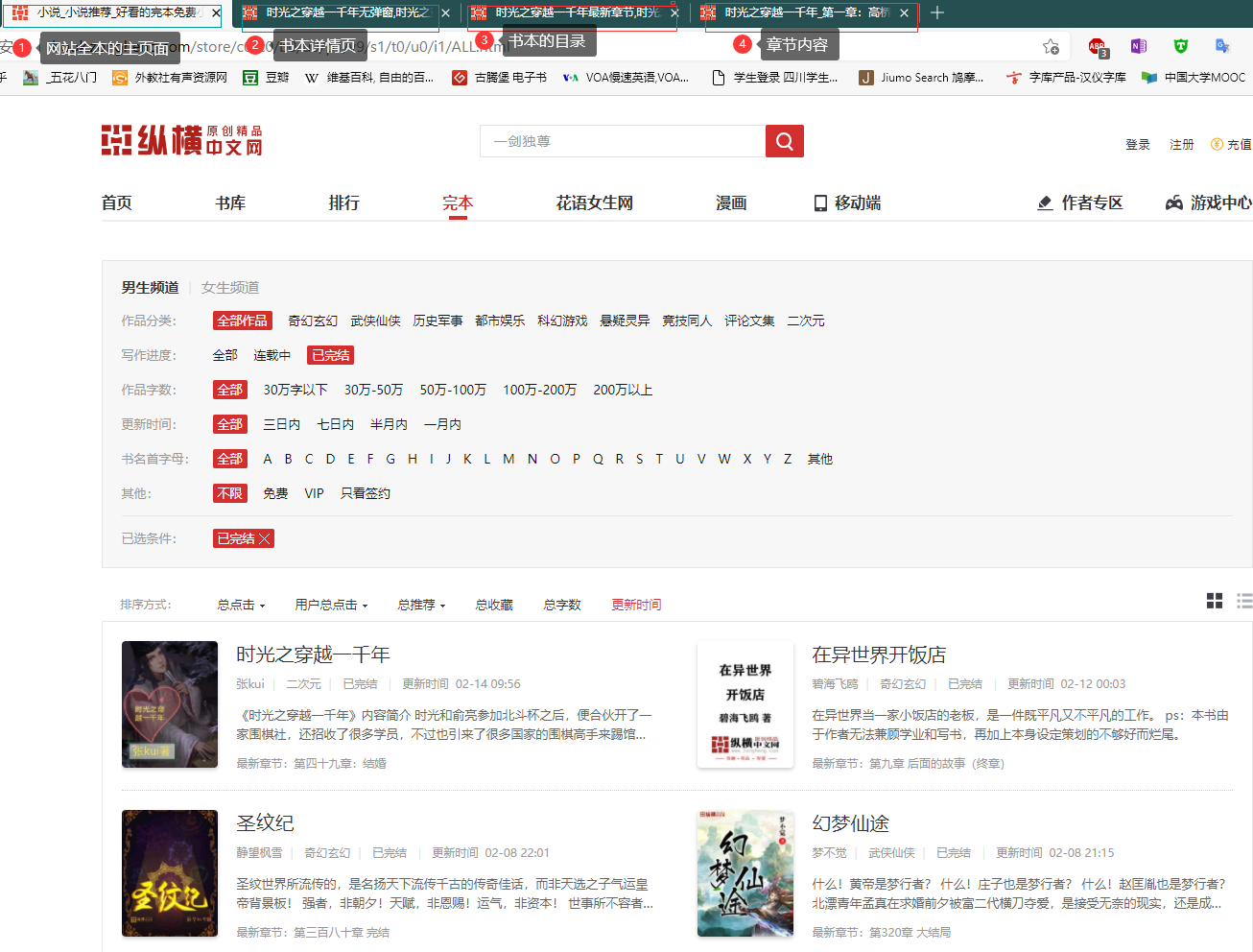
2 在书本详情页源码中确认信息是否包含
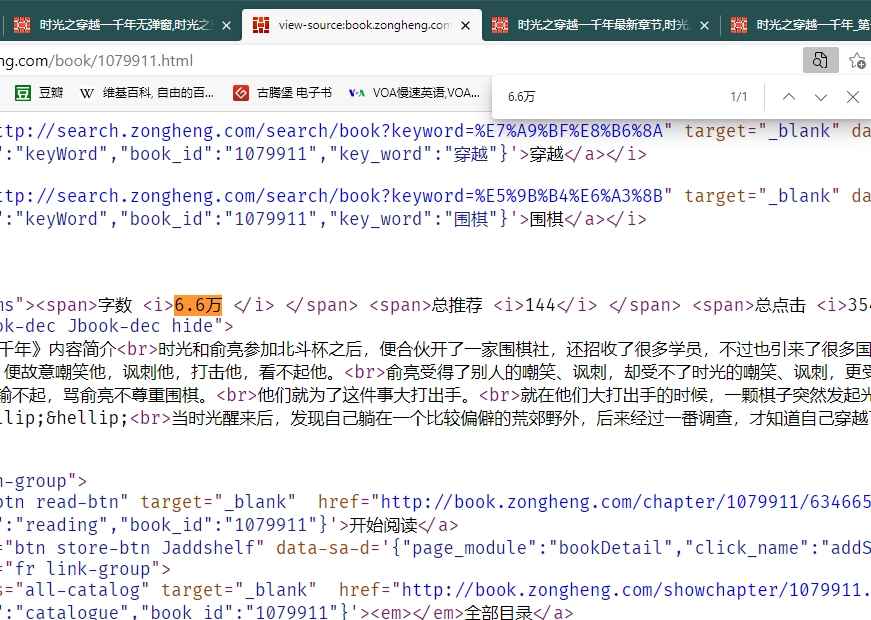
3 在目录页面使用调试工具获取章节的URL,将URL复制到详情页的源码中,看是否存在
确认文章内容是否存在于网页源码,注意使用浏览器中的设置——>开发工具——>其他开发工具
书本中的内容是静态保存的。
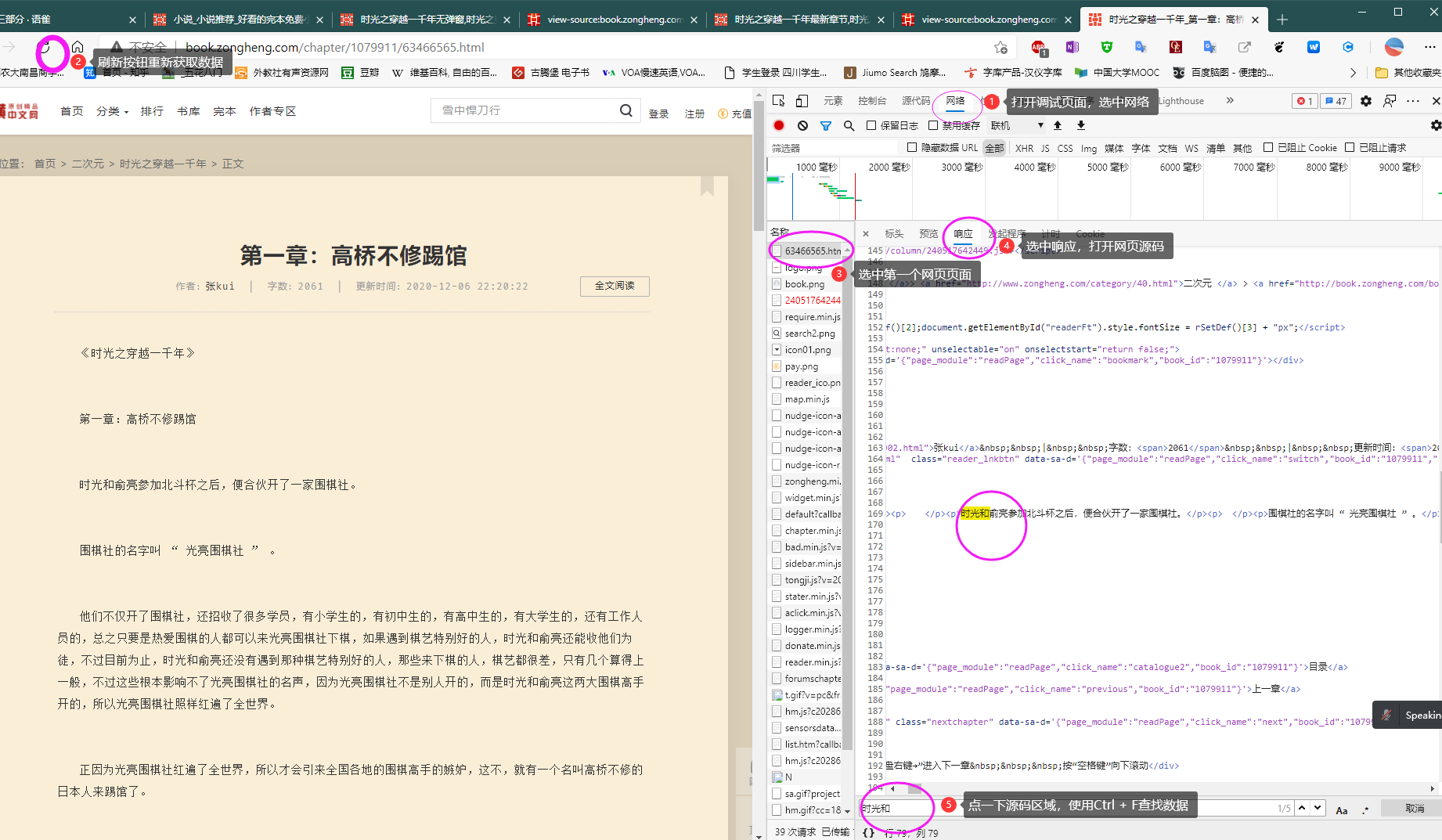
首先选中网络,使用刷新重新获取数据;
选中列表中第一行网页,选择查看源码
点击源码,使用快捷键查找书本内容,确认数据
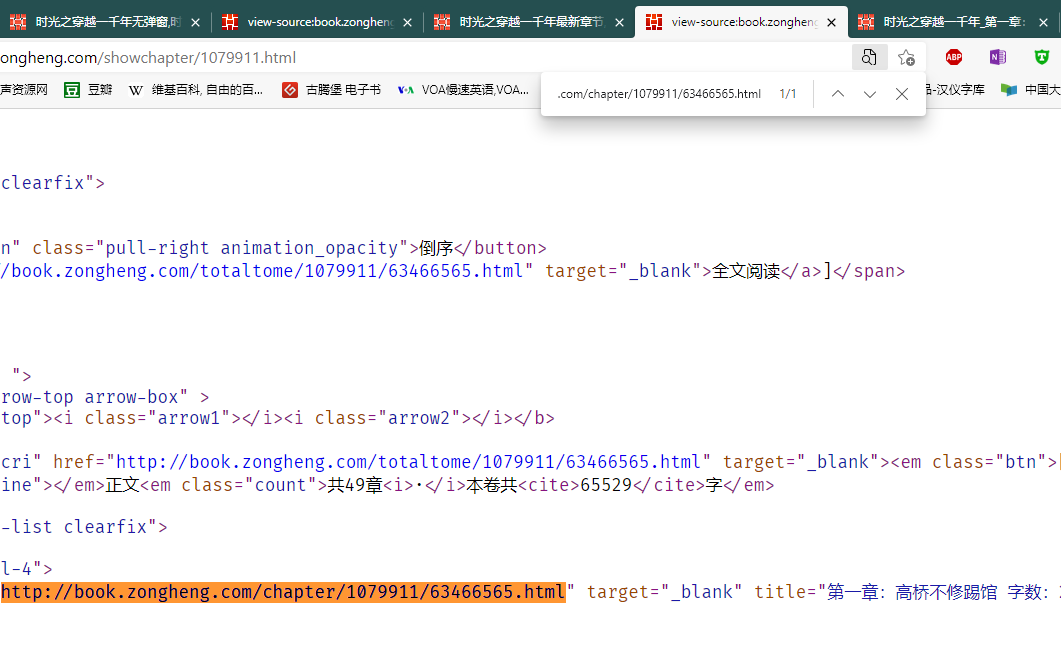
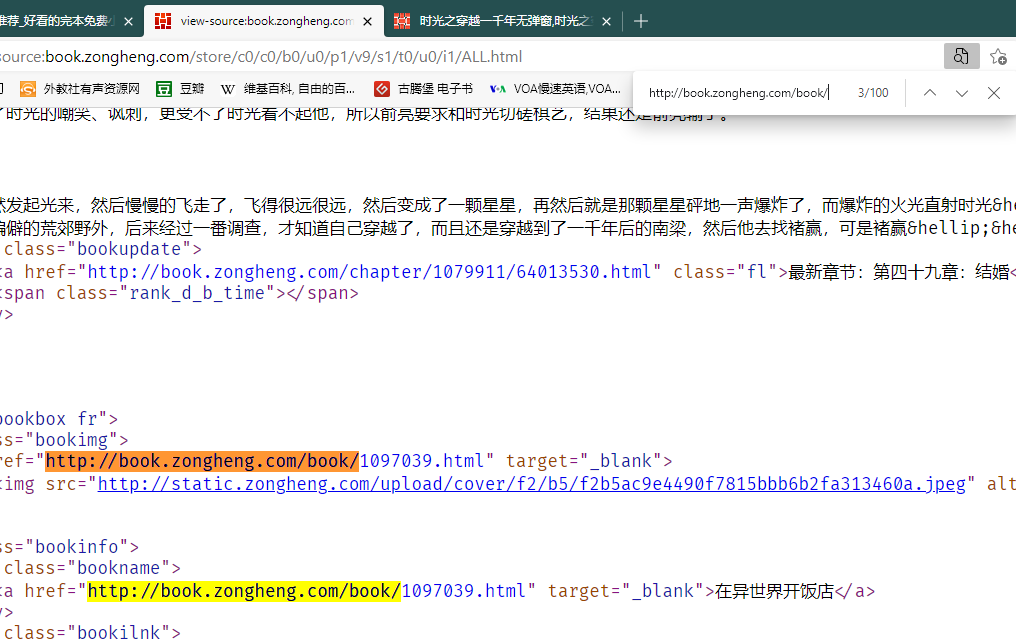
章节的URL也在主页面的网页源码中
除主界面以外,一本书的详情页,详情页中的目录页,目录页中的文本页面依次存在嵌套关系,需要分别获取其URL
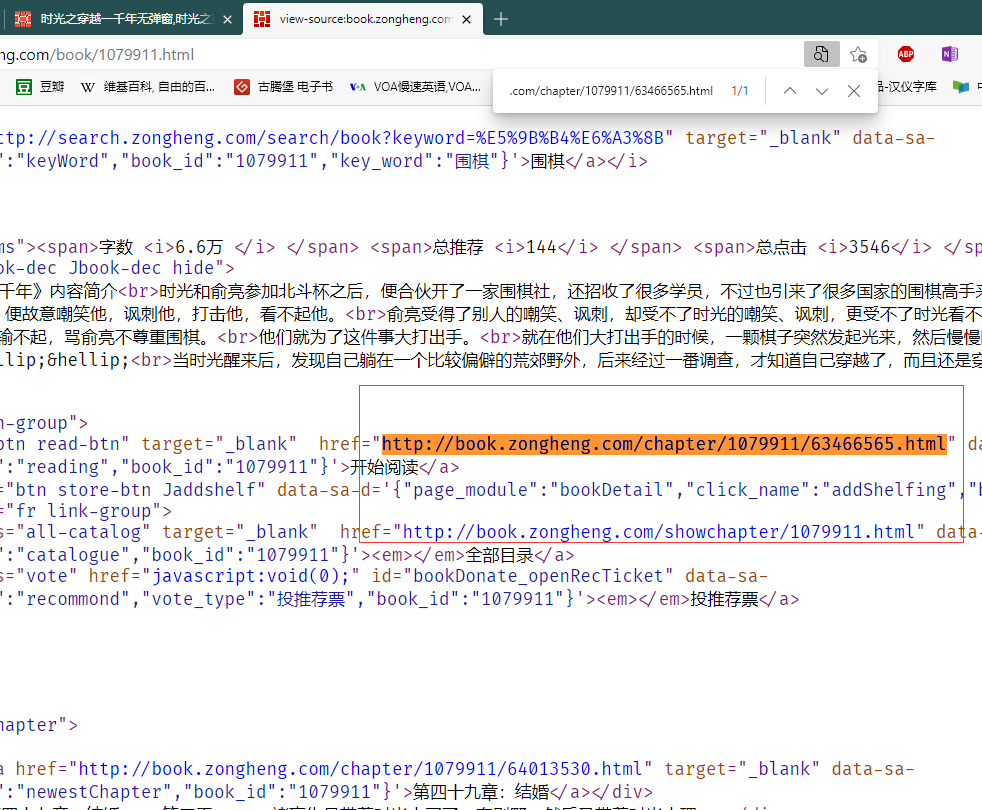
这里是查看详情页URL是否存在于主界面的源码当中
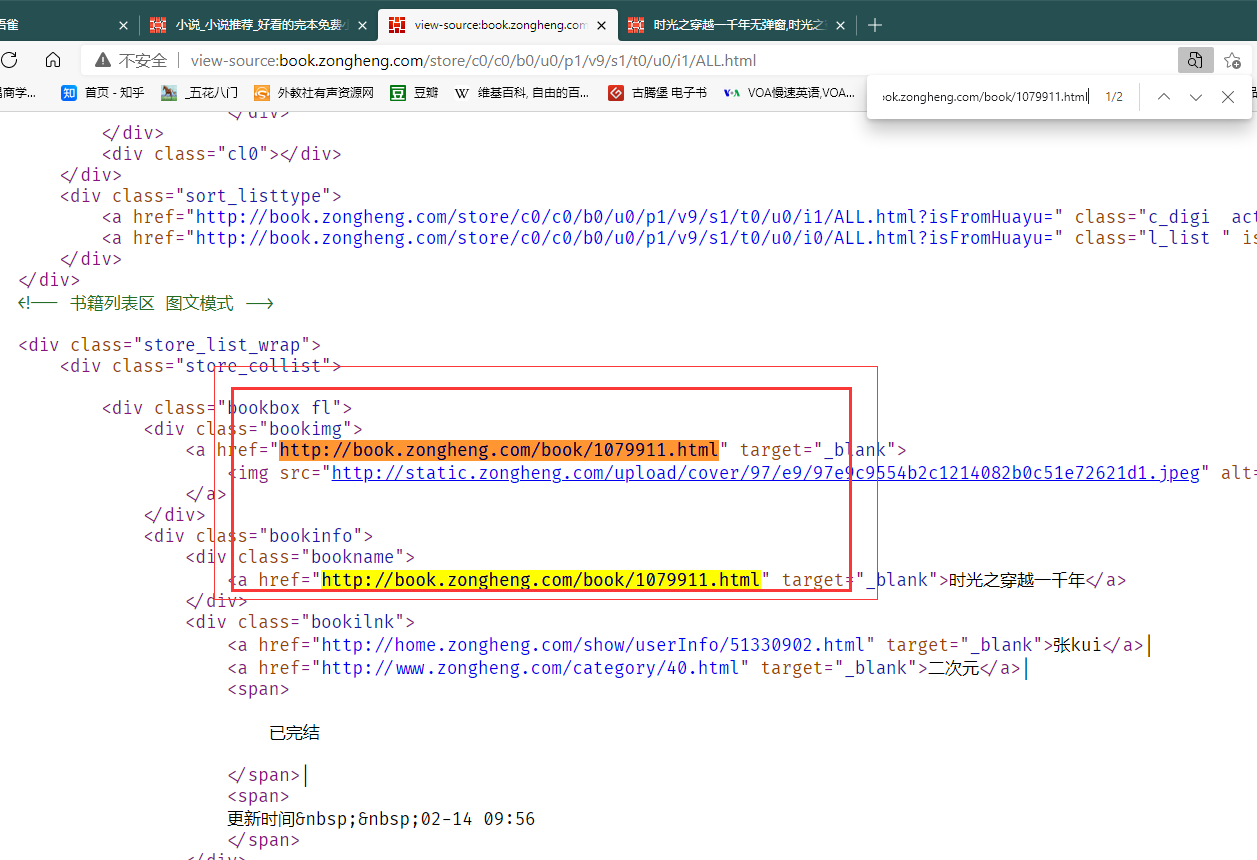
爬取流程
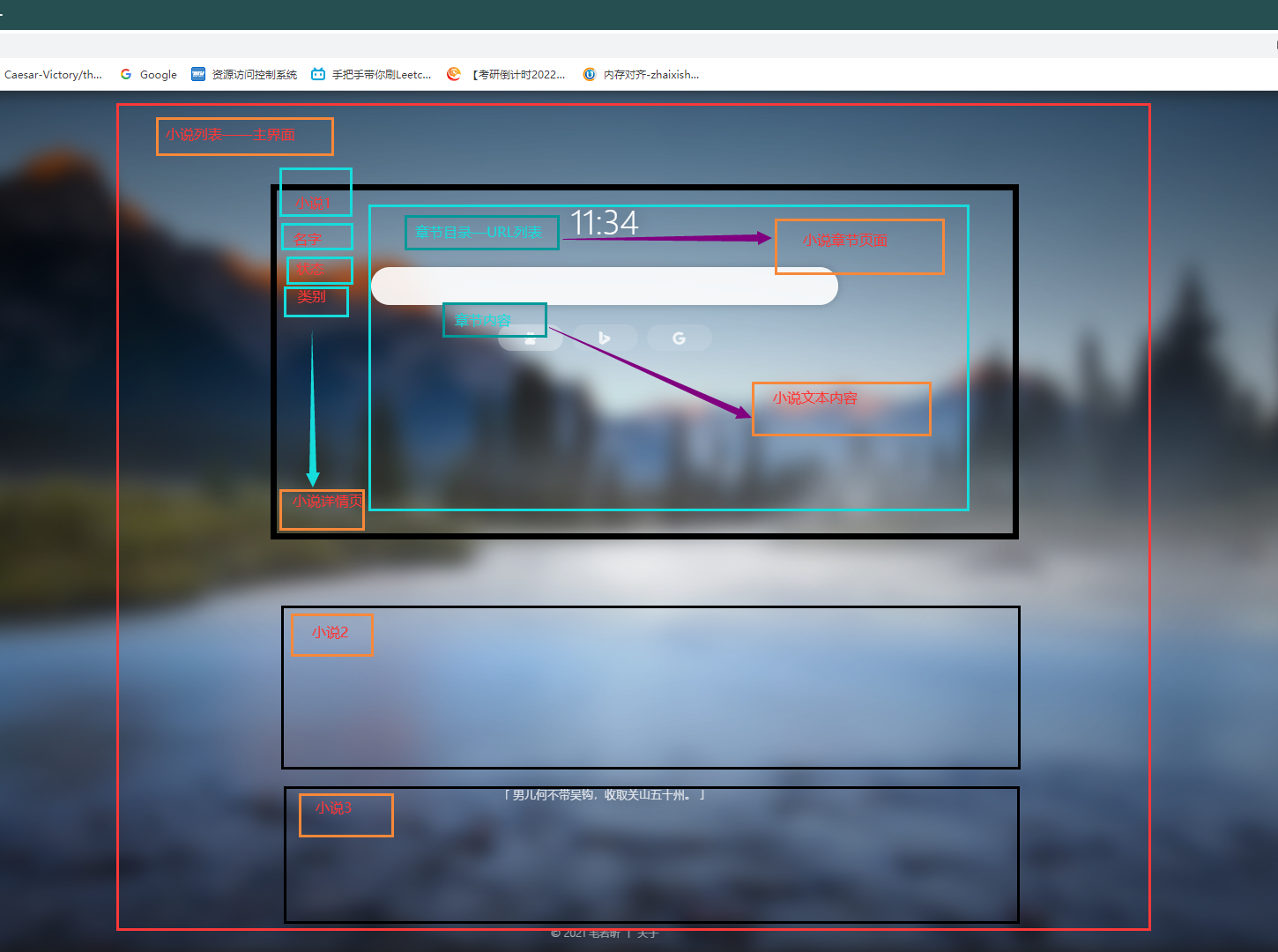
对主程序的修改
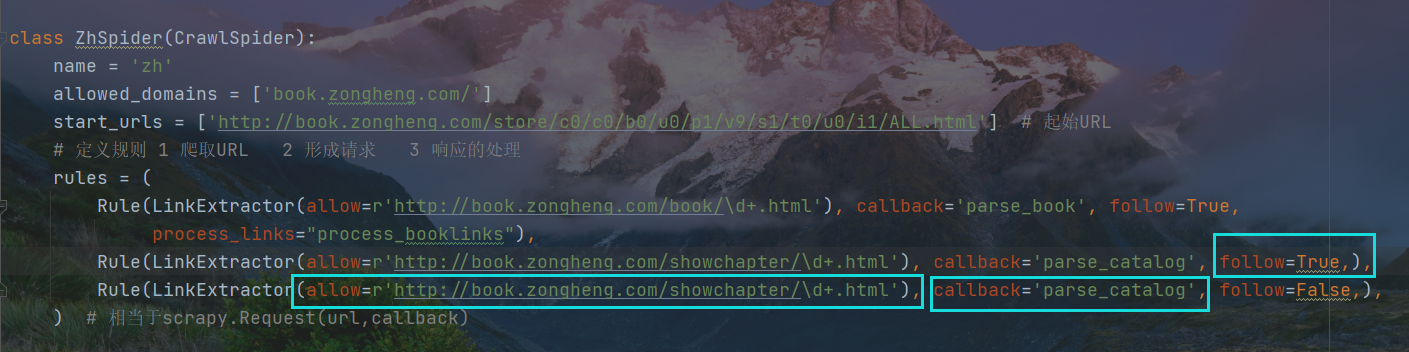
首先设定允许域名和起始域名
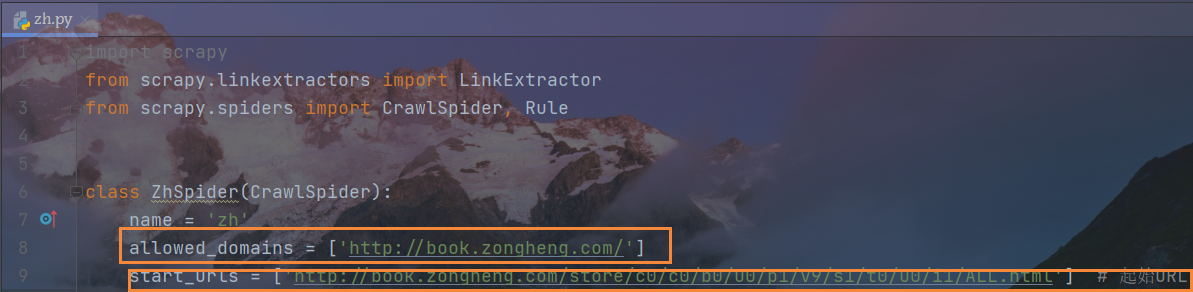
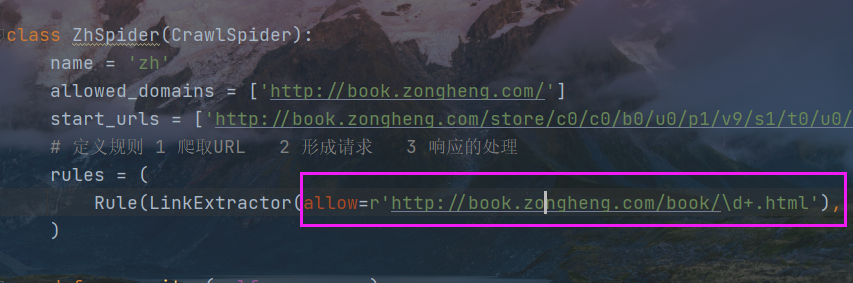
rules规则中,允许的域名
以正则表达式的格式书写,匹配小说的URL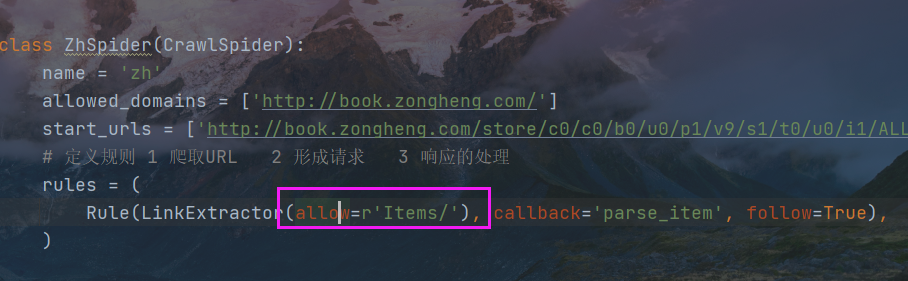
发现网页有重复,每一个小说详情页面的URL会出现两次,但爬取工具会自动过滤,无需多虑
数据交换过程
文字描述:从起始页面开始,将URL交给引擎,引擎交给下载器从而拿到响应,响应返回给RULER
RULER对响应过滤,正则提取子页面URL,此URL提交给引擎,引擎将其提交给下载器获得影响
此响应经RULER中的回调参数传递给parse_item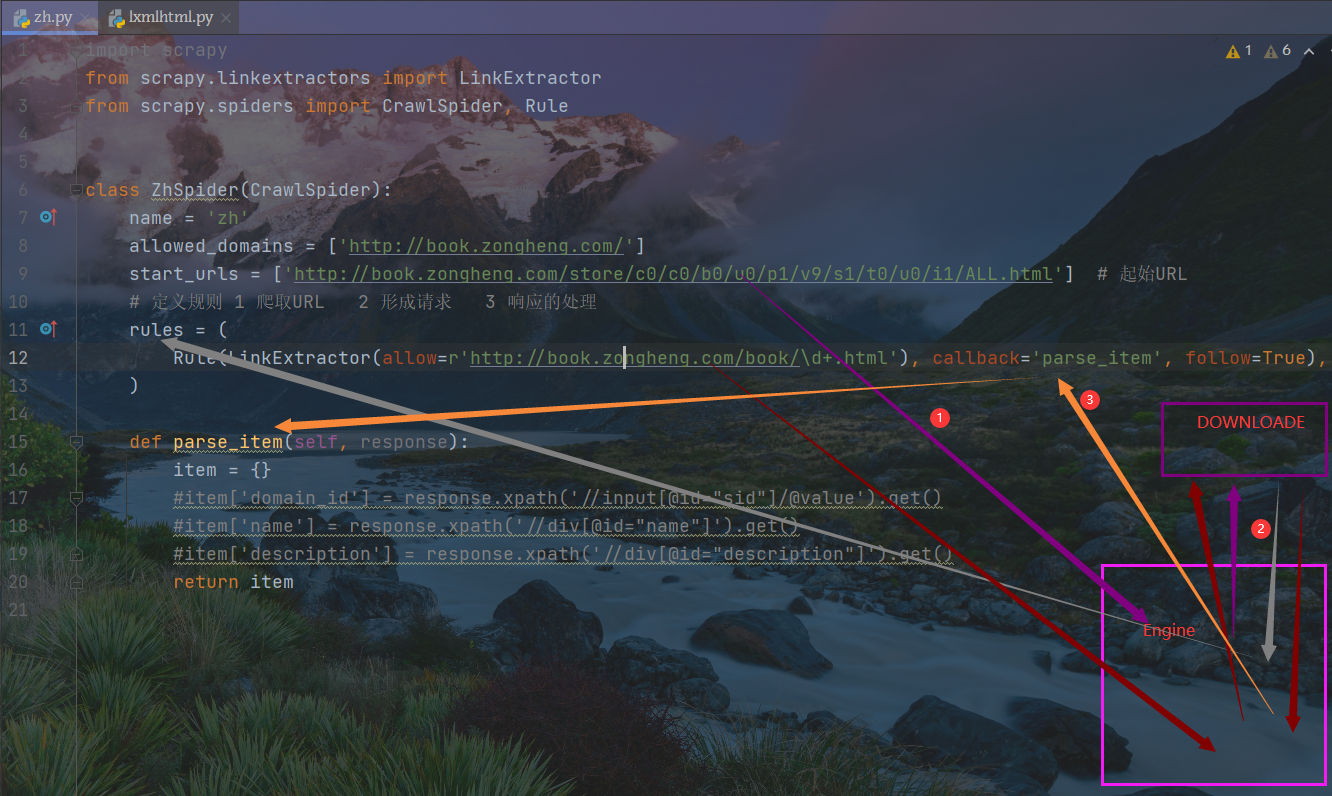
第三个参数follow的设置,值为False,否则数据会分别交给parse_item和rule两处
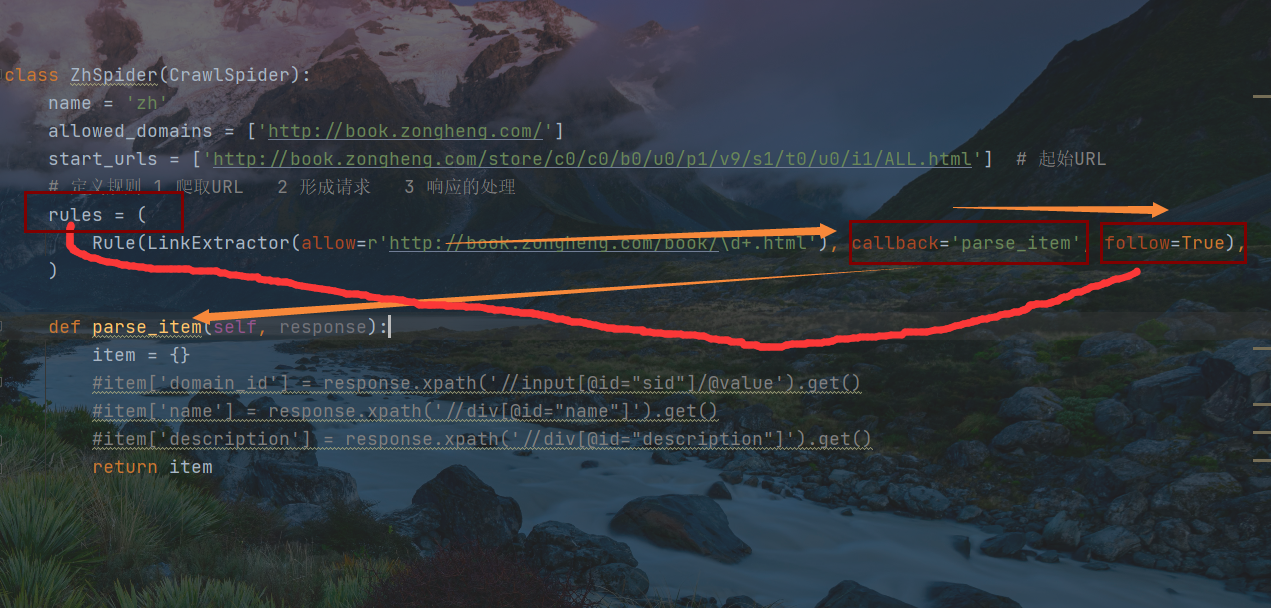
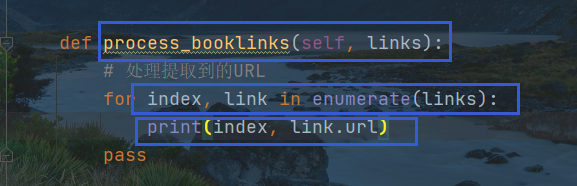
设置从主页面提取小说详情页URL的处理函数,由RULER中的参数process_links进行转交,下一步是定义转交对象的函数

设定处理响应中解析到子页面URL的函数
在settings中关闭机器爬虫规范协议
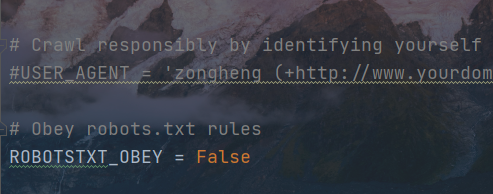
默认请求头增加User-Agent

解决函数报错未果

process_links对象必须加双引号才能识别数据回传对象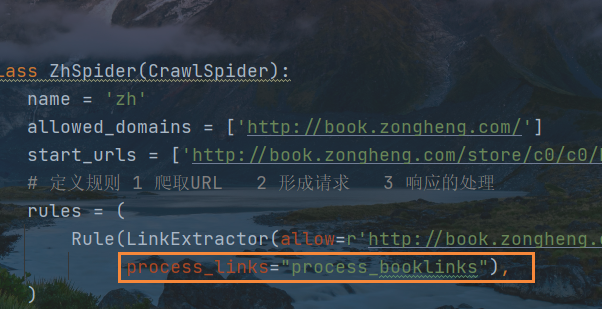
将子页面网页链接回传,才不会有下面的报错
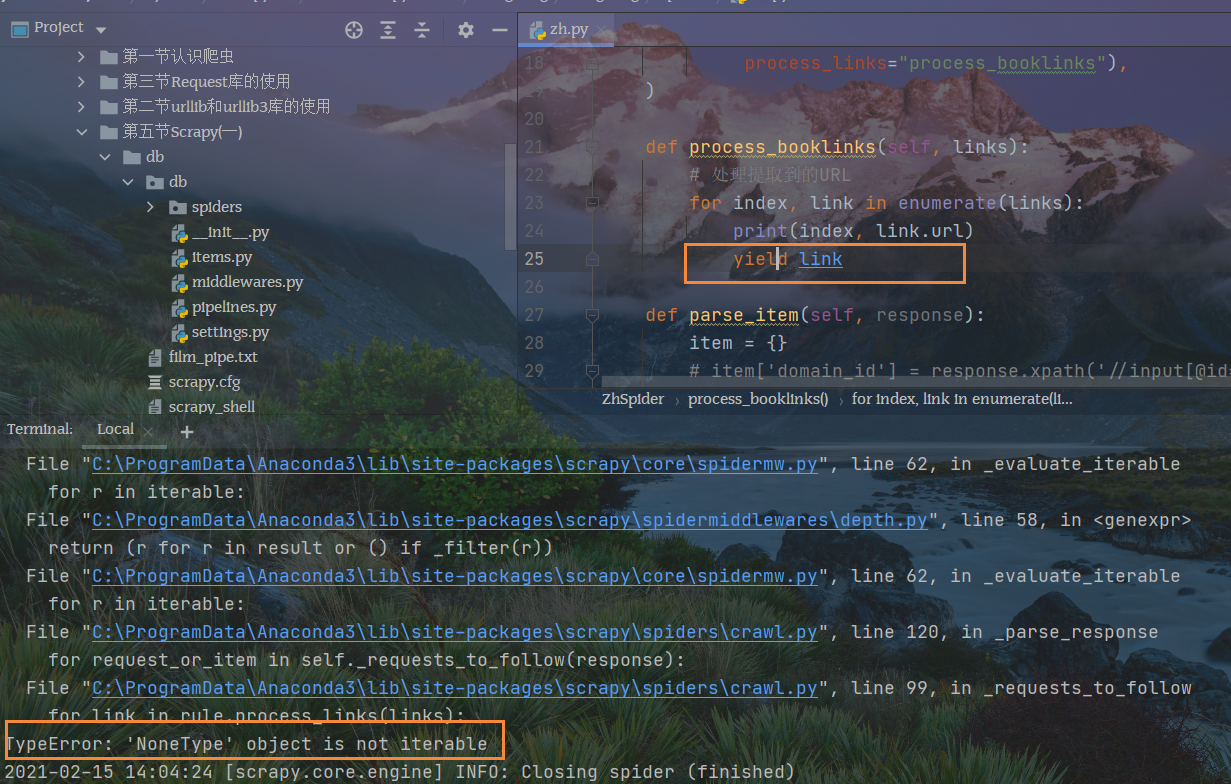
仅仅获取一本书的小说详情页URL
降低下载延时,在settings文件的第二十八行,将三改为一
分析抓取对象(从小说详情页中找需要哪些元素)
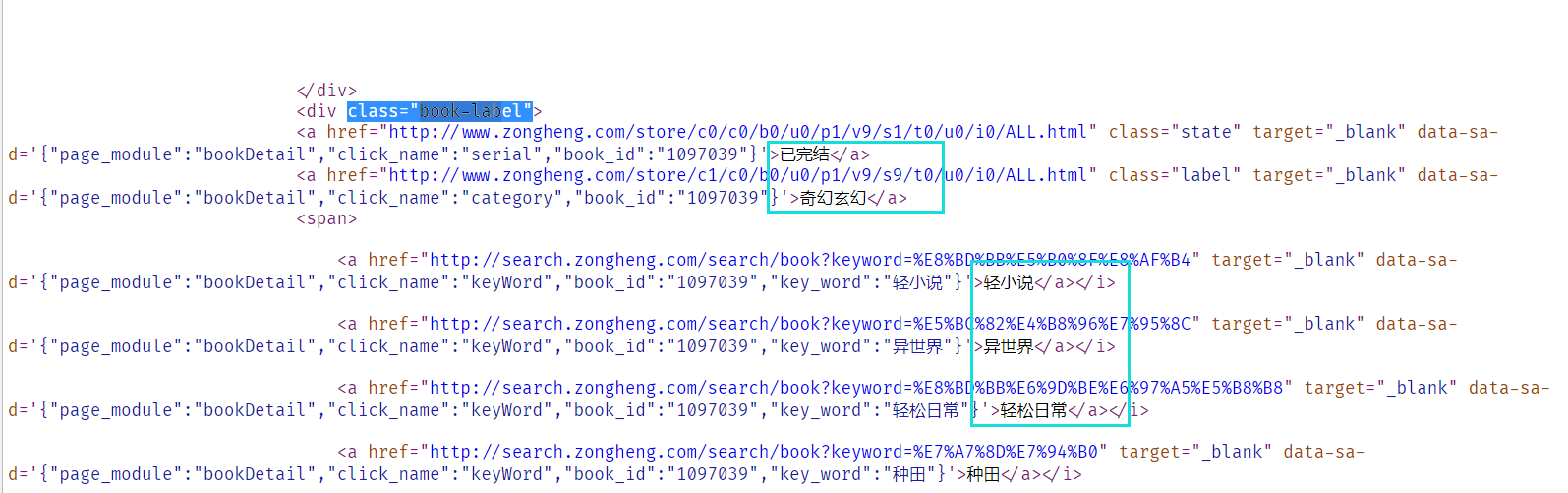
解析网页,获取小说类别
response.xpath('//div[@class="book-label"]/a/text()').extract()[1]
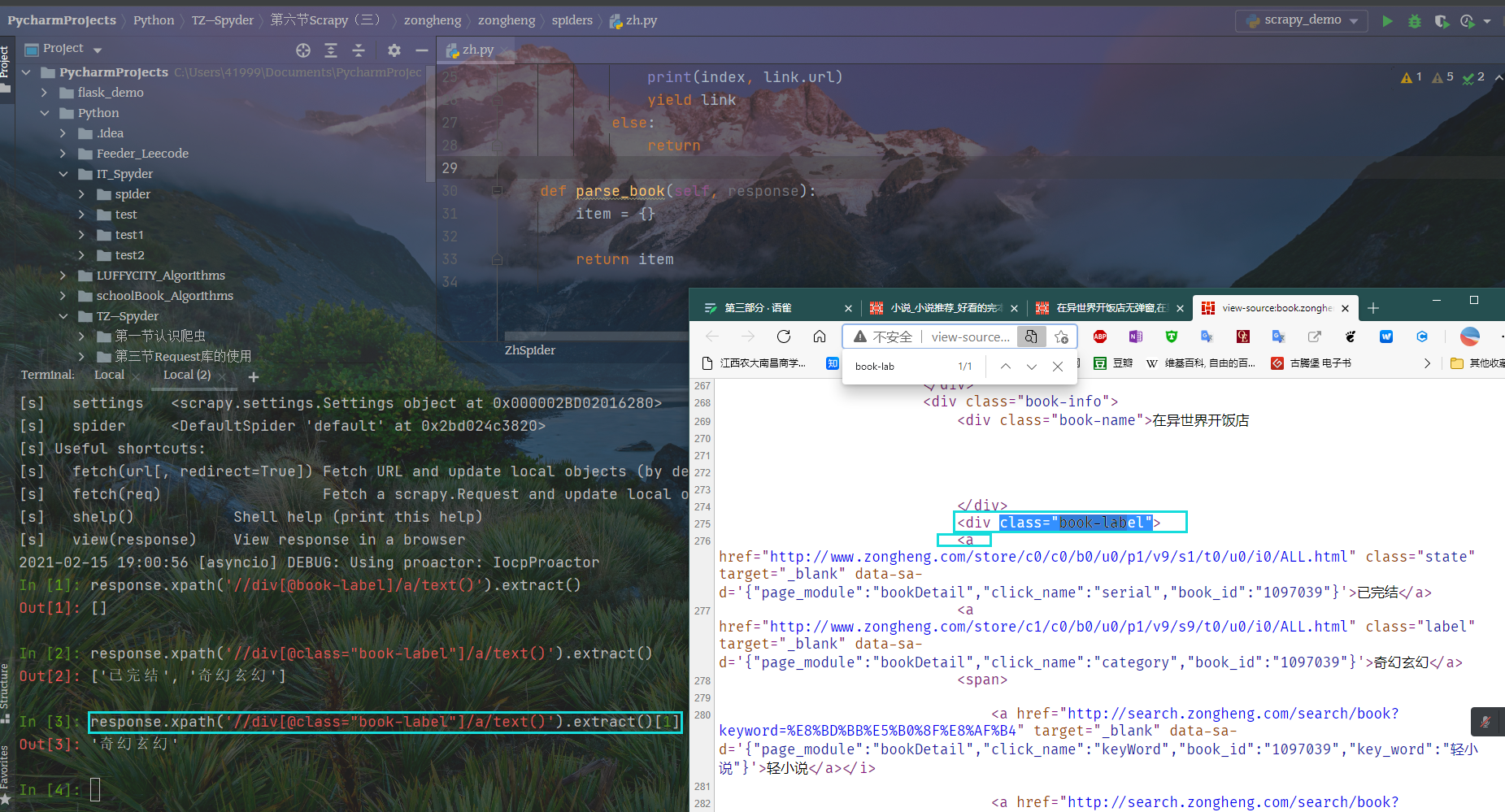
提取书名
response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()
作者
response.xpath('//div[@class="au-name"]/a/text()').extract()[0]
更新状态
response.xpath('//div[@class="book-label"]/a/text()').extract()[0]
图书字数
response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]
完整解析函数
def parse_book(self, response):category = response.xpath('//div[@class="book-label"]/a/text()').extract()[1]book_name = response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()author = response.xpath('//div[@class="au-name"]/a/text()').extract()[0]status = response.xpath('//div[@class="book-label"]/a/text()').extract()[0]book_nums = response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]description = ''.join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').re("\S+"))c_time = datetime.datetime.now()book_url = response.url # 可以拿到请求的URLcatalog_url = response.css("a").re('http://book.zongheng.com/showchapter/\d+.html')[0]print(category, book_name, author, status, book_nums, description, c_time, book_url, catalog_url)
利用rule函数继续获取目录页这个子级页面
注意!!!
引擎返回的报文,一方面要交给回调参数进行解析处理,一方面由follow的值决定,是否再传递给Rule用于再次提取子页面
1, 首先从主页面开始,用引擎下载及返回报文,交给第一个rule负责匹配
2, 第一个rule匹配到的数据交给parse_book解析,它又会再次拿到URL
3,将这个URL交给引擎下载并且获得响应,将响应交给第二个rule进行正则匹配,这次获得的是目录页的URL
细节处理
第一个Rule中的follow设置为True,那么响应报文中的URL才会提交给rule
第二个Rule则不需要再次将响应报文返回给rule
第二个Rule中的callback回调对象需要重新设置
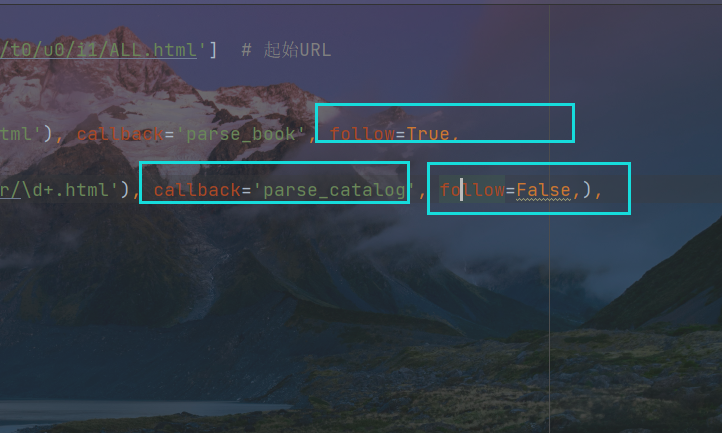
创造第三个Rule,继续匹配章节目录源代码中每一个章节的URL
目录源码中存放的第二章章节的URL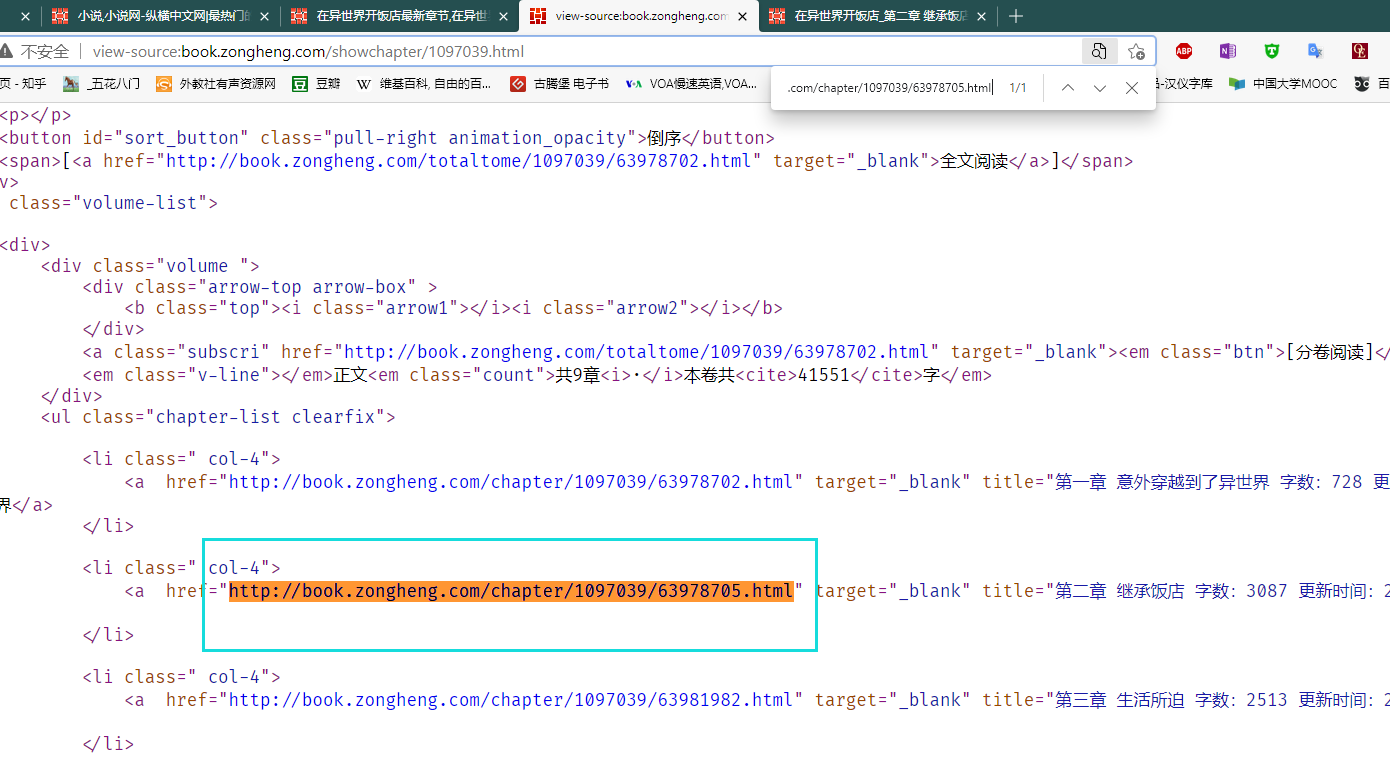
主流程已经完成,先逐步完善细节
第一 针对主界面每一本小说文框下最新章节进行限制。因此会对其产生干扰
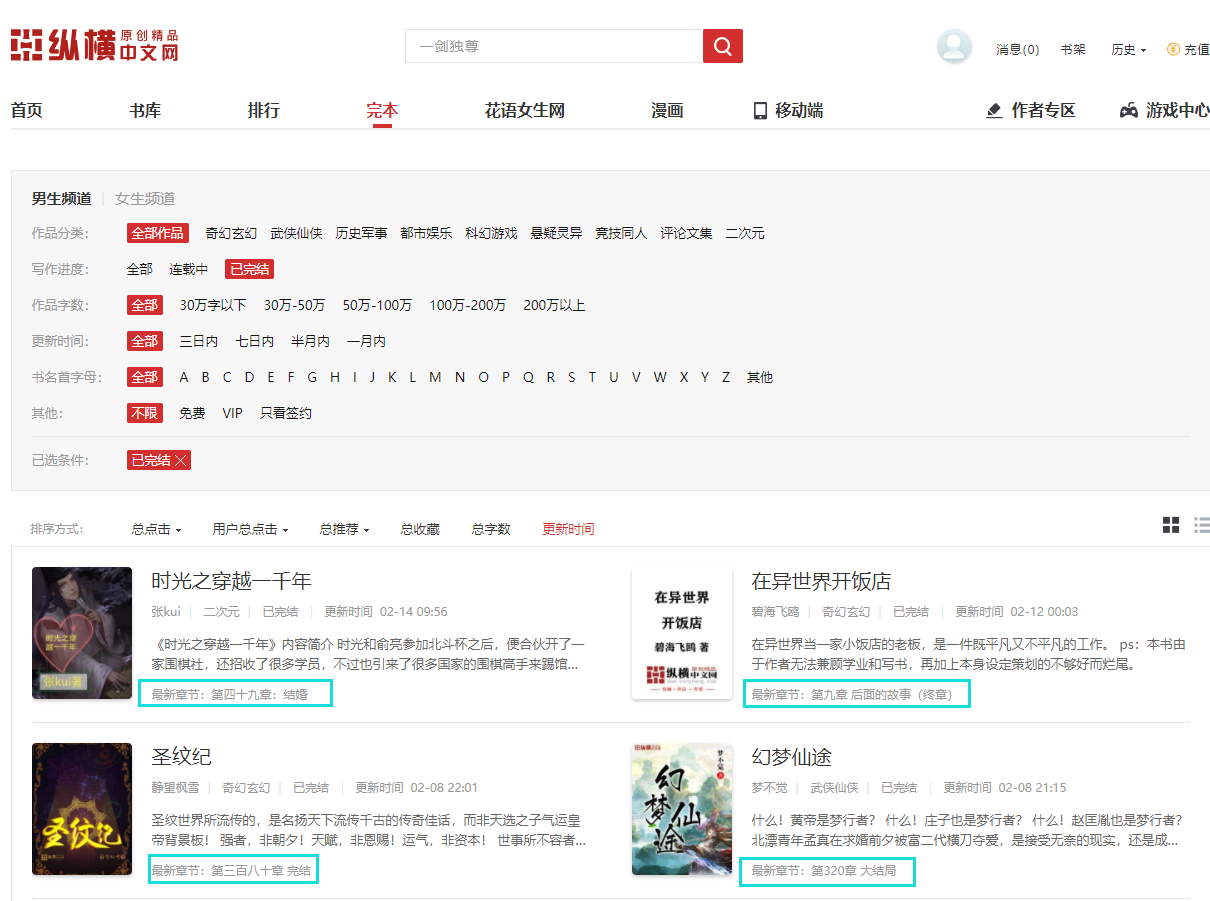
从响应提取方法中寻找限制方法
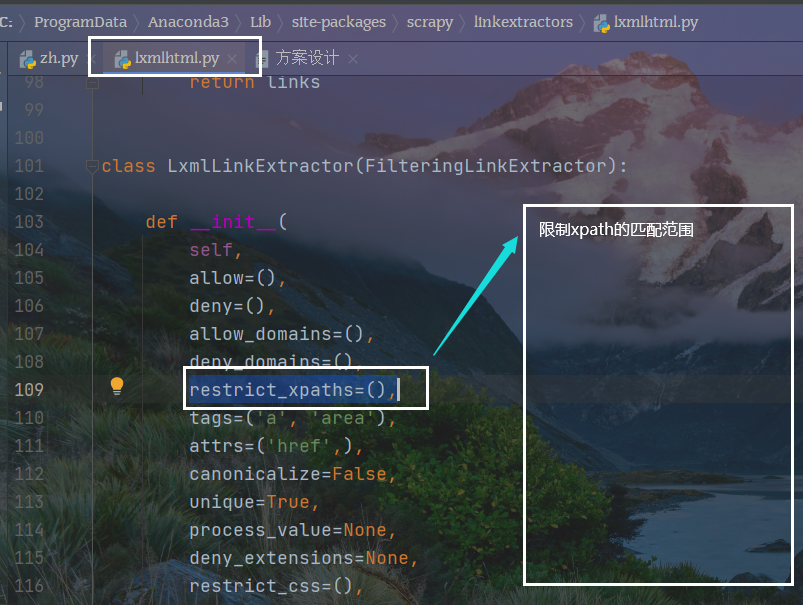
从源码中找到提取对象的范围
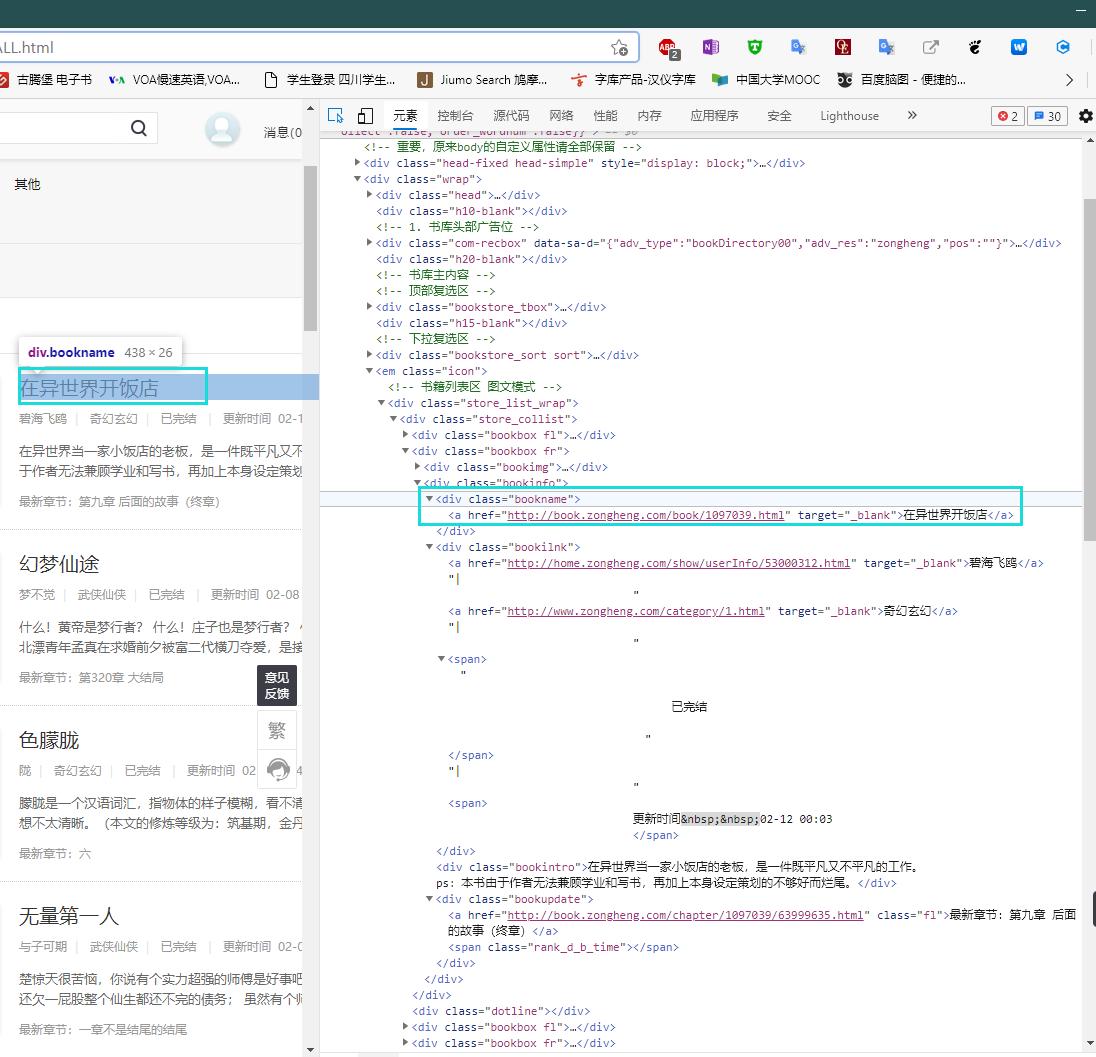
在第三个rule也就是从全部章节源码中找到一个章节的限制区域,以第一章为例
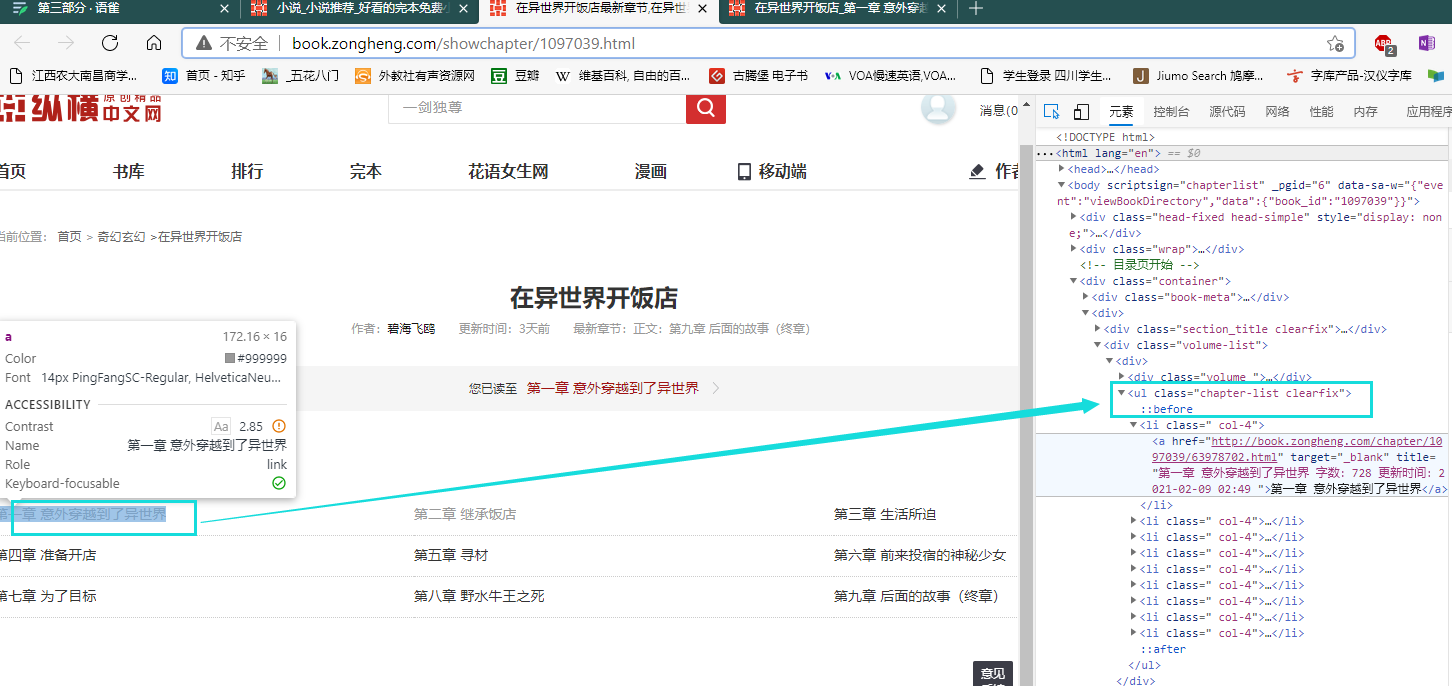
总结:
后一个限制解析用来限制前一个提取网页进行的区域范围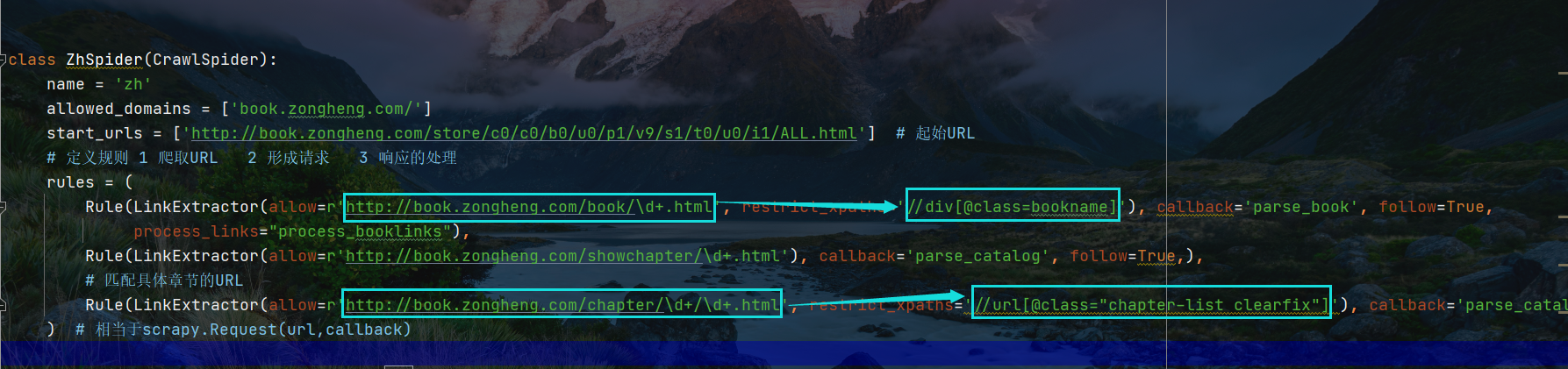
第二,针对第二个Rule,展示全部章节源码进行分析,我们爬取的元素是有序的章节排布,包括章节的URL,以及title
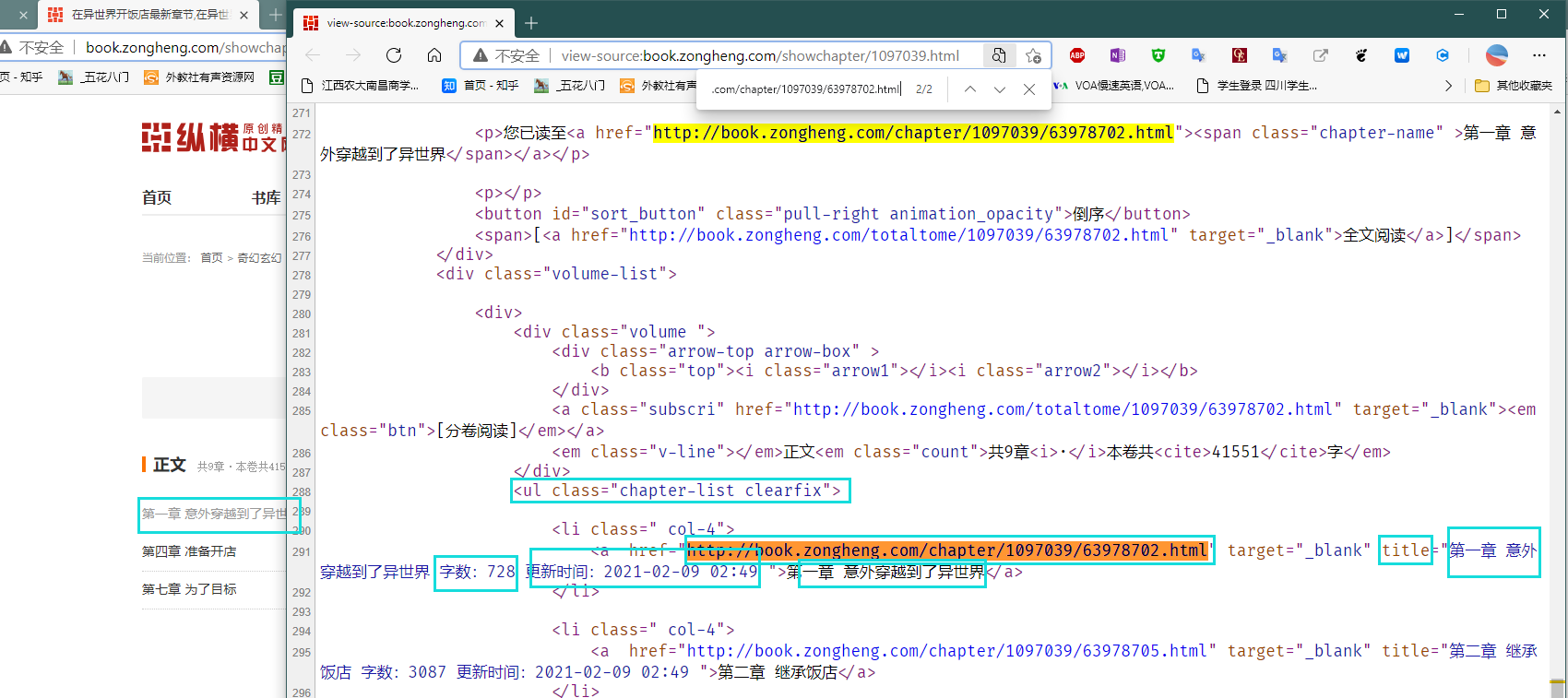
有序数据的对应
利用列表来存储爬取到的章节URL以及title,这样数据就会变得有序
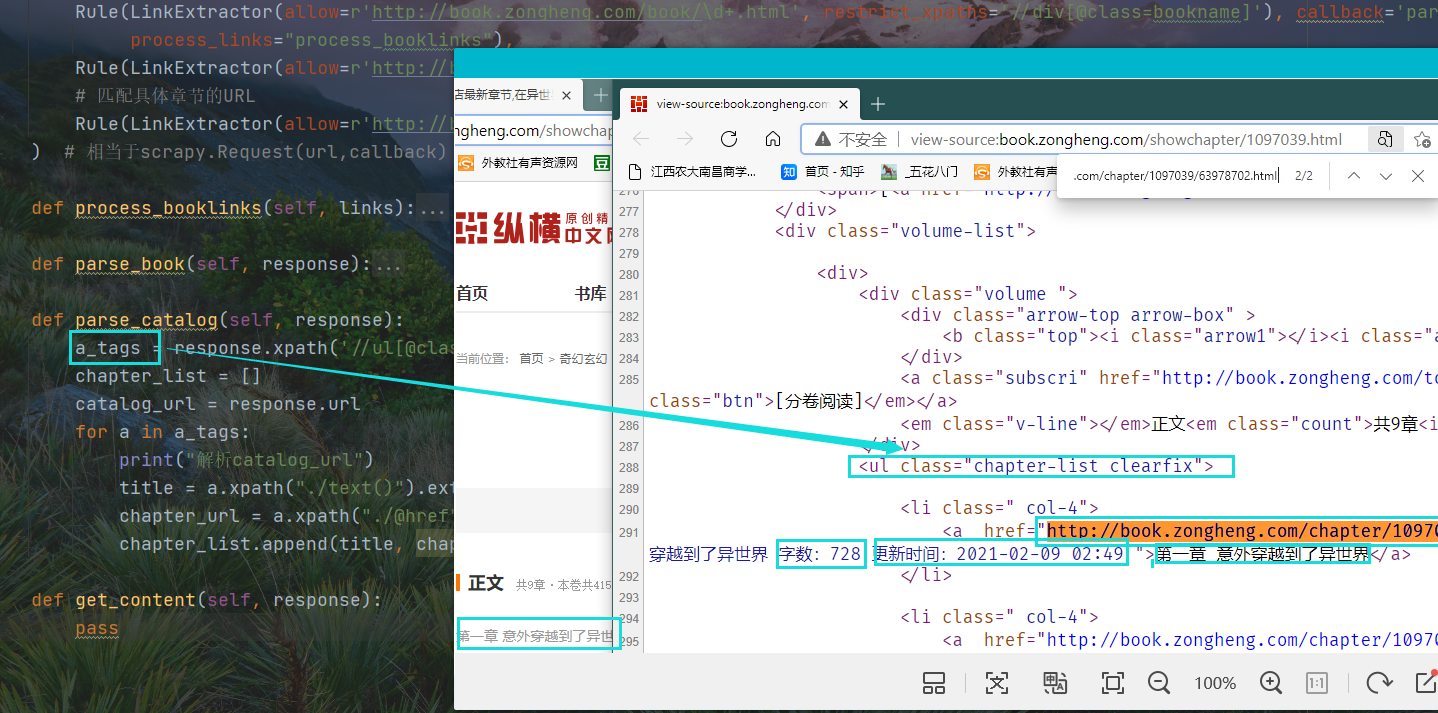
第三 针对第三个Rule,也就是第四级页面,确定小说内容存在的位置
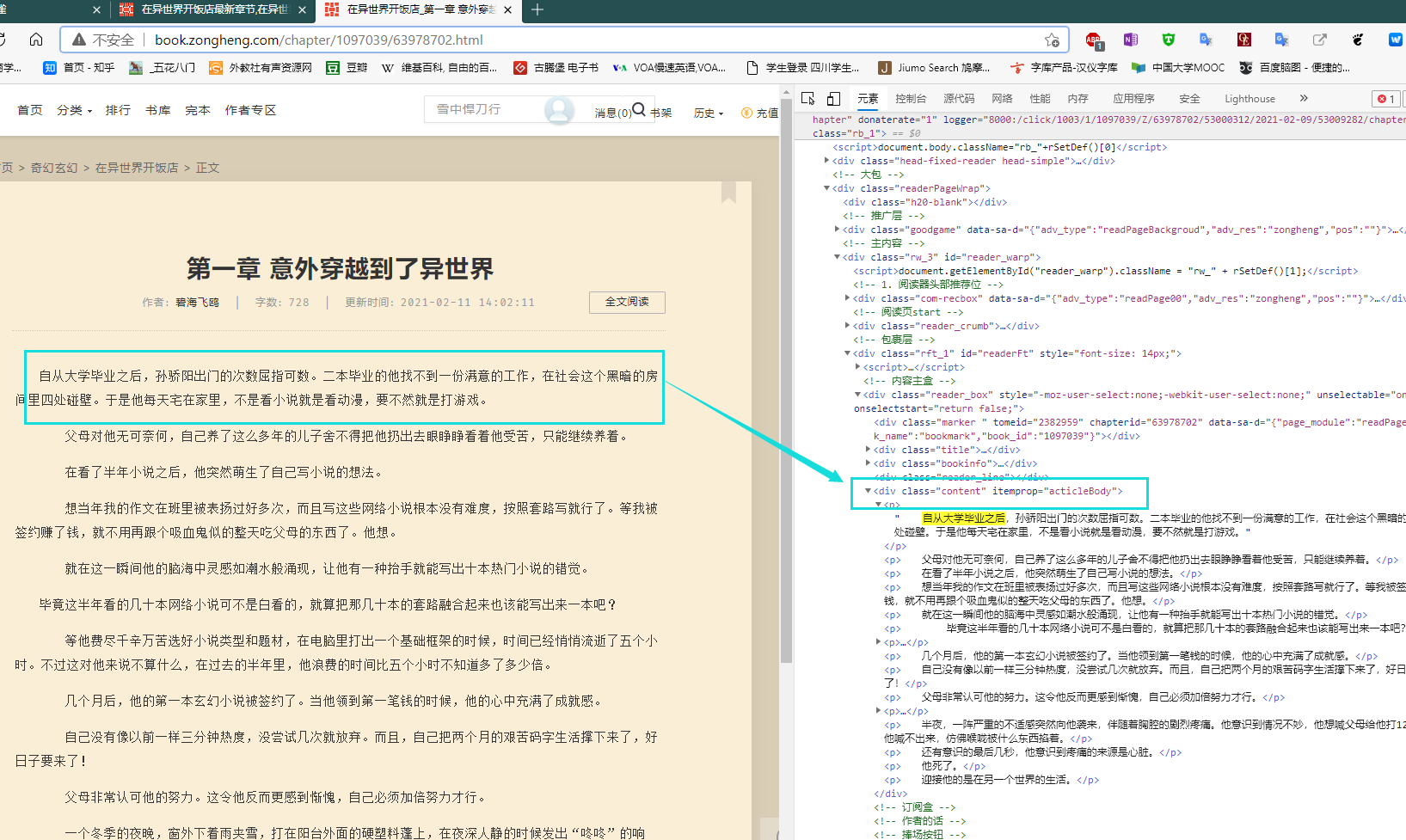
细节处理
获取到章节内容后,还有多余的字符,本人尝试处理一下
1 将其转换为字符串,使用replace()方法替换,结果不行,因为字符在列表中每一个字符串中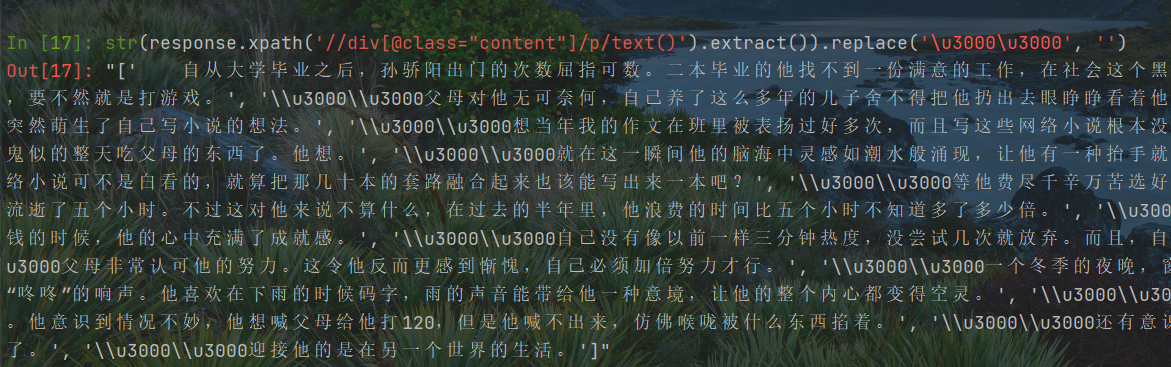
2 extract()方法也是选择器专用的,无法插手
3 我尝试自己写一个循环,循环读取数据,取出再返回去,未果,下课后再尝试,先解决进度
老师先将列表转换为字符串拼接,我加了replace()方法之后成功将字符替换为空,但是不怎么美观

存储结构的规划

暂时收工,还剩下十四分钟的课程没有学习
**
20210216
对主程序分别新增管道存储结构
def parse_book(self, response):category = response.xpath('//div[@class="book-label"]/a/text()').extract()[1]book_name = response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()author = response.xpath('//div[@class="au-name"]/a/text()').extract()[0]status = response.xpath('//div[@class="book-label"]/a/text()').extract()[0]book_nums = response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]description = ''.join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').re("\S+"))c_time = datetime.datetime.now()book_url = response.url # 可以拿到请求的URLcatalog_url = response.css("a").re('http://book.zongheng.com/showchapter/\d+.html')[0]item = NovelItem()item["category"] = categoryitem["book_url"] = book_urlitem["author"] = authoritem["statu"] = statusitem["book_nums"] = book_numsitem["description"] = descriptionitem["c_time"] = c_timeitem["book_url"] = book_urlitem["catalog_url"] = catalog_urlyield item
def parse_catalog(self, response):a_tags = response.xpath('//ul[@class="chapter-list clearfix"]/li/a')chapter_list = []catalog_url = response.urlfor a in a_tags:print("解析catalog_url")title = a.xpath("./text()").extract()[0]chapter_url = a.xpath("./@href").extract()[0]chapter_list.append(title, chapter_url, catalog_url)item = ChapterItem()item["chapter_list"] = chapter_listyield item
def get_content(self, response):chapter_url = response.urlcontent = ''.join(response.xpath('//div[@class="content"]/p/text()').extract()).replace("\u3000\u3000", "")c_time = datetime.datetime.now()# 向管道传递数据item = ContentItem()item["chapter_url"] = chapter_urlitem["content"] = contentitem["c_time"] = c_timeyield item
在settings中配置MySQL连接

设置文件目录
时间有限,还剩下八节课时间,全部章节学完之后再重新扣这一个章节的内容
由于Windows下配置MySQL之困难,我前后花了两个小时左右,上一次凌晨配置也是。以后的项目学习搬到Ubuntu下开始。
所以从下一个章节开始,项目就在Ubuntu操作系统上运行。MySQL配置比较简单。等会儿将整个文件复制过去。
另外学习爬虫的时候,会产生一些业务需求,比如文件的存储和转换。比较典型的,小型数据使用JSON存储。稍微大型的文件使用MySQL存储。
上一次在终端产生的报错,由于程序关闭导致无法重新查看,所以还需要去学习OS模块,看能否将报错信息持久固化到文件当中,便于查找问题。
目前发现的就这几个需求,随着学习的深入,需要掌握的东西肯定是越来越多。所以一般需要什么就重新学习什么。
20210216 | 1952再次梳理代码逻辑
spider拿到数据,将数据交给引擎,引擎拿到数据之后交给管道存储,管道建立了对应结构,同时管道中的结构和items中的结构对应
pipelines中存储的数据,会转存到mysql,转存的工具是模块pymsql。
使用pymysql需要在settings中的设置链接数据库。
几个重要的pymysql命令
1 select insert into 读写
2 commit 提交
3 细节 items分为三类, 第一类是小说 第二类是章节 第三类是具体的文章内容
对知识点的补充:
settings程序中,需要自己先行创建一个数据库
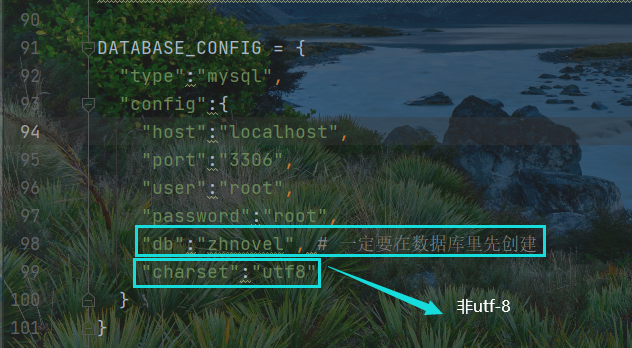
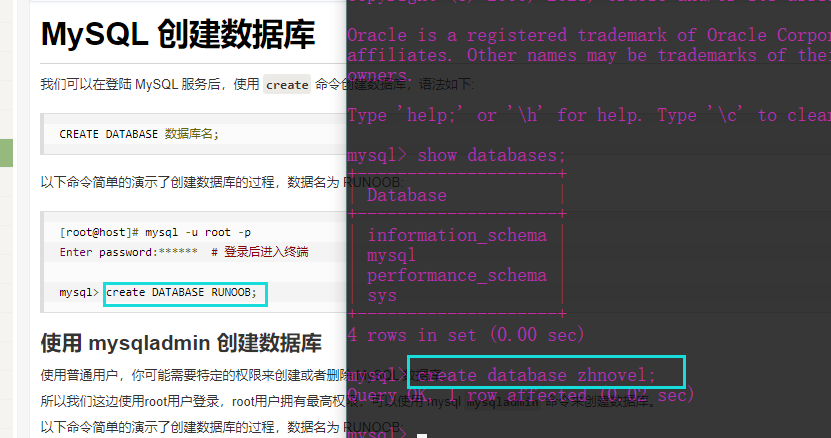
本项目还未解决的问题:
MySQL数据表中字段的写入,id需要自增减 章节内容需要设定类型为text
数据之间发生的转交
现在已经是20点19分,还剩下一天的内容没有学习,先去追赶进度
CrawlSpider去重

若有收获,就点个赞吧
0 人点赞
