项目总结
昨天爬虫没有取得数据,我去把settings中所有能够开的,自己知道的设置全部都开了,还是不行,老师远程调试了很久,删除了他的代码,程序又不能拿到数据。
百度查了报错,先是更改主机域名,随后在生成请求的语句中,参数设置不过滤,然后数据就被爬到了。
另外一个收获就是使用管道存储的关联流程。在settings文件中开启管道存储,在items中建立结构,在piplines中导入item,然后调用item。至此关联处理完毕。

spider类下载图片
分析请求流程
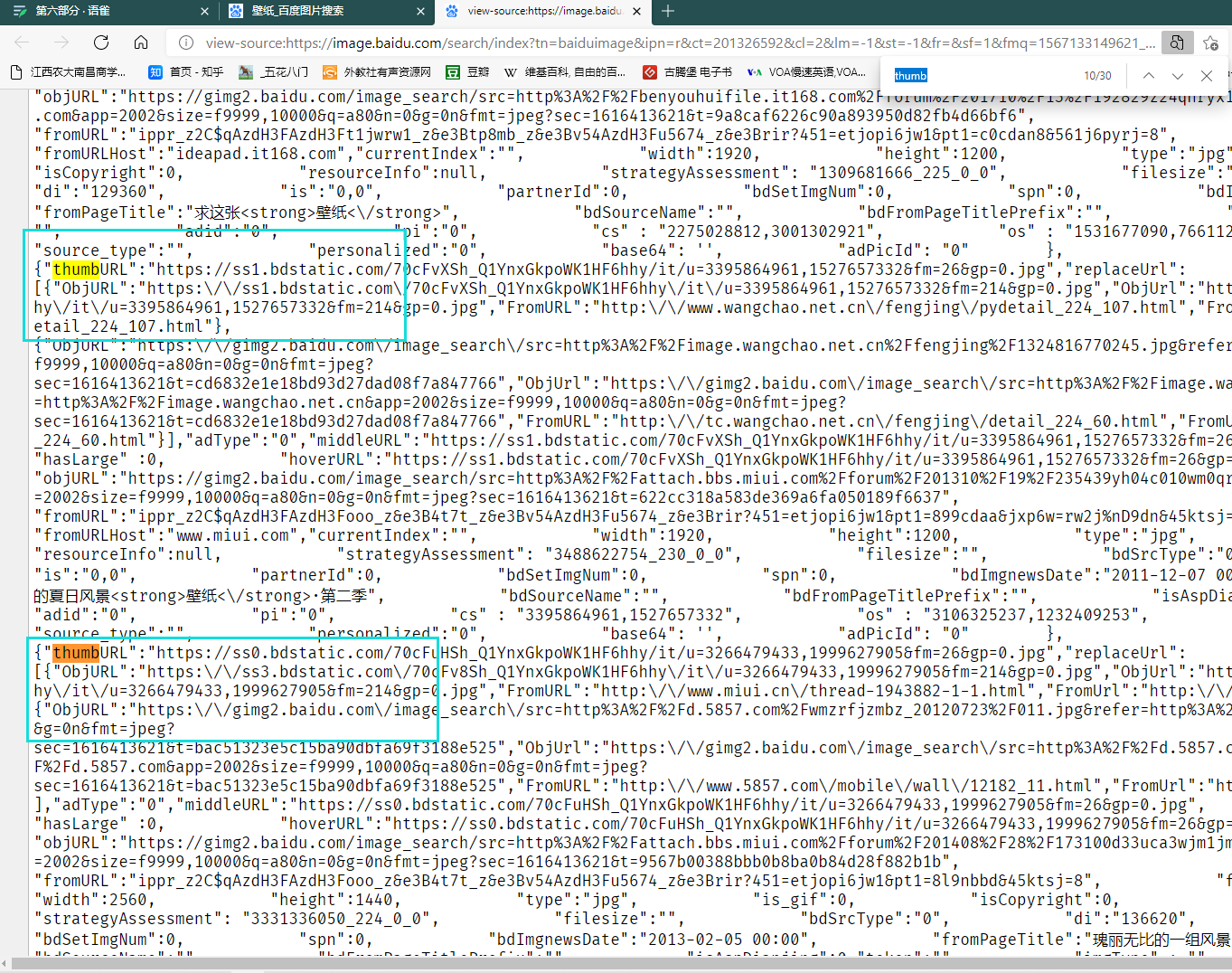
百度图片搜索关键字,在网页源代码中找到有规律的图片URL
创建scrapy项目
cd C:\Users\41999\Documents\PycharmProjects\Python\TZ—Spyder\第九节Scrapy(六)scrapy startproject bdimagecd cd C:\Users\41999\Documents\PycharmProjects\Python\TZ—Spyder\第九节Scrapy(六)\baiduimage\baiduimagecd ../start genspider bdimgspider xxx
结合代码构建请求流程
1 设定起始页URL 解析URL 获取图片的URL
2 使用re模块匹配响应网页源码中的每一个图片URL
3 for循环,遍历每一个图片的URL,并且利用生成器发起访问
4 得到响应,使用生成语句中的回调函数将响应转给指定的解析函数
settings配置参数
关闭遵循爬虫协议 增添请求头
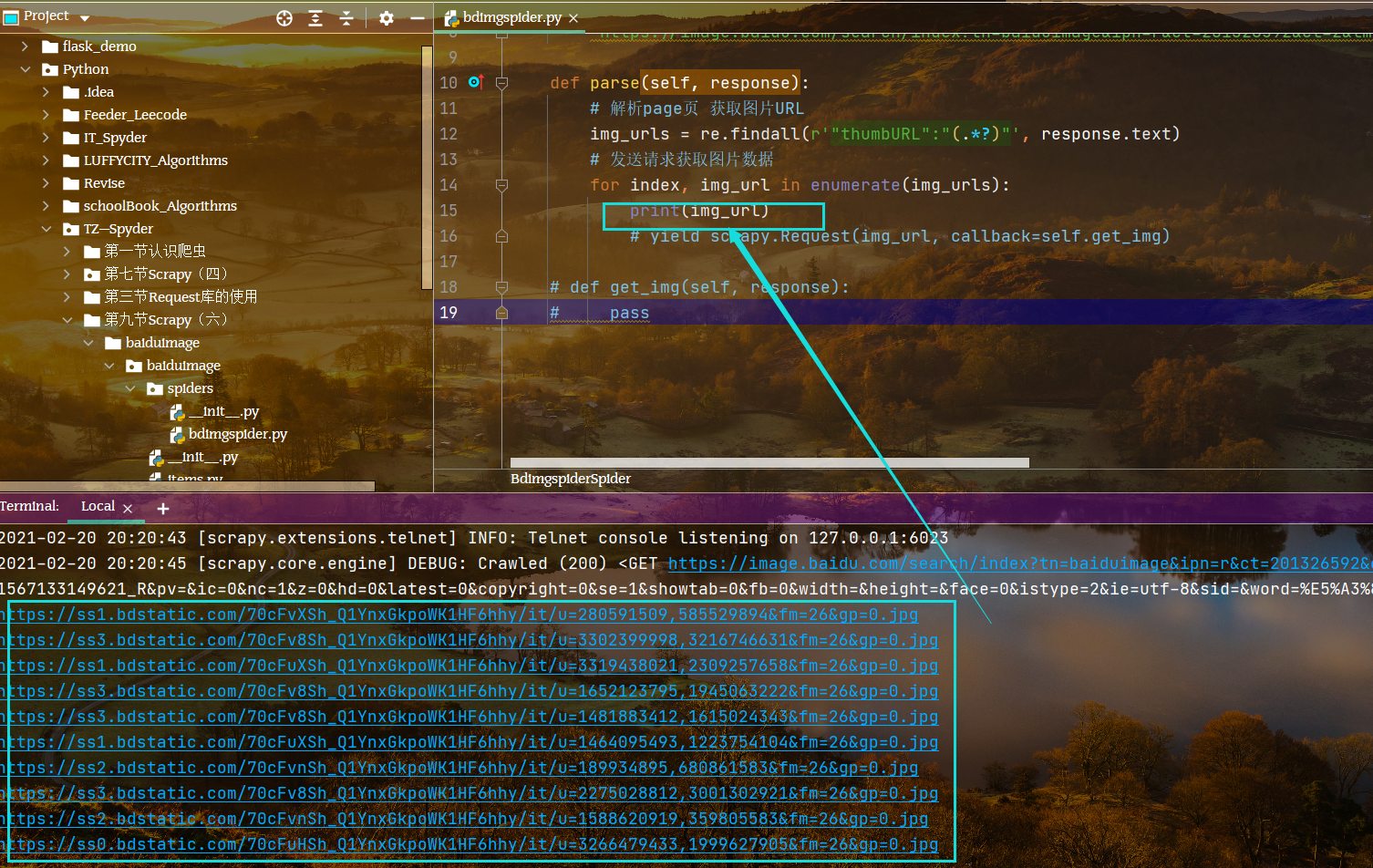
预打印单个URL,看是否匹配成功
代码解析
第一部分
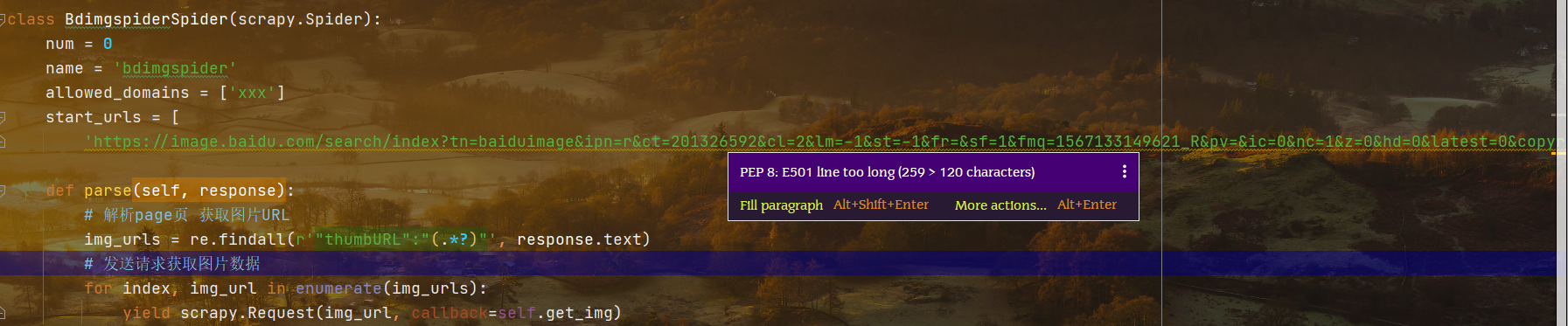
import scrapy, re, osfrom ..items import BaiduimageItemclass BdimgspiderSpider(scrapy.Spider):num = 0name = 'bdimgspider'allowed_domains = ['image.baidu.com/']start_urls = ['https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fr=&sf=1&fmq=1567133149621_R&pv=&ic=0&nc=1&z=0&hd=0&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E5%A3%81%E7%BA%B8']def parse(self, response):# 解析page页 获取图片URLimg_urls = re.findall(r'"thumbURL":"(.*?)"', response.text)# 发送请求获取图片数据for index, img_url in enumerate(img_urls):yield scrapy.Request(img_url, callback=self.get_img, dont_filter=True)def get_img(self, response):print("图片数据", response.status)img_data = response.body # 图片二进制数据# 一直存储if not os.path.exists("dirspider"):os.mkdir("dirspider")filename = "dirspider/%s.jpg" % str(self.num)self.num += 1with open(filename, "wb") as f:f.write(img_data)# 使用管道存储item = BaiduimageItem()item["img_data"] = img_datayield item
首先从响应中获得网页源码,通过re模块解析网页中的指定URL,获取每一个图片的URL
通过枚举,生成器访问每一个图片的URL,并且将网站的返回数据传递给指定的解析函数
def parse(self, response):# 解析page页 获取图片URLimg_urls = re.findall(r'"thumbURL":"(.*?)"', response.text)# 发送请求获取图片数据for index, img_url in enumerate(img_urls):yield scrapy.Request(img_url, callback=self.get_img)
第二部分
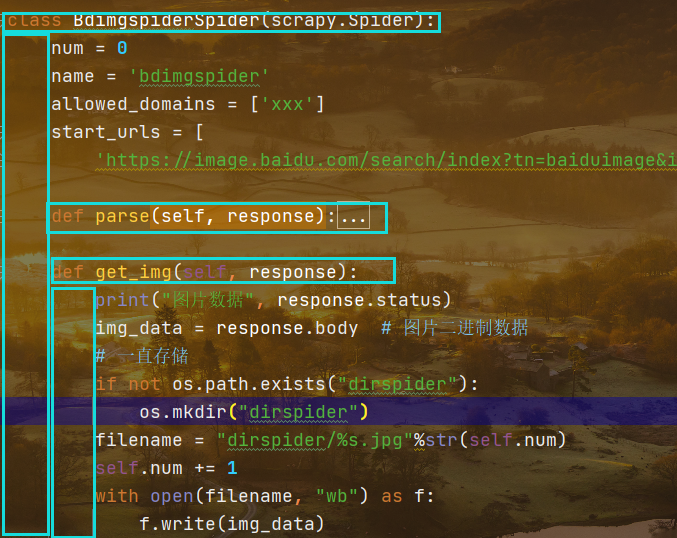
打印获得访问每张图片的响应状态码,确认响应正常
由变量img_data接受活到的响应数据,由于图片数据是二进制文件,所以这里获得的是响应的主体文字
建立文件夹,持久化存储数据
首先使用if语句判断不存在指定文件夹,然后使用os模块分别识别是否存在以及建立指定文件夹
单个文件,使用字符串拼接文件名字,在类下的第一行添加一个变量num,初始值为1,在文件名建立成功后,使用self.name格式自增加,方式图片的名字而非属性的名字重名
打开一个文件文件,以wb方式打开,然后使用写入方法写入上面建立的变量img_data,它会逐次获得每一个图片的二进制数据
最后使用管道存储
def get_img(self, response):print("图片数据", response.status)img_data = response.body # 图片二进制数据# 一直存储if not os.path.exists("dirspider"):os.mkdir("dirspider")filename = "dirspider/%s.jpg"%str(self.num)self.num += 1with open(filename, "wb") as f:f.write(img_data)
在管道存储中
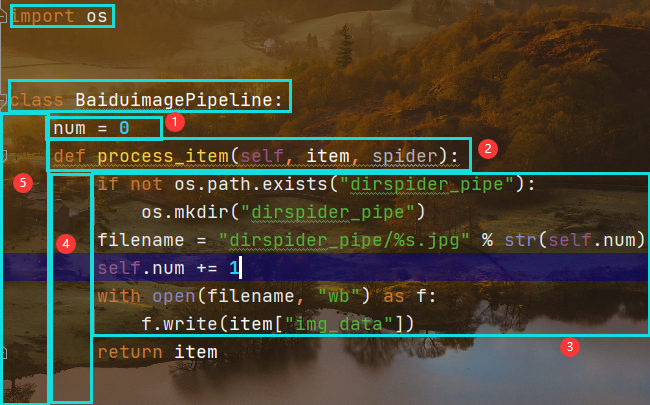
在管道中创建如下代码,首先是创建一个变量num初始值为1,用于自增长
# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass BaiduimageItem(scrapy.Item):# define the fields for your item here like:img_data = scrapy.Field()
然后定义执行item,在item中,有如下大致的流程,
首先在items中定义存储的变量,然后去piplines下引入items下包含该变量的类,然后去设置中打开管道,这是三部基础操作,便于我们使用管道存储数据
# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfacefrom .items import BaiduimageItemimport osclass BaiduimagePipeline:num = 0def process_item(self, item, spider):if not os.path.exists("dirspider_pipe"):os.mkdir("dirspider_pipe")filename = "dirspider_pipe/%s.jpg" % str(self.num)self.num += 1with open(filename, "wb") as f:f.write(item["img_data"])return item
在管道的类定义中,依然是创建一个变量初始值为零,然后在名为执行itme的函数中,定义存储图片的文件夹和文件的名称
定义文件夹主要由OS模块完成,只要不存在则创建该指定文件夹
定义文件名主要由管道名称,加上字符串而来,而字符串就是对自增加数值的转换
最关键的一步,打开刚才创建的文件,并且以二进制方式写入爬取到的图片数据
class BaiduimagePipeline:num = 0def process_item(self, item, spider):if not os.path.exists("dirspider_pipe"):os.mkdir("dirspider_pipe")filename = "dirspider_pipe/%s.jpg" % str(self.num)self.num += 1with open(filename, "wb") as f:f.write(item["img_data"])return item
批量爬取
第一个细节处理:关于获取有规律的图片URL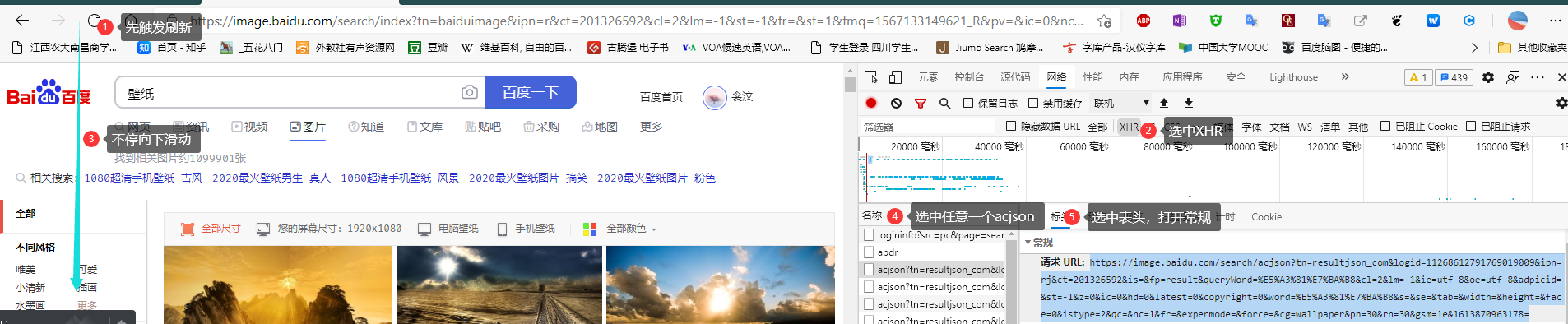
代码中的书写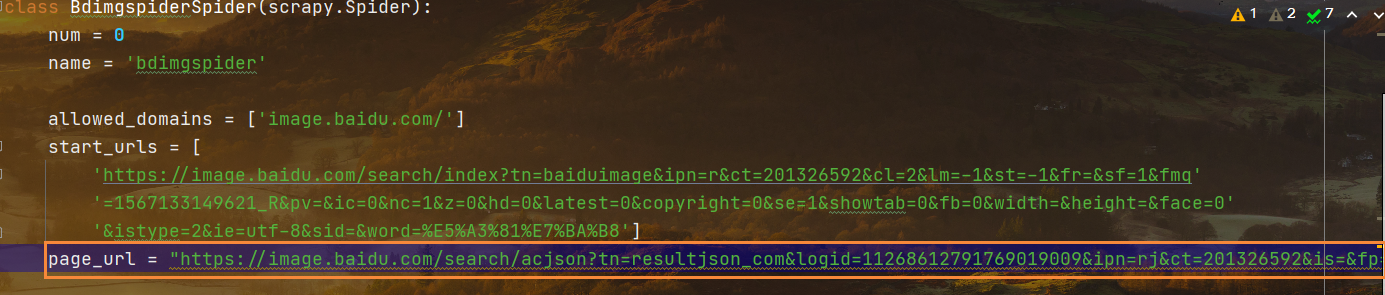
要修改的URL参数
修改后的样式
设置爬取指定页数的图片
设置变量,每次for遍历请求一次则变量自增减,然后将增减的变量乘以三十返回给原来的主页面,此时又会生成下一个包含30张图片的网页地址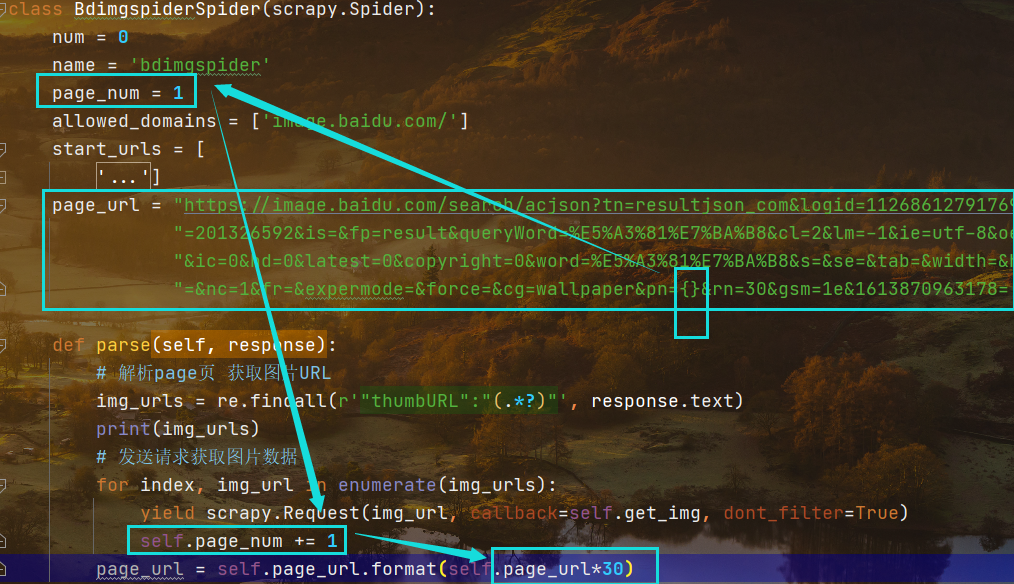
指定获取前四页的内容,超过四页则返回空(这是在函数里面可以这样用,在while语句中则使用break)for语句使用自增减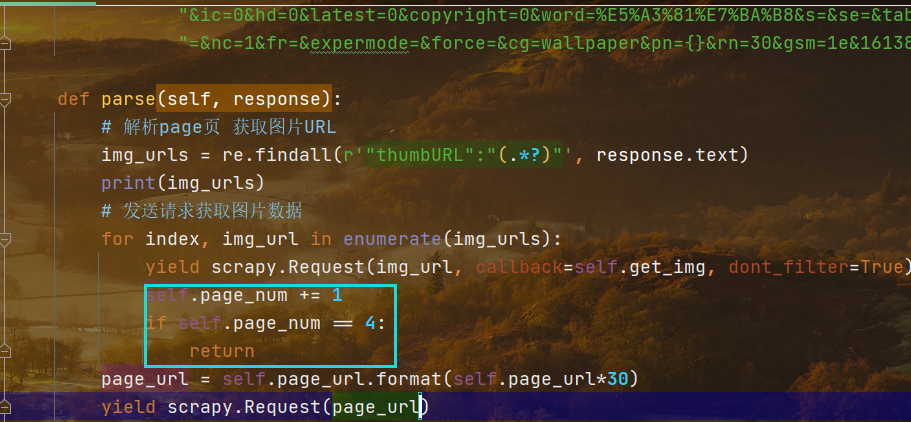
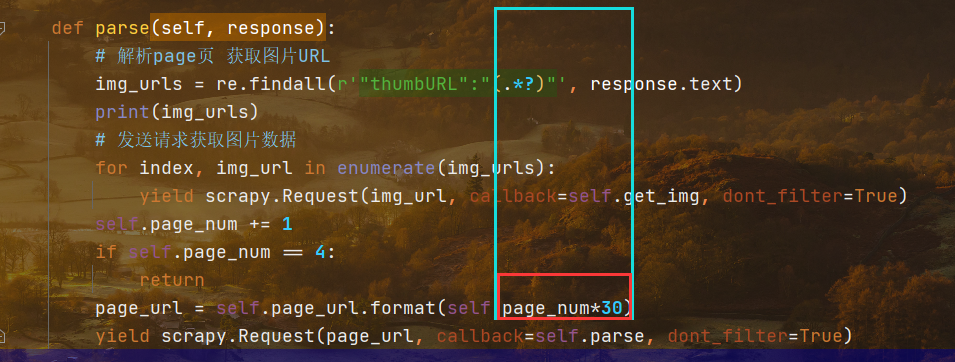
解决图片数量不足的问题
纠正写错的代码,生成语句中,每次被执行的page_url应该是由page_num乘法运算得出的结果
ImagesPipline类下载图片
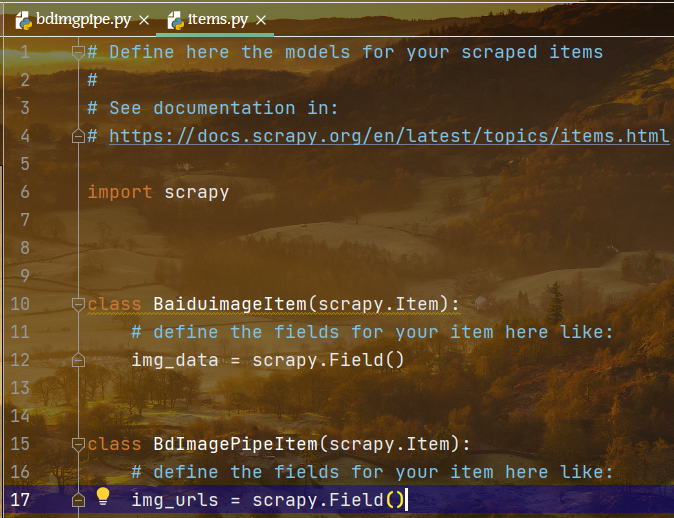
1 在items中创建和主程序名字对应的items类,且创建存储结构
class BdImagePipeItem(scrapy.Item):# define the fields for your item here like:img_urls = scrapy.Field()
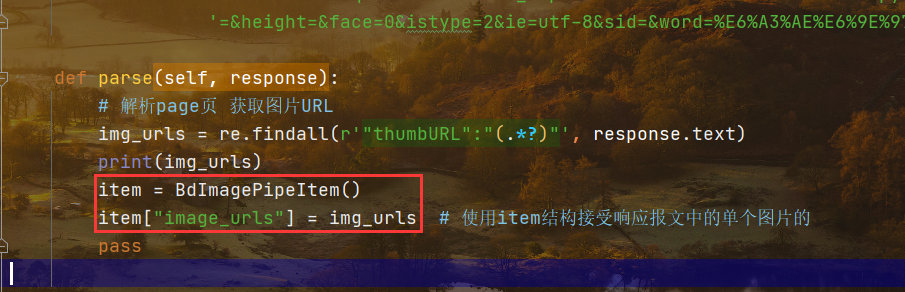
2 在主程序中创建存储结构,使用的是引用加字典的方式
首先在头位置导入items包中的类BdImgPipItem,然后再主程序中使用变量的方式实例化类
实例化向其传递之前已经创建好的单个图片url
3 导入框架中的类,并且继承用于处理图片存储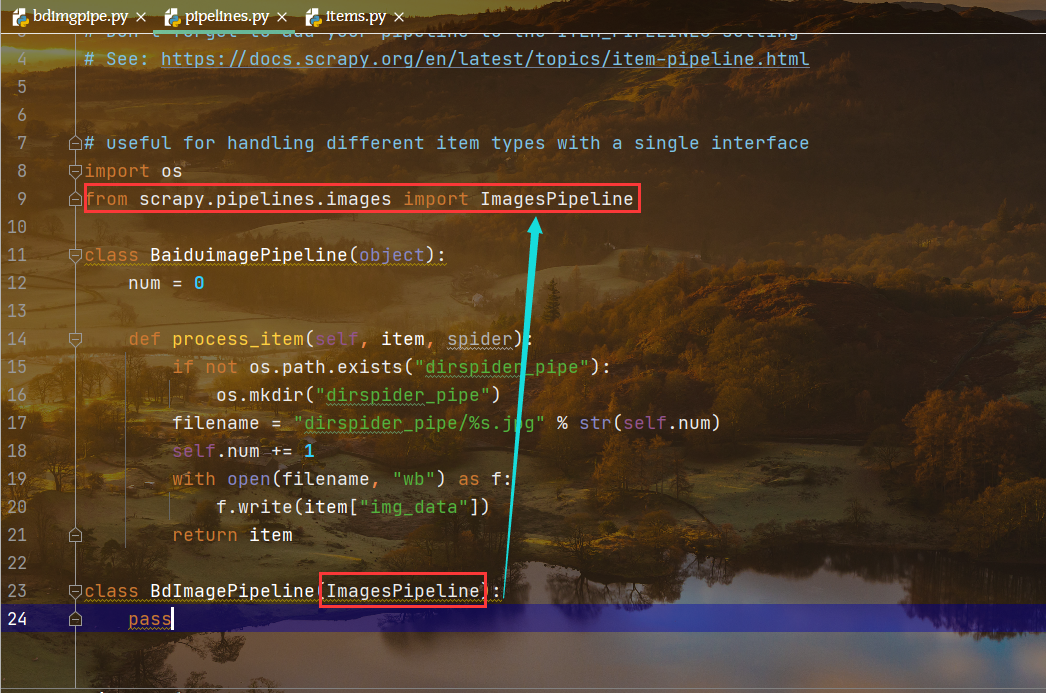
4 设置媒体管道类的存储位置
注意:由于是绝对路径,同一份代码到其他主机运行需要修改它的存储路径
5 在settings中打开管道
其实就是复制上一个管道,并且修改其名字,改一下优先级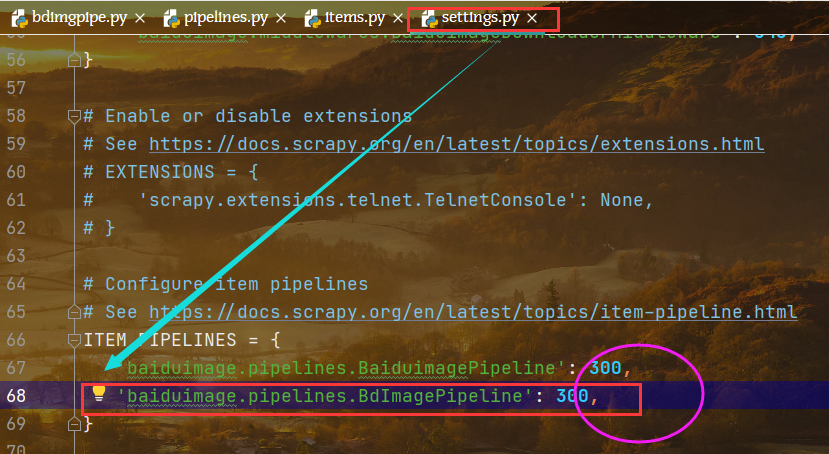
ImagesPipeline类简介
1 在主文件中从起始页发起请求,获得响应
2 正则表达式匹配每个图片的URL
3 将URL传递给items
4 pipeline收到items
在这个文件中,继承图片处理的管道类: from scrapy.pipelines.images import ImagesPipeline
从items中导入两个图片存储类: from .items import BaiduimageItem, BdImagePipeItem
定义图片管道类,并且继承图片处理管道类 : class BdImagePipeline(ImagesPipeline)
**
在settings中指定存储位置
IMAGES_STORE = r”C:\Users\41999\Documents\PycharmProjects\Python\TZ—Spyder\第九节Scrapy(六)\baiduimage\baiduimage\ImagePipedir”
ImagesPipeline类重写
实现图片管道类的代码
"""Images PipelineSee documentation in topics/media-pipeline.rst"""import functoolsimport hashlibfrom contextlib import suppressfrom io import BytesIOfrom itemadapter import ItemAdapterfrom PIL import Imagefrom scrapy.exceptions import DropItemfrom scrapy.http import Requestfrom scrapy.pipelines.files import FileException, FilesPipeline# TODO: from scrapy.pipelines.media import MediaPipelinefrom scrapy.settings import Settingsfrom scrapy.utils.misc import md5sumfrom scrapy.utils.python import to_bytesclass NoimagesDrop(DropItem):"""Product with no images exception"""class ImageException(FileException):"""General image error exception"""class ImagesPipeline(FilesPipeline):"""Abstract pipeline that implement the image thumbnail generation logic"""MEDIA_NAME = 'image'# Uppercase attributes kept for backward compatibility with code that subclasses# ImagesPipeline. They may be overridden by settings.MIN_WIDTH = 0MIN_HEIGHT = 0EXPIRES = 90THUMBS = {}DEFAULT_IMAGES_URLS_FIELD = 'image_urls'DEFAULT_IMAGES_RESULT_FIELD = 'images'# 解析settings里的配置字段def __init__(self, store_uri, download_func=None, settings=None):super().__init__(store_uri, settings=settings, download_func=download_func)if isinstance(settings, dict) or settings is None:settings = Settings(settings)resolve = functools.partial(self._key_for_pipe,base_class_name="ImagesPipeline",settings=settings)self.expires = settings.getint(resolve("IMAGES_EXPIRES"), self.EXPIRES)if not hasattr(self, "IMAGES_RESULT_FIELD"):self.IMAGES_RESULT_FIELD = self.DEFAULT_IMAGES_RESULT_FIELDif not hasattr(self, "IMAGES_URLS_FIELD"):self.IMAGES_URLS_FIELD = self.DEFAULT_IMAGES_URLS_FIELDself.images_urls_field = settings.get(resolve('IMAGES_URLS_FIELD'),self.IMAGES_URLS_FIELD)self.images_result_field = settings.get(resolve('IMAGES_RESULT_FIELD'),self.IMAGES_RESULT_FIELD)self.min_width = settings.getint(resolve('IMAGES_MIN_WIDTH'), self.MIN_WIDTH)self.min_height = settings.getint(resolve('IMAGES_MIN_HEIGHT'), self.MIN_HEIGHT)self.thumbs = settings.get(resolve('IMAGES_THUMBS'), self.THUMBS)@classmethoddef from_settings(cls, settings):s3store = cls.STORE_SCHEMES['s3']s3store.AWS_ACCESS_KEY_ID = settings['AWS_ACCESS_KEY_ID']s3store.AWS_SECRET_ACCESS_KEY = settings['AWS_SECRET_ACCESS_KEY']s3store.AWS_ENDPOINT_URL = settings['AWS_ENDPOINT_URL']s3store.AWS_REGION_NAME = settings['AWS_REGION_NAME']s3store.AWS_USE_SSL = settings['AWS_USE_SSL']s3store.AWS_VERIFY = settings['AWS_VERIFY']s3store.POLICY = settings['IMAGES_STORE_S3_ACL']gcs_store = cls.STORE_SCHEMES['gs']gcs_store.GCS_PROJECT_ID = settings['GCS_PROJECT_ID']gcs_store.POLICY = settings['IMAGES_STORE_GCS_ACL'] or Noneftp_store = cls.STORE_SCHEMES['ftp']ftp_store.FTP_USERNAME = settings['FTP_USER']ftp_store.FTP_PASSWORD = settings['FTP_PASSWORD']ftp_store.USE_ACTIVE_MODE = settings.getbool('FEED_STORAGE_FTP_ACTIVE')store_uri = settings['IMAGES_STORE']return cls(store_uri, settings=settings)def file_downloaded(self, response, request, info, *, item=None):return self.image_downloaded(response, request, info, item=item)def image_downloaded(self, response, request, info, *, item=None):checksum = Nonefor path, image, buf in self.get_images(response, request, info, item=item):if checksum is None:buf.seek(0)checksum = md5sum(buf)width, height = image.sizeself.store.persist_file(path, buf, info,meta={'width': width, 'height': height},headers={'Content-Type': 'image/jpeg'})return checksum# 图片获取方法 图片大小的过滤 缩略图的生成def get_images(self, response, request, info, *, item=None):path = self.file_path(request, response=response, info=info, item=item)orig_image = Image.open(BytesIO(response.body))width, height = orig_image.sizeif width < self.min_width or height < self.min_height:raise ImageException("Image too small "f"({width}x{height} < "f"{self.min_width}x{self.min_height})")image, buf = self.convert_image(orig_image)yield path, image, buffor thumb_id, size in self.thumbs.items():thumb_path = self.thumb_path(request, thumb_id, response=response, info=info)thumb_image, thumb_buf = self.convert_image(image, size)yield thumb_path, thumb_image, thumb_buf# 转换图片格式def convert_image(self, image, size=None):if image.format == 'PNG' and image.mode == 'RGBA':background = Image.new('RGBA', image.size, (255, 255, 255))background.paste(image, image)image = background.convert('RGB')elif image.mode == 'P':image = image.convert("RGBA")background = Image.new('RGBA', image.size, (255, 255, 255))background.paste(image, image)image = background.convert('RGB')elif image.mode != 'RGB':image = image.convert('RGB')if size:image = image.copy()image.thumbnail(size, Image.ANTIALIAS)buf = BytesIO()image.save(buf, 'JPEG')return image, buf# 生成媒体请求def get_media_requests(self, item, info):# 得到图片URL 变成请求 发给引擎urls = ItemAdapter(item).get(self.images_urls_field, [])return [Request(u) for u in urls]def item_completed(self, results, item, info): # 此方法 提取文件名进行改写with suppress(KeyError):ItemAdapter(item)[self.images_result_field] = [x for ok, x in results if ok]return itemdef file_path(self, request, response=None, info=None, *, item=None):image_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()# URL是唯一 hash值也是唯一 图片名字是唯一的return f'full/{image_guid}.jpg'def thumb_path(self, request, thumb_id, response=None, info=None):# 缩略图的存储路径thumb_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()return f'thumbs/{thumb_id}/{thumb_guid}.jpg'
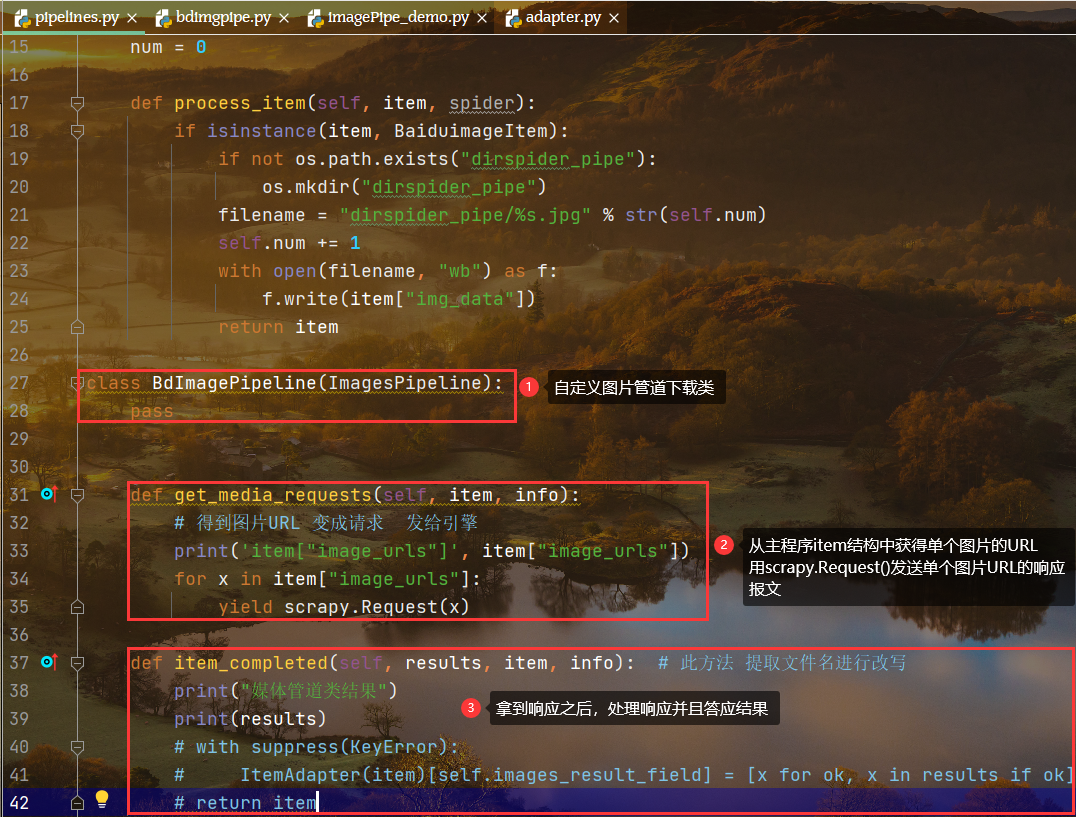
自定义图片下载管道类
注意:自定义图片下载管道类的方法写在pipelines文件中
需要在items中建立对应结构,同时在settings中编写并且开启对应管道
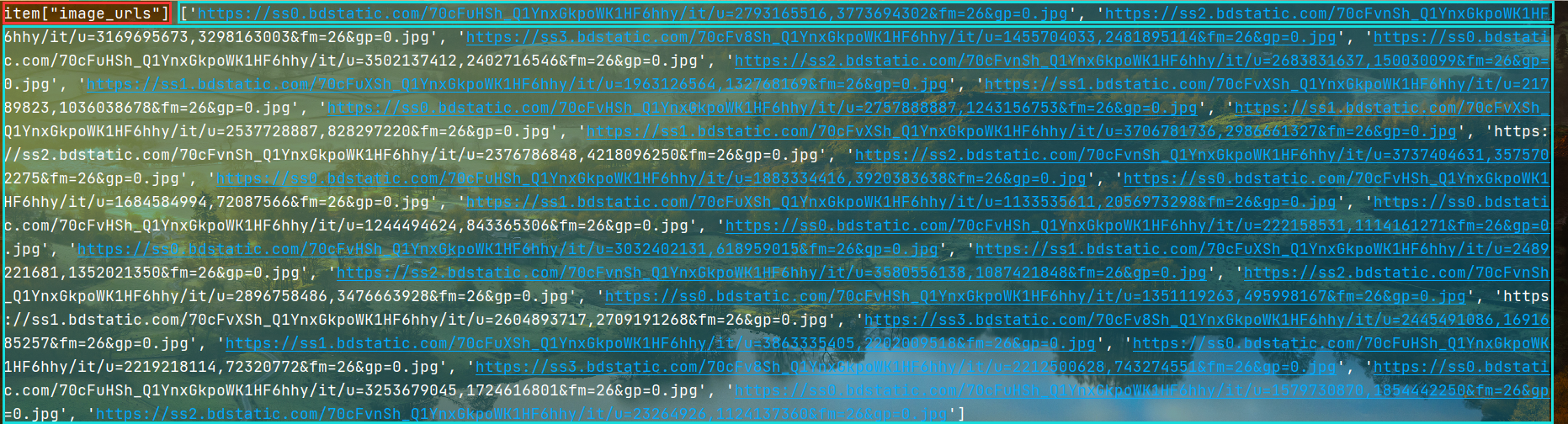
class BdImagePipeline(ImagesPipeline):passdef get_media_requests(self, item, info):# 得到图片URL 变成请求 发给引擎print('item["image_urls"]', item["image_urls"])for x in item["image_urls"]:yield scrapy.Request(x)def item_completed(self, results, item, info): # 此方法 提取文件名进行改写print("媒体管道类结果")print(results)# with suppress(KeyError):# ItemAdapter(item)[self.images_result_field] = [x for ok, x in results if ok]# return item
打印的结构内容信息
打印媒体管道类内容
分别打印出获取的URL对象,图片的存储路径,MD5加密,以及下载状态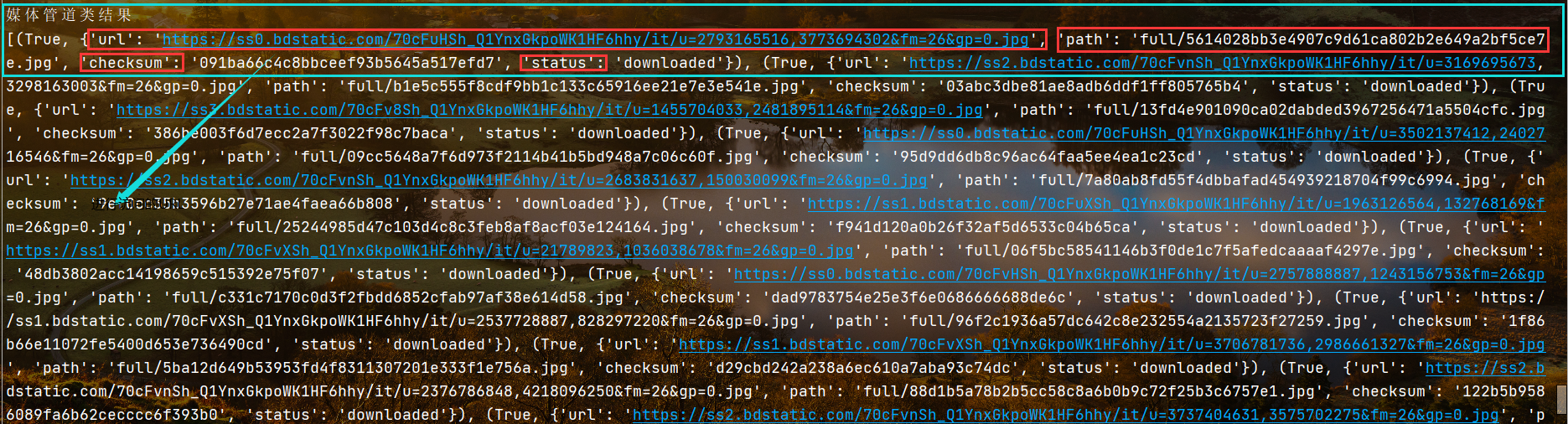
对应文件的查找
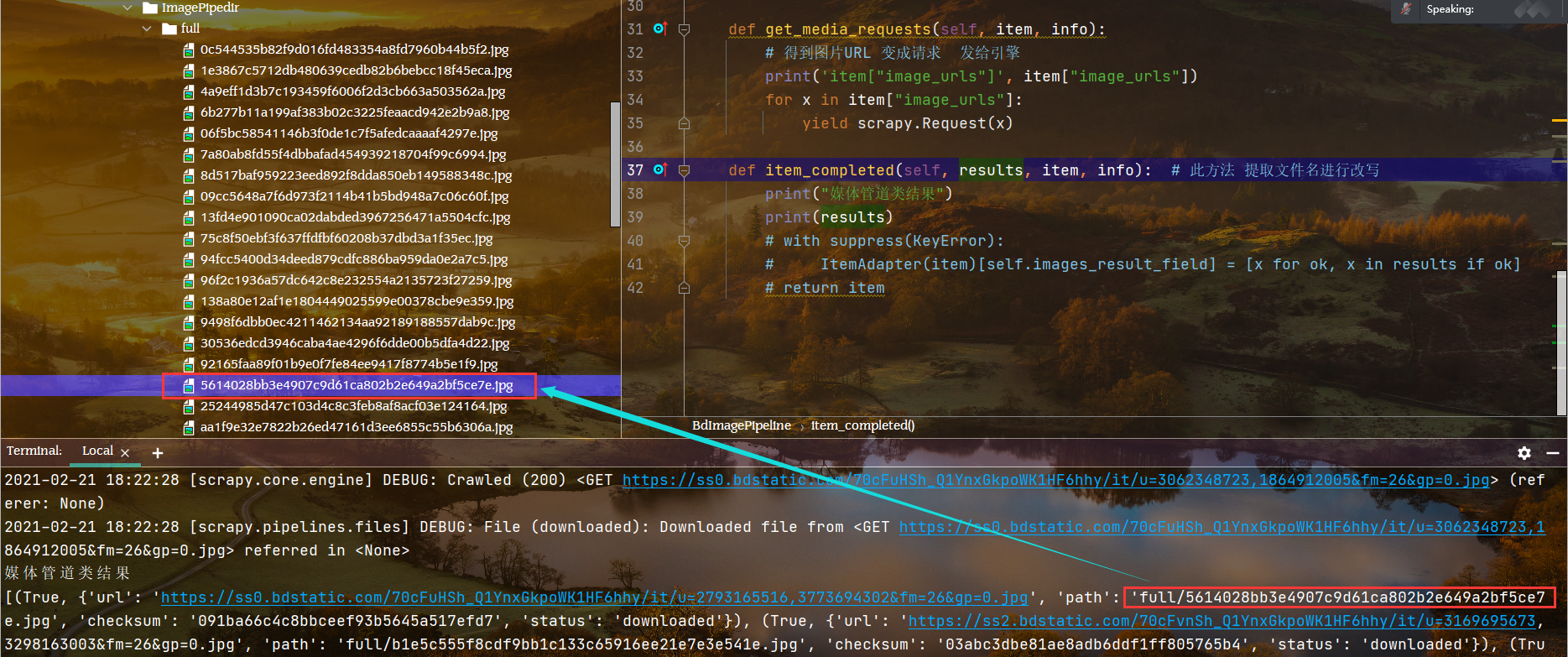
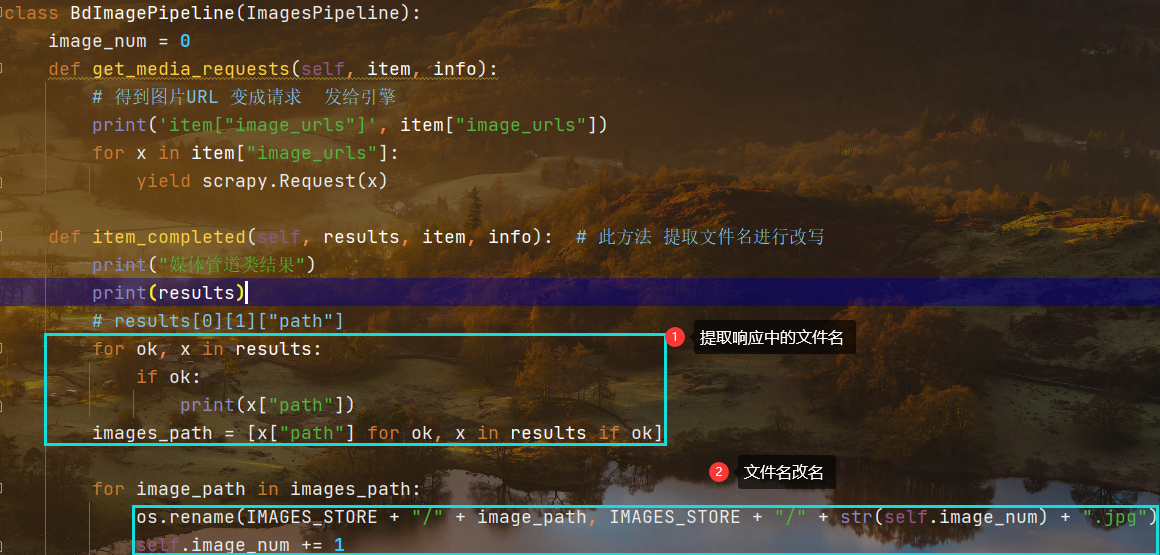
构建代码更改文件名字
首先从响应中提取文件名,注意文件名存放的层次,从元组,列表到键值对依次深入提取
注意加文件时用的反斜杠,这个格式要和之前在settings中设置的存储绝对路径保持一致
调试代码的时候,一定要把之前的内容全部删除重新爬取
class BdImagePipeline(ImagesPipeline):image_num = 0def get_media_requests(self, item, info):# 得到图片URL 变成请求 发给引擎print('item["image_urls"]', item["image_urls"])for x in item["image_urls"]:yield scrapy.Request(x)def item_completed(self, results, item, info): # 此方法 提取文件名进行改写print("媒体管道类结果")print(results)# results[0][1]["path"]for ok, x in results:if ok:print(x["path"])images_path = [x["path"] for ok, x in results if ok]for image_path in images_path:os.rename(IMAGES_STORE + "/" + image_path, IMAGES_STORE + "/" + str(self.image_num) + ".jpg")self.image_num += 1

若有收获,就点个赞吧
0 人点赞
