- 项目结构
- Request
- Response
- 日志使用
- 第三个参数 标准输出 LOG_STDOUT
- Github登录
- 项目遗留报错
项目结构
Request Response
日志使用 Github登录
**
Request
分为三个部分解析,分别是参数,功能, 返回值
参数:
| url, | callback=None, | method=’GET’ |
|---|---|---|
| headers=None, | body=None,cookies=None, | |
| meta=None, | encoding=’utf-8’, | priority=0, |
| dont_filter=False, | errback=None, | flags=None, |
| cb_kwargs=None |
功能
返回值
第一个 —- priority
功能:修改请求在调度器排队处理的优先级
参数: 数字(数字越大,优先级越高,越容易被处理请求从而获得响应)
返回值:
第二个 —- tdont_filter=False_filter=Falsedont_filter=False
功能: 对请求进行过滤,双重否定表肯定,那就是过滤
第三个 构造请求,包含headers url meta
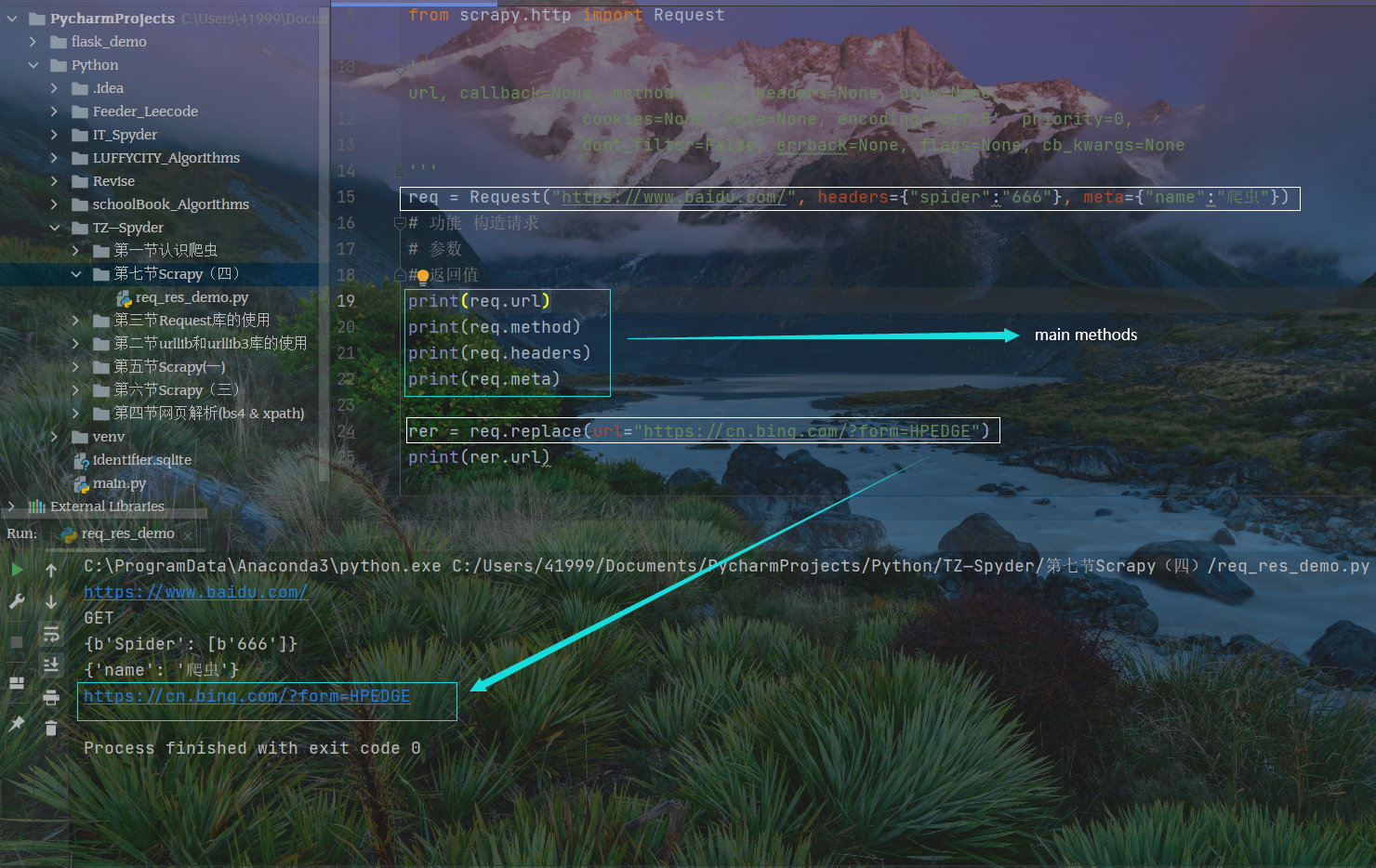
from scrapy.http import Request'''url, callback=None, method='GET', headers=None, body=None,cookies=None, meta=None, encoding='utf-8', priority=0,dont_filter=False, errback=None, flags=None, cb_kwargs=None'''req = Request("https://www.baidu.com/", headers={"spider":"666"}, meta={"name":"爬虫"})# 功能 构造请求# 参数# 返回值print(req.url)print(req.method)print(req.headers)print(req.meta)rer = req.replace(url="https://cn.bing.com/?form=HPEDGE")print(rer.url)
FormRequest
导入包
from scrapy.http import Request, FormRequest
源码
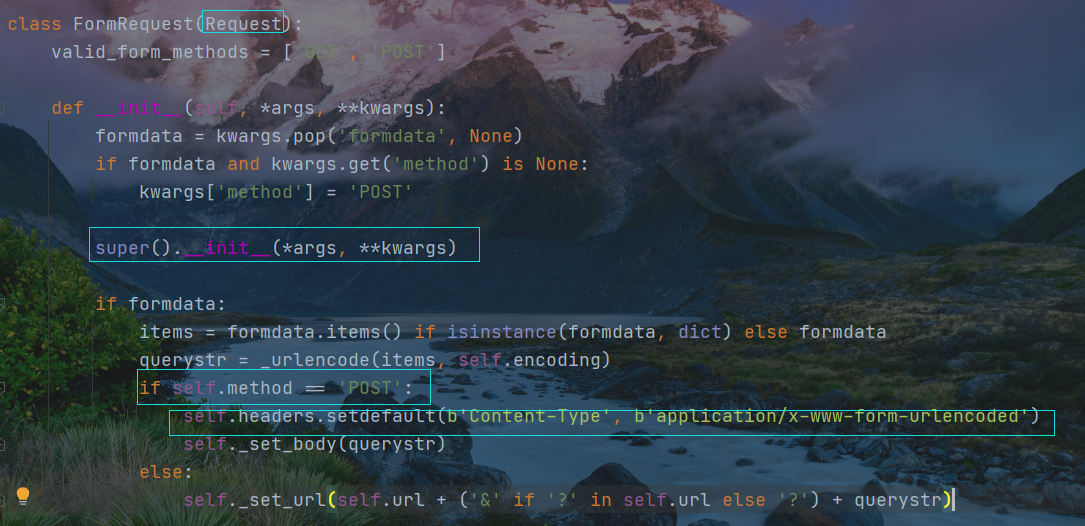
class FormRequest(Request):valid_form_methods = ['GET', 'POST']def __init__(self, *args, **kwargs):formdata = kwargs.pop('formdata', None)if formdata and kwargs.get('method') is None:kwargs['method'] = 'POST'super().__init__(*args, **kwargs)if formdata:items = formdata.items() if isinstance(formdata, dict) else formdataquerystr = _urlencode(items, self.encoding)if self.method == 'POST':self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')self._set_body(querystr)else:self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)
Response
对象参数返回值
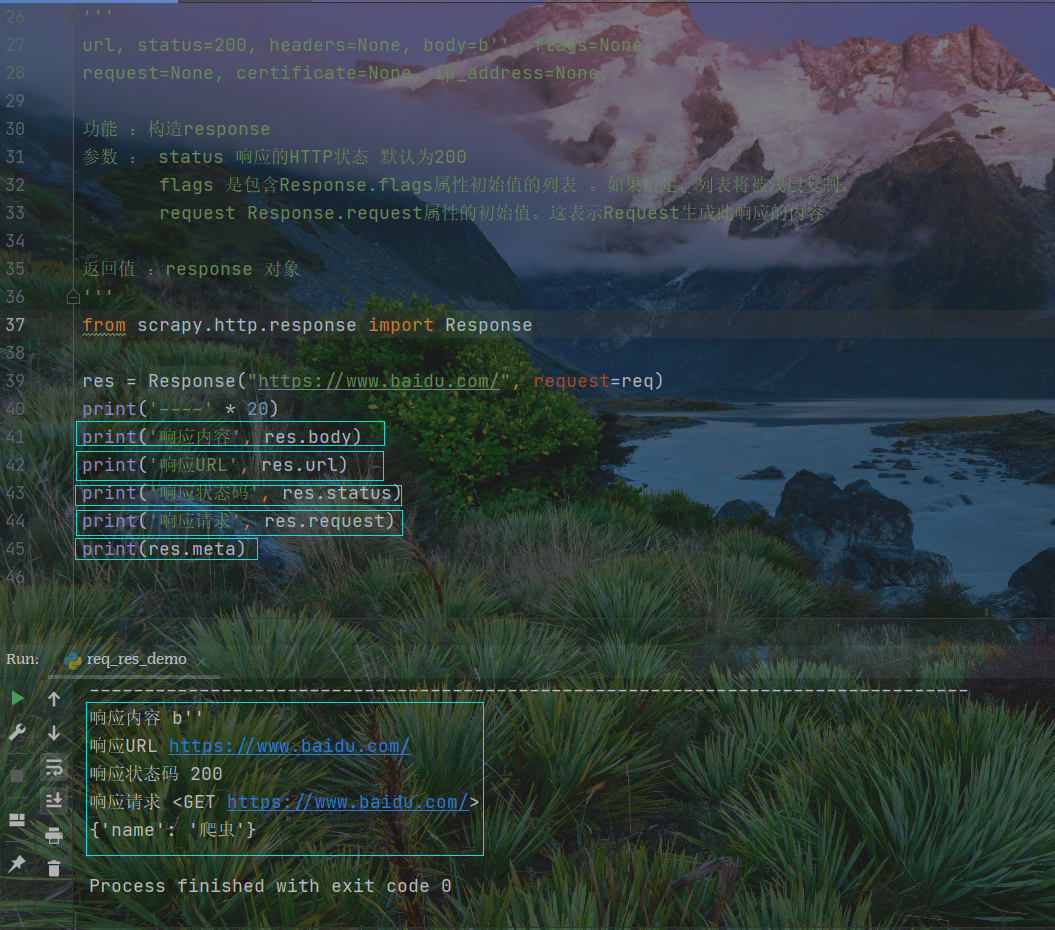
'''url, status=200, headers=None, body=b'', flags=None,request=None, certificate=None, ip_address=None,功能 :构造response参数 : status 响应的HTTP状态 默认为200flags 是包含Response.flags属性初始值的列表 。如果给定,列表将被浅层复制。request Response.request属性的初始值。这表示Request生成此响应的内容返回值 :response 对象'''from scrapy.http.response import Responseres = Response("https://www.baidu.com/", request=req)print('----' * 20)print('响应内容', res.body)print('响应URL', res.url)print('响应状态码', res.status)print('响应请求', res.request)print(res.meta)
测试状况
日志使用
创建项目
cd C:\Users\41999\Documents\PycharmProjects\Python\TZ—Spyder\第七节Scrapy(四)\project# 创建项目scrapy startproject baidu# 进入项目文件夹cd baidu# 创建模板 注意命令行command line需要带网址 但网址不能带http请求scrapy genspider bd www.baidu.com
配置settings.py文件
添加请求头的代理

添加日志配置
# 日志的设置LOG_FILE = 'bd.log'LOG_FORMAT = '%(ascTime)s [%(name)s] %(levelname)s: %(message)s'LOG_DATEFORMAT = '%Y'

测试日志记录
scrapy crawl bd
运行结果

日志文件配置的参数解读
第一个参数—-LOG_ENABLED
设置日志是否打印在控制台,若值为False,则无论如何不会出现在控制台,无论是否有db.log日志文件

第二个参数 日志等级
LOG_LEVEL = 'DEBUG'# 调试信息的六个等级# DEBUG < INFO < WARNING < ERROR < CRITICAL
log文件中本就有这些不同等级的信息,可以利用等级设置剥离日志信息,一部分在控制台显示,一部分在log日志中显示

日志编码格式设置
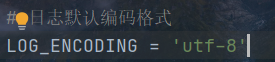
第三个参数 标准输出 LOG_STDOUT
默认值为False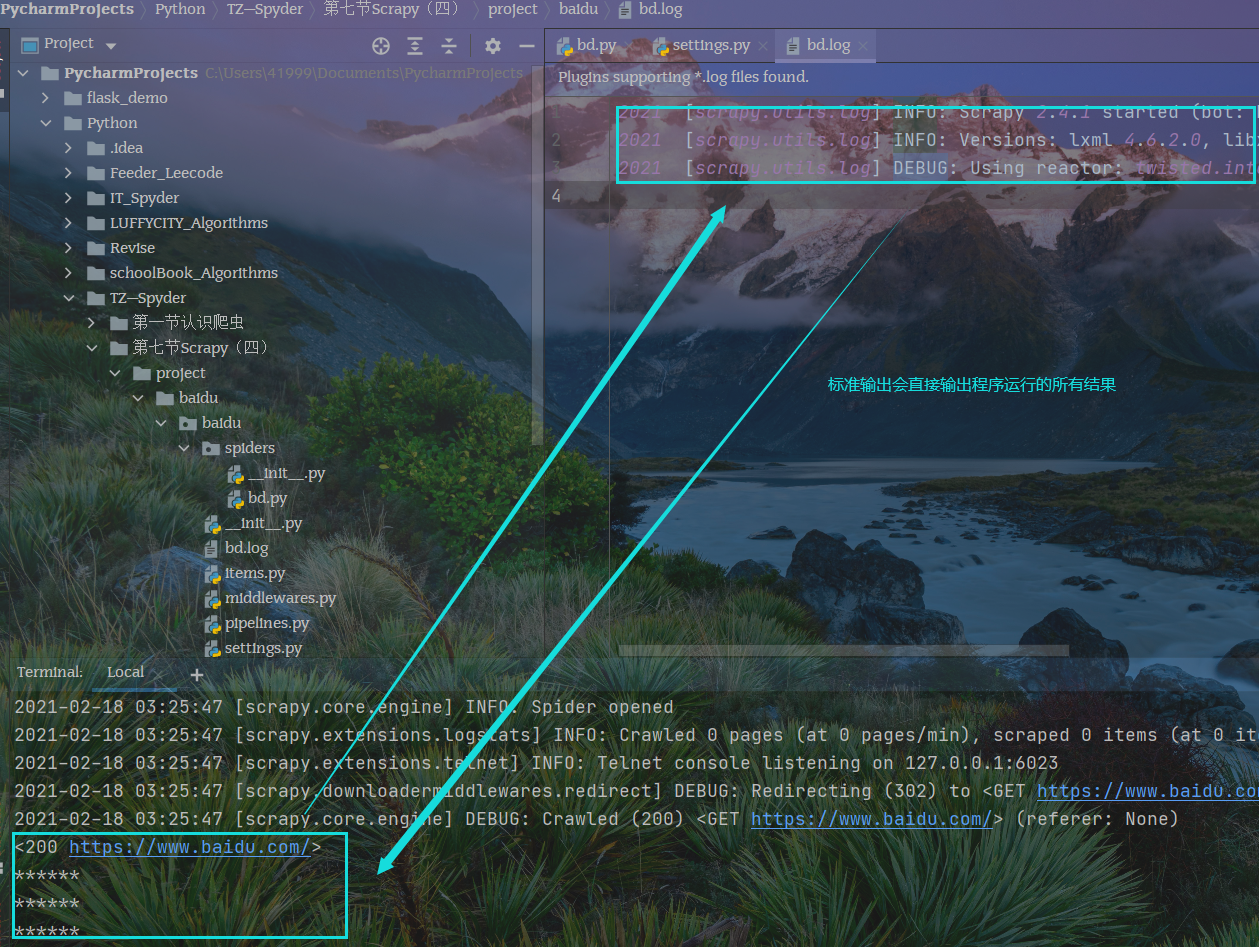
Ps: 这里程序代码出现问题,无法实现运行结果的部分呈现,print()打印语句(即标准输出在控制台),其他日志信息放在log日志文件里,无奈注释除日志开启设置外的所有代码,方才出现打印结果。
特别注意
有两个日志设置项目,它们的值无需双引号包裹
分别是开启日志 标准输出
补充
self.logger.warning("可能出现错误")

Github登录
操作流程
1,先登录再退出
2,用错误密码登录,打开调试,进入第一个session,获取请求头信息
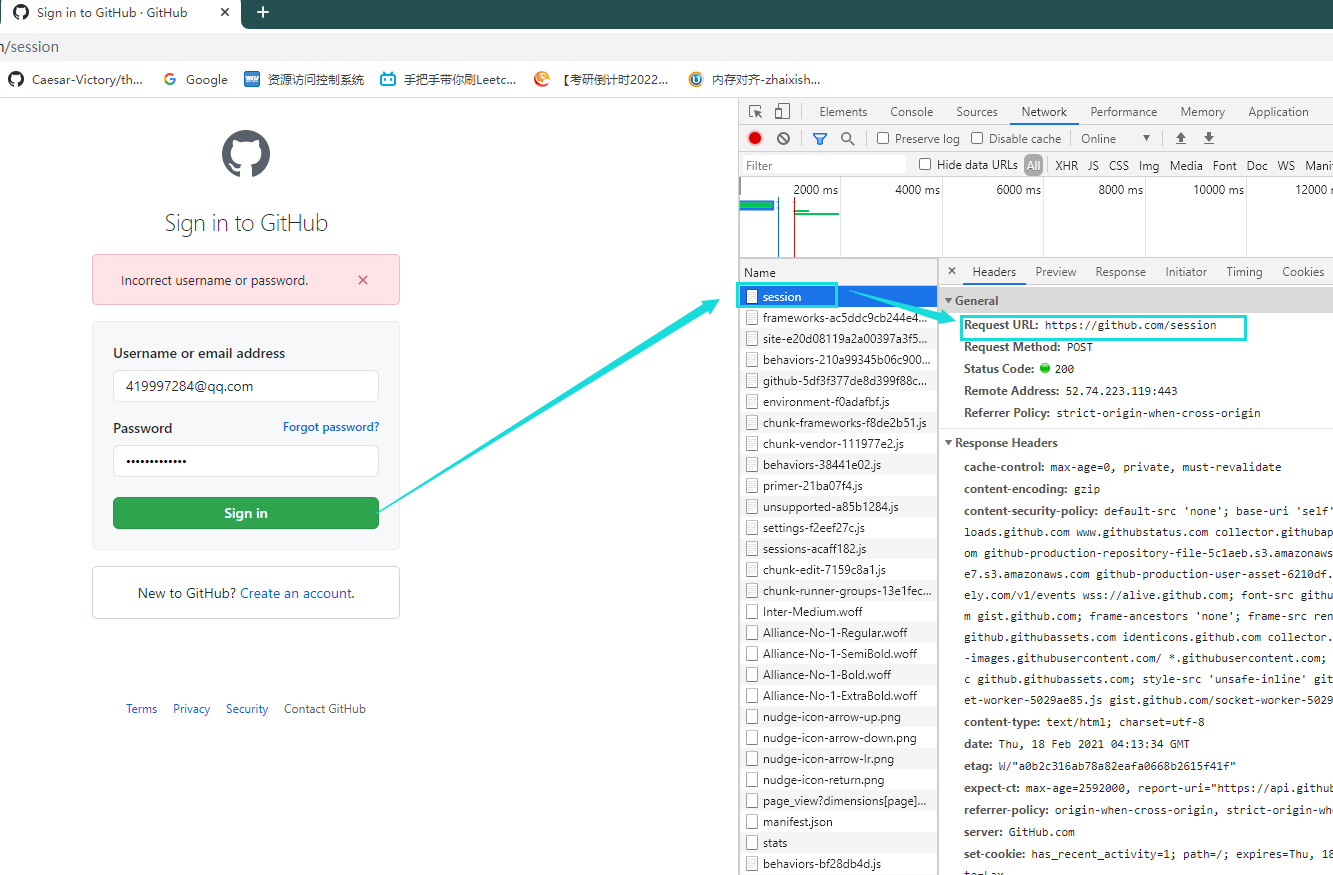
3,复制整个form表单 研究其内容,两次尝试登录,比较两次form表单的区别
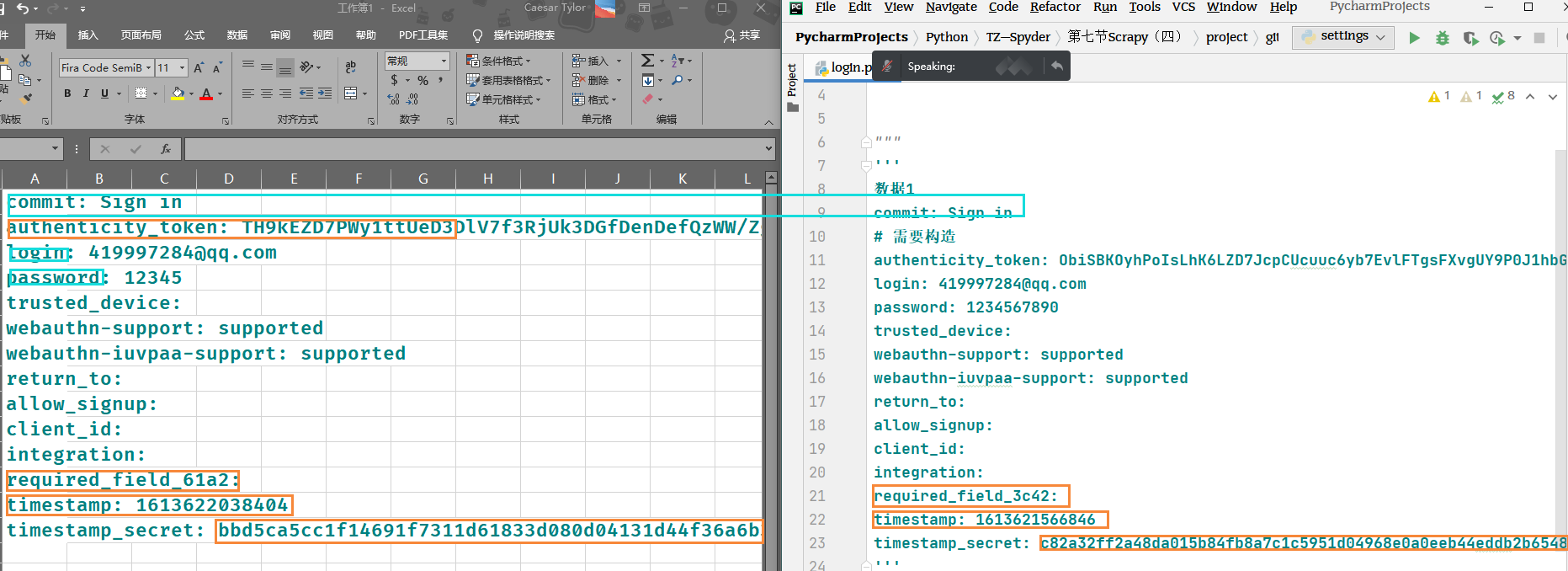
authenticity_token:login: 419997284@qq.compassword: 1234567890timestamptimestamp_secret:
4,分析请求流程
1 验证源码中特定数据段的唯一性
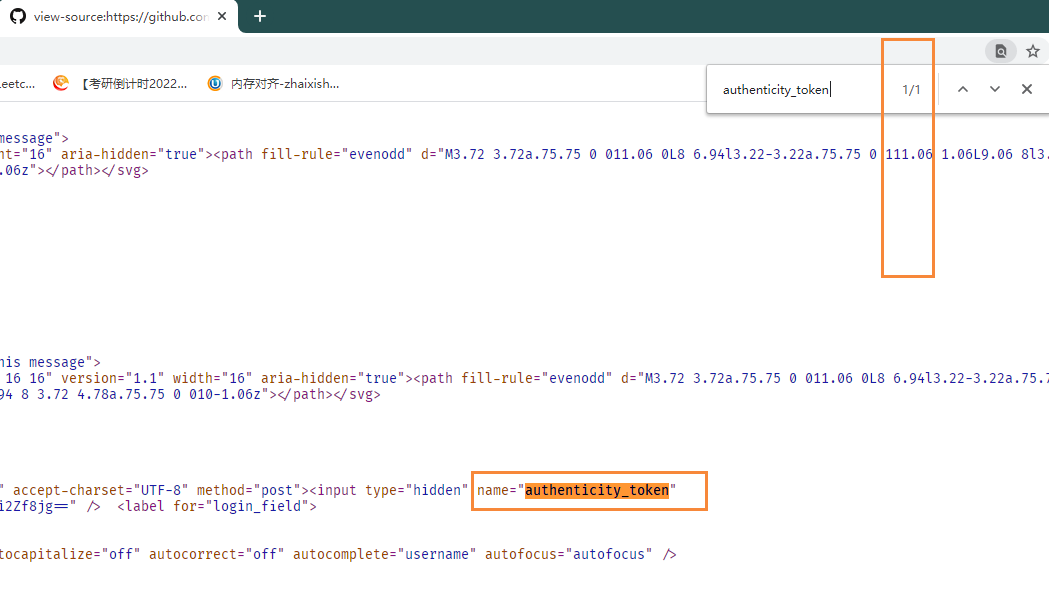
向 https://github.com/session 以POST方式提交用户名,密码等数据,获取登录页面访问 https://github.com/login 获取 https://github.com/session 需要的参数
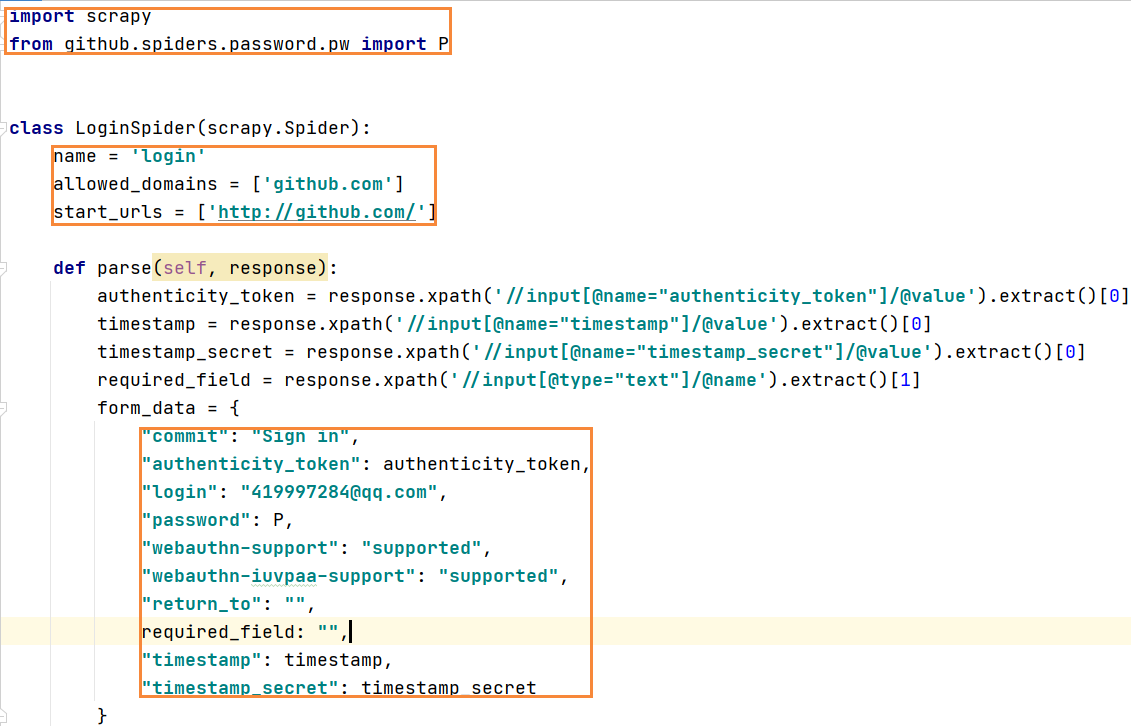
5 解析登录页面的源码 拿到需要构造的信息
6 以字典方式构建程序向https://github.com/session推的信息,模拟浏览器
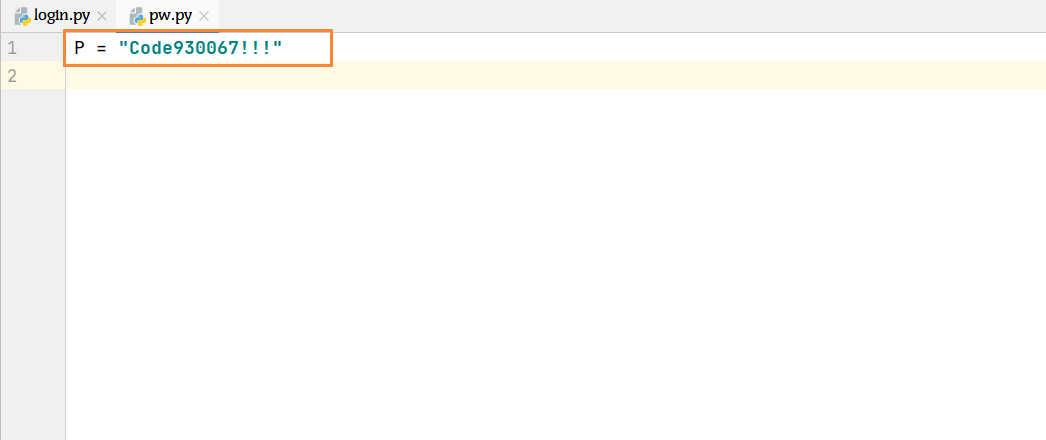
7 密码需要单独构建一个文件,以字符串的方式构建密码
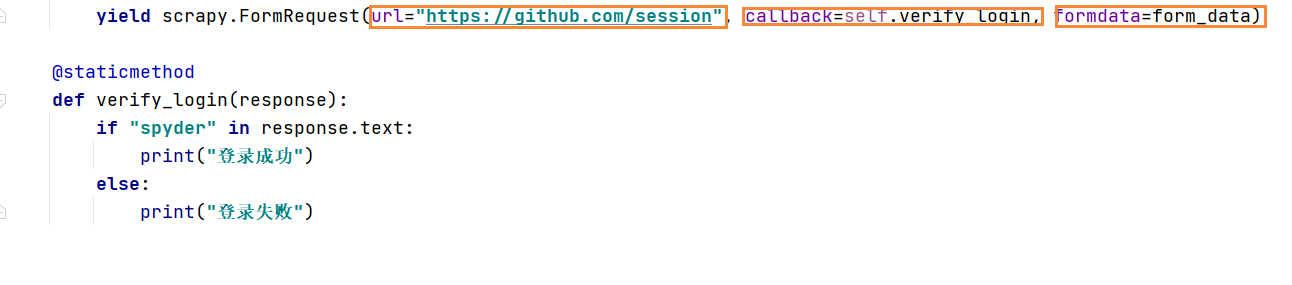
8 生成的请求需要向另外一个函数回调,便于直观回报访问是否成功
细节处理:
导入包的时候需要单独将其设置为root文件夹
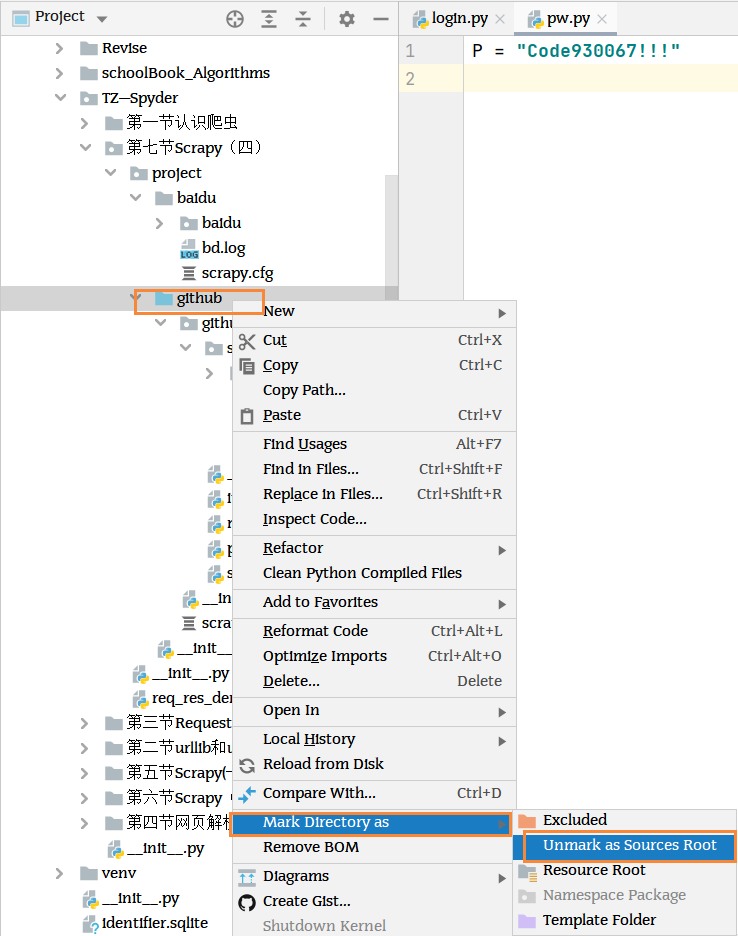
代码规范性:导入包的语句必须置顶,字符串信息置底
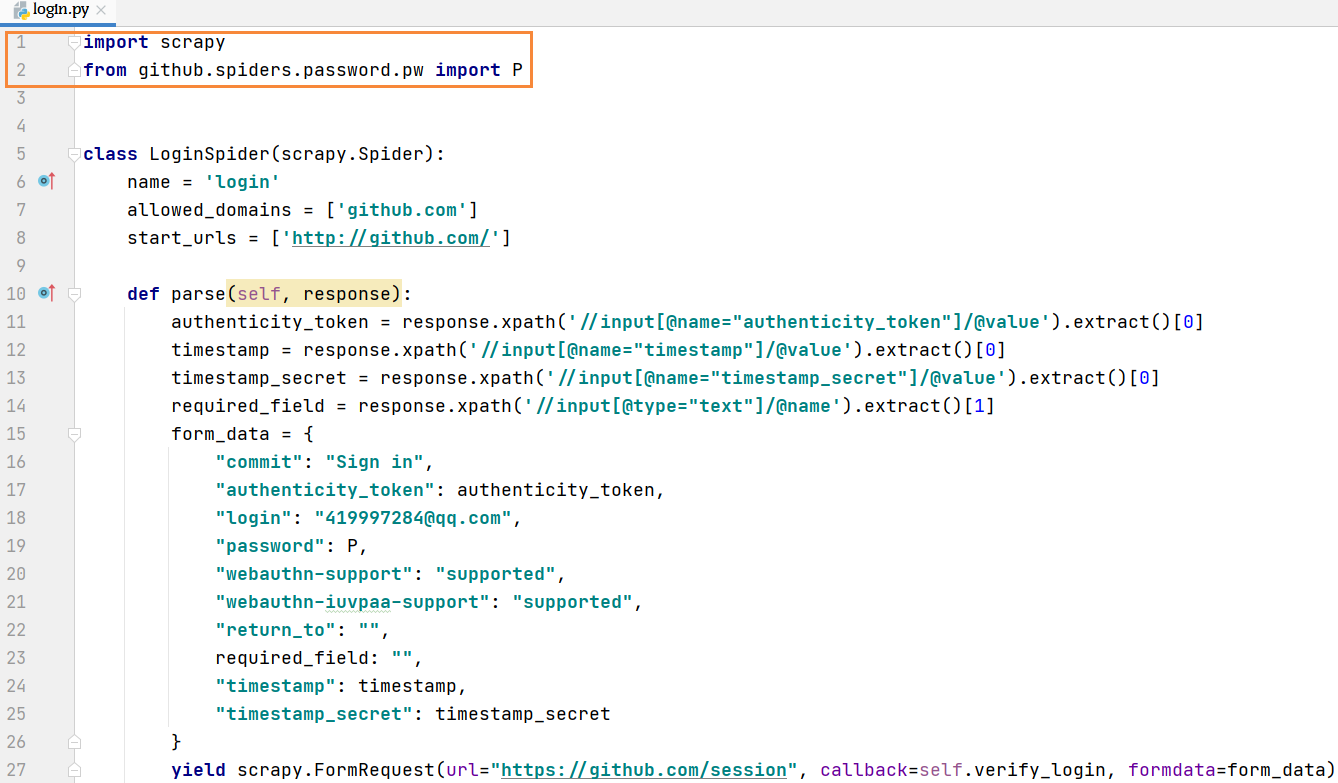

完整项目代码
import scrapyfrom github.spiders.password.pw import Pclass LoginSpider(scrapy.Spider):name = 'login'allowed_domains = ['github.com']start_urls = ['http://github.com/']def parse(self, response):authenticity_token = response.xpath('//input[@name="authenticity_token"]/@value').extract()[0]timestamp = response.xpath('//input[@name="timestamp"]/@value').extract()[0]timestamp_secret = response.xpath('//input[@name="timestamp_secret"]/@value').extract()[0]required_field = response.xpath('//input[@type="text"]/@name').extract()[1]form_data = {"commit": "Sign in","authenticity_token": authenticity_token,"login": "419997284@qq.com","password": P,"webauthn-support": "supported","webauthn-iuvpaa-support": "supported","return_to": "",required_field: "","timestamp": timestamp,"timestamp_secret": timestamp_secret}yield scrapy.FormRequest(url="https://github.com/session", callback=self.verify_login, formdata=form_data)@staticmethoddef verify_login(response):if "spyder" in response.text:print("登录成功")else:print("登录失败")"""登录github请求流程 向 https://github.com/session 以POST方式提交用户名,密码等数据,获取登录页面访问 https://github.com/login 获取 https://github.com/session 需要的参数"""'''数据1commit: Sign in# 需要构造authenticity_token: ObiSBKOyhPoIsLhK6LZD7JcpCUcuuc6yb7EvlFTgsFXvgUY9P0J1hbG3siEh9hXkCPHmN/JbKstrUVxcTfTtog==login: 419997284@qq.compassword: 1234567890trusted_device:webauthn-support: supportedwebauthn-iuvpaa-support: supportedreturn_to:allow_signup:client_id:integration:required_field_3c42:timestamp: 1613621566846timestamp_secret: c82a32ff2a48da015b84fb8a7c1c5951d04968e0a0eeb44eddb2b654895f62cb''''''需要构造的数据authenticity_token:login: 419997284@qq.compassword: 1234567890timestamptimestamp_secret:参数获取的方式:1 之前请求页面中获取2 js代码动态构造'''
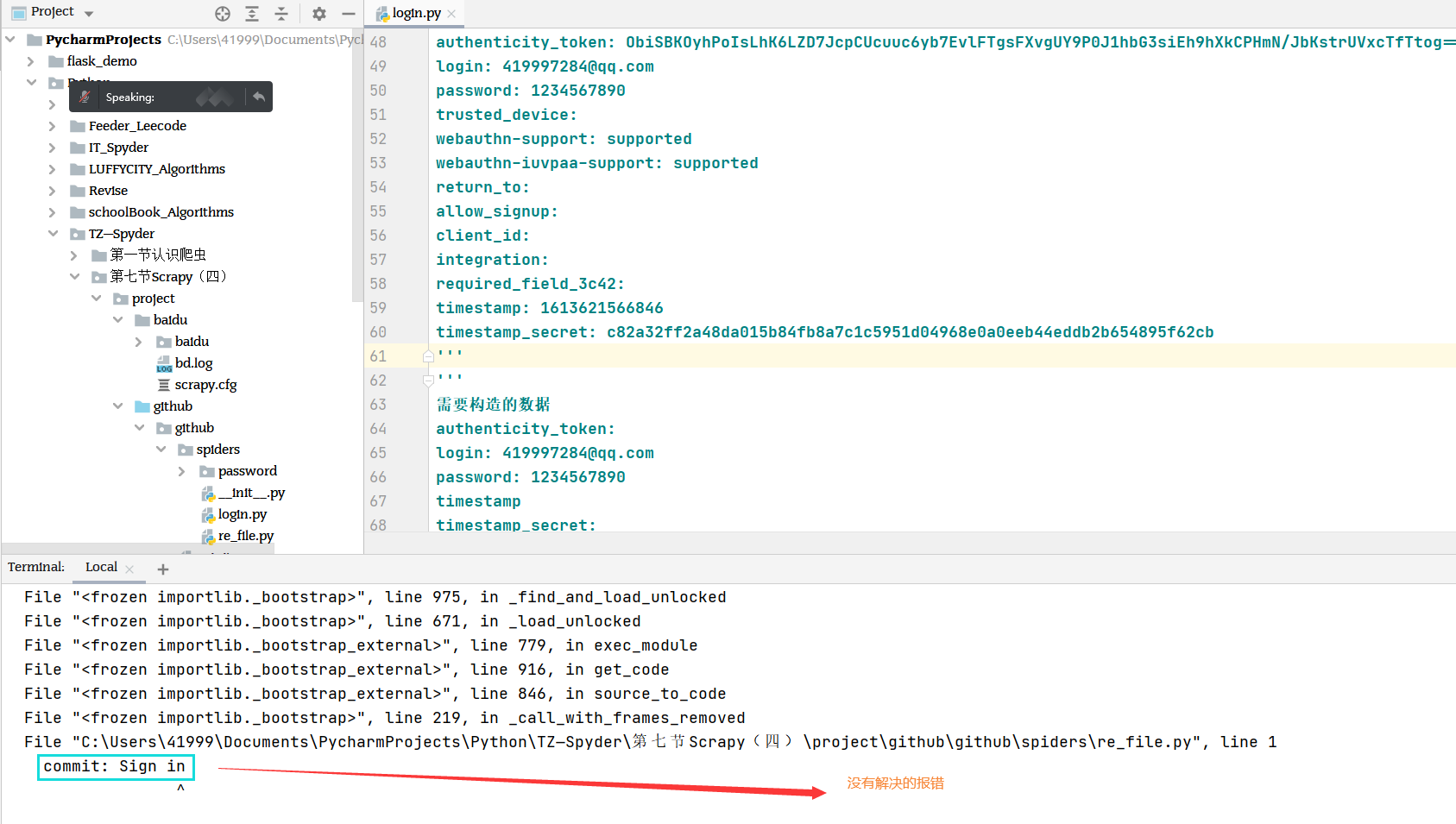
项目遗留报错

若有收获,就点个赞吧
0 人点赞
