下载中间件
中间件信息
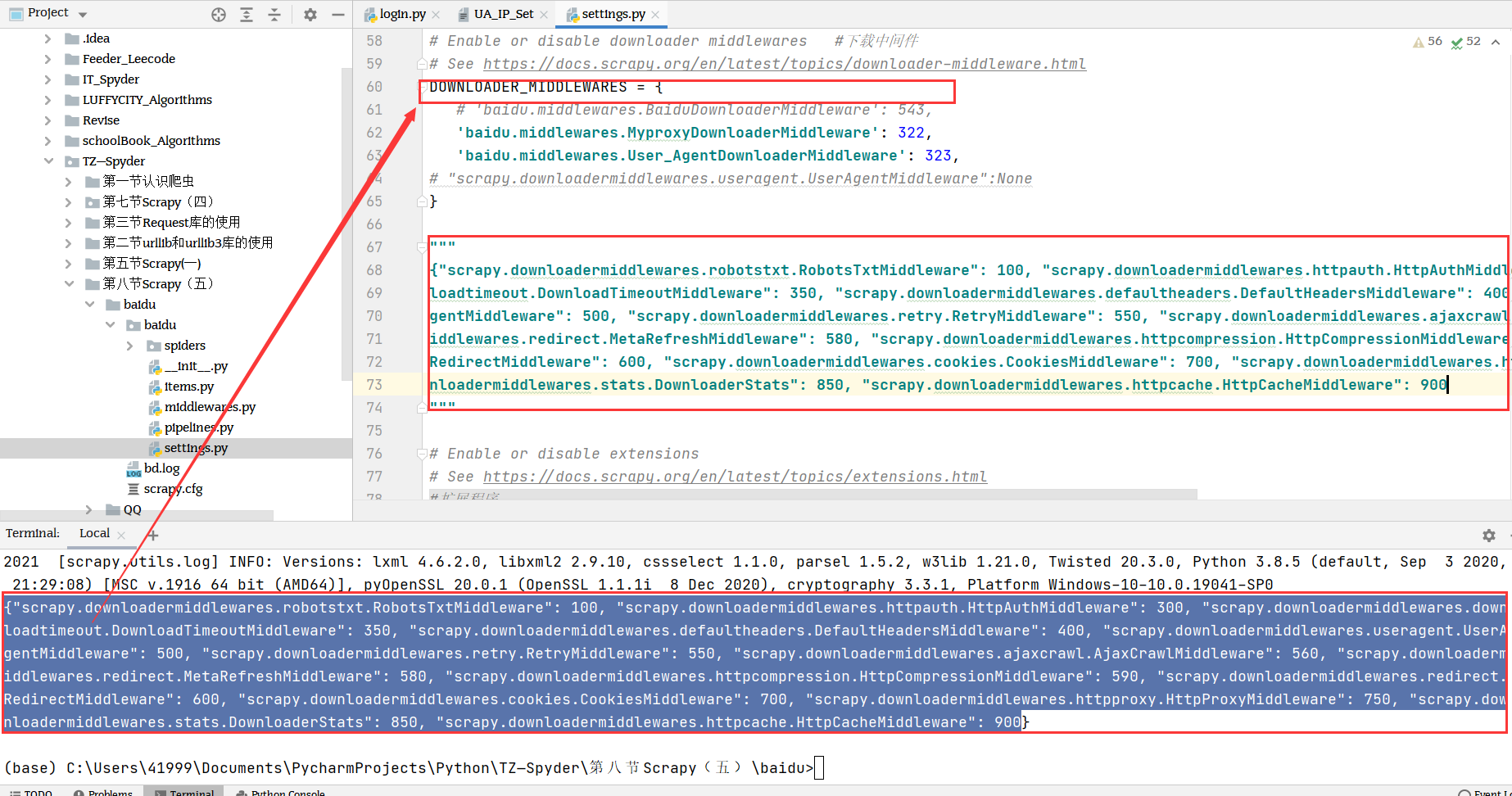
"scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware": 100,"scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware": 300,"scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware": 350,"scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware": 400,"scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": 500,"scrapy.downloadermiddlewares.retry.RetryMiddleware": 550,"scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware": 560,"scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware": 580,"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 590,"scrapy.downloadermiddlewares.redirect.RedirectMiddleware": 600,"scrapy.downloadermiddlewares.cookies.CookiesMiddleware": 700,"scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": 750,"scrapy.downloadermiddlewares.stats.DownloaderStats": 850,"scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware": 900
1 进入项目 命令查看下载中间件信息

2 在settings文件中找到下载中间件信息并且存放信息
信息解读
1 数字越小越靠近引擎,越早执行该信息
2 middlewares中下载中间件的定义

3 对中间件的功能—-简单解读
""""scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware": 100, # 机器人协议中间件"scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware": 300, #http身份验证中间件"scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware": 350, # 下载超时中间件"scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware": 400, # 默认请求头"scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": 500, # 用户代理中间件"scrapy.downloadermiddlewares.retry.RetryMiddleware": 550, # 重新尝试中间件"scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware": 560, # ajax抓取中间件"scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware": 580, # 始终使用字符串作为原因"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 590, # 允许网站数据压缩发送"scrapy.downloadermiddlewares.redirect.RedirectMiddleware": 600, # 重定向"scrapy.downloadermiddlewares.cookies.CookiesMiddleware": 700, # cookie 中间件"scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": 750, # 代理中间件"scrapy.downloadermiddlewares.stats.DownloaderStats": 850, # 通过此中间件存储通过他的所有请求 响应"scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware": 900 # 缓存中间件"""
4 常用内置中间件
CookieMiddleware 支持cookie,通过设置COOKIES_ENABLED 来开启和关闭HttpProxyMiddleware HTTP代理,通过设置request.meta['proxy']的值来设置UserAgentMiddleware 与用户代理中间件。
5 四个重要的下载中间件解读
第一个 process_request
def process_request(self, request, spider):# Called for each request that goes through the downloader# 功能: 处理请求 参数: request & spider对象 返回值# middleware.# Must either: 以下必选其一# - return None: continue processing this request 返回None request被继续交给下一个中间件进行处理# - or return a Response object 返回一个response对象,不会交给下一个process_request,而是直接交给下载器,最后传递给引擎# - or return a Request object 返回一个request对象 直接交给引擎处理# - or raise IgnoreRequest: process_exception() methods of # 抛出异常,由process_exception()处理# installed downloader middleware will be calledreturn None

第二个 process_response
def process_response(self, request, response, spider):# Called with the response returned from the downloader.# 功能 处理响应 类型 request, response, spider# Must either;# - return a Response object # 继续交给下一个中间件处理# - return a Request object # 返回一个request对象 直接交给引擎处理# - or raise IgnoreRequest # 抛出异常 使用process_exception处理

第三个 process_exception
def process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# 处理异常# Must either:# - return None: continue processing this exception # 继续调用其他中间件的process_exception# - return a Response object: stops process_exception() chain # 停止调用其他中间件的process_exception# - return a Request object: stops process_exception() chain # 直接交给引擎处理pass


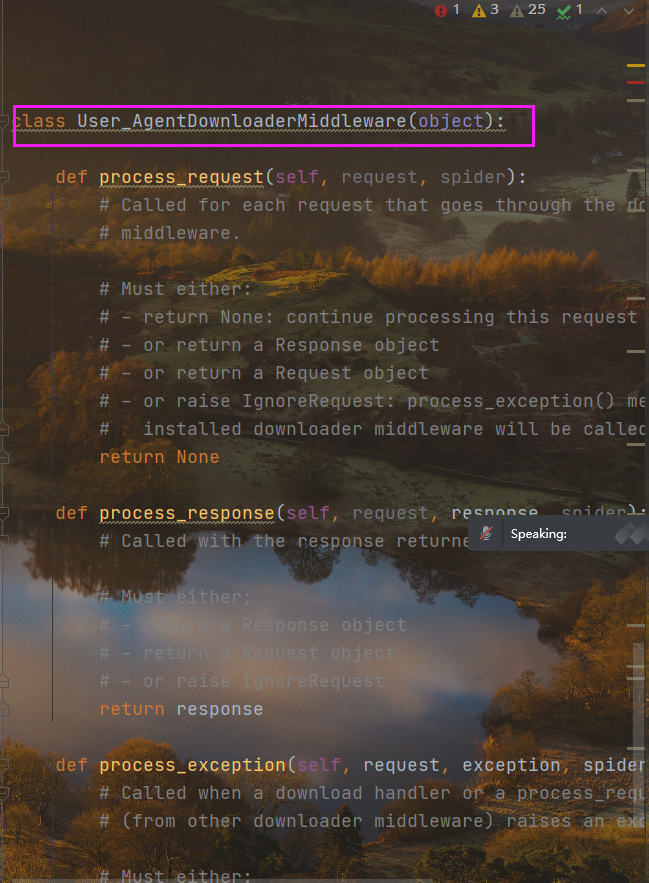
自定义User-Agent中间件
多种不同的用户代理用来模拟浏览器登录

在middlewares中间件中自定义代理中间件
class User_AgentDownloaderMiddleware(object):def process_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be calledreturn Nonedef process_response(self, request, response, spider):# Called with the response returned from the downloader.# Must either;# - return a Response object# - return a Request object# - or raise IgnoreRequestreturn responsedef process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpass
将浏览器代理信息复制到settings文件中,以包的形式导入进middlewares
尤其应该注意路径名的书写,同级目录下导入文件,直接写文件名即可
与以上操作相同
将IP代理信息复制到settings,在middlewares中重新制作一个自定义代理下载中间件,同时从settings中导入到此文件
细节:注意IP地址
def process_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be calledreturn Nonedef process_response(self, request, response, spider):# Called with the response returned from the downloader.# Must either;# - return a Response object# - return a Request object# - or raise IgnoreRequestreturn responsedef process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpass

开启下载中间件

关闭特定下载中间件
DOWNLOADER_MIDDLEWARES = {'github.middlewares.GithubDownloaderMiddleware': 543,'scrapy.downloadermiddlewares.retry.RetryMiddleware' : None}

设定指定下载中间件的优先级
DOWNLOADER_MIDDLEWARES = {'github.middlewares.GithubDownloaderMiddleware': 543,'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware' : 1024,'scrapy.downloadermiddlewares.retry.RetryMiddleware' : None}

常用Scrapy.settings
第一部分
BOT_NAME = 'baidu' # scrapy 项目名称SPIDER_MODULES = ['baidu.spiders'] # 爬虫模块NEWSPIDER_MODULE = 'baidu.spiders' # 使用genspider 命令创建的爬虫模板

第二部分
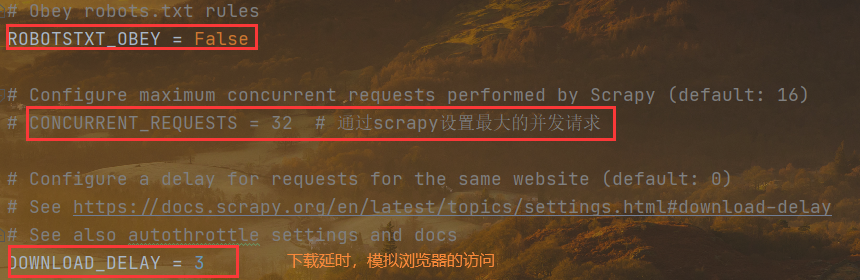
# Obey robots.txt rulesROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)CONCURRENT_REQUESTS = 32 # 通过scrapy设置最大的并发请求# Configure a delay for requests for the same website (default: 0)# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docsDOWNLOAD_DELAY = 3
第三部分
# Obey robots.txt rulesROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)CONCURRENT_REQUESTS = 32 # 通过scrapy设置最大的并发请求# Configure a delay for requests for the same website (default: 0)# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docsDOWNLOAD_DELAY = 3# The download delay setting will honor only one of:# CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 单个域名运行的并发请求CONCURRENT_REQUESTS_PER_IP = 16 # 单个IP允许运行的并发请求# Disable cookies (enabled by default)COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)# TELNETCONSOLE_ENABLED = False # 设置控制台监控
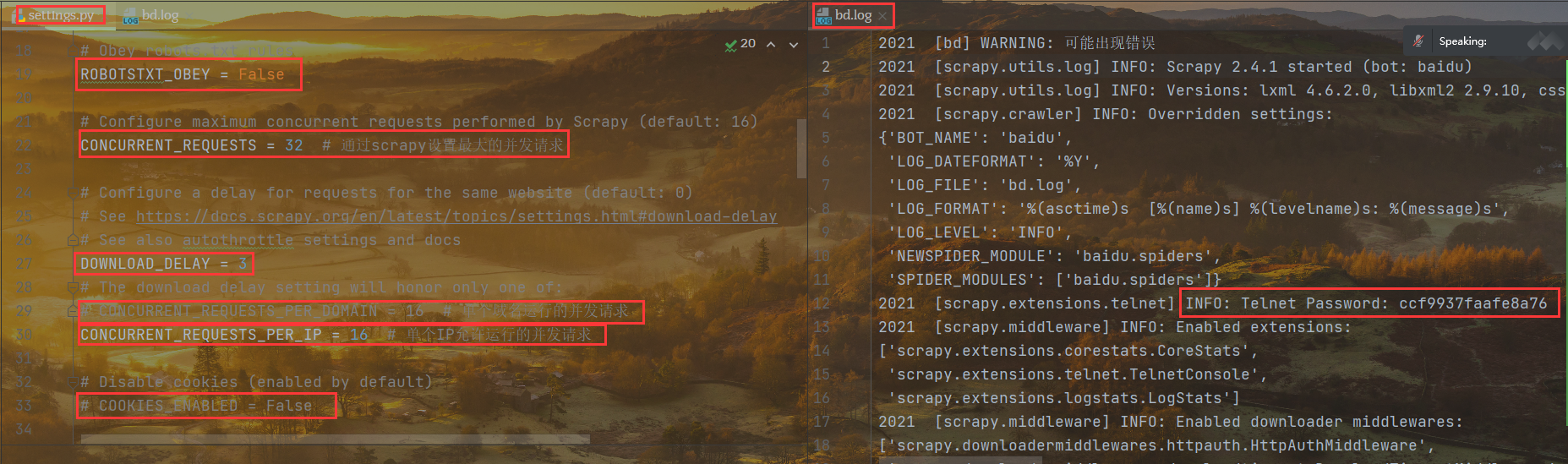

第四部分
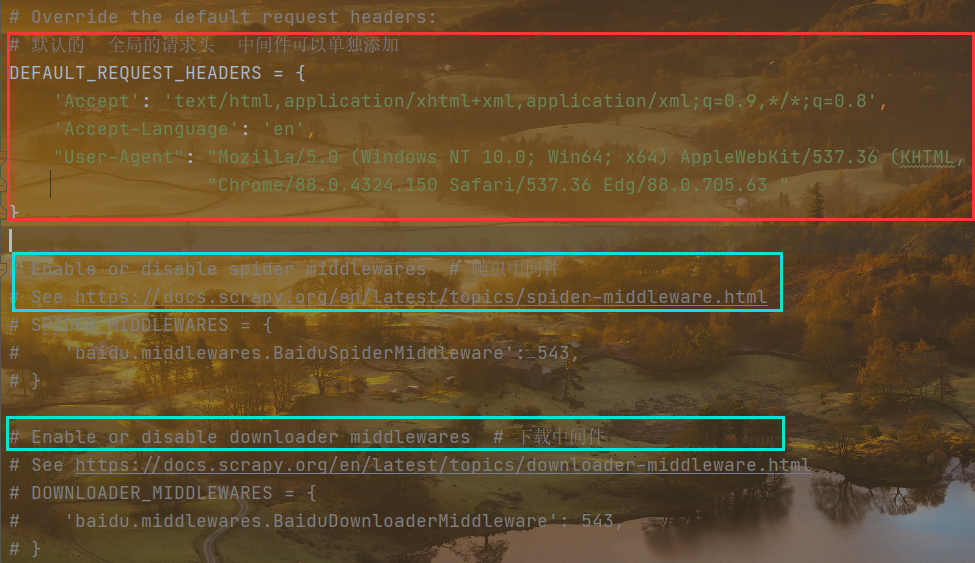
第五部分
# Enable or disable extensions# See https://docs.scrapy.org/en/latest/topics/extensions.html# 选择开启或者关闭监听控制台EXTENSIONS = {'scrapy.extensions.telnet.TelnetConsole': None,}# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = {'baidu.pipelines.BaiduPipeline': 300, # 数字代表优先级 数字越大优先级越高}# 启用或者配置扩展# Enable and configure the AutoThrottle extension (disabled by default)# See https://docs.scrapy.org/en/latest/topics/autothrottle.html# AUTOTHROTTLE_ENABLED = True# The initial download delay # 初始下载延迟AUTOTHROTTLE_START_DELAY = 5# The maximum download delay to be set in case of high latencies # 最大下载延迟AUTOTHROTTLE_MAX_DELAY = 60# The average number of requests Scrapy should be sending in parallel to# each remote server# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0# 启用显示每一个响应的调节信息# Enable showing throttling stats for every response received:AUTOTHROTTLE_DEBUG = False

项目总结
这一个项目没有具体的构造一个获取数据的过程,主要是学习三个主要的下载中间件,之后用户配置下载中间件,最后讲解一些主要的settings设置。
这一节是对前面项目的补充。之前对settings的了解主要停留在设置延时,关闭对爬虫协议的遵循,然后是设置请求头,最后是开启日志。而在这一个章节,我们不仅学习了自定义下载中间件,设置爬虫的IP代理和用户池,还监视了一个叫做控制台监听的功能,虽然不知道具体做什么,但开了一个头。

若有收获,就点个赞吧
0 人点赞
