
次级页面抓取及数据拼接
流程复习: headers中的User-Agent,robot.text以及管道都需要在settings中开启
功能介绍: Schedule功能相当于SPOOLing假脱机技术,用作请求网页的排队
Response负责网页解析
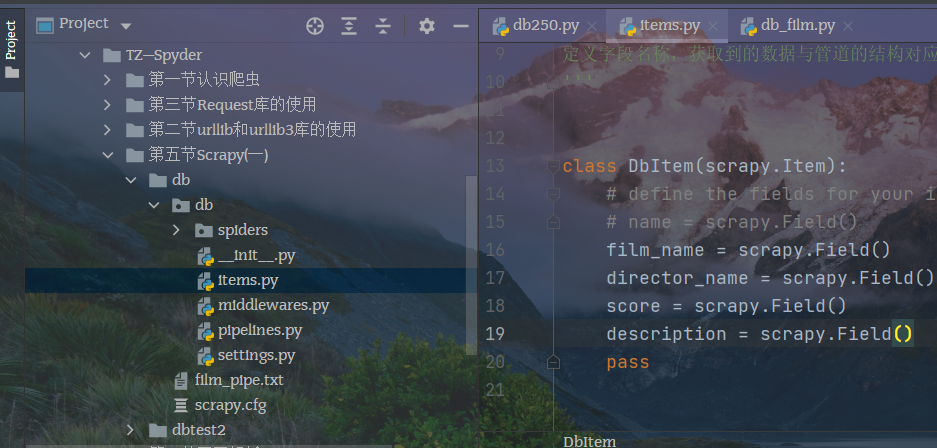
结构化存储需要现在item pipelines中定义结构,然后response将数据交给引擎,由引擎将数据转发给item pipelines
实战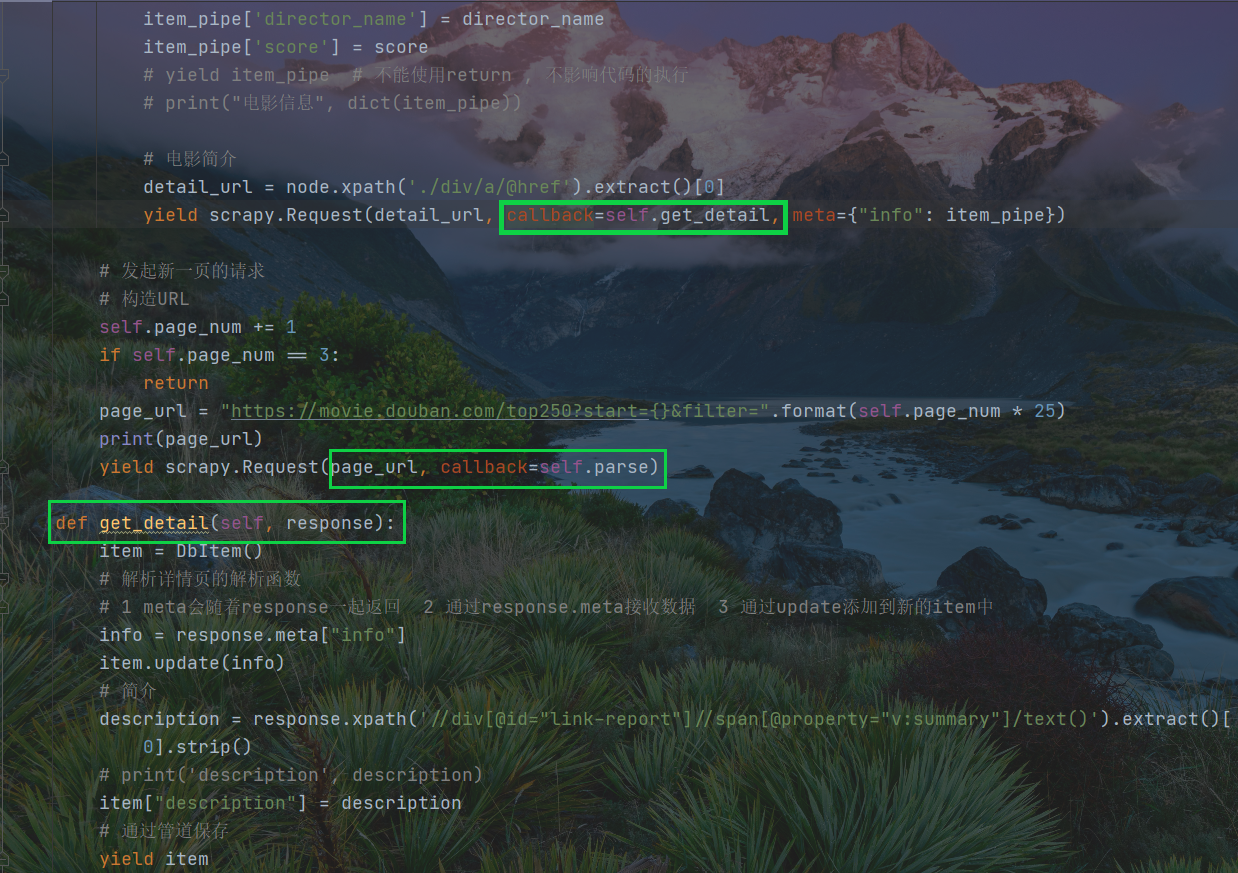
次级页面仍然使用Request请求爬取,需要单独创建解析函数,items仅需要新增一个结构。
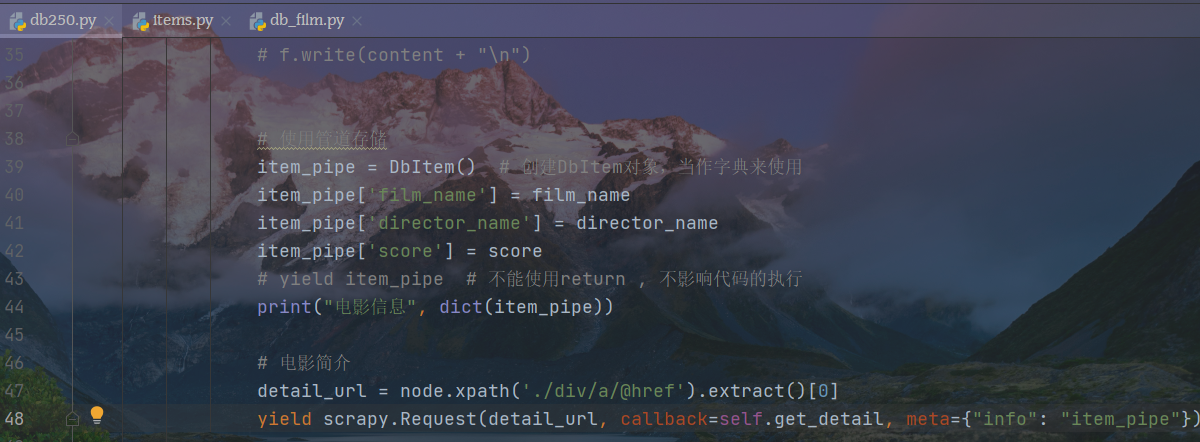
db 250在创建时已经生成了一个网页解析函数,如下图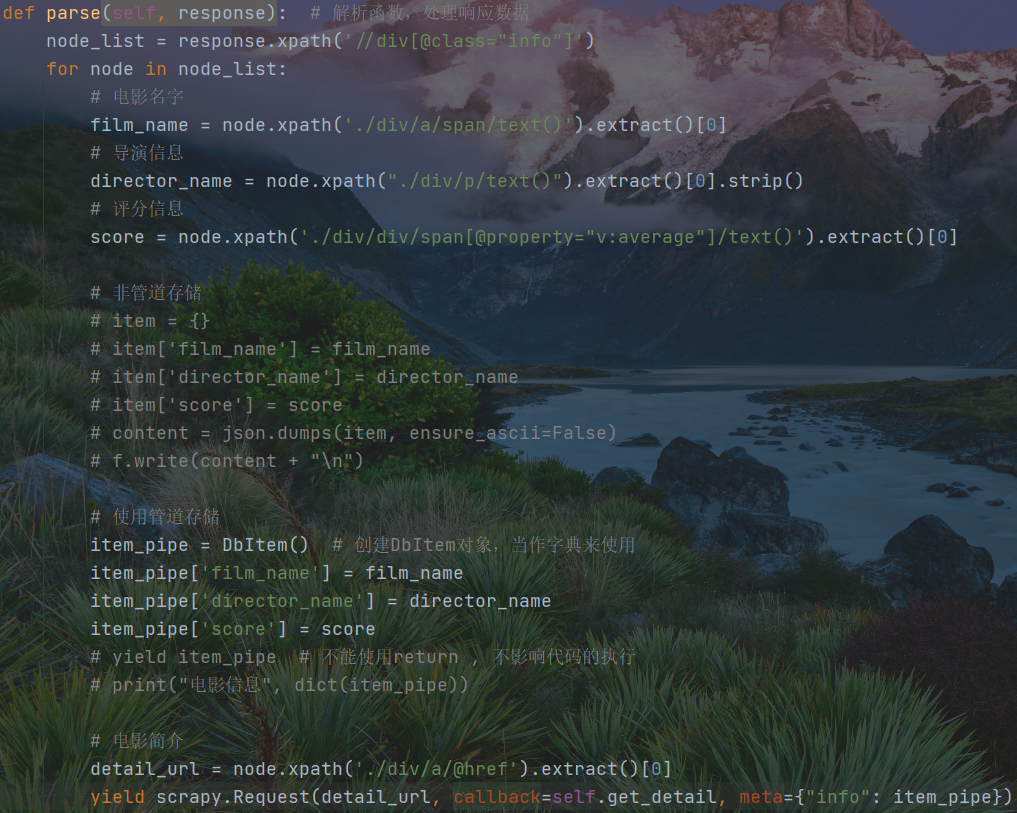
由下面这部分语句控制数据的爬取,yield语句执行爬取,由回调函数将数据传递给整个项目的parse函数,负责对网页的解析。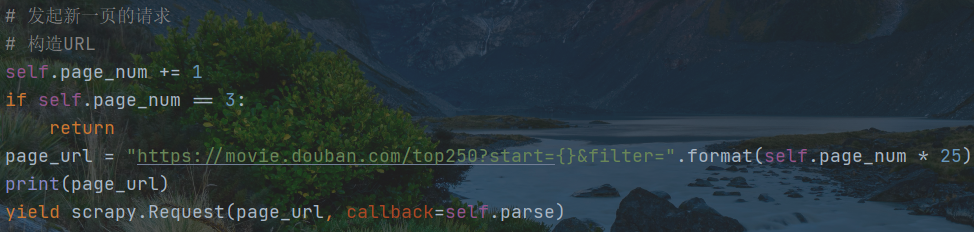
解析函数拿到数据逐步解析,主信息不必关心,主要简介页面数据的解析。这里仍然使用xpath解析子页面的网页URL,在执行爬取语句中,通过回调将特定URL传递给新建的解析函数,这里通过meta函数,将info信息传递给items。
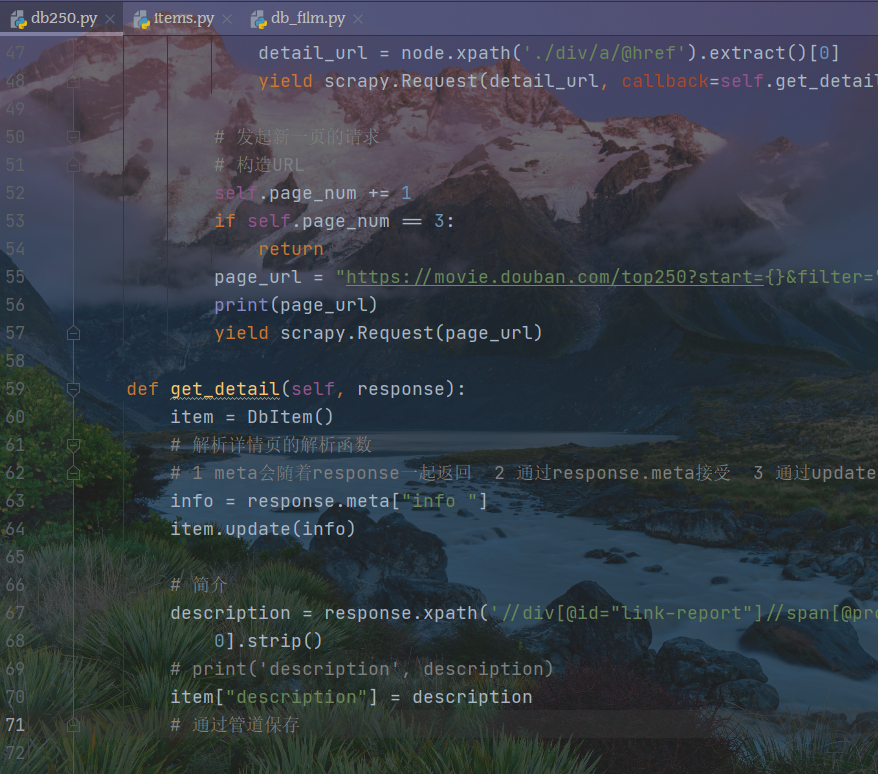
主解析函数已经对子页面的数据进行网页获取,将子网页响应报文传递给子解析页面,在主解析函数的执行访问语句中,已经绑定了info信息;
子网页响应信息使用meta方法,将执行后的数据赋值给变量info ,将info信息使用字典更新的方式传递到items中存储起来。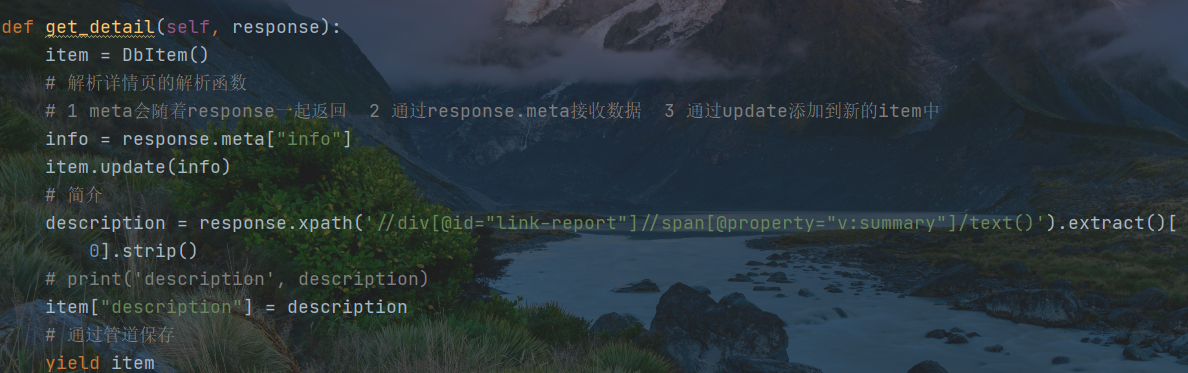
由xpath方法对网页解析,解析后的数据被赋值给变量description,然后将数据传递给items管道
目标数据分析
子网页数据分析,目前来看,第三项数据最为完整,先从网页简介中剪切关键字,打开网页源代码,通过搜索获取网页片段(Ctrl + F)
https://movie.douban.com/subject/1292052/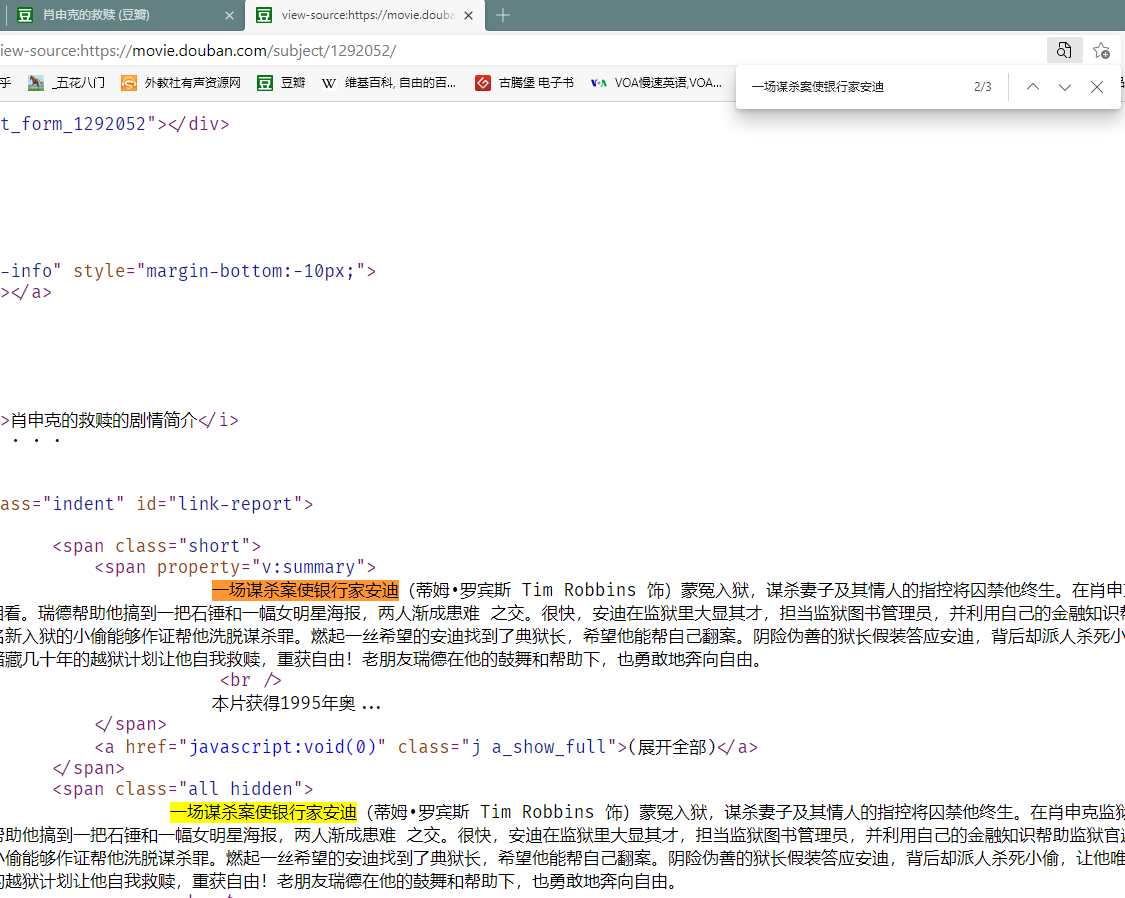
从主页面(豆瓣top250)肖申克主界面源代码中,获取子网页的网址
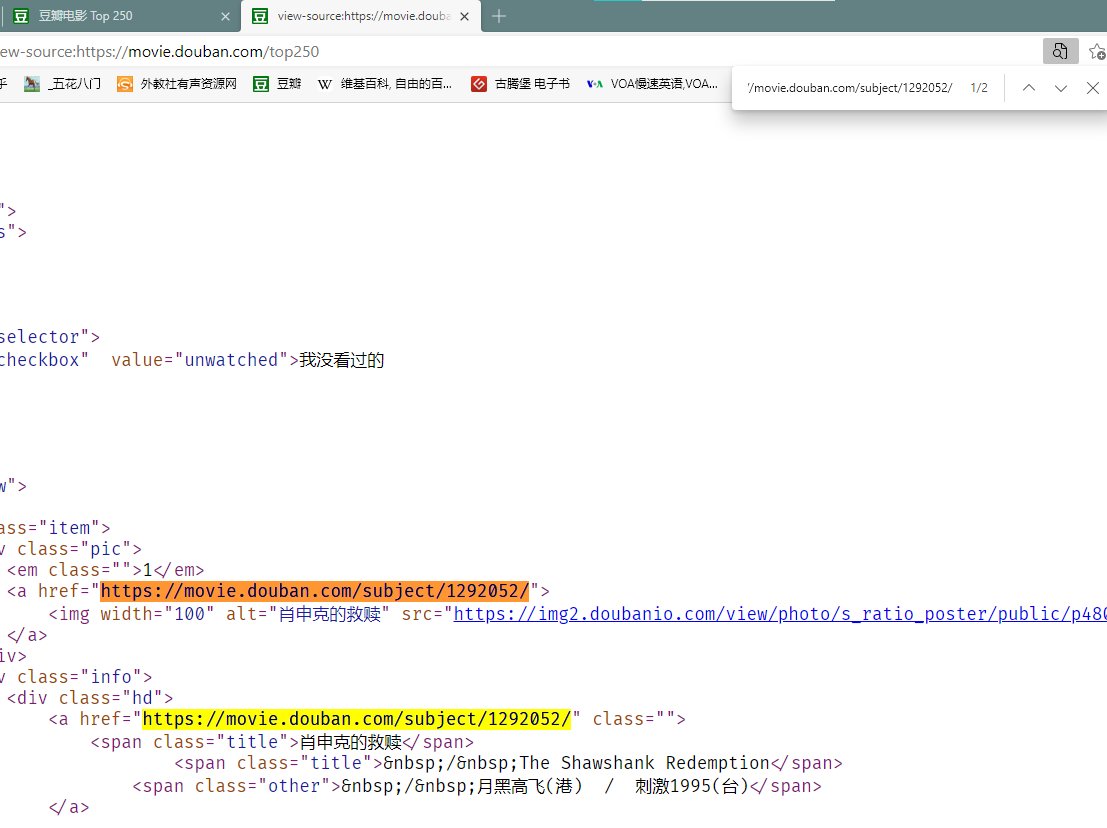

爬取流程分析
从主页面douban top250中获得子页面的URL,通过此URL访问电影简介,获取电影简介中的数据
代码调试
首先在终端进入项目外文件夹
cd C:\Users\41999\Documents\PycharmProjects\Python\TZ—Spyder\第五节Scrapy(一)\db
在终端使用命令,获取主页面douban top 250的响应报文
scrapy shell https://movie.douban.com/top250
使用XPath解析网页数据,并且以子数据项肖申克为例
node_list = response.xpath('//div[@class="info"]')node_xsk = node_list[0]node_xsk.xpath('./div/a/span/text()').extract()[0]
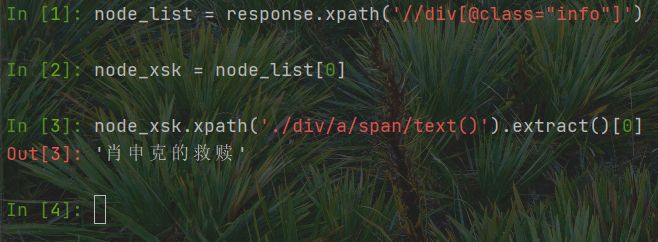
观察网页路径
获取子页面网址
解析数据和使用方法获取纯净的URL
node_xsk.xpath('./div/a/@href')node_xsk.xpath('./div/a/@href').extract_first()node_xsk.xpath('./div/a/@href').extract()[0] # 两种方法均可

在遍历中添加对详情页URL的获取
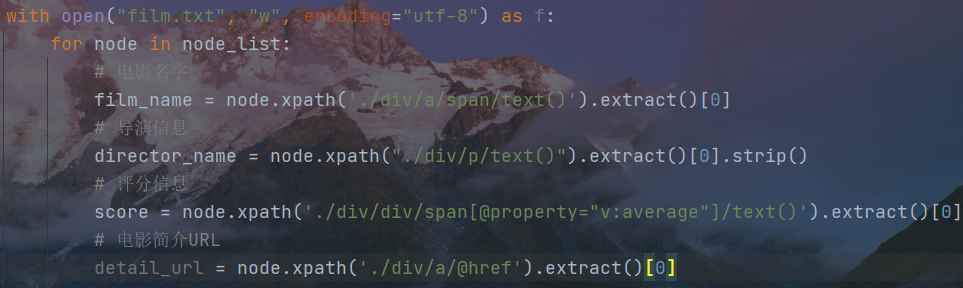
构建网页请求以及网页解析函数(这里需要重新创建一个网页解析函数,对子网页的网页解析不能再使用原有解析函数)
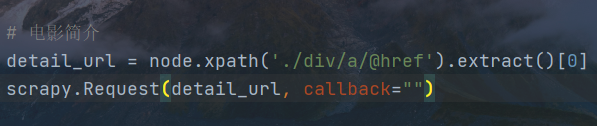
创建子页面解析函数,注意缩进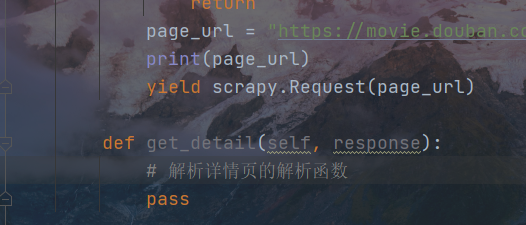
确定详情页数据解析对象的路径

link_report有且仅有一个
退出当前调试命令行,重新测试子页面响应数据
fetch('https://movie.douban.com/subject/1292052/')exit()scrapy shell https://movie.douban.com/subject/1292052/

详情页解析测试,获取电影详情介绍
response.xpath('//div[@id="link-report"]')response.xpath('//div[@id="link-report"]/span/span[@property="v:summary"]')response.xpath('//div[@id="link-report"]/span/span[@property="v:summary"]').extract()
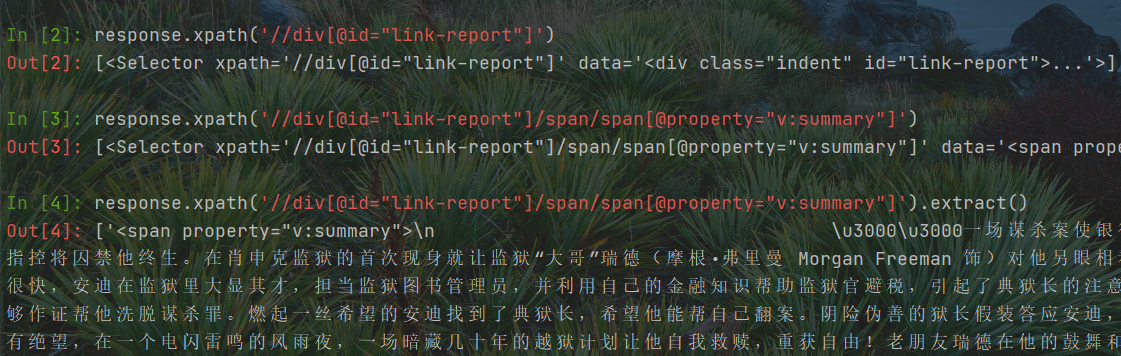
详情页数据解析的排坑
肖申克详情页面的路径有两个span, 但是霸王别姬详情页路径有且仅有一个span;
解决措施: 去掉一个span, 之前的div和span后的指定已经确定了路径下唯一的属性


数据对象的提纯

自行研究出来的问题
霸王别姬的详情页有换行,如果对extract()指定,则获取的数据一定不完整
补充: strip方法隶属于str数据类型,具体描述如下
测试框架的异步性(管道存储和爬取后数据的存放的执行顺序是乱序的)
对管道增加字段名,便于使用管道的方式保存数据(由于爬虫异步,可以将数据和之前爬取的数据放在一起)
修改db259下前面数据的管道存储
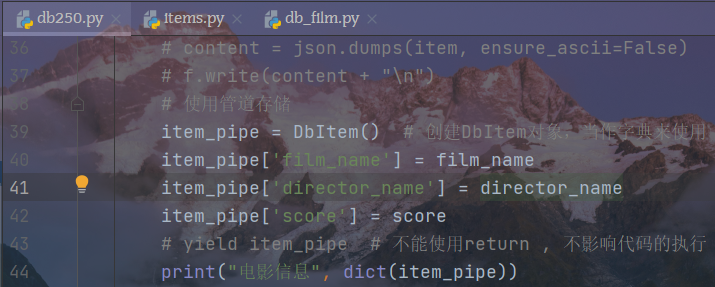
修改数据解析
对错误的处理
1, 将中文名字写进了dict
2, 没有将response的返回数据传递给解析函数
数据无需,电影信息和详情页不对应
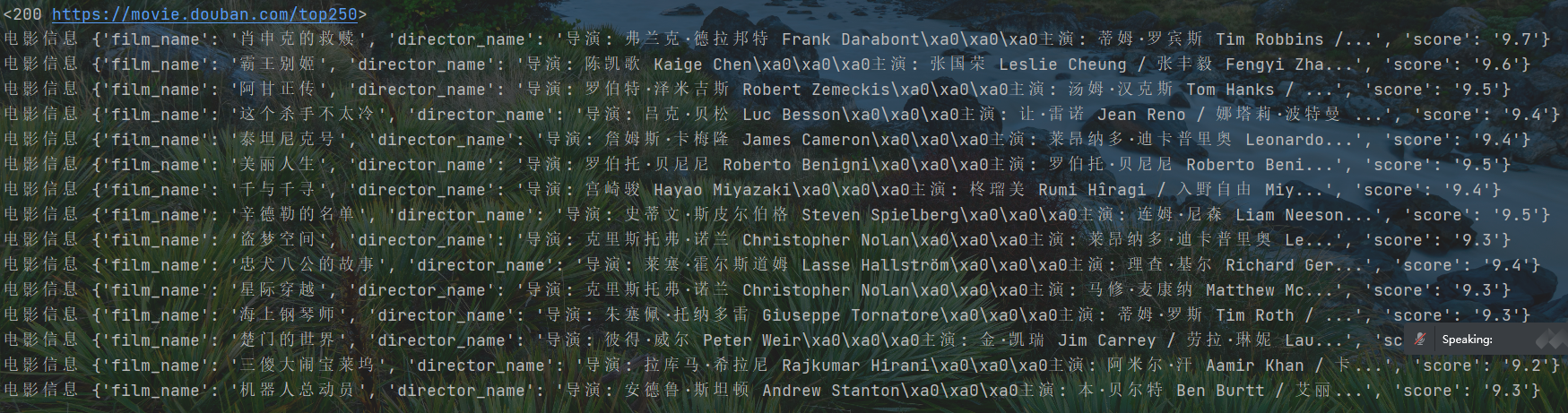
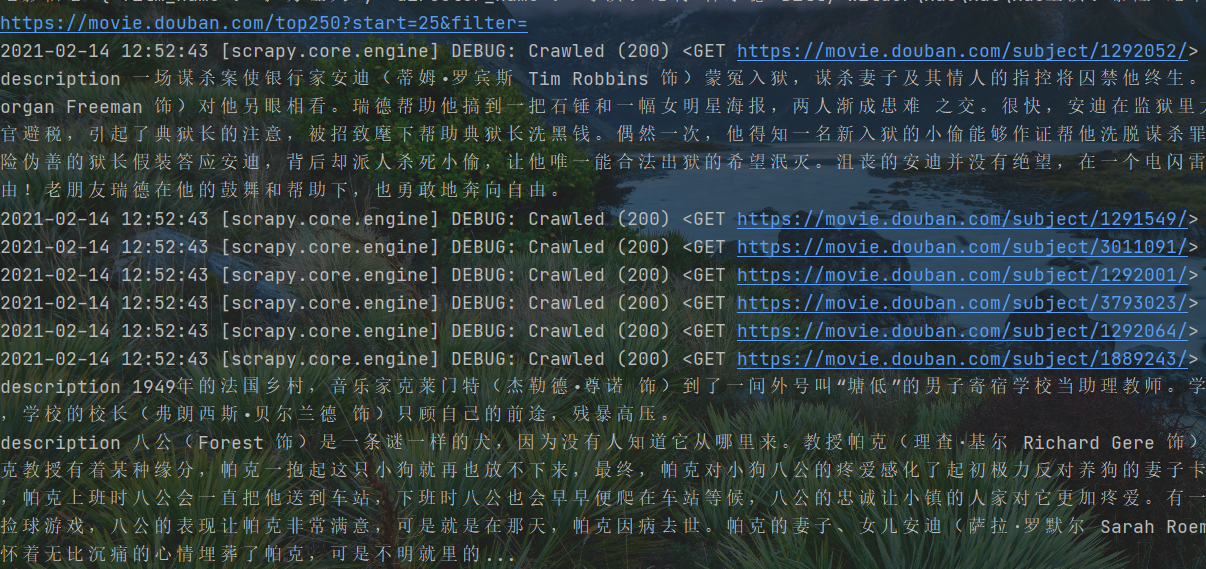
绑定数据,便于表示意义
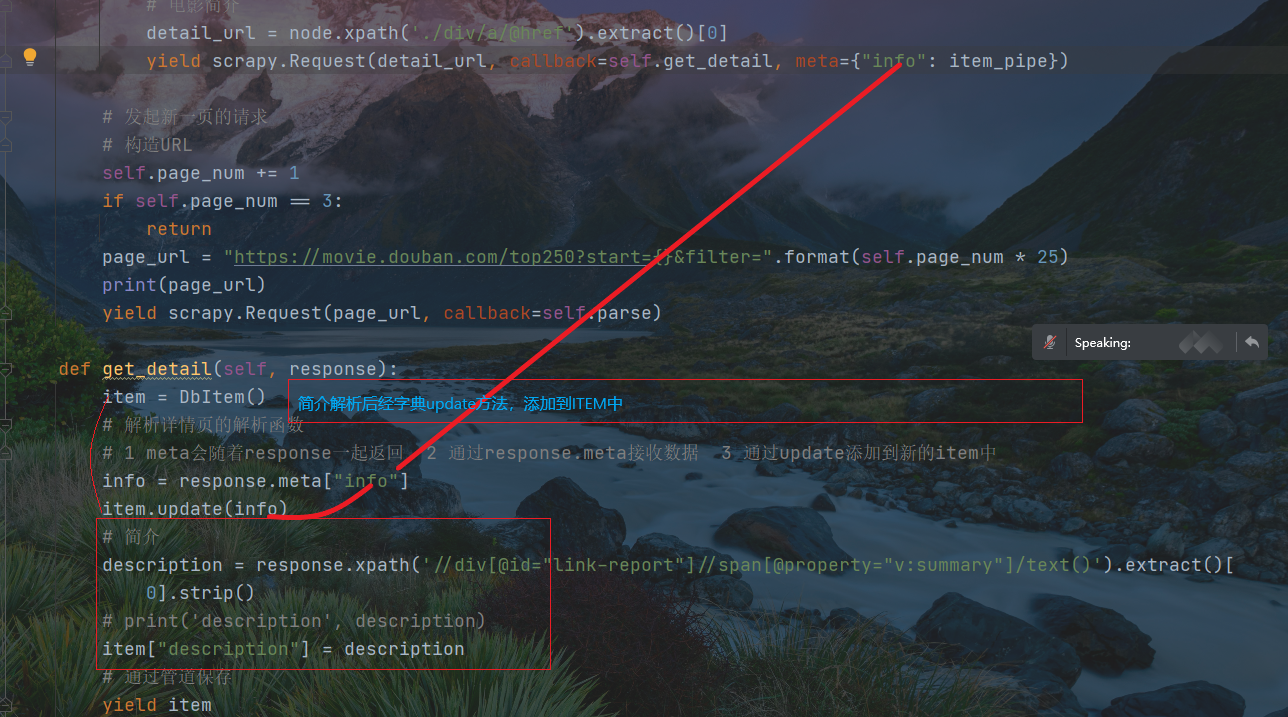
在简介解析函数中增加数据结构,存储异步数据(简介)
备注:
代码一遍又一遍检查,至少六遍,先是对着视频检查,然后去群里下载爬虫文件,最后无计可施,居然数据又冒出来了,我不知道是不是因为IP被封锁,拿不到数据(如果封锁IP是不是可以用浏览器试一试),过了五六个小时时间,下午一点四十结束,到下午六点,我才拿到数据。
看到数据的那一刻激动万分,但是找不到出问题的原因特别痛苦。
刚才准备回去保存控制台的数据,但是已经被覆盖了,非常的遗憾,所以待会儿项目学习完成之后,去学习OS模块,试一试把终端的运行数据持久化保存到文档当中,至少还有寻求没有数据的原因的机会,这俩天老师没上班,等上班了还可以问一下,还好今天直播有录屏,到时候回放一下。
项目过程总结:
1 目标数据 电影信息(名字,导演及主演,评分)+ 电影简介, 简介在次级页面的网页源码中
2 请求流程 访问一级页面 提取电影次级页面URL 访问次级页面URL,从次级数据中提取电影简介
3 存储问题,数据获取和保存的次序是混乱的 需要使用meta传参,将同一部电影的数据绑定在一起
项目完整代码
import jsonimport scrapyfrom ..items import DbItem # 是一个安全的字典class Db250Spider(scrapy.Spider): # 继承基础类name = 'db250' # 爬虫文件名字,必须存在且唯一# allowed_domains = ['https://moive.douban.com'] # 允许的域名 相当于防火墙, 可以不存在,可以访问任何网站start_urls = ['https://movie.douban.com/top250'] # 初始URL, 必须存在page_num = 0def parse(self, response): # 解析函数,处理响应数据node_list = response.xpath('//div[@class="info"]')for node in node_list:# 电影名字film_name = node.xpath('./div/a/span/text()').extract()[0]# 导演信息director_name = node.xpath("./div/p/text()").extract()[0].strip()# 评分信息score = node.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]# 非管道存储# item = {}# item['film_name'] = film_name# item['director_name'] = director_name# item['score'] = score# content = json.dumps(item, ensure_ascii=False)# f.write(content + "\n")# 使用管道存储item_pipe = DbItem() # 创建DbItem对象,当作字典来使用item_pipe['film_name'] = film_nameitem_pipe['director_name'] = director_nameitem_pipe['score'] = score# yield item_pipe # 不能使用return , 不影响代码的执行# print("电影信息", dict(item_pipe))# 电影简介detail_url = node.xpath('./div/a/@href').extract()[0]yield scrapy.Request(detail_url, callback=self.get_detail, meta={"info": item_pipe})# 发起新一页的请求# 构造URLself.page_num += 1if self.page_num == 3:returnpage_url = "https://movie.douban.com/top250?start={}&filter=".format(self.page_num * 25)print(page_url)yield scrapy.Request(page_url, callback=self.parse)def get_detail(self, response):item = DbItem()# 解析详情页的解析函数# 1 meta会随着response一起返回 2 通过response.meta接收数据 3 通过update添加到新的item中info = response.meta["info"]item.update(info)# 简介description = response.xpath('//div[@id="link-report"]//span[@property="v:summary"]/text()').extract()[0].strip()# print('description', description)item["description"] = description# 通过管道保存yield item'''目标数据: 从次级页面网页源代码里获取电影简介数据;请求流程: 访问一级页面,提取次级页面的url, 从次级页面抓取电影简介数据存储的问题: 数据没有次序,需要使用meta传参,保证同一部电影的信息在一起(导演评分加简介)'''
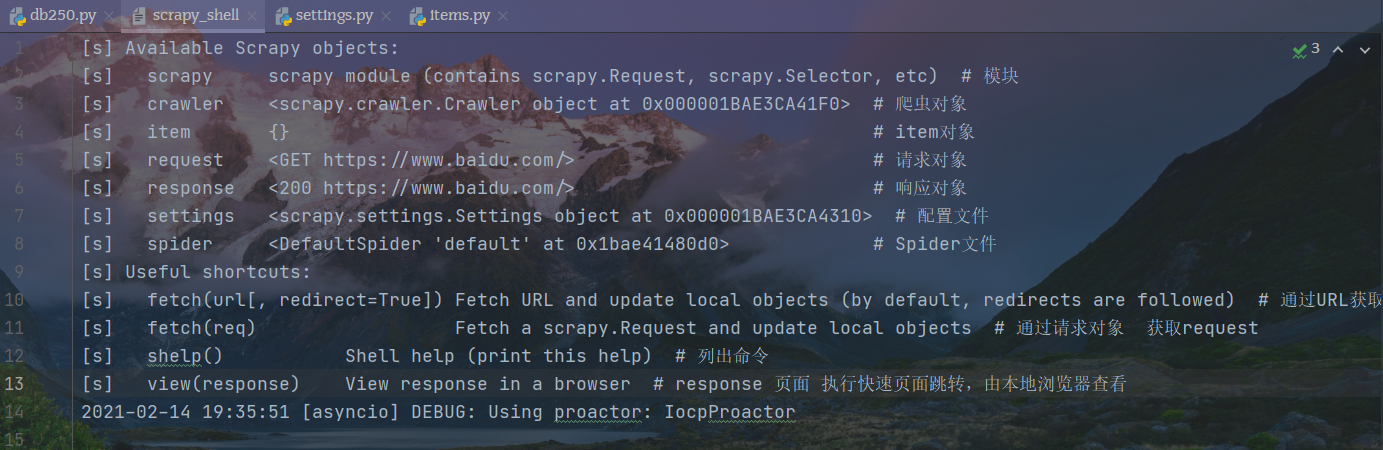
Scrapy shell
全部shell命令
[s] Available Scrapy objects:[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) # 模块[s] crawler <scrapy.crawler.Crawler object at 0x000001BAE3CA41F0> # 爬虫对象[s] item {} # item对象[s] request <GET https://www.baidu.com/> # 请求对象[s] response <200 https://www.baidu.com/> # 响应对象[s] settings <scrapy.settings.Settings object at 0x000001BAE3CA4310> # 配置文件[s] spider <DefaultSpider 'default' at 0x1bae41480d0> # Spider文件[s] Useful shortcuts:[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) # 通过URL获取response数据[s] fetch(req) Fetch a scrapy.Request and update local objects # 通过请求对象 获取request[s] shelp() Shell help (print this help) # 列出命令[s] view(response) View response in a browser # response 页面 执行快速页面跳转,由本地浏览器查看2021-02-14 19:35:51 [asyncio] DEBUG: Using proactor: IocpProactor
settings数据的读取
先使用如何命令对网页进行解析,然后开始shell命令测试
scrapy shell https://www.baidu.com/
命令如下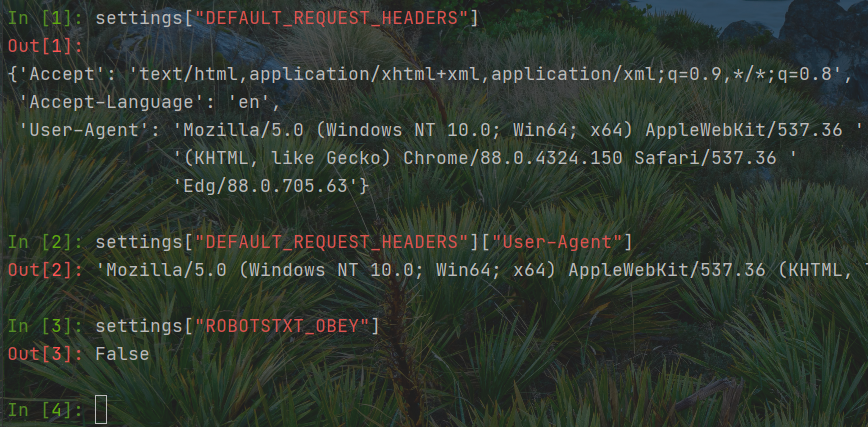
快速切换爬取对象
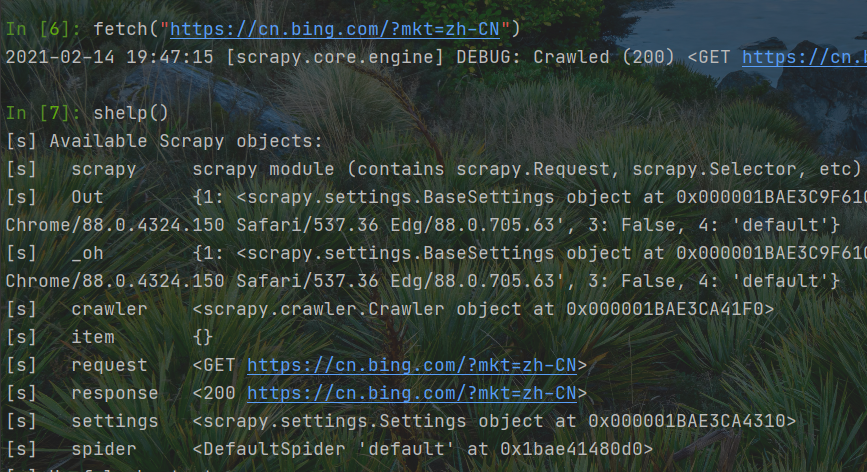
查看命令

快速查看response响应
view(response)
Scrapy 选择器
第一步构建文件
# -*- codeing = utf-8 -*-# @Time : 2/14/2021 8:04 PM# @Autor : Caesar# @File : scrapy_demo.py# @ Software : PyCharmfrom scrapy.selector import Selectorhtml_str = '''<div class="info"><div class="hd"><a href="https://movie.douban.com/subject/1292052/" class=""><span class="title">肖申克的救赎</span><span class="title"> / The Shawshank Redemption</span><span class="other"> / 月黑高飞(港) / 刺激1995(台)</span></a><span class="playable">[可播放]</span></div><div class="bd"><p class="">导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>1994 / 美国 / 犯罪 剧情</p><div class="star"><span class="rating5-t"></span><span class="rating_num" property="v:average">9.7</span><span property="v:best" content="10.0"></span><span>2273737人评价</span></div><p class="quote"><span class="inq">希望让人自由。</span></p>'''# 通过text参数构造对象selc_text = Selector(text=html_str)print(selc_text.extract())print("ok")
1 选择器会主动添加网页结构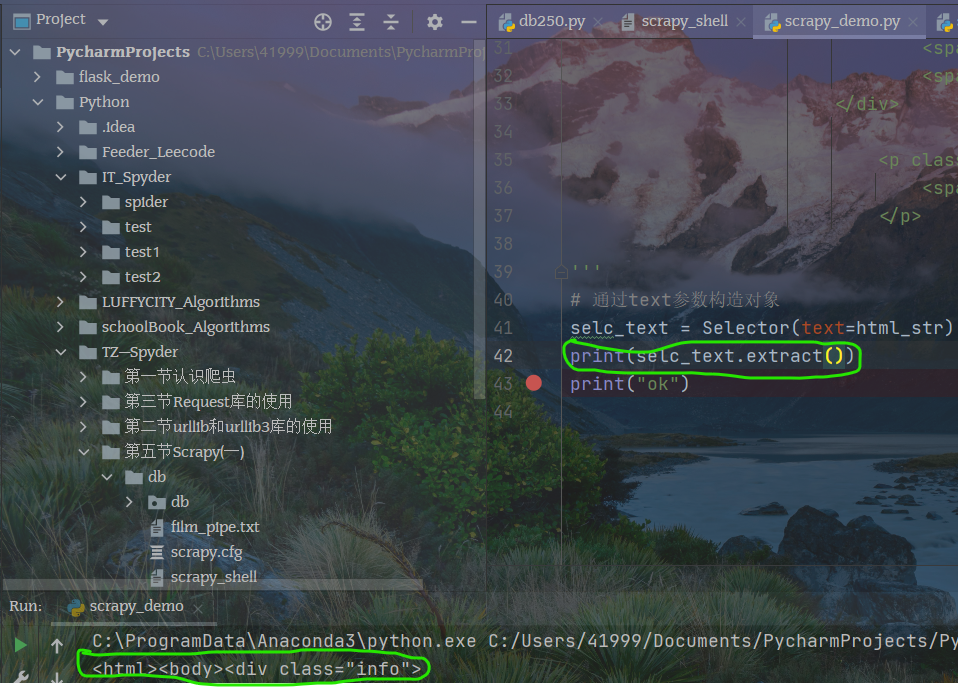
2 用xpath解析数据
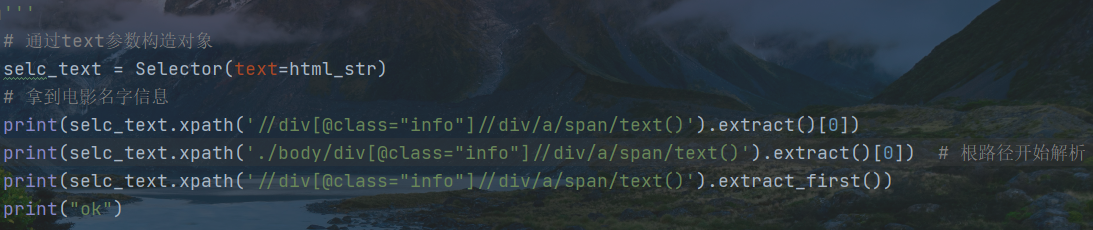
scrapy.Spider
这里的信息整理在思维导图中,由于会在后面用到,所以只是做一个概览


若有收获,就点个赞吧
0 人点赞
