应用场景
cookie过期时间很长,常用于一些不规范的网站
能够在cookies过期之前把所有的数据都拿到
配合其他程序使用,比如使用selenium把登录之后的cookie获取并且保存到本地,scrapy发送请求之前先读取本地cookie
网站实战
由于没有人人网账号,以及网站关闭注册功能,遂使用博客园作为实验对象
第一步:使用自己的账号密码登录博客园
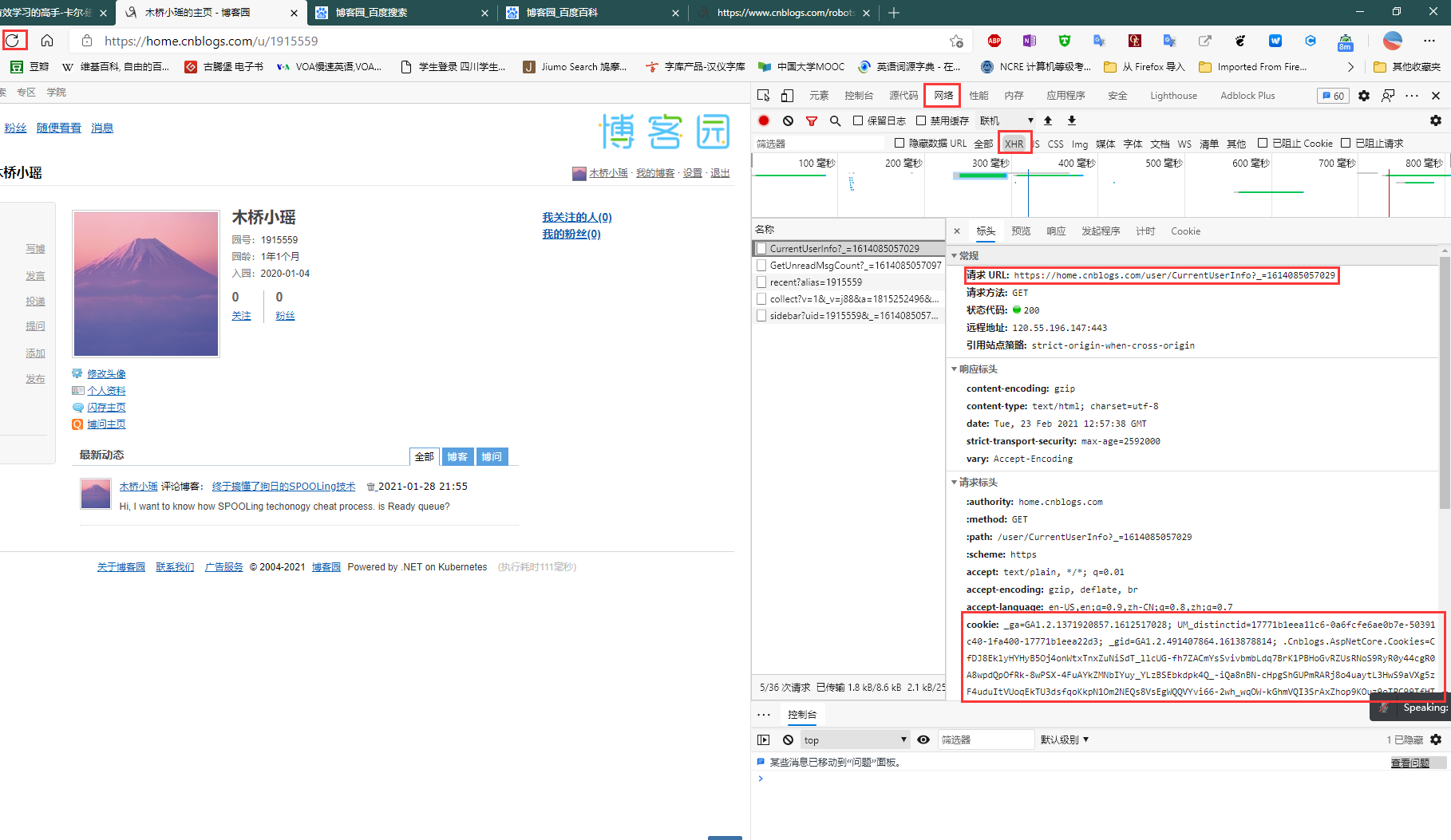
第二步:打开开发者工具,查看代码,尤其是获取cookie和响应网页地址
第三步:在设置中开启COOKIE_DEBUG并且关闭爬虫机器人协议
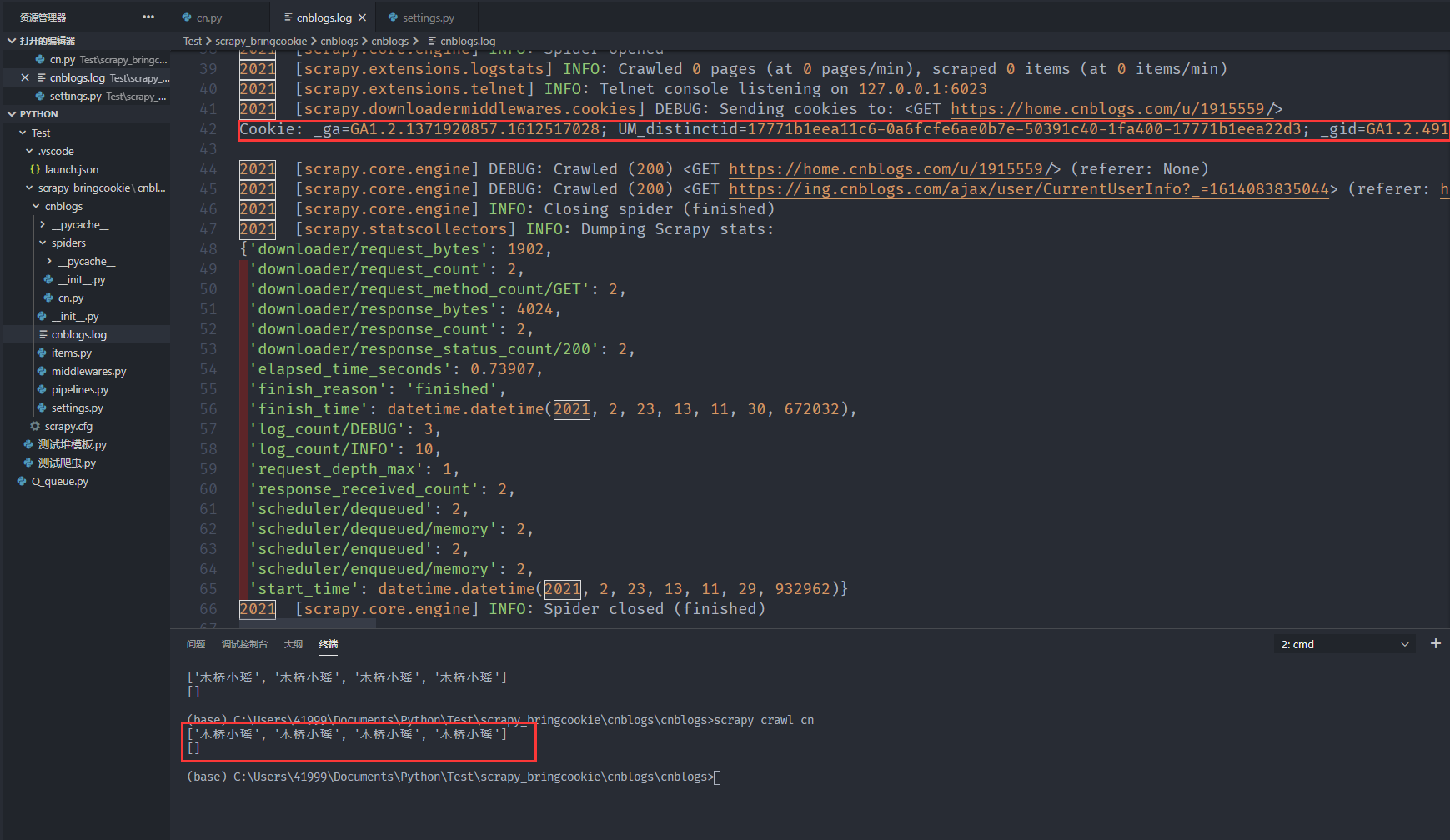

代码 cn主文件 以及 settings
import scrapy,reclass CnSpider(scrapy.Spider):name = 'cn'allowed_domains = ['cnblogs.com']start_urls = ['https://home.cnblogs.com/u/1915559/']# 自定义请求def start_requests(self):cookies = "_ga=GA1.2.1371920857.1612517028; UM_distinctid=17771b1eea11c6-0a6fcfe6ae0b7e-50391c40-1fa400-17771b1eea22d3; _gid=GA1.2.491407864.1613878814; .Cnblogs.AspNetCore.Cookies=CfDJ8EklyHYHyB5Oj4onWtxTnxZuNiSdT_llcUG-fh7ZACmYsSvivbmbLdq7BrK1PBHoGvRZUsRNoS9RyR0y44cgR0A8wpdQpOfRk-8wPSX-4FuAYkZMNbIYuy_YLzBSEbkdpk4Q_-iQa8nBN-cHpgShGUPmRARj8o4uaytL3HwS9aVXg5zF4uduItVUoqEkTU3dsfqoKkpN1Om2NEQs8VsEgWQQVYvi66-2wh_wqOW-kGhmVQI3SrAxZhop9KOuz9oTPC99TfHTLNcOa44GV4trAG7uwvs5VLdxJZssLtpWb2RTlq4IiVjg5tJyVLc523RfQmQhEZwy4-kkLbErHVCpz5xRnApd8A2ngSr7TkK4G2zSi30fH2R_euRrkubgseMurctQYCCcVSSk4i2e7-rd6UbgXEqC7ixxQAkhStK91f5r-DPVymdjggfiCPgaSfiKYtsUC5uH1c8ssNRTIVVEJcsoyV2sjO5ZE5uESuwOgRnWSL7ZtyFmNYuIbOvX6P68IMFkUDtEl7zxUledkriSYhOqke2MkQ0_tcdI_fndPtDFSLMEH7P2b0izmolyL2SriQ; .CNBlogsCookie=50AF3098CC48D4796BBA7747DED1407466251BA9586FAF7A72E68E073ED6DCEFD9D72BFD4BC4FE559970B441CD0A35B6BDEB555C1E172A7DDC0DBD3F026BD591220DBC257E27DF555E7523900750C97AB52D2727B6F28A1D3B24921B33B56F9F77854C02; .AspNetCore.Antiforgery.b8-pDmTq1XM=CfDJ8EklyHYHyB5Oj4onWtxTnxZDDbDJ2fgtNBtN06jdLFlxNlY48vW_t14mH8tWcMGBhGzPsgMML0WmWvrbF6hHFEiu_T_b4NekX18fo4Z-sKIBqgS3ZECQZl0EaaILyiSrxRTss7w05HaBBQriGeSclwY"cookies = {i.split("=")[0]:i.split("=")[1] for i in cookies.split("; ")}yield scrapy.Request(self.start_urls[0],callback = self.parse,cookies = cookies)def parse(self, response):print(re.findall("木桥小瑶", response.body.decode()))yield scrapy.Request("https://ing.cnblogs.com/ajax/user/CurrentUserInfo?_=1614083835044",callback = self.parse_detal)def parse_detal(self, response):print(re.findall("木桥小瑶", response.body.decode()))
BOT_NAME = 'cnblogs'SPIDER_MODULES = ['cnblogs.spiders']NEWSPIDER_MODULE = 'cnblogs.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent#USER_AGENT = 'cnblogs (+http://www.yourdomain.com)'# Obey robots.txt rulesROBOTSTXT_OBEY = FalseDOWNLOAD_DELAY = 3#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)#TELNETCONSOLE_ENABLED = FalseCOOKIES_DEBUG = True# Override the default request headers:DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74'}LOG_FILE = 'cnblogs.log'LOG_ENABLED = TrueLOG_FORMAT = '%(asctime)s [%(name)s] %(levelname)s: %(message)s'LOG_DATEFORMAT = '%Y'# 日志默认编码格式LOG_ENCODING = 'utf-8'# LOG_LEVEL 日志等级,默认debugLOG_LEVEL = 'DEBUG'# 调试信息的六个等级# DEBUG < INFO < WARNING < ERROR < CRITICAL
项目总结:
很难的地方在于如何快速提取cookie,解决这一点需要非常熟悉语句表达式
另外一点就是爬取到网页,我只是成功了一半,因为个人资料页的网页没有拿到数据
刚才去看了爬虫机器人协议,完全没有爬取限制,可以任意爬取
cookies的设置就是为了复用,会自动在请求第二个页面的时候发送给这个页面
即使使用cookie访问网页,更加容易绕过限制,但一旦被抓住,那就是定点打击
系统还会记录cookie访问次数

若有收获,就点个赞吧
0 人点赞
