分布式概念和作用
scrapy_redist
软件安装:
3.2.100
https://github.com/MicrosoftArchive/redis/releases
Redis Desktop Manager(百度云盘)
https://www.jianshu.com/p/6895384d2b9e
Redis包下载地址:
https://github.com/microsoftarchive/redis/releases
教程:
https://www.cnblogs.com/ttlx/p/11611086.html
注意事项:添加到防火墙 添加到环境变量 单独设置内存推荐1024MB 端口号为6379.使用命令看一下是否被占用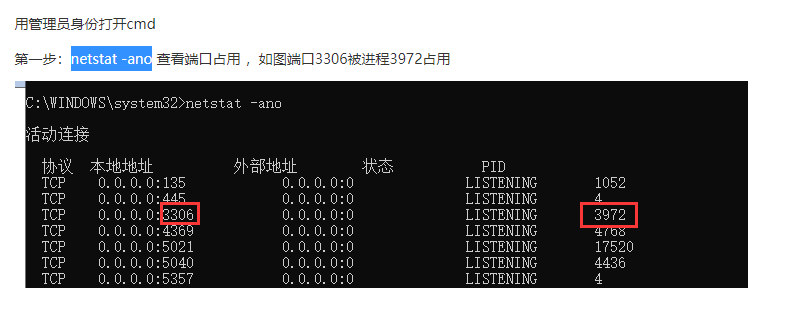
框架安装:
推荐conda安装
pip install scrapy-redis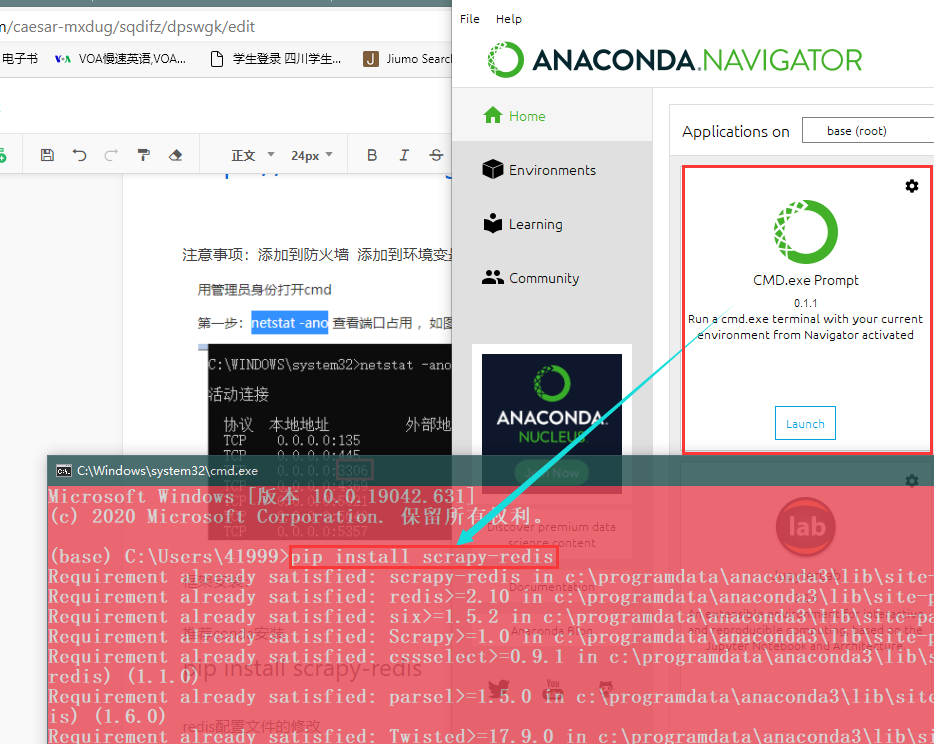
Redis的配置
修改绑定IP地址为0.0.0.0 ——>为了任何服务器都可以访问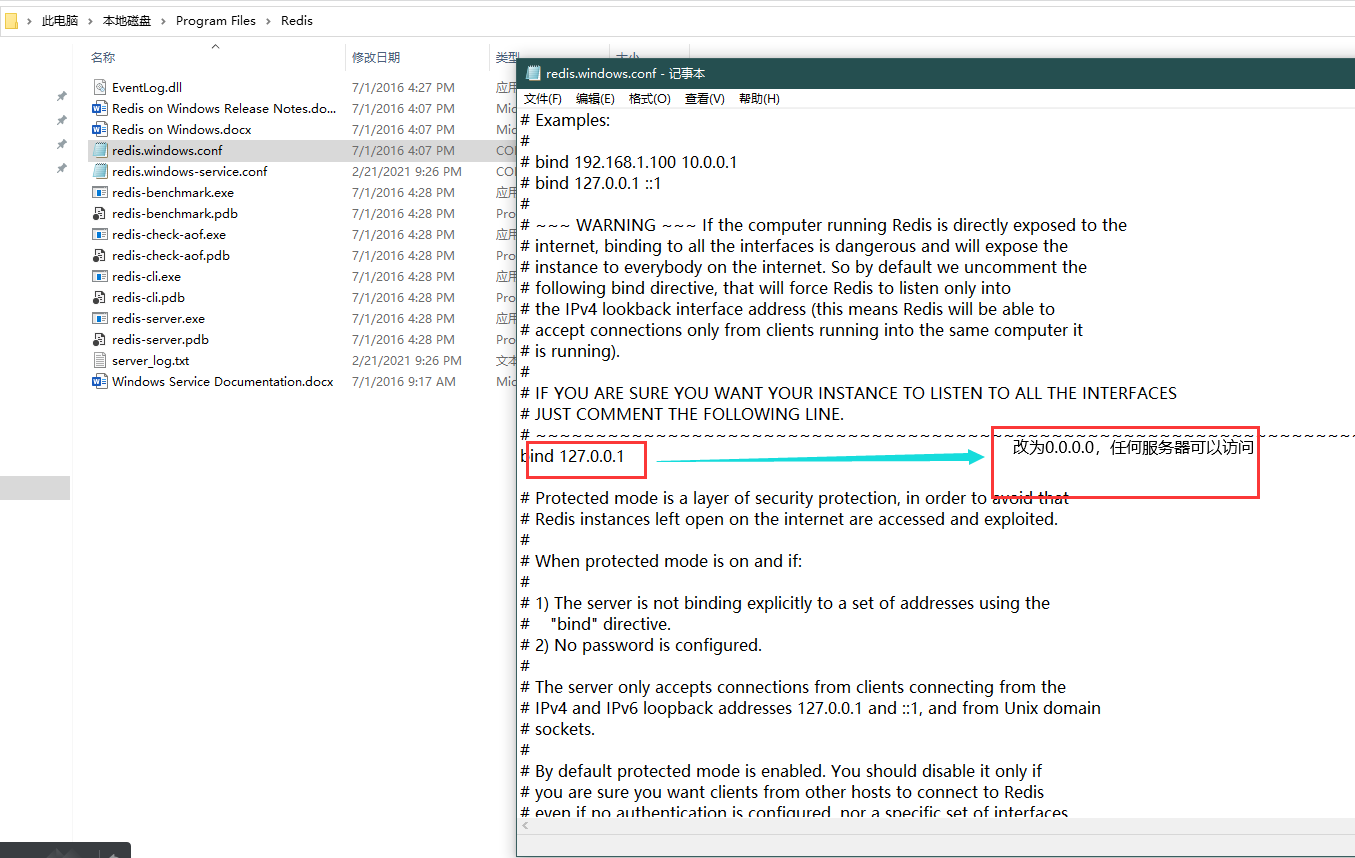
redis配置文件的更改

上面的配置无效,需要重新指定文件
目前的权限修改方案[20211002]
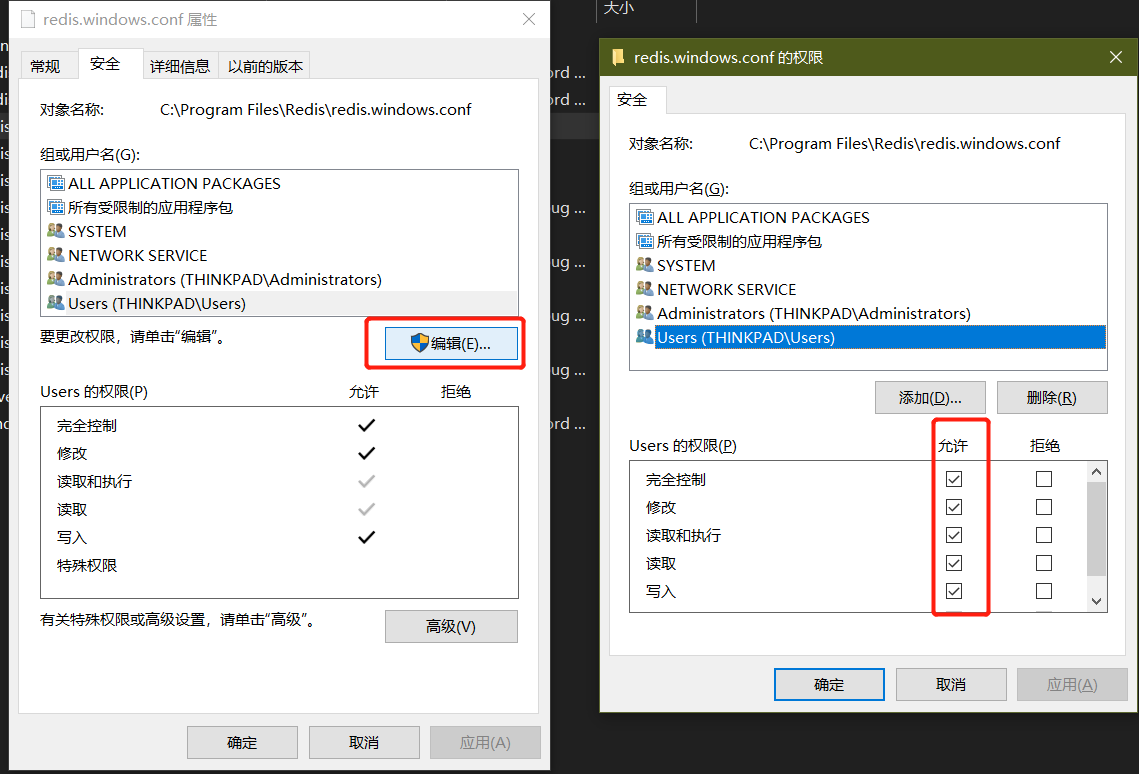
重装,直接放在C盘,另存为再复制回原路径,使用管理员权限替换
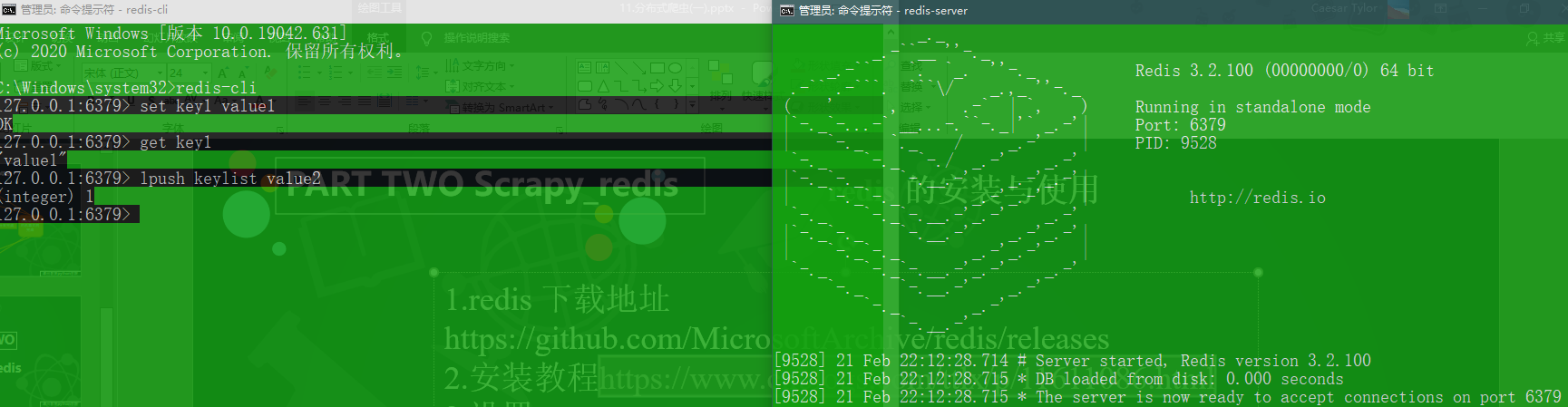
简单的Redis命令
# 两个命令行窗口使用redis-serverredis-cli# 创建键值对set key1 value1# 查询keykeys *# 清空数据库flushdb
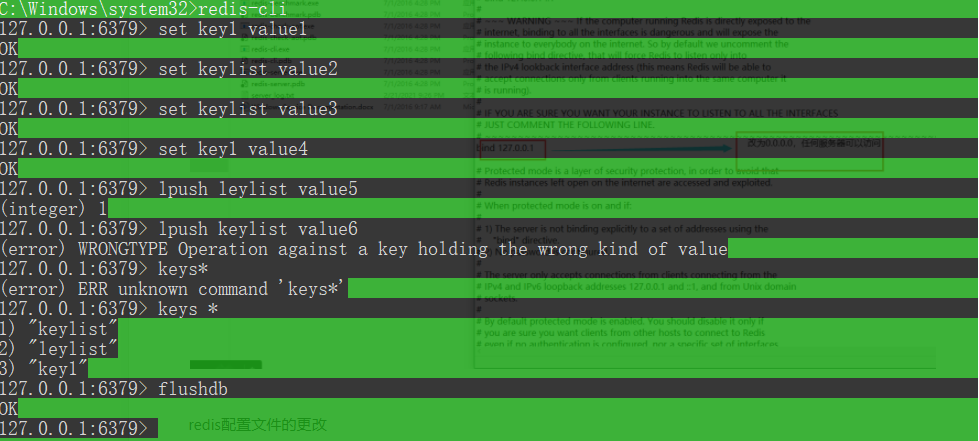
Scrapy_redis介绍
1 个人开发项目,扩展scrapy功能,使其支持分布式
2 scrapy原有Scheduler不支持分布式 数据下载完成经过引擎传递给scrapy_redis框架
3 Redis支持去重(scrapy_redis会去掉重复请求)
Redis功能
# 启用调度将请求存储进redis# 必须SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 确保所有spider通过redis共享相同的重复过滤。# 必须DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"#公共管道ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline' : 300}# 指定连接到Redis时要使用的主机和端口。# 必须REDIS_HOST = 'localhost'REDIS_PORT = 6379# 不清理redis队列,允许暂停/恢复抓取。# 可选 允许暂定,redis数据不丢失#SCHEDULER_PERSIST = True # 用于支持断点续爬(请求数据不会丢失)官方文档:https://scrapy-redis.readthedocs.io/en/stable/
Redis中存储的数据
spidername:items# list类型,保存爬虫获取到的数据item内容是json字符串。spidername:dupefilter# set类型,用于爬虫访问的URL去重内容是40个字符的url的hash字符串spidername:start_urls# list类型,用于接收redisspider启动时的第一个urlspidername:requests# zset类型,用于存放requests等待调度。内容是requests对象的序列化字符串。
分布式项目演示
1 settings中配置scrapy_redis
导入包
from scrapy_redis import scheduler
配置代码
# Scrapy_Redis配置# 启用调度将请求存储进redis# 必须SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 确保所有spider通过redis共享相同的重复过滤。# 必须DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"#公共管道ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline':300,}# 指定连接到Redis时要使用的主机和端口。# 必须REDIS_HOST = 'localhost'REDIS_PORT = 6379# 不清理redis队列,允许暂停/恢复抓取。# 可选 允许暂定,redis数据不丢失#SCHEDULER_PERSIST = True # 用于支持断点续爬(请求数据不会丢失)
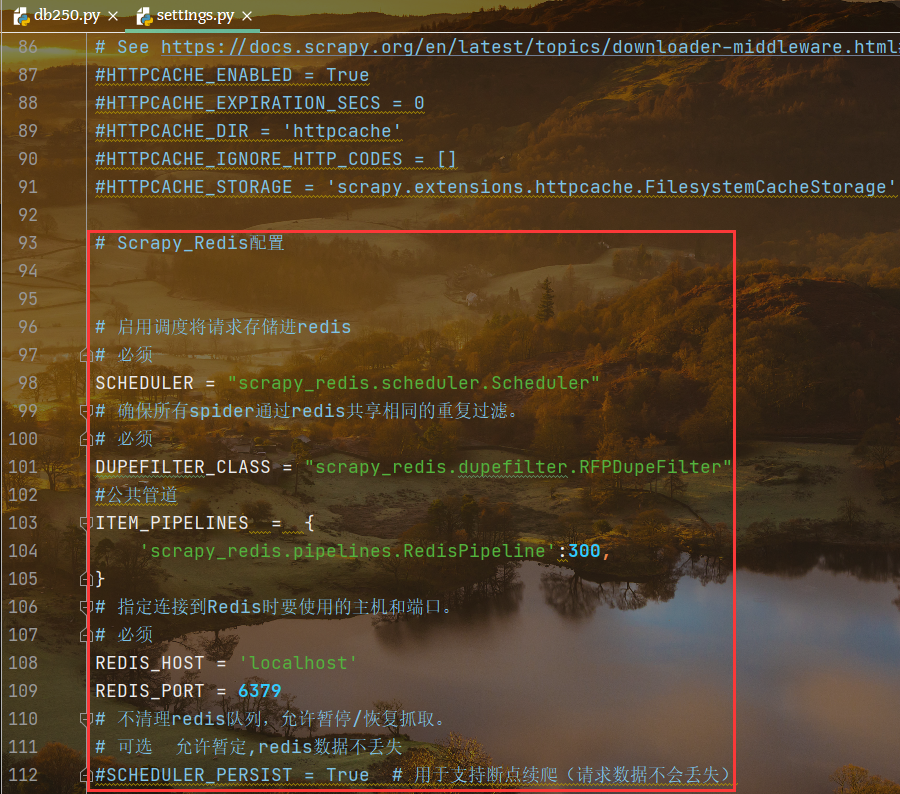
注意:需要注释原有设置中的pipeline存储管道
查看运行结果
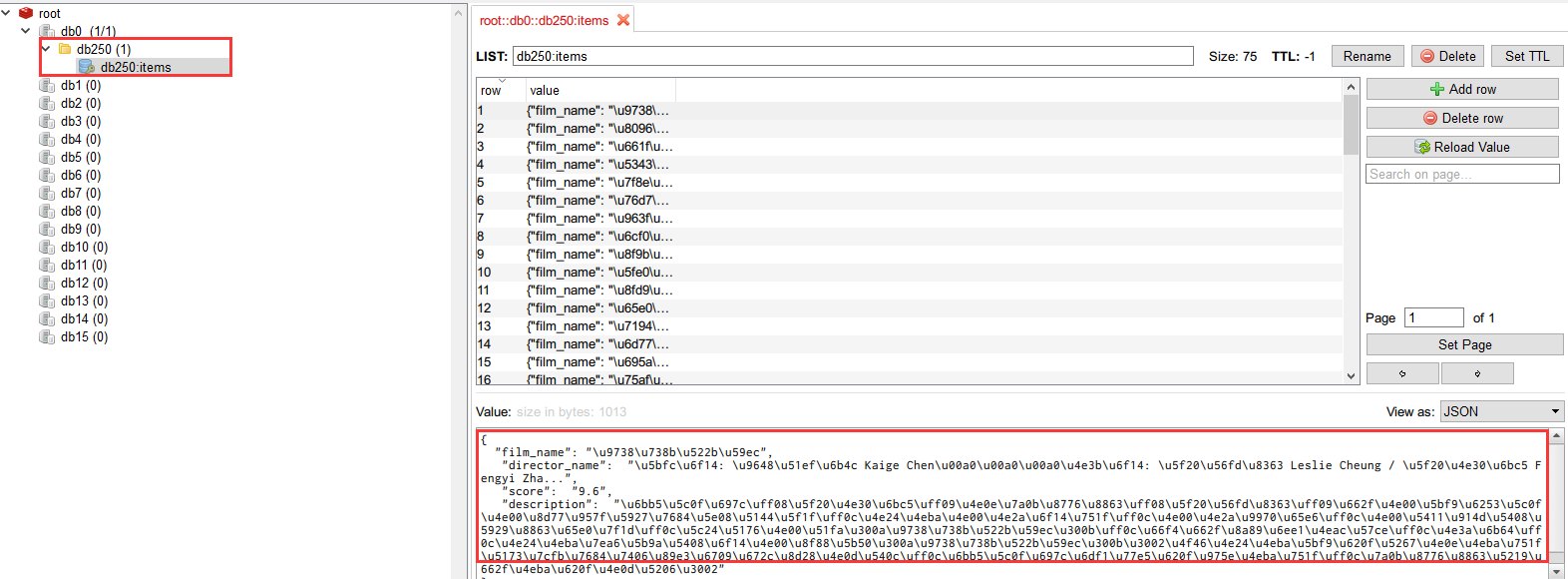
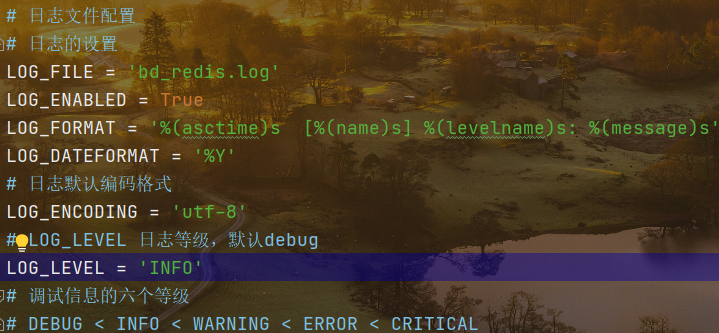
2 配置日志以及调低延迟
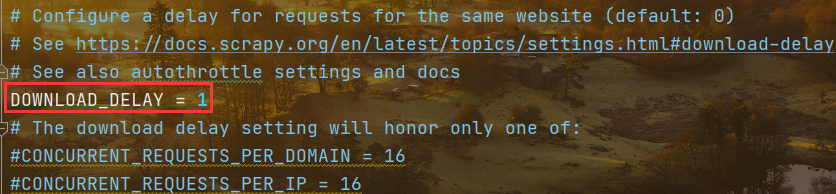
# 日志文件配置# 日志的设置LOG_FILE = 'bd_redis.log'LOG_ENABLED = TrueLOG_FORMAT = '%(asctime)s [%(name)s] %(levelname)s: %(message)s'LOG_DATEFORMAT = '%Y'# 日志默认编码格式LOG_ENCODING = 'utf-8'# LOG_LEVEL 日志等级,默认debugLOG_LEVEL = 'INFO'# 调试信息的六个等级# DEBUG < INFO < WARNING < ERROR < CRITICAL# Configure a delay for requests for the same website (default: 0)# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docsDOWNLOAD_DELAY = 1# The download delay setting will honor only one of:#CONCURRENT_REQUESTS_PER_DOMAIN = 16#CONCURRENT_REQUESTS_PER_IP = 16
分布式爬取数据
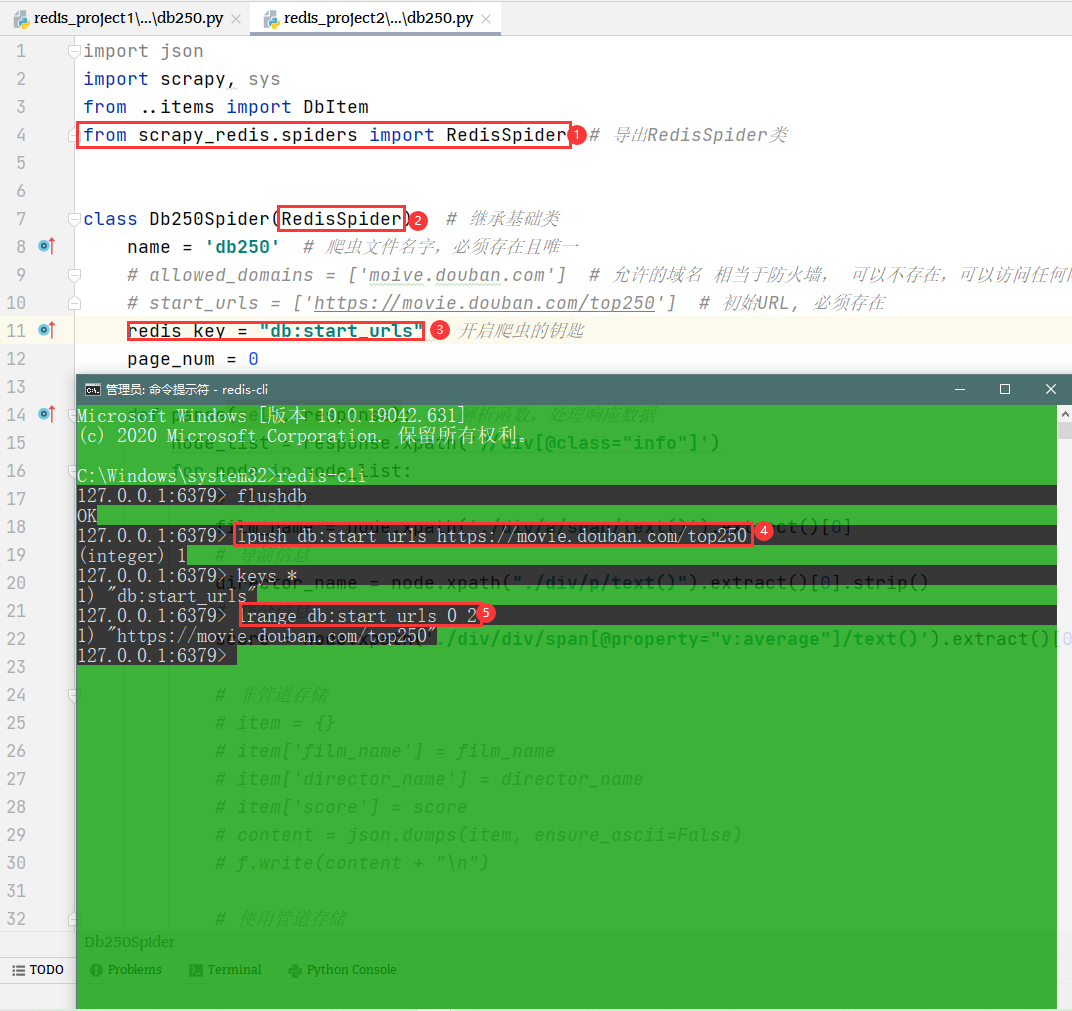
导入指定的包,改变爬虫继承的类
创建redis_key
最后创建数据库中的结构(相当于创建公共存储区域)
修改pipline中存储文件的名字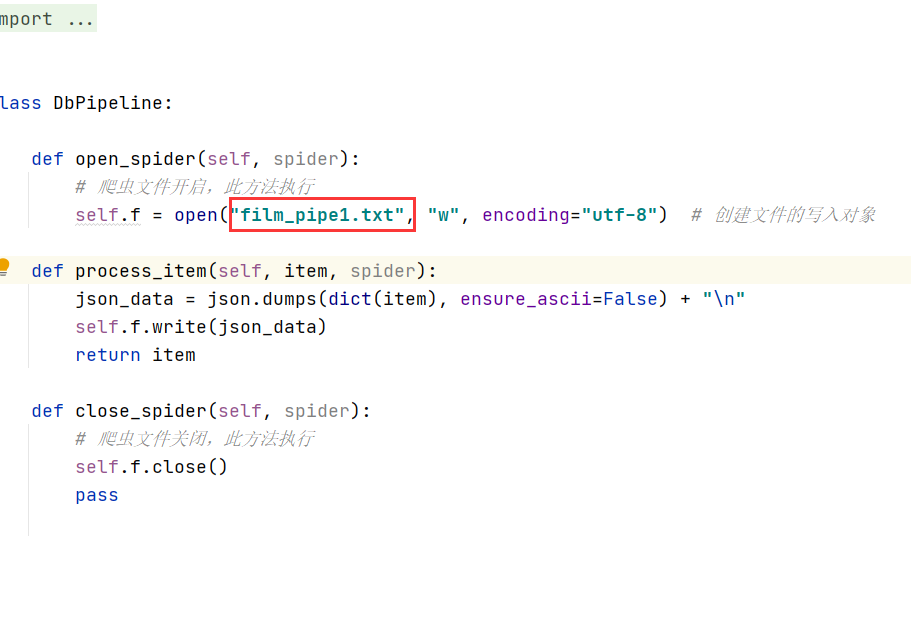
设置打印语句 检测运行状态
控制台开启两个终端同时爬取数据
细节处理
起始URL不启用的原因
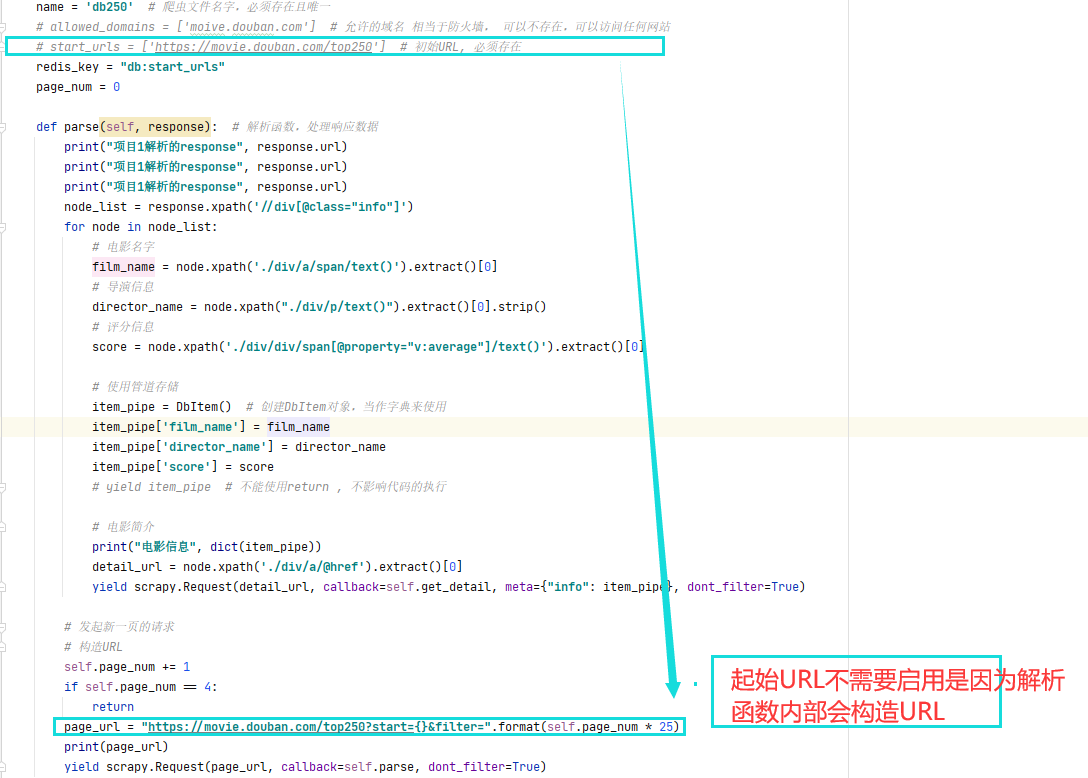
请求被过滤导致页数不足的问题
由于两个爬虫项目是交替或者乱序执行的,所以上一个程序的执行结果可能被另外一个爬虫主程序拿到,但由于程序内部对访问编排顺序还是按照page_number =0 开始构造,请求会重复,所以两个程序只会拿到第一页和第二页的信息,就拿不到第三页,第四页的信息。
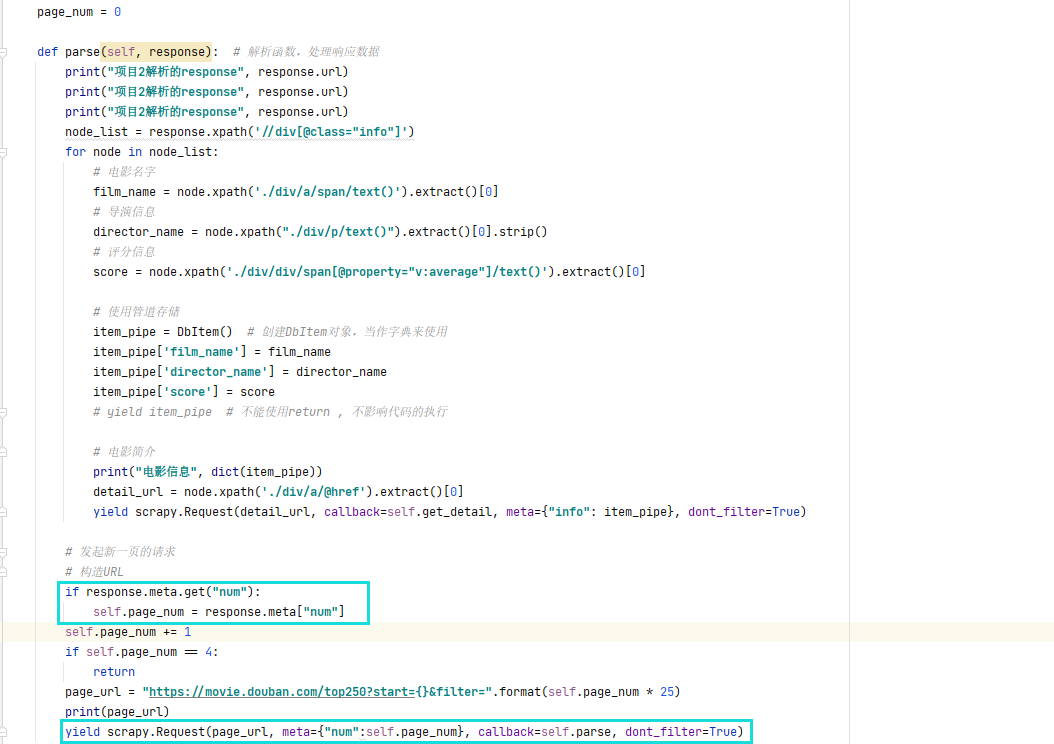
解决方案
在主程序生成请求的时候,直接将主函数中的page.num传递进请求,当response拿到响应之后,就将其中的数字传递给self.page_num,这样就会形成一个闭环,无论是哪一个程序拿到了page_number都会以响应的方式传递给下一个程序,拿到上一次page_num的结果再进行爬取,整个爬取过程就变得井然有序了。
项目总结
做这个项目过程中,首先遇到的问题就是存储模块报错,找老师还是自己核对代码始终不能正常运行,所以只能在拿不到数据的情况下,继续追进度。
后面老师解释爬取数据不足的原因,这一块儿足足听了六遍才搞懂,一是因为做项目的时间太长,问题没有一天解决,主程序也看了两遍,在脑子里面走流程,老师讲的原因,还得顺着程序走一遍,然后再走一遍。刚开始我也不知道meta传参究竟怎么实现的。后来才直到类似于之前自定义请求头,请求头在请求报文和响应报文都可以获取和查看。meta传参的好处在于主程序拿到响应之后可以修改了数据再传入请求,然后响应再获取其中的数据,我们用户是可以自行修改的。
解决问题的经验就是不懂的地方反复听,把流程多走几次,这样就会了然于胸了。

若有收获,就点个赞吧
0 人点赞
