一、为什么要进行拥塞控制?
我们知道,两台主机在传输数据包的时候,如果发送方迟迟没有收到接收方反馈的ACK,那么发送方就会认为它发送的数据包丢失了,进而会重新传输这个丢失的数据包。然而实际上有许多主机正在使用信道资源,导致网络堵塞,而发送方的数据包迟迟没有达到接收方。这个时候发送方会误认为是发生了丢包情况,进而重新传输这个数据包。
结果就是不仅浪费了信道资源,还会使网络更加拥塞。因此我们需要进行拥塞控制。
二、如何知道网络的拥塞情况?
A 和 B 通过三握手建立连接后,就可以向 B 发送数据了,然而这时候 A 并不知道此时的网络的堵塞情况,也就是说,A 不知道一次性发送多少个数据包称之为拥塞窗口,用cwnd表示。
以下有两种方法来探测网络的拥塞情况:
- 拥塞避免:先发送一个数据包试探,如果该数据包没有发生超时事件,那么下次发送时就发送2个,如果还没有发生超时事件,下次就发送3个,以此类推,即呈线性增长:cwnd = 1, 2, 3, 4, …
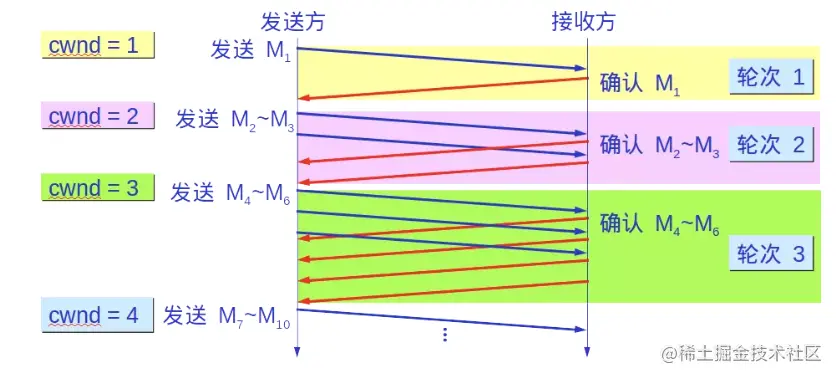
- 慢启动:一个一个增长太慢了,所以可以刚开始发送1个,如果没有发生超时,就发送2个,如果仍然没有发生超时就发送4个,接着8个,以此类推,即呈指数增长:cwnd = 1, 2, 4, 8, 32, …
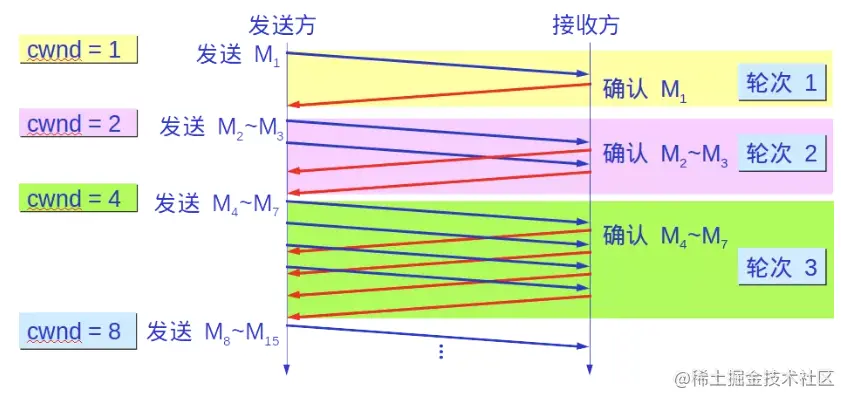
无论第一种还是第二种方法,最后都会出现瓶颈值。但第一种方法增长过慢,第二种方法增长过快,为了解决这个问题,我们可以把两种方法进行结合。也就是说,我们刚开始以指数的速度增长,增长到阈值(ssthresh)后,我们采用线性增长。
所以最终的策略是:前期指数增长,到达阈值后,就以一个一个线性的速度来增长。
三、到了瓶颈值怎么办?
策略已经确定了,可是ssthresh是怎么设置的呢? TCO/IP中规定无论是在慢开始阶段还是在拥塞避免阶段,只要发现网络中出现拥塞(没有按时收到确认),就要把**ssthresh**设置为此时发送窗口的一半大小(不能小于2)。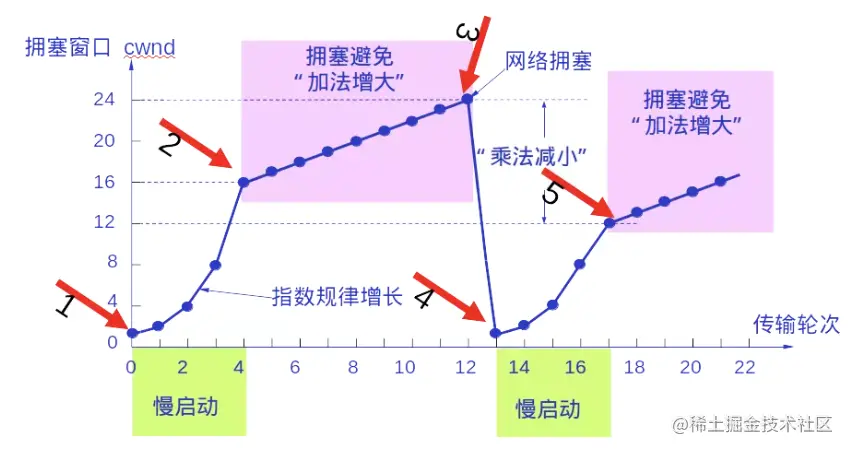
如上图所示,拥塞控制的大致流程如下:
- 一开始把
ssthresh初始值设置为16,开始慢启动增加拥塞窗口cwnd,直到cwnd=16 停止慢启动,开始拥塞避免算法。 - 使用拥塞避免算法线性增加cwnd,直到cwnd=24,这时候网络出现拥塞(ACK信号没有及时到达),把
ssthresh设置为原来的一半,也就是ssthresh=12,同时把 cwnd 设置为1。 - 重新启动慢启动,直到cwnd 到达
ssthresh=12,然后执行拥塞避免算法进行加法增大,直到网络拥塞,把ssthresh调成原来的一半。 - 如此循环动态计算cwnd,以达到拥塞控制的目的。
四、超时事件就一定是网络堵塞吗?
超时事件发生除了网络拥堵,还有可能是因为某个数据包出现丢失或者损害了,导致这个数据包超时事件发生。
为了防止这种情况,我们可以通过 TCP快重传 来处理。即允许发送方在连续收到3个重复确认后就可以开始执
行乘法减小过程而不必等待重发超时时间。这要求接收方每收到一个失序的报文段就立即发出重复的确认以让发
送方及早知道有报文段丢失,而不是等待自己发送数据的时候进行携带确认。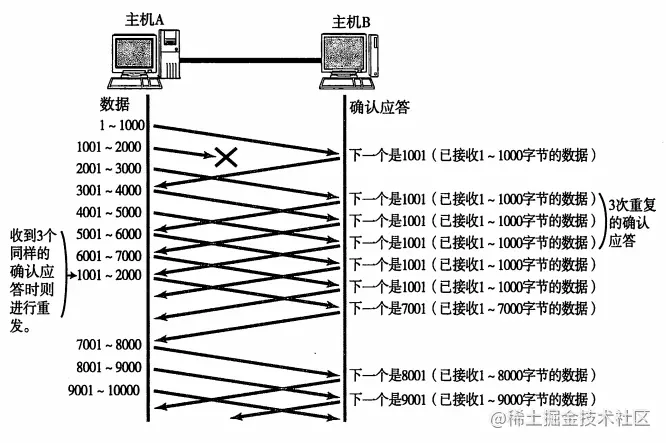
当快重传时,发送方快速收到了3个重复的确认,因此会认为网络不是拥塞状态,所以在乘法减小过程(设置 ssthresh 为原来的一半),会启动拥塞避免,而不是慢启动,这种算法被称为快恢复。

若有收获,就点个赞吧
0 人点赞
