背景
opendiffy 是 Twitter 开源的一个 diff 系统,想系统了解可以移步至之前的文章 opendiffy原理和源码剖析。
diff 的总体流程是,先比对 2 个 JSON,然后汇总统计,生成报表。在 opendiffy 中,因为是单进程的,所以比对和统计都在单点上,本身是不支持水平扩展的,从官方作者的回答中我们可以看出。
https://github.com/opendiffy/diffy/issues/37
官方作者回复,opendiffy 不支持水平扩展,需要重新设计,如果需要可以去使用他们的企业版本。
但是,真的没有办法吗 ? 答案是有的。
方案
我们来分析一下, 目前 opendiffy 的逻辑是这样的。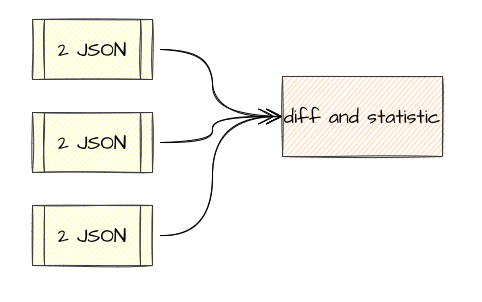
多个 JSON 对都是怼给一个实例,diff 和统计都在单点上,无法实现水平扩展。 统计目前来看是必须单点,因为要汇总一批数据,这个逃不掉必须是单点,但是 diff 其实可以扩展的,diff 本身是最吃资源的,它是 CPU 密集型的计算,而且是无状态计算。 所以,我们可以把架构拆分为这样。
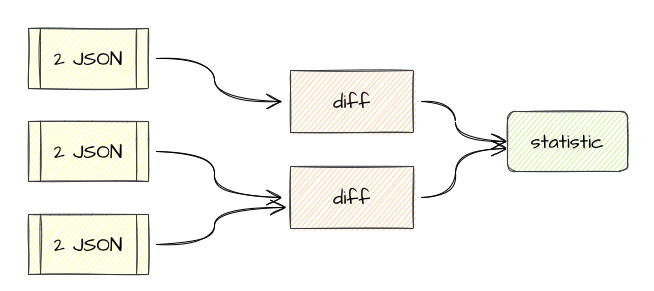
最慢的节点被解决为可以无限水平扩展,statistic 只是非常轻量级的汇总就好了,理论上 statistic 几乎不太可能成为瓶颈。
总结
我做过一次数据统计,不一定非常准确,但是可以作为一个参考。
单点的时候,1000 对 JSON比对,response 的字段为 10 个,字段层级最多 3 层,全部计算和统计完要 10s。
diff 节点水平扩展为 100 个计算节点,相同的数据量,基本上在 2s 就算完了,性能提升了好几个数量级。
其实这是系统优化的常规思路,将计算和存储分离,只要是看懂了本质问题,优化起来一点都不难。

若有收获,就点个赞吧
0 人点赞
