opendiffy 诞生的背景
在微服务领域,验证协议稳定性的一种方法,就是 diff 2 个 response。一个很常见的做法是我们的 response 会以 json 的形式来定义,那问题就变成了比对 2 个 json 。如果只是单纯的 1 组 json,那前端就有相应的比对库,直接看就行了。可是微服务领域的接口不会这么简单,经常接口里有随机数等噪声,如果不去掉,那么报表是没法看的,所以需要有相应的去噪算法。
基于以上的原因,opendiffy 这个项目诞生了。 opendiffy 集成了 proxy 分发流量模块,统计汇总diff模块,前端展示模块等,是一个开箱即用的开源项目,非常傻瓜。 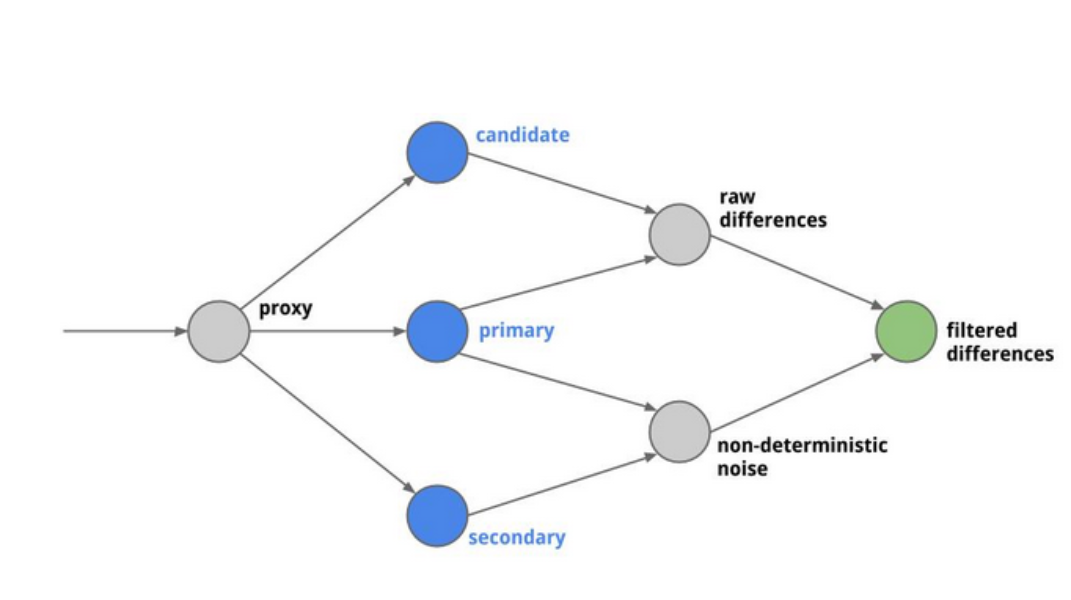
使用
针对 opendiffy,可以快速搭建一个项目来测试一下。 主要步骤如下:
- 启动 opendiffy,因为是 scala写的,需要本地有 jvm 环境,如果偷懒,可以直接用 docker 启动
- docker 启动的时候,记得映射一下存储卷,将本地的某个目录 mount 到容器里
- 在本地的目录下开发一段代码,这段代码就是模拟项目的更新发布,编译好二进制,这里我是用 golang 写的,跨平台编译出 Linux 的包
- 登录容器,进到自己 mount 的那个目录下,逐个启动 primary, secondary, candidate(这个就是自己的新 feature 代码)
- 在 mac 上往 proxy 发送请求,proxy 会路由到 3 个版本上,然后就能比对出结果了
如果安装了 jvm,则直接运行opendiffy 的 jar 文件即可了,测试非常简单。
java -jar diffy-server.jar \-candidate=localhost:9992 \-master.primary=localhost:9990 \-master.secondary=localhost:9991 \-service.protocol=http \-serviceName=Fancy-Service \-proxy.port=:8880 \-admin.port=:8881 \-http.port=:8888 \-rootUrl="localhost:8888" \-summary.email="info@diffy.ai" \-summary.delay="5"
发送请求,然后打开 http://localhost:8888 看到 diff 结果了。
这是我的测试代码:
package mainimport ("fmt""net/http")func hello(w http.ResponseWriter, req *http.Request) {fmt.Printf("hello handler is being called, method: %v, url: %v \n", req.Method, req.URL.String())fmt.Fprintf(w, "hello.\n") // 新版本的代码,多了一个点}func headers(w http.ResponseWriter, req *http.Request) {for name, headers := range req.Header {for _, h := range headers {fmt.Fprintf(w, "%v: %v\n", name, h)}}}func main() {http.HandleFunc("/", hello)http.HandleFunc("/headers", headers)fmt.Println("server listen on 9992. i am candidate")http.ListenAndServe(":9992", nil)}
架构
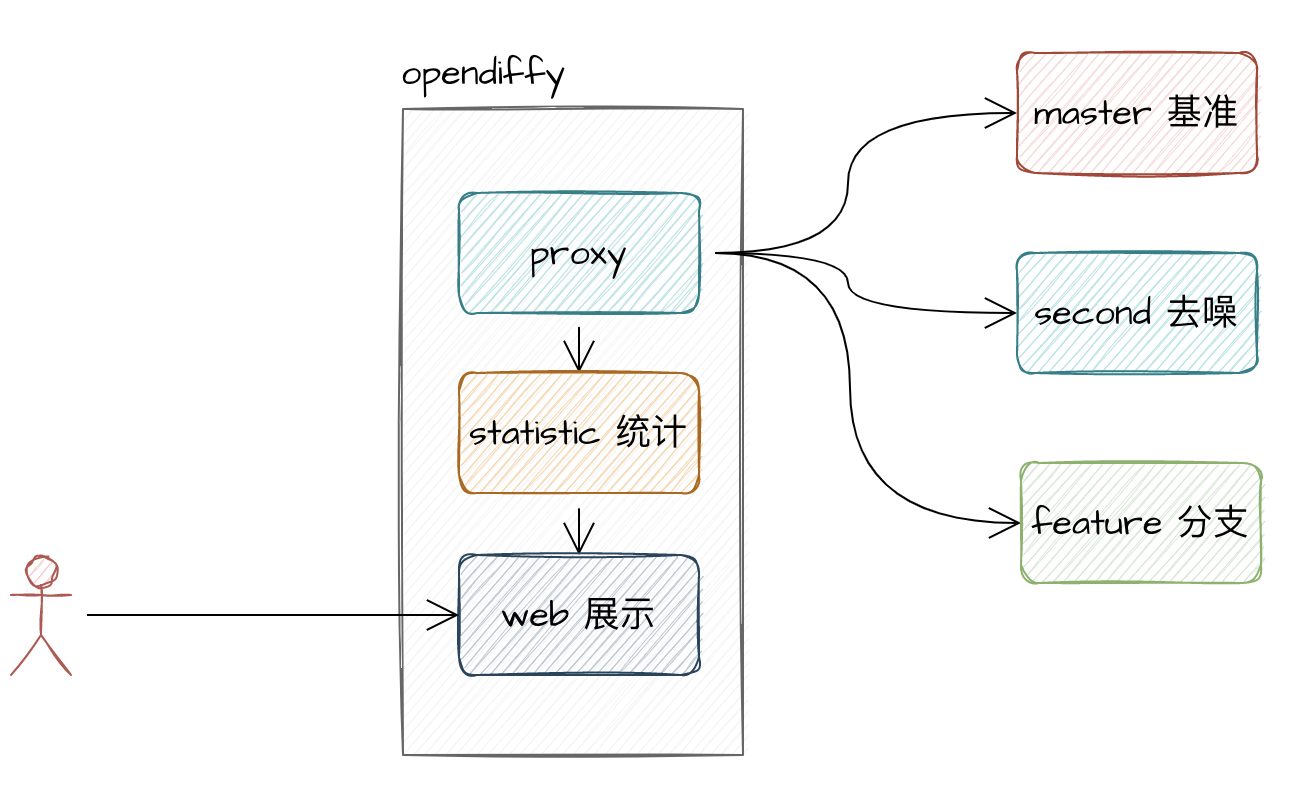
原理
比对计算
比对是 2 个 JSON 的比对,JSON 的比对是递归的比对。所有的比对,最后都会终止于几个原子比对,有:
空 => trueBoolean => trueByte => trueChar => trueShort => trueInt => trueLong => trueFloat => trueDouble => trueString => true
只要比对到这些类型的,就能直接返回结果,相同就是 true,不同就是 false。
其中还有几个特殊的类型,会转化为基础类型去比对。
字节数组
转换为 string 去比对。
数组比对
长度比对
索引比对
内容比对
内容一致,顺序不一样,返回的是 OrderingDifference。 如果内容一致,配置了忽略顺序,则是 NoDifference。 如果内容不一致,长度一样,则是 IndexedDifference。 以上都不是则是 SeqSizeDifference。
map 比对
转化为 key 比对和 value 比对。
key 确实或者 key 冗余。
value 就是 JSON 比对了。
JSON string 比对
转化为 JSON 去比对。
比对之后的结果
假设 AB 2 个 JSON 比对,里面有 1 个字段有 diff。每个字段 diff 都是一个 map 结构。
{ "字段名": "xxx" , "diff 的个数": 1, 权重: 1, "actual": 89, "expected": 90 ,“diff类型": "基础类型diff"}
汇总统计
如何判断某个字段是否得到了一个有效 diff
1000 个请求里,一个字段出现了 10 次 diff,它是否为一个有效 diff 呢? 是有一个固定公式的,这个公式是开源项目写死的,经过Twitter内部验证过的。
总请求数 totalAA 比对出现相同字段名有 diff 的总数 noiseAB 比对出现相同字段名有 diff 的总数 raw相对值 = abs(raw - noise) / (raw + noise) * 100绝对值 = abs(raw - noise) / total * 100当 raw > noise && 相对值 > 20 && 绝对值 > 0.03true --> 有效 difffalse --> 无效 diff
权重的概念
2 个 JSON 去diff,这个 diff 肯定是因为某个一个方法请求引发的,但是 diff 不一定是在一个字段里,可能是在多个字段里。
每个有 diff 的字段都有权重值。一个字段的权重 = 引起该字段出现diff的 request 的所有字段diff的总和。 可以理解为一个request引发了多少字段的diff。
所以,这个权重值是跟这个字段 diff 相关的request 所引发的 所有的 diff 数。 这个不好理解,举个例子吧。
我发了 1 个请求,里面有 5 个字段,都出现了 diff。
针对 A 字段,它的 diff 数就是 1. 但是它的总权重是 5 。
针对 B 字段,它的 diff 数也是 1,它的总权重也是 5。
…….
如果我发了第2个请求,里面依然是5个字段,只有 A字段出现了diff,那么 A的总权重为 5+1 = 6, B的总权重依然是5。
diff 成功 or 失败
有效 diff 总权重 = 所有有效字段 diff 的权重的求和总权重 = 所有有diff 的字段的权重求和diff 率 = (有效 diff 总权重 / 总权重 ) * (AB 出现的请求级别的 diff 数 / 总请求数)这个公式可以这么理解,我们分为 2 个部分:diff 率 = X * Y大众所知的 diff 率是 Y,就是我一个请求出现 diff,就应该算 1,最后除以总的请求数。但这个没有考虑噪声,是不置信的。 所以我们要乘以一个置信率。 权重就是考虑到了噪声。所以变成了 diff 率 = 置信率 * 我们通常认为的 diff 率。diff 率 > 你在用例配置的比例, 则报表显示就是失败, 也就是你的所有请求里,diff 太多了,超过阈值了。如果你配置了多个方法,每个方法都有自己的阈值,则只要有一个为失败,整个报表就是失败的。
总结
本文介绍了 opendiffy 的项目背景,架构,使用,原理。
原理主要分为计算和统计,计算就是比对的计算,其实就是 JSON 的比对逻辑。统计就是如何确定噪声,有效 diff 等,然后判断最后 diff 的成功 or 失败。
参考资料

若有收获,就点个赞吧
0 人点赞
