HashSet集合存储数据的结构(哈希表)
什么是哈希表呢?
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一
个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率
较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转
换为红黑树,这样大大减少了查找时间。当链表长度从8减少打牌6时 ,将红黑树转换为链表。初始桶量16,散列因子0.75。散列因子越大,越节省空间,越难查询,散列因子越小,越浪费空间,查询效率高。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。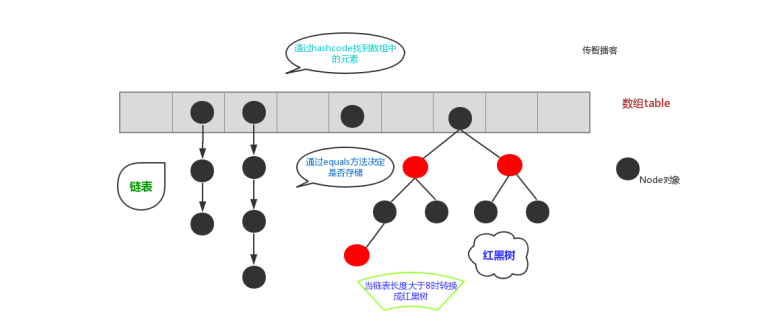
存储流程图
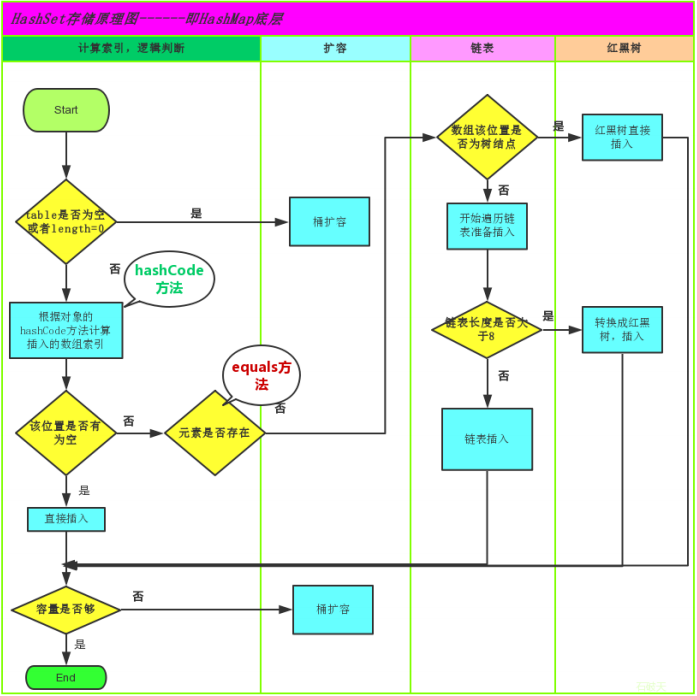
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元
素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对
象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方
式,才能保证HashSet集合中的对象唯一
LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类 java.util.LinkedHashSet ,它是链表和哈希表组合的一个数据存储结构。

若有收获,就点个赞吧
0 人点赞
