一、MySQL数据库的介绍
1.1什么是数据库
数据库(Database)就是按照数据结构来组织,存储和管理数据的仓库
专业的数据库是专门对数据进行创建,访问,管理,搜索等操作的软件,比起我们自己用文件读写的方
式对象数据进行管理更加的方便,快速,安全
1.2作用
(1)对数据进行持久化的保存
(2)方便数据的存储和查询,速度快,安全,方便
(3)可以处理并发访问
(4)更加安全的权限管理访问机制
1.3库和表的概念与关系
库就像是文件夹,库中可以有很多个表
表就像是我们的excel表格文件一样
每一个表中都可以存储很多数据
mysql中可以有很多不同的库,库中可以有很多不同的表
表中可以定义不同的列(字段),
表中可以根据结构去存储很多的数据
1.4mysql处理客户端请求原理
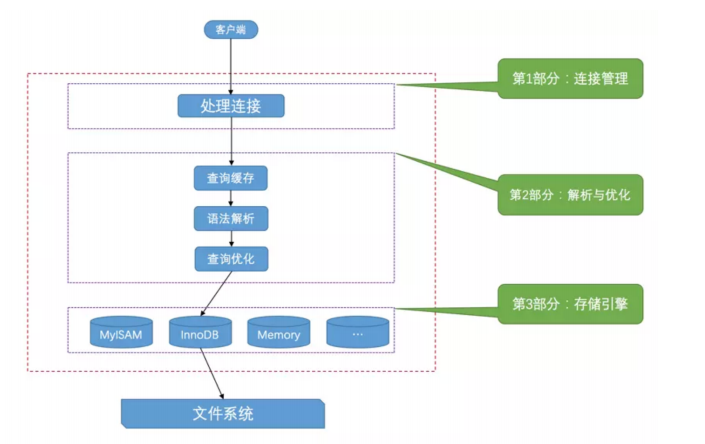
虽然查询缓存有时可以提升系统性能,但也不得不因维护这块缓存而造成一些开销,比如每次都要去查询缓
存中检索,查询请求处理完需要更新查询缓存,维护该查询缓存对应的内存区域。从MySQL 5.7.20开始,不
推荐使用查询缓存,并在MySQL 8.0中删除。
1.5存储引擎 (表处理器)
为了管理方便,人们把 连接管理 、 查询缓存 、 语法解析 、 查询优化 这些并不涉及真实数据存储的功能划分为
MySQL server 的功能,把真实存取数据的功能划分为 存储引擎 的功能。各种不同的存储引擎向上边的 MySQL
server 层提供统一的调用接口(也就是存储引擎API),包含了几十个底层函数,像”读取索引第一条内容”、”读取
索引下一条内容”、”插入记录”等等。
所以在 MySQL server 完成了查询优化后,只需按照生成的执行计划调用底层存储引擎提供的API,获取到数据后返
回给客户端就好了
MySQL 支持非常多种存储引擎: 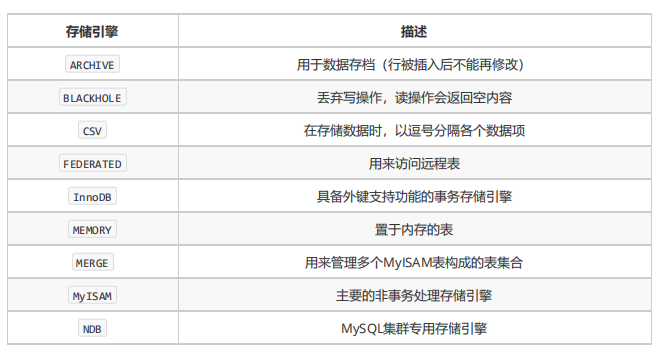
1.6MyISAM和InnoDB表引擎的区别
1) 事务支持
MyISAM不支持事务,而InnoDB支持。
事物:访问并更新数据库中数据的执行单元。事物操作中,要么都执行要么都不执行
2) 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。
.frm文件存储表结构。
.MYD文件存储数据
.MYI文件存储索引。
InnoDB:主要分为两种文件进行存储
.frm 存储表结构
.ibd 存储数据和索引 (也可能是多个.ibd文件,或者是独立的表空间文件)
3) 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如
果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。 InnoDB:支持事务和行级锁,是
innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有
效的,非主键的WHERE都会锁全表的。
4) 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。 InnoDB:如果没有设定主键或者非空唯
一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。
InnoDB的主键范围更大,最大是MyISAM的2倍。
5) 表的具体行数
MyISAM:保存有表的总行数,如果select count() from table;会直接取出出该值。 InnoDB:没有保存表的总行数
(只能遍历),如果使用select count() from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,
myisam和innodb处理的方式都一样。
6) CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。 InnoDB:如果你的数据执行大量的INSERT或
UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table
时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用
truncate table这个命令。
7) 外键
8) 查询效率
MyISAM相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用MyISAM。
推荐考虑使用InnoDB来替代MyISAM引擎,原因是InnoDB自身很多良好的特点,比如事务支持、存储 过程、视
图、行级锁定等等,在并发很多的情况下,相信InnoDB的表现肯定要比MyISAM强很多。
另外,任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优
势。如果不是很复杂的Web应用,非关键应用,还是可以继续考虑MyISAM的,这个具体情况可以自己斟酌。
9)MyISAM和InnoDB两者的应用场景:
MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那
么MyISAM是更好的选择。 InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要
执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。现在默认使用
InnoDB。
1.7字符集简介
字符与二进制数据的映射关系
字符发展历程:ASCII 字符集 -扩充->ISO 8859-1 字符集 -扩充->GB2312 字符集 -扩充->GBK 字符集 -扩充->utf8 字符集
utf8 字符集
收录地球上能想到的所有字符,而且还在不断扩充。这种字符集兼容 ASCII 字符集,采用变长编码方式,编
码一个字符需要使用1~4个字节是现在我们使用的字符集。
注意:
MySQL中的utf8指的是utf8mb3 :阉割过的 utf8 字符集,只使用1~3个字节表示字符。
推荐使用utf8mb4 :正宗的 utf8 字符集,使用1~4个字节表示字符。
二、mysql的基本操作
1.通过命令行连接MySQL
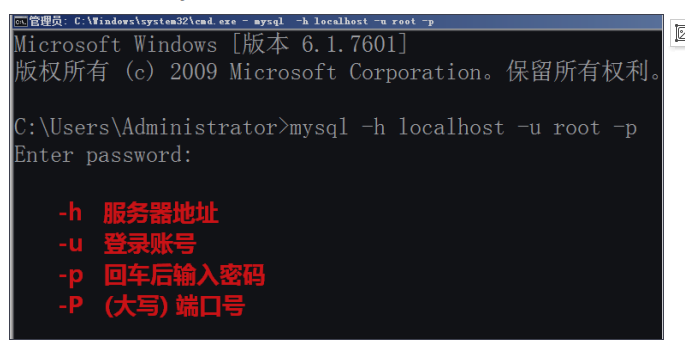
数据库语法的特点
1) SQL 语句可以换行, 要以分号结尾
2) 命令不区分大小写. 关键字和函数建议用大写
3) 如果提示符为 ‘> 那么需要输入一个’回车
4) 命令打错了换行后不能修改, 可以用 \c 取消
2. 数据库操作
1)查看数据库 show databases;
2)创建数据库 create database 库名 default charset=utf8mb4;
3)创建数据库
create database if not exists tlxy default charset=utf8;-- 1. 数据库 tlxy 如果不存在则创建数据库,存在则不创建-- 2. 创建 tlxy 数据库,并设置字符集为utf8-- 3. 无特殊情况都要求字符集为utf8或者utf8mb4的字符编码
4)删除数据库 drop database 库名; (删除库,那么库中的所有数据都将在磁盘中删除。)
5)打开数据库 use 库名;
3. 数据表操作
数据库管理系统中, 可以有很多库, 每个数据库中可以包括多张数据表
3.1查看表:
3.2创建表:
create table 表名(字段名1 类型,字段名2 类型)engine=innodb default charset=utf8;
3.3创建表:
如果表不存在,则创建, 如果存在就不执行这条命令
create table if not exists 表名(字段1 类型,字段2 类型);
create table if not exists users(id int not null primary key auto_increment,name varchar(4) not null,age tinyint,sex enum('男','女'))engine=innodb default charset=utf8mb4;#创建表的基本原则:#表明和字段名 尽可能的符合命名规范,并且最好能够‘见名之意’#表中数据必须有唯一标示,即主键定义。无特殊情况,主键都为数字并自增即可#表中字段所对应的类型设置合理,并限制合理长度#表引擎推荐使用innodb,并无特殊情况都要求为utf8或者utf8mb4的字符编码
3.4删除表:
3.5表结构:
3.6查看建标语句:
3.7修改表的字段
添加字段
# 语法:alter table 表名 add 添加的字段信息-- 在 users 表中 追加 一个 num 字段alter table users add num int not null;-- 在指定字段后面追加字段 在 users 表中 age字段后面 添加一个 email 字段alter table users add email varchar(50) after age;-- 在指定字段后面追加字段,在 users 表中 age字段后面 添加一个 phonealter table users add phone char(11) not null after age;-- 在表的最前面添加一个字段alter table users add aa int first;
删除字段
# 删除字段 alter table 表名 drop 被删除的字段名alter table users drop aa;
修改字段
语法格式: alter table 表名 change|modify 被修改的字段信息change: 可以修改字段名,modify: 不能修改字段名。# 修改表中的 num 字段 类型,使用 modify 不修改表名alter table users modify num tinyint not null default 12;# 修改表中的 num 字段 为 int并且字段名为 nnalter table users change num mm int;# 注意:一般情况下,无特殊要求,不要轻易修改表结构
3.8修改表名
# 语法:alter table 原表名 rename as 新表名
3.9更改表中的自增的值
# 在常规情况下,auto_increment 默认从1开始继续递增alter table users auto_increment = 1000;
3.10修改表引擎
# 推荐在定义表时,表引擎为 innodb。# 通过查看建表语句获取当前的表引擎mysql> show create table users\G;*************************** 1. row ***************************Table: usersCreate Table: CREATE TABLE `users` (PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf81 row in set (0.00 sec)# 直接查看当前表状态信息mysql> show table status from tlxy where name = 'users'\G;*************************** 1. row ***************************Name: usersEngine: InnoDB# 修改表引擎语句alter table users engine = 'myisam';
4. 数据操作 增删改查
1)插入
insert into 表名(字段1,字段2,字段3) values(值1,值2,值3);
insert into 表名(字段1,字段2,字段3) values(a值1,a值2,a值3),(b值1,b值2,b值3);
2)查询
select from 表名;
select 字段1,字段2,字段3 from 表名;
select from 表名 where 字段=某个值;
3)修改
update 表名 set 字段=某个值 where 条件;
update 表名 set 字段1=值1,字段2=值2 where 条件;
update 表名 set 字段=字段+值 where 条件;
4)删除
delete from 表名 where 字段=某个值;
5. 退出MySQL
exit; 或者 quit;
三、MySQL的数据类型
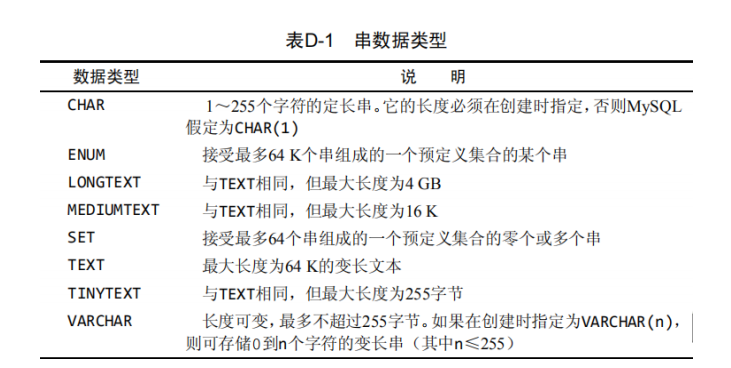
1、字符串数据类型
*1.1定长串:char
1) 接受长度固定的字符串,其长度是在创建表时指定的。 定长列不允许存储多于指定长度字符的数据。
2)指定长度后,就会分配固定的存储空间用于存放数据
3)性能高,MySQL处理定长列远比处理变长列快得多。
char(7) 不管实际插入多少字符,它都会占用7个字符位置
*1.2变长串 varchar
存储可变长度的字符串 varchar(7) 如果实际插入4个字符, 那么它只占4个字符位置,当然插入的数据长度不能超过7
个字符。
1.3Text 变长文本类型存储
2、数值类型
与字符串不一样,数值不应该括在引号内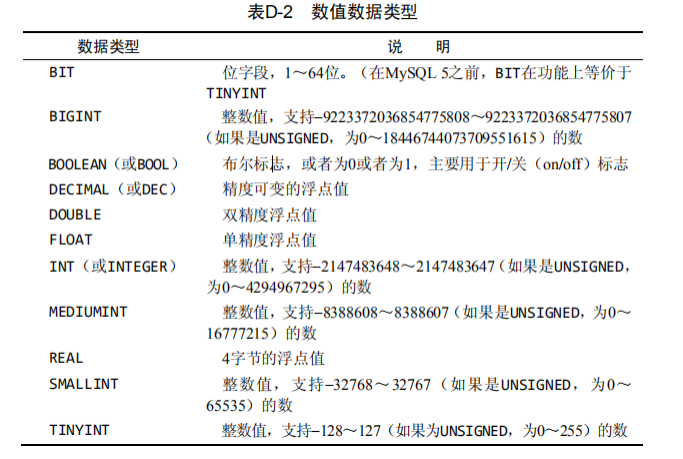
例子
decimal(5, 2) 表示数值总共5位, 小数占2位tinyint 1字节(8位) 0-255。-128,127int 4字节。 -21亿,21亿。0-42亿float.MySQL中没有专门存储货币的数据类型,一般情况下使用DECIMAL(8, 2)
所有数值数据类型(除BIT和BOOLEAN外)都可以有符号或无符号
1)有符号数值列可以存储正或负的数值
2)无符号数值列只能存储正数。
3)默认情况为有符号,但如果你知道自己不需要存储负值,可以使用UNSIGNED关键字
注意:
在数值前加0则0不会存进去,如将邮政编码类似于01234存储为数值类型,则保存的将是数值1234
3、日期和时间类型

4、二进制数据类型
二进制数据类型可存储任何数据(甚至包括二进制信息),如图像、多媒体、字处理文档等 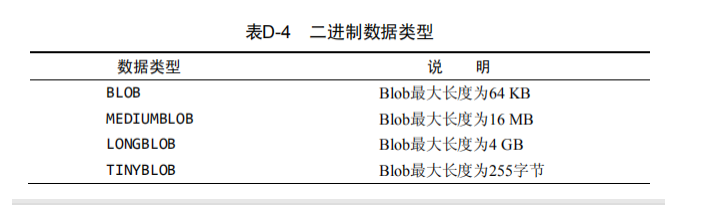
四、表的字段约束
1.unsigned 无符号(给数值类型使用,表示为正数,不写可以表示正负数都可以)
2.字段类型后面加括号限制宽度
1)char(5). varchar(7) 在字符类型后面加限制 表示 字符串的长度
2)int(4) 没有意义,默认无符号的int为int(11),有符号的int(10)
3)int(4) unsigned zerofifill只有当给int类型设置有前导零时,设置int的宽度才有意义。
3.not null 不能为空,在操作数据库时如果输入该字段的数据为NULL ,就会报错
4.default 设置默认值
5.primary key 主键不能为空,且唯一.一般和自动递增一起配合使用。
6.auto_increment 定义列为自增属性,一般用于主键,数值会自动加1
7.unique 唯一索引(数据不能重复:用户名)可以增加查询速度,但是会降低插入和更新速度
五、MySQL的运算符
1.算术运算符: +、 -、 *、 /、 %
2.比较运算符: =、 >、 <、 >=、 <=、!=
3.数据库特有的比较: in、not in、is null、is not null、like、between、and
4.逻辑运算符: and、or、not
5.like: 支持特殊符号%和_ ;
六、 数据操作 DML
6.1添加数据
格式: insert into 表名[(字段列表)] values(值列表…);
--标准添加(指定所有字段,给定所有的值)
mysql> insert into stu(id,name,age,sex,classid) values(1,'zhangsan',20,'m','lamp138');
Query OK, 1 row affected (0.13 sec)
mysql>
--指定部分字段添加值
mysql> insert into stu(name,classid) value('lisi','lamp138');
Query OK, 1 row affected (0.11 sec)
-- 不指定字段添加值
mysql> insert into stu value(null,'wangwu',21,'w','lamp138');
Query OK, 1 row affected (0.22 sec)
-- 批量添加值
mysql> insert into stu values
-> (null,'zhaoliu',25,'w','lamp94'),
-> (null,'uu01',26,'m','lamp94'),
-> (null,'uu02',28,'w','lamp92'),
-> (null,'qq02',24,'m','lamp92'),
-> (null,'uu03',32,'m','lamp138'),
-> (null,'qq03',23,'w','lamp94'),
-> (null,'aa',19,'m','lamp138');
Query OK, 7 rows affected (0.27 sec)
Records: 7 Duplicates: 0 Warnings: 0
6.2修改数据
格式:update 表名 set 字段1=值1,字段2=值2,字段n=值n… where 条件
-- 将id为11的age改为35,sex改为m值
mysql> update stu set age=35,sex='m' where id=11;
Query OK, 1 row affected (0.16 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 将id值为12和14的数据值sex改为m,classid改为lamp92
mysql> update stu set sex='m',classid='lamp92' where id=12 or id=14 --等价于下面
mysql> update stu set sex='m',classid='lamp92' where id in(12,14);
Query OK, 2 rows affected (0.09 sec)
Rows matched: 2 Changed: 2 Warnings: 0
6.3删除数据
格式:delete from 表名 [where 条件]
-- 删除stu表中id值为100的数据
mysql> delete from stu where id=100;
Query OK, 0 rows affected (0.00 sec)
-- 删除stu表中id值为20到30的数据
mysql> delete from stu where id>=20 and id<=30;
Query OK, 0 rows affected (0.00 sec)
-- 删除stu表中id值为20到30的数据(等级于上面写法)
mysql> delete from stu where id between 20 and 30;
Query OK, 0 rows affected (0.00 sec)
-- 删除stu表中id值大于200的数据
mysql> delete from stu where id>200;
Query OK, 0 rows affected (0.00 sec)
七、DQL-MySQL数据查询SQL
7.1语法格式
select 字段列表|* from 表名
[where 搜索条件]
[group by 分组字段 [having 分组条件]]
[order by 排序字段 排序规则]
[limit 分页参数]
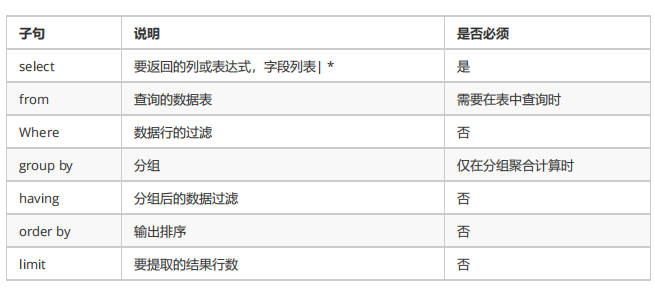
7.2基础查询
# 查询表中所有列 所有数据
select * from users;
# 指定字段列表进行查询
select id,name,phone from users;
7.3Where 条件查询
1)可以在where子句中指定任何条件
2)可以使用 and 或者 or 指定一个或多个条件
3)where条件也可以运用在update和delete语句的后面
4)where子句类似程序语言中if条件,根据mysql表中的字段值来进行数据的过滤
7.4and和or 使用时注意
select * from users where age=22 or age = 25 and sex = '女';
+------+--------+------+-------+-------+------+------+
| id | name | age | phone | email | sex | mm |
+------+--------+------+-------+-------+------+------+
| 1 | 章三 | 22 | | NULL | 男 | 0 |
| 1002 | cc | 25 | 123 | NULL | 女 | NULL |
+------+--------+------+-------+-------+------+------+
2 rows in set (0.00 sec)
-- 上面的查询结果并不符合 查询条件的要求。
-- 问题出在 sql 计算的顺序上,sql会优先处理and条件,所以上面的sql语句就变成了
-- 查询变成了为年龄22的不管性别,或者年龄为 25的女生
-- 如何改造sql符合我们的查询条件呢?
-- 使用小括号来关联相同的条件
select * from users where (age=22 or age = 25) and sex = '女';
+------+------+------+-------+-------+------+------+
| id | name | age | phone | email | sex | mm |
+------+------+------+-------+-------+------+------+
| 1002 | cc | 25 | 123 | NULL | 女 | NULL |
+------+------+------+-------+-------+------+------+
1 row in set (0.00 sec)
7.5Like 子句
-- like 语句 like某个确定的值 和。where name = '王五' 是一样
select * from users where name like '王五';
+----+--------+------+-------+-----------+------+------+
| id | name | age | phone | email | sex | mm |
+----+--------+------+-------+-----------+------+------+
| 5 | 王五 | 24 | 10011 | ww@qq.com | 男 | 0 |
+----+--------+------+-------+-----------+------+------+
1 row in set (0.00 sec)
-- 使用 % 模糊搜索。%代表任意个任意字符
-- 查询name字段中包含五的
select * from users where name like '%五%';
-- 查询name字段中最后一个字符 为 五的
select * from users where name like '%五';
-- 查询name字段中第一个字符 为 王 的
select * from users where name like '王%';
-- 使用 _ 单个的下划线。表示一个任意字符,使用和%类似
-- 查询表中 name 字段为两个字符的数据
select * from users where name like '__';
-- 查询 name 字段最后为五,的两个字符的数据
select * from users where name like '_五';
where子句中的like在使用%或者_进行模糊搜索时,效率不高,使用时注意:
1)尽可能的不去使用%或者_
2)如果需要使用,也尽可能不要把通配符放在开头处
7.6Mysql中的统计函数(聚合函数)
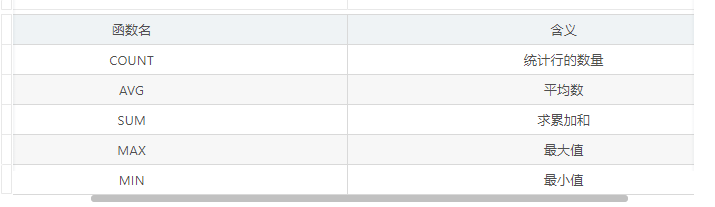
# 计算 users 表中 最大年龄,最小年龄,年龄和及平均年龄
select max(age),min(age),sum(age),avg(age) from users;
+----------+----------+----------+----------+
| max(age) | min(age) | sum(age) | avg(age) |
+----------+----------+----------+----------+
| 28 | 20 | 202 | 22.4444 |
+----------+----------+----------+----------+
-- 上面数据中的列都是在查询时使用的函数名,不方便阅读和后期的调用,可以通过别名方式 美化
select max(age) as max_age,
min(age) min_age,sum(age) as sum_age,
avg(age) as avg_age
from users;
+---------+---------+---------+---------+
| max_age | min_age | sum_age | avg_age |
+---------+---------+---------+---------+
| 28 | 20 | 202 | 22.4444 |
+---------+---------+---------+---------+
-- 统计 users 表中的数据量
select count(*) from users;
+----------+
| count(*) |
+----------+
| 9 |
+----------+
select count(id) from users;
+-----------+
| count(id) |
+-----------+
| 9 |
+-----------+
-- 上面的两个统计,分别使用了 count(*) 和 count(id),结果目前都一样,有什么区别?
-- count(*) 是按照 users表中所有的列进行数据的统计,只要其中一列上有数据,就可以计算
-- count(id) 是按照指定的 id 字段进行统计,也可以使用别的字段进行统计,
-- 但是注意,如果指定的列上出现了NULL值,那么为NULL的这个数据不会被统计
-- 假设有下面这样的一张表需要统计
+------+-----------+------+--------+-----------+------+------+
| id | name | age | phone | email | sex | mm |
+------+-----------+------+--------+-----------+------+------+
| 1 | 章三 | 22 | | NULL | 男 | 0 |
| 2 | 李四 | 20 | | NULL | 女 | 0 |
| 5 | 王五 | 24 | 10011 | ww@qq.com | 男 | 0 |
| 1000 | aa | 20 | 123 | NULL | 女 | NULL |
| 1001 | bb | 20 | 123456 | NULL | 女 | NULL |
| 1002 | cc | 25 | 123 | NULL | 女 | NULL |
| 1003 | dd | 20 | 456 | NULL | 女 | NULL |
| 1004 | ff | 28 | 789 | NULL | 男 | NULL |
| 1005 | 王五六 | 23 | 890 | NULL | NULL | NULL |
+------+-----------+------+--------+-----------+------+------+
9 rows in set (0.00 sec)
-- 如果按照sex这一列进行统计,结果就是8个而不是9个,因为sex这一列中有NULL值存在
mysql> select count(sex) from users;
+------------+
| count(sex) |
+------------+
| 8 |
+------------+
7.7Group BY 分组
group by 语句根据一个或多个列对结果集进行分组
一般情况下,是用与数据的统计或计算,配合聚合函数使用
-- 统计1班和2班的人数
select classid,count(*) from users group by classid;
+---------+----------+
| classid | count(*) |
+---------+----------+
| 1 | 5 |
| 2 | 4 |
+---------+----------+
-- 分别统计每个班级的男女生人数
select classid,sex,count(*) as num from users group by classid,sex;
+---------+------+-----+
| classid | sex | num |
+---------+------+-----+
| 1 | 男 | 2 |
| 1 | 女 | 3 |
| 2 | 男 | 2 |
| 2 | 女 | 2 |
+---------+------+-----+
# 注意,在使用。group by分组时,一般除了聚合函数,其它在select后面出现的字段列都需要出现在grouop by 后
面
Having 子句 与shere区别:
1)having类似于where,在分组聚合计算后,对结果再一次进行过滤,
2)where过滤的是行数据,having过滤的是分组数据
-- 要统计班级人数
select classid,count(*) from users group by classid;
-- 统计班级人数,并且要人数达到5人及以上
select classid,count(*) as num from users group by classid having num >=5;
7.8Order by 排序
我们在mysql中使用select的语句查询的数据结果是根据数据在底层文件的结构来排序的,
首先不要依赖默认的排序,另外在需要排序时要使用orderby对返回的结果进行排序
Asc 升序,默认
desc降序
-- 按照年龄对结果进行排序,从大到小
select * from users order by age desc;
-- 从小到大排序 asc 默认就是。可以不写
select * from users order by age;
-- 也可以按照多个字段进行排序
select * from users order by age,id; # 先按照age进行排序,age相同情况下,按照id进行排序
select * from users order by age,id desc;
7.9Limit 数据分页
limit n 提取n条数据,
limit m,n 跳过m跳数据,提取n条数据
-- 查询users表中的数据,只要3条
select * from users limit 3;
-- 跳过前4条数据,再取3条数据
select * from users limit 4,3;
-- limit一般应用在数据分页上面
-- 例如每页显示10条数据,第三页的 limit应该怎么写? 思考
第一页 limit 0,10
第二页 limit 10,10
第三页 limit 20,10
第四页 limit 30,10
-- 提取 user表中 年龄最大的三个用户数据 怎么查询?
select * from users order by age desc limit 3;
八、Mysql数据库导入导出和授权
8.1数据导出
8.1.1.数据库数据导出
导出一个库中所有数据,会形成一个建表和添加语句组成的sql文件
之后可以用这个sql文件到别的库,或着本机中创建或回复这些数据
# 不要进入mysql,然后输入以下命令 导出某个库中的数据
mysqldump -u root -p tlxy > ~/Desktop/code/tlxy.sql
8.1.2.将数据库中的表导出
# 不要进入mysql,然后输入以下命令 导出某个库中指定的表的数据
mysqldump -u root -p tlxy tts > ~/Desktop/code/tlxy-tts.sql
8.2数据导入
把导出的sql文件数据导入到mysql数据库中
# 在新的数据库中 导入备份的数据,导入导出的sql文件
mysql -u root -p ops < ./tlxy.sql
# 把导出的表sql 导入数据库
mysql -u root -p ops < ./tlxy-tts.sql
8.3权限管理 (了解)
mysql中的root用户是数据库中权限最高的用户,千万不要用在项目中。
可以给不同的用户,或者项目,创建不同的mysql用户,并适当的授权,完成数据库的相关操作
这样就一定程度上保证了数据库的安全。
创建用户的语法格式:
grant 授权的操作 on 授权的库.授权的表 to 账户@登录地址 identified by ‘密码’;
示例:
# 在mysql中 创建一个 zhangsan 用户,授权可以对tlxy这个库中的所有表 进行 添加和查询 的权限
grant select,insert on tlxy.* to zhangsan@'%' identified by '123456';
# 用户 lisi。密码 123456 可以对tlxy库中的所有表有 所有操作权限
grant all on tlxy.* to lisi@'%' identified by '123456';
# 删除用户
drop user 'lisi'@'%';

若有收获,就点个赞吧
0 人点赞
