分布式技术就是将大任务分解成多个子任务,使用多台服务器共同承担任务,让整体系统的服务能力相比于单机系统得到了大幅提升。
简单的分布式结构是怎样的?
一个完备的分布式系统会有复杂的服务管理机制,包括服务注册、服务发现、负载均衡、流量控制、远程调用和冗余备份等。在这里,我们先抛开分布式系统的实现细节,回归到它的本质,也就是从“让多台服务器共同承担任务”入手,来看一个简单的分布式检索系统是怎样工作的。
首先,我们需要一台接收请求的服务器,但是该服务器并不执行具体的查询工作,它只负责任务分发,我们把它叫作分发服务器。真正执行检索任务的是多台索引服务器,每台索引服务器上都保存着完整的倒排索引,它们都能完成检索的工作。
当分发服务器接到请求时,它会根据负载均衡机制,将当前查询请求发给某台较为空闲的索引服务器进行查询。具体的检索工作由该台索引服务器独立完成,并返回结果。但是,这种简单的分布式系统有一个问题:它仅能提升检索系统整体的“吞吐量”,而不能缩短一个查询的检索时间。
如何使用分布式系统提升单次检索的效率
当多台服务器的总内存量远远大于单机的内存时,我们可以把倒排索引拆分开,分散加载到每台服务器的内存中。这样,我们就可以避免或者减少磁盘访问,从而提升单次检索的效率了。即使原来的索引都能加载到内存中,索引拆分依然可以帮助我们提升单次检索的效率。这是因为,检索时间和数据规模是正相关的。当索引拆分以后,每台服务器上加载的数据都会比全量数据少,那每台服务器上的单次查询所消耗的时间也就随之减少了。
因此,索引拆分是检索加速的一个重要优化方案。
索引拆分
- 业务拆分
首先,在工业界中一个最直接的索引拆分思路,是根据业务进行索引拆分。但是这种方案和业务的耦合性太强,需要根据不同的业务需求灵活调整。
- 基于文档拆分
以搜索引擎为例,一个通用的方案是借鉴索引构建的拆分思路,将大规模文档集合随机划分为多个小规模的文档集合分别处理。这样我们就可以基于文档进行拆分,建立起多个倒排索引了。其中,每个倒排索引都是一个索引分片,它们分别由不同的索引服务器负责。每个索引分片只包含部分文档,所以它们的 posting list 都不会太长,这样单机的检索效率也就得到了提升。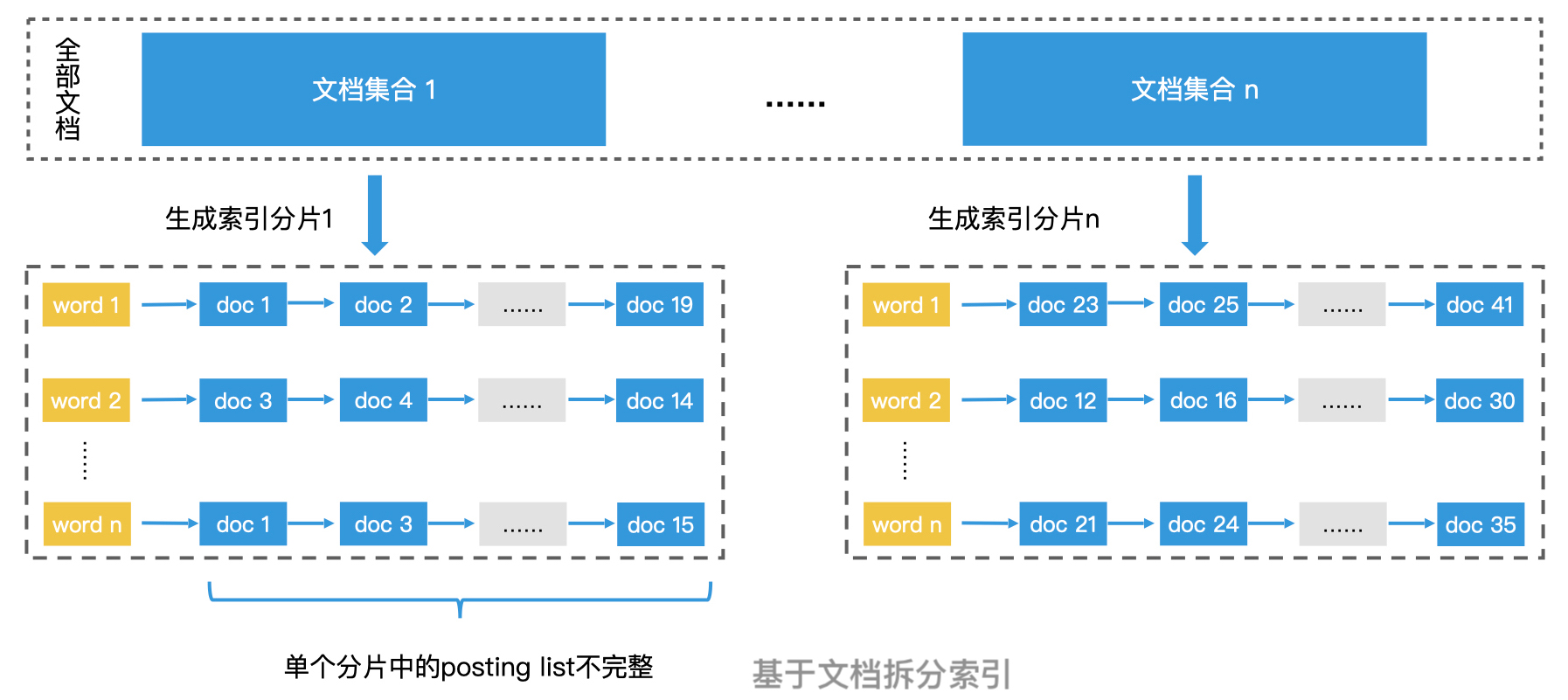
这种基于文档拆分的方案是随机划分的,所以我们可以不用关心业务细节。而且每个索引分片的大小都能足够相近,因此,这种拆分方式能很均匀地划分检索空间和分担检索负载。并且,如果我们将索引数据分成合适的份数,是有可能将所有数据都加载到内存中的。由于每个索引分片中的文档列表都不长,因此每台机器对于单个请求都能在更短的时间内返回,从而加速了检索效率。
但是,分片的数量也不宜过多。这是因为,一个查询请求会被复制到所有的索引分片上,如果分片过多的话,每台加载索引分片的服务器都要返回 n 个检索结果,这会带来成倍的网络传输开销。而且,分片越多,分发服务器需要合并的工作量也会越大,这会使得分发服务器成为瓶颈,造成性能下降。因此,对于索引分片数量,我们需要考虑系统的实际情况进行合理的设置。
- 基于关键词拆分
在搜索引擎中,为了解决分片过多导致一次请求被复制成多次的问题,我们还可以使用另一种拆分方案,那就是基于关键词进行拆分。这种方案将词典划分成多个分片,分别加载到不同的索引服务器上。每台索引服务器上的词典都是不完整的,但是词典中关键词对应的文档列表都是完整的。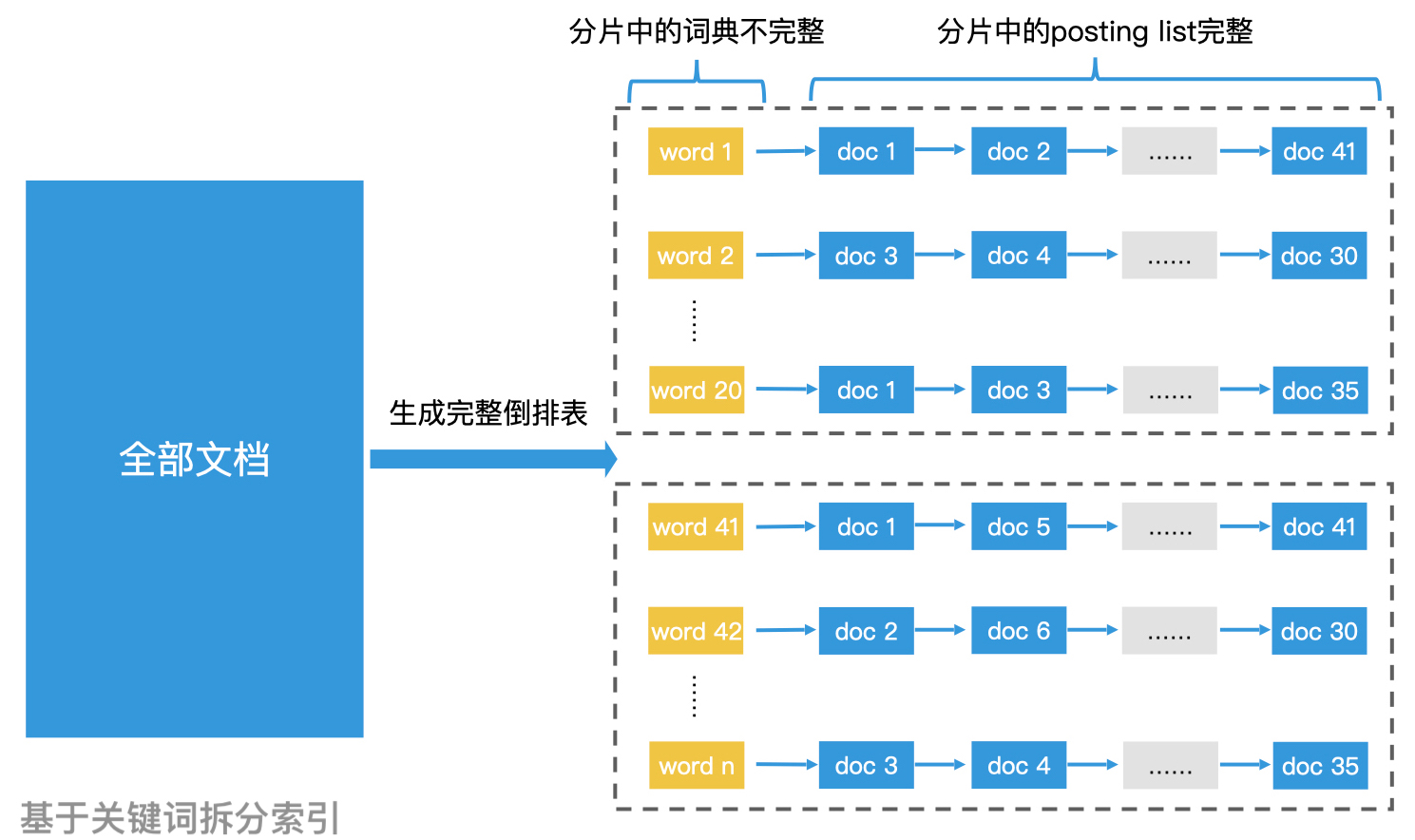
当用户查询时,如果只有一个关键词,那我们只需要查询存有这个关键词的一台索引服务器,就能得到完整的文档列表,而不需要给所有的索引服务器都发送请求;当用户同时查询两个关键词时,如果这两个关键词也同时属于一个索引分片的话,那系统依然只需要查询一台索引服务器即可。如果分别属于两个分片,那我们就需要发起两次查询,再由分发服务器进行结果合并。
也就是说,在查询词少的情况下,如果能合理分片,我们就可以大幅降低请求复制的代价了。但是这种切分方案也带来了很多复杂的管理问题,比如,如果查询词很多并且没有被划分到同一个分片中,那么请求依然会被多次复制。再比如,以及如果有的关键词是高频词,那么对应的文档列表会非常长,检索性能也会急剧下降。此外,还有新增文档的索引修改问题,系统热点查询负载均衡的问题等。
因此,除了少数的高性能检索场景有需求以外,一般我们还是基于文档进行索引拆分。这样,系统的扩展性和可运维性都会更好。
总结
利用分布式技术,我们可以将倒排索引进行索引拆分。索引拆分的好处是:一方面是能将更多的索引数据加载到内存中,降低磁盘访问次数,使得检索效率能得到大幅度的提升;另一方面是基于文档的拆分,能将一个查询请求复制成多份,由多台索引服务器并行完成,单次检索的时间也能得到缩短。
根据处理对象将倒排索引进行拆分,每个索引分片都可能有完整的词典,但 posting list 不完整,这种拆分方案叫作水平拆分。如果是根据倒排索引中的关键词进行拆分,每个索引分片的词典都不完整,但是词典中的关键词对应的 posting list 是完整的,这种拆分方案叫作垂直拆分。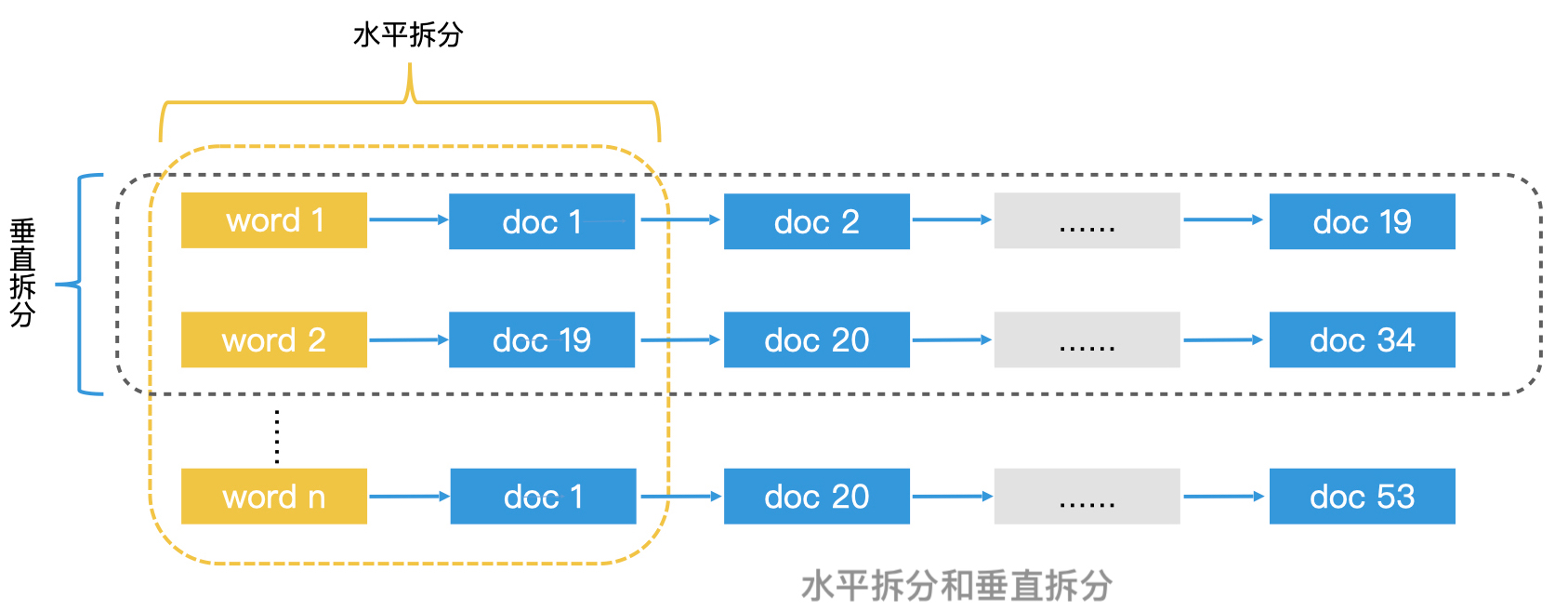
总之,合理的索引拆分是分布式检索加速的重要手段,也是工业界的有效实践经验。
讨论
为什么说基于文档拆分的方案会比基于关键词拆分的方案更好维护?你可以结合以下 2 个问题来考虑一下:
- 当有新文档加入时,会影响多少台索引服务器?
- 当某些关键词是热点,会被大量查询时,每台服务器的负载是否均衡?
答:
在更新一个文档的时候,如果是基于关键词拆分的话,由于一篇文档中会有多个关键词,这些关键词可能是分布在不同的服务器上的,因此会影响多台服务器。
至于热点查询问题,如果是基于文档拆分,那么负载会更容易均衡到多台服务器上,避免热点。如果真有热点发生时,也可以灵活地重新分片进行负载均衡。因此会比基于关键词拆分更灵活。
问:
基于文档的方案在有新文档加入时只会影响到有文档的那台服务器,基于关键词的拆分会影响到有关键词的所有服务器。
热点关键词问题我怎么觉得基于文档跟基于关键词的划分都有,并且基于文档划分的影响范围更大。因为基于文档的划分所有索引服务器都保存了完整的key,也就意味着热点key来了后会导致所有索引服务器负载高,基于热点key的划分还只会影响到热点key的那台服务器,也主要针对那些服务器加副本就可以了。
答:
对于热点的问题,如果所有的服务器的负载都同时上升,其实这是我们期望的事情,这时候没有服务器是“热点”,我们在运维时只要无差别扩容就行。
相反,如果有的服务器查询负载很低,但有的服务器查询负载很高,那么这时候就存在“热点”问题了,我们需要针对特殊的一小撮服务器进行加副本扩容。但这时候可能其他服务器其实还是足够空闲的,这就造成了资源浪费。而且,如果第二天热点切换了的话,那我们是不是还要将原热点的副本下线,然后上线其他热点的副本?这样就会给运维带来很大的复杂性。

若有收获,就点个赞吧
0 人点赞
