LSM 树(Log Structured Merge Trees),是近年来许多火热的 NoSQL 数据库中使用的检索技术,针对写大于读的场景。
为什么日志系统主要用LSM树而非B+树?
B+ 树的数据都存储在叶子节点中,而叶子节点一般都存储在磁盘中。因此,每次插入的新数据都需要随机写入磁盘,而随机写入的性能非常慢。如果是一个日志系统,每秒钟要写入上千条甚至上万条数据,这样的磁盘操作代价会使得系统性能急剧下降,甚至无法使用。
LSM树的设计思路
以块为单位写入,因为操作系统对磁盘的读写是以块为单位的,这样就大大减小了每次插入一个数据都要随机写入磁盘的性能开销。
具体实现机制
当数据写入时,延迟写磁盘,将数据先存放在内存中的树里,进行常规的存储和查询。当内存中的树持续变大达到阈值时,再批量地以块为单位写入磁盘的树中。因此,LSM 树至少需要由两棵树组成,一棵是存储在内存中较小的 C0 树,另一棵是存储在磁盘中较大的 C1 树。简单起见,接下来我们就假设只有 C0 树和 C1 树。
C1 树存储在磁盘中,因此我们可以直接使用 B+ 树来生成。而, 由于C0树完全存储在内存中, 所以B+ 树并不是最合适的选择了, 应该使用平衡二叉树甚至跳表等。但是为了更简单、清晰地理解 LSM 树的核心理念,本文所有分析假设仅有C0和C1两棵树, 且C0 树也是一棵 B+ 树。
注意: 相比于普通 B+ 树,C1 的B+ 树的所有的叶子节点都是满的。因为,C1 树不需要支持随机写入了,我们完全可以等内存中的数据写满一个叶子节点之后,再批量写入磁盘。因此,每个叶子节点都是满的,不需要预留空位来支持新数据的随机写入。
如何保证未落盘的数据的高可用?
为了保证内存中的数据在系统崩溃后能恢复,工业界会使用 WAL 技术(Write Ahead Log,预写日志技术)将数据第一时间高效写入磁盘进行备份,并在处理完成后生成检查点的机制。
- 具体实现步骤 :
- 内存中的程序在处理数据时,会先将对数据的修改作为一条记录,顺序写入磁盘的 log 文件作为备份。由于磁盘文件的顺序追加写入效率很高,因此许多应用场景都可以接受这种备份处理。
- 系统会周期性地检查内存中的数据是否都被处理完了(比如,被删除或者写入磁盘),并且生成对应的检查点(Check Point)记录在磁盘中。然后,我们就可以随时删除被处理完的数据了。这样一来,log 文件就不会无限增长了。
- 系统崩溃重启,我们只需要从磁盘中读取检查点,就能知道最后一次成功处理的数据在 log 文件中的位置。接下来,我们就可以把这个位置之后未被处理的数据,从 log 文件中读出,然后重新加载到内存中。
如何将内存数据与磁盘数据合并?
参考两个有序链表归并排序的过程,将 C0 树和 C1 树的所有叶子节点中存储的数据,看作是两个有序链表, 那滚动合并问题就变成了我们熟悉的两个有序链表的归并问题。如下图: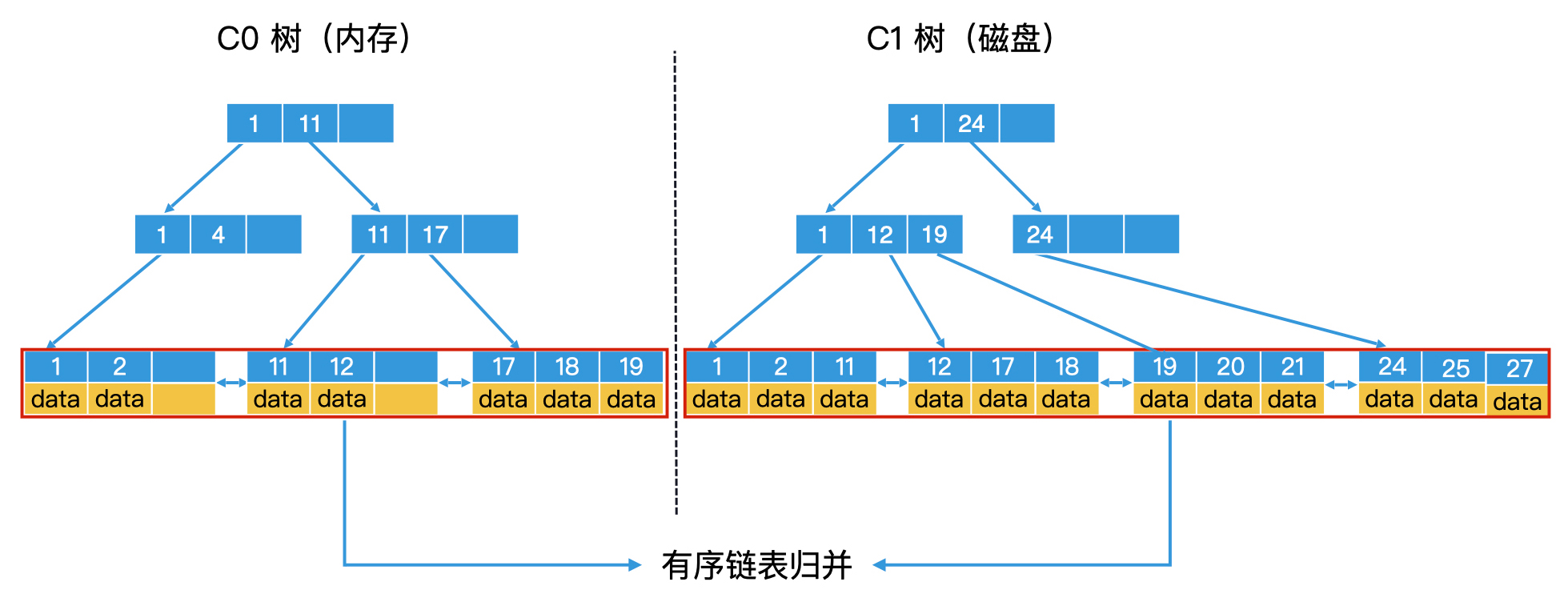
归并细节上的优化
因为涉及磁盘操作,那为了提高写入效率和检索效率,我们还需要针对磁盘的特性,在一些归并细节上进行优化。<br /> 由于磁盘具有顺序读写效率高的特性,因此,为了提高 C1 树中节点的读写性能,除了根节点以外的节点都要尽可能地存放到连续的块中,让它们能作为一个整体单位来读写。这种包含多个节点的块就叫作多页块(Multi-Pages Block)。
滚动归并详细过程
- 以多页块为单位,将 C1 树的当前叶子节点从前往后读入内存。读入内存的多页块,叫作清空块(Emptying Block),意思是处理完以后会被清空。
- 将 C0 树的叶子节点和清空块中的数据进行归并排序,把归并的结果写入内存的一个新块中,叫作填充块(Filling Block)。
- 如果填充块写满了,我们就要将填充块作为新的叶子节点集合顺序写入磁盘。这个时候,如果 C0 树的叶子节点和清空块都没有遍历完,我们就继续遍历归并,将数据写入新的填充块。如果清空块遍历完了,我们就去 C1 树中顺序读取新的多页块,加载到清空块中。
- 重复第三步,直到遍历完 C0 树和 C1 树的所有叶子节点,并将所有的归并结果写入到磁盘。这个时候,我们就可以同时删除 C0 树和 C1 树中被处理过的叶子节点。这样就完成了滚动归并的过程。
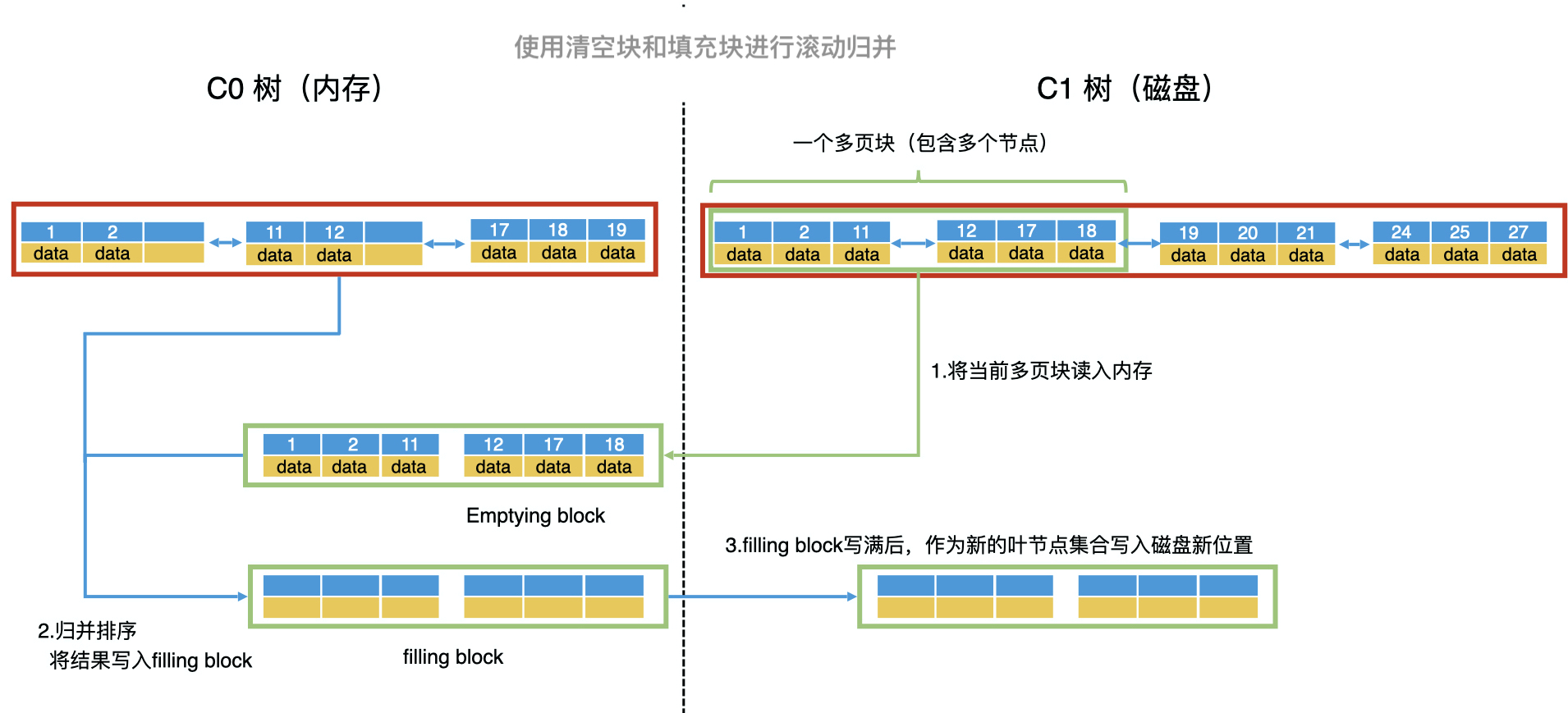
在 C0 树到 C1 树的滚动归并过程中,你会看到,几乎所有的读写操作都是以多页块为单位,将多个叶子节点进行顺序读写的。而且,因为磁盘的顺序读写性能和内存是一个数量级的,这使得 LSM 树的性能得到了大幅的提升。
LSM树的检索
因为同时存在 C0 和 C1 树,所以要查询一个 key 时,我们会先到 C0 树中查询。如果查询到了则直接返回,不用再去查询 C1 树了。而且,C0 树会存储最新的一批数据,所以 C0 树中的数据一定会比 C1 树中的新。如果一个系统的检索主要是针对近期数据的,那么大部分数据我们都能在内存中查到,检索效率就会非常高。
- LSM树的删除
一个数据已经被写入系统了,并且我们也把它写入 C1 树了。但是,在最新的操作中,这个数据被删除了,那我们自然不会在 C0 树中查询到这个数据。但由于我们不希望对 C1 树进行随机访问,所以不能立刻从 C1 树中将该条数据删除。为确保数据的一致性, LSM树的解决方案如下:
依然可以采取延迟写入和批量操作的方式。对于被删除的数据,我们会将这些数据的 key 插入到 C0 树中,并且存入删除标志。如果 C0 树中已经存有这些数据,我们就将 C0 树中这些数据对应的 key 都加上删除标志。这样一来,当我们在 C0 树中查询时,如果查到了一个带着删除标志的 key,就直接返回查询失败,我们也就不用去查询 C1 树了。在滚动归并的时候,我们会查看数据在 C0 树中是否带有删除标志。如果有,滚动归并时就将它放弃。这样 C1 树就能批量完成“数据删除”的动作。
问题集
- 当内存的C0 树满时, 都要 把磁盘的 C1 树的全部数据 加载到内存中合并生成新树吗? 我感觉这样性能不高啊。
把c1树的全部叶子节点处理一次的确效率不高,因此实际上会有多棵不同大小的磁盘上的树。包括工业界还有其他的优化思路。后面会介绍。
此外,直接把c0树的叶子节点放在c1树后面,这样的话叶子节点就不是有序的了,就无法高效检索了。
- 如果wal所在的盘和数据在同一个盘,那怎么保证wal落盘是顺序写呢,我理解也得寻道寻址
这个问题很好!我提炼出来有三个点:
1.wal的日志文件能否保证在物理空间上是顺序的?
这个是可以做到的。日志文件都是追加写模式,包括可以提前分配好连续的磁盘空间,不受其他文件干扰。因此是可以保证空间的连续性。
2.wal的日志文件和其他数据文件在一个磁盘,那么是否依然会面临磁头来回移动寻道寻址的问题?
这个问题的确存在,如果日志文件和数据文件在同一个盘上,的确可能面临一个磁头来回移动的情况。因此,尽量不要在一个磁盘上同时开太多进程太多文件进行随机写。包括你看lsm的写磁盘,也是采用了顺序写。
3.如果第二个问题存在,那么wal依然高效么?
wal依然是高效的。一方面,如果是wal连续写(没有其他进程和文件竞争磁头),那么效率自然提升;另一方面,往磁盘的日志文件中简单地追加写,总比处理好数据,组织好b+树的索引结构再写磁盘快很多。
- 两个关于检查点check point的问题。
- 检查点也是要落盘,和WAL一样的位置么?
- 在数据删除和同步到硬盘之后会生成检查点,还有其它情况会生成检查点么?
答:
1.check point的信息是独立存在的,和wal的日志文件是不同文件。
2.check point的触发条件可以有多个,比如说间隔时长达到了预定时间,比如说wal文件增长到一定程度,甚至还可以主动调用check point相关命令强制执行。
- 填充块写满了,我们就要将填充块作为新的叶节点集合顺序写入磁盘,这个时候 填充快写的磁盘位置会是之前C1 叶子节点 清空块的位置吗? 还是另外开辟有个新的空间,当新的树生成后,在把旧的C1树 磁盘数据空间在标记为删除?
答:
是新的磁盘空间。因为c1树要保证在磁盘上的连续性,如果是利用原c1树的旧空间的话,可能会放不下(因为合并了c0树的数据)。
- 如果是ssd,顺序写和随机写的差异不大,那么是否还有必要写wal, 毕竟写wal相当于double写了数据,那直接就写数据是否性能还会更好呢?
答:
对于SSD,这些理论和方法是否依然有效?答案是yes。
考虑这么两点:
1.SSD是以page作为读写单位,以block作为垃圾回收单位,因此,批量顺序写性能依然大幅高于随机写!
2.SSD的性能和内存相比依然有差距,因此,先在内存处理好,再批量写入SSD依然是高效的。

若有收获,就点个赞吧
0 人点赞
