给检索结果的排序过程装上“加速器”
对于这整个检索过程来说,精准复杂的打分开销要比排序大得多。因此,如果想更大幅度地提升检索性能,优化打分过程是一个重要的研究方向。
工业界的解决方案
其实在很多实际的应用场景中,高质量的检索结果并不一定要非常精准,我们只需要保证质量足够高的结果,被包含在最终的 Top K 个结果中就够了。这就是非精准 Top K 检索的思路。
- 非精准 Top K 检索 结合 精准 Top K 检索
在工业界中,会使用非精准 Top K 检索结合精准 Top K 检索的方案,来保证高效地检索出高质量的结果。
具体来说,就是把检索排序过程分为两个阶段:第一阶段,会进行非精准的 Top K 检索,将所有的检索结果进行简单的初步筛选,留下 k1 个结果,这样处理代价会小很多(这个阶段也被称为召回阶段);第二个阶段,就是使用精准 Top K 检索,也就是使用复杂的打分机制,来对这 k1 个结果进行打分和排序,最终选出 k2 个最精准的结果返回(这个阶段也被称为排序阶段)。
非精准 Top K 检索 具体实现
重要思路:尽可能地将计算放到离线环节,而不是在线环节。
这样,在线环节就只需要进行简单的计算,然后快速截断就可以了。一般有三种实现方法,静态质量分法、胜者表法、分层索引法。其中分层索引法最为通用。
| 方案 | 定义 | 优点 | 缺点 |
|---|---|---|---|
| 静态质量分 | 指不考虑检索结果和实时检索词的相关性,打分计算仅和结果自身的质量有关 | 没有实时的复杂运算,仅有简单的截断操作,性能开销非常小。 | 相关性精度低 |
| 胜者表 | 根据某种权重将 posting list 中的元素进行排序,并提前截取 r 个最优结果的方案 | 性能开销非常小,且排序方案更加灵活,相关性精度较高 | 提前截断是有风险的,它可能会造成归并后的结果不满 k 个,造成索引结果的丢失 |
| 分层索引 | 先相关性和结果质量给全部文档打分,然后将得分最高的 m 个文档作为高分文档,单独建立一个高质量索引,其他的文档则作为低质量索引。高质量索引和低质量索引的 posting list 都可以根据静态质量分来排序,以方便检索的时候能快速截断。 | 综合以上两种方案 | 不明 |
- 静态质量分
静态质量得分:指不考虑检索结果和实时检索词的相关性,打分计算仅和结果自身的质量有关。
也就是说,只需要根据离线算好的静态质量得分直接截断,就可以加速检索的过程了。以搜索引擎为例,可以不考虑搜索词和网页之间复杂的相关性计算,只根据网站自身的质量打分排序。比如说,使用 Page Rank 算法(Google 的核心算法,通过分析网页链接的引用关系来判断网页的质量)离线计算好每个网站的质量分,当一个搜索词要返回多个网站时,只需要根据网站质量分排序,将质量最好的 Top K 个网站返回即可。
不过,为了能快速返回 Top K 个结果,我们需要改造一下倒排索引中的 posting list 的组织方式。倒排索引的 posting list 都是按文档 ID 进行排序的。如果希望根据静态质量得分快速截断的话,那就应该将 posting list 按照静态质量得分,由高到低排序。对于分数相同的文档,再以文档 ID 二次排序。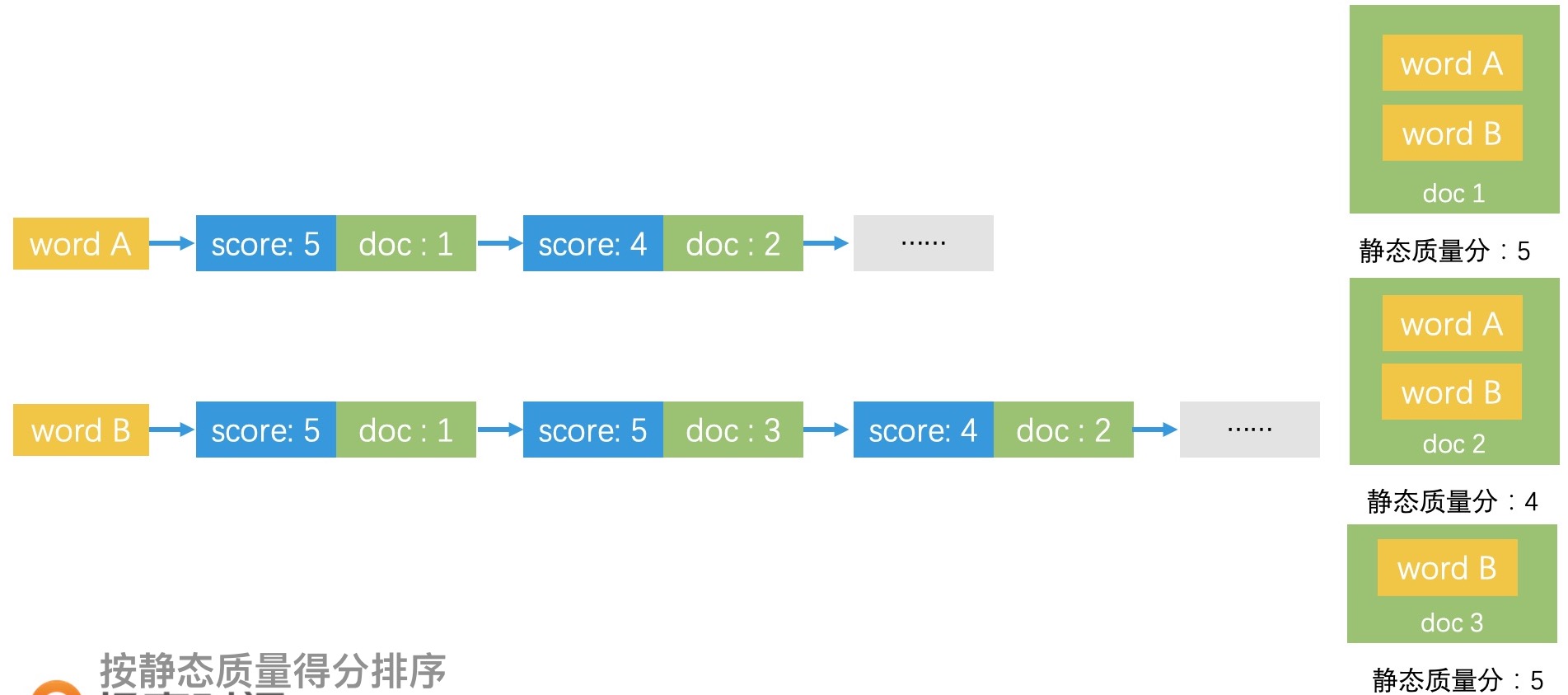
这样一来,在检索的时候,如果只有一个关键词,那只需要查出该关键词对应的 posting list,截取前 k 个结果即可。但是如果要同时查询两个关键词,截断的过程就会复杂一些。尽管比较复杂,我们可以总结为两步:第一步,取出这两个关键词的 posting list,但不直接截断;第二步,对这两个 posting list 归并排序。留下分数和文档 ID 都相同的条目作为结果集合(为什么还需要id相同?因为,分数相同是id相同的充分不必要条件),当结果集合中的条目达到 k 个时,就直接结束归并。如果是查询多个关键词,步骤也一样。
那在这个过程中,为什么可以对这两个 posting list 进行归并排序呢?这是因为文档是严格按照静态质量得分排列的。如果文档 1 的分数大于文档 2,那在这两个 posting list 中文档 1 都会排在文档 2 前面。而且,对于分数相同的文档,它们也会按照 ID 进行二次排序。所以,任意的两个文档在不同的 posting list 中,是会具有相同的排序次序的。也因此,可以使用归并的方式来处理这两个 posting list。
使用静态质量得分选取非精准 Top K 个结果的过程中,因为没有实时的复杂运算,仅有简单的截断操作,所以它和复杂的精准检索打分相比,开销几乎可以忽略不计。因此,在对相关性要求不高的场景下,如果使用静态质量得分可以满足系统需求,这会是一个非常合适的方案。
- 胜者表
词频可以代表关键词在文档中的重要性,而且,词频的计算是在索引构建的时候,也就是在离线环节完成的,并且它还可以直接存储在 posting list 中。
但是,由于此时的posting list 排序是按照TF,而需要归并的posting确是按照其文档id相同来进行归并的。因此归并相同文档是无法使用快速归并法的。 快速归并的前提条件是:必须要保证各参与归并的链表的归并条件元素要有序,即也就是此处的文档id必须保证有序。那如何才能做到既用上词频的分值,又保持 ID 有序呢?
一般,先 从posting list中根据词频大小选出远多于 k 的前 r 个结果,然后将这 r 个结果按文档 ID 排序,这样就兼顾了相关性和快速归并截断的问题。这种根据某种权重将 posting list 中的元素进行排序,并提前截取 r 个最优结果的方案,就叫作胜者表。
胜者表的优点在于,它的排序方案更加灵活。比如说,我可以同时结合词频和静态质量得分进行排序(比如说权重 = 词频 + 静态质量得分),这样就同时考虑了相关性和结果质量两个维度。然后,对于每个 posting list 提前截断 r 个结果,再按文档 ID 排序即可。
但是有一点需要注意,胜者表的提前截断是有风险的,它可能会造成归并后的结果不满 k 个。比如说,文档 1 同时包含关键词 A 和 B,但它既不在关键词 A 的前 r 个结果中,也不在关键词 B 的前 r 个结果中,那它就不会被选出来。在极端情况下,比如,关键词 A 的前 r 个结果都是仅包含 A 的文档,而关键词 B 的前 r 个结果都是仅包含 B 的文档,那关键词 A 和 B 的前 r 个结果的归并结果就是空的!这就会造成检索结果的丢失。
- 分层索引
对于胜者表可能丢失检索结果的问题,有一种更通用的解决方案:分层索引。可以同时考虑相关性和结果质量,用离线计算的方式先给所有文档完成打分,然后将得分最高的 m 个文档作为高分文档,单独建立一个高质量索引,其他的文档则作为低质量索引。高质量索引和低质量索引的 posting list 都可以根据静态质量得分来排序,以方便检索的时候能快速截断。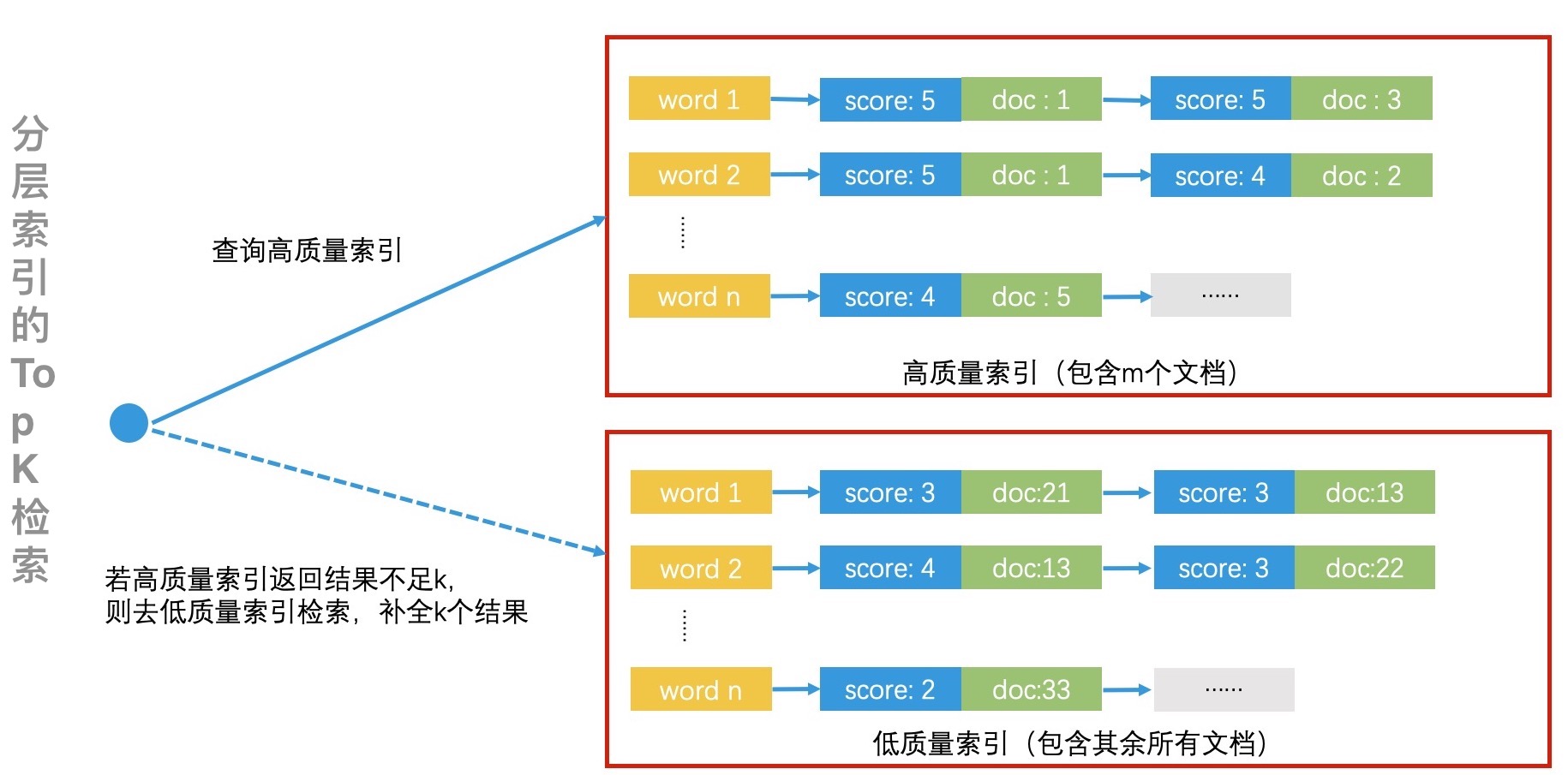
检索的时先去高质量索引中查询,如果高质量索引中可以返回的结果大于 k 个,直接截取 Top K 个结果返回即可;如果高质量索引中的检索结果不足 k 个,再去低质量索引中查询,补全到 k 个结果,然后终止查询。通过这样的分层索引,就能快速地完成 Top K 的检索了。
分层索引还可以看作是一种特殊的索引拆分,它可以和我们前面学过的索引拆分技术并存。比如说,对于高质量索引和低质量索引,我们还可以通过文档拆分的方式,将它们分为多个索引分片,使用分布式技术来进一步加速检索。
扩展
到这里,非精准 Top K 检索的三种实现方法都讲完了。总结来说,这些方法都是把非精准 Top K 检索应用在了离线环节,实际上,非精准 Top K 检索的思想还可以拓展应用到在线环节。即,还能在倒排检索结束后,精准打分排序前,插入一个“非精准打分”环节,让我们能以较低的代价,快速过滤掉大部分的低质量结果,从而降低最终进行精准打分的性能开销。
除此之外,我还想补充一点。我们说的“非精准打分”和“精准打分”其实是相对的。这怎么理解呢?举个例子,如果我们的“精准打分”环节采用的是传统的机器学习打分方式,如逻辑回归、梯度下降树等。那“非精准打分”环节就可以采用相对轻量级的打分方案,比如说采用 TF-IDF 方案,甚至是 BM25 方案等。而如果“精准打分”环节采用的是更复杂的深度学习的打分方式,比如使用了 DNN 模型,那么相对来说,“非精准打分”环节就可以采用逻辑回归这些方案了。所以说,无论非精准打分的方案是什么,只要和精准打分相比,“能使用更小的代价,快速减少检索范围”,这就足够了。而这也是在前面多次出现过的检索加速的核心思想。
总结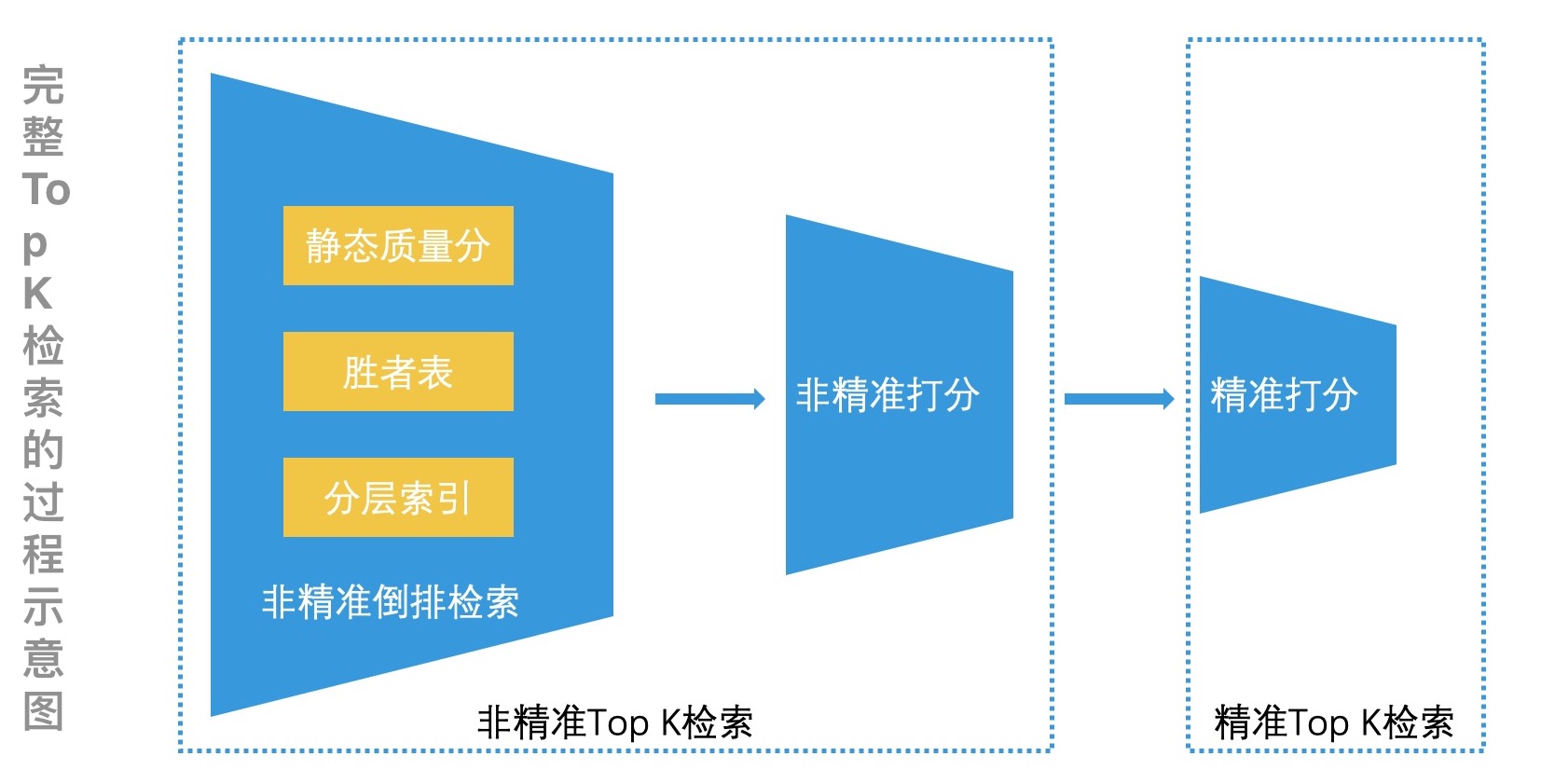
讨论
在分层索引中,posting list 中的文档为什么还要根据静态质量得分排序?排序应该是升序还是降序?
答:
分层索引大概率只扫描第一层就能得到top k。因此,在第一层索引候选集充足的情况下,采用静态质量分降序,能更快进行top k截断,而不需要完整检索完第一层索引,从而达到检索加速的目的。

若有收获,就点个赞吧
0 人点赞
