如何生成大于内存容量的倒排索引?
主要思路:将大任务分解为多个小任务,最终根据 key 来归并。具体步骤如下:
分割文档集合
对于大规模的文档集合,可以将它均匀划分割成多个小规模文档集合,便可以在多个分布式节点的内存中建立倒排索引了。即使分割后的文档集合生成的倒排索引中,完整的词典中term的数量也会非常大,所以为了方便后续的处理,我们不仅会为词典中的每个term编号,还会把每个term对应的字符串存储在词典中。
生成临时倒排文件(硬盘)
接下来,我们需要将内存中的倒排索引存入磁盘,生成一个临时倒排文件。我们先将内存中的Posting list 按照对应的term的字符串长度从小到大进行排序,然后将term以及对应的Posting list 作为一条记录写入临时倒排文件。这样一来,临时文件中的每条记录就都是有序的了。
而且,在临时倒排文件中,我们并不需要存储term的编号。原因在于每个临时倒排文件的编号都是局部的,并不是全局唯一的,不能作为最终的唯一编号,所以无需保存。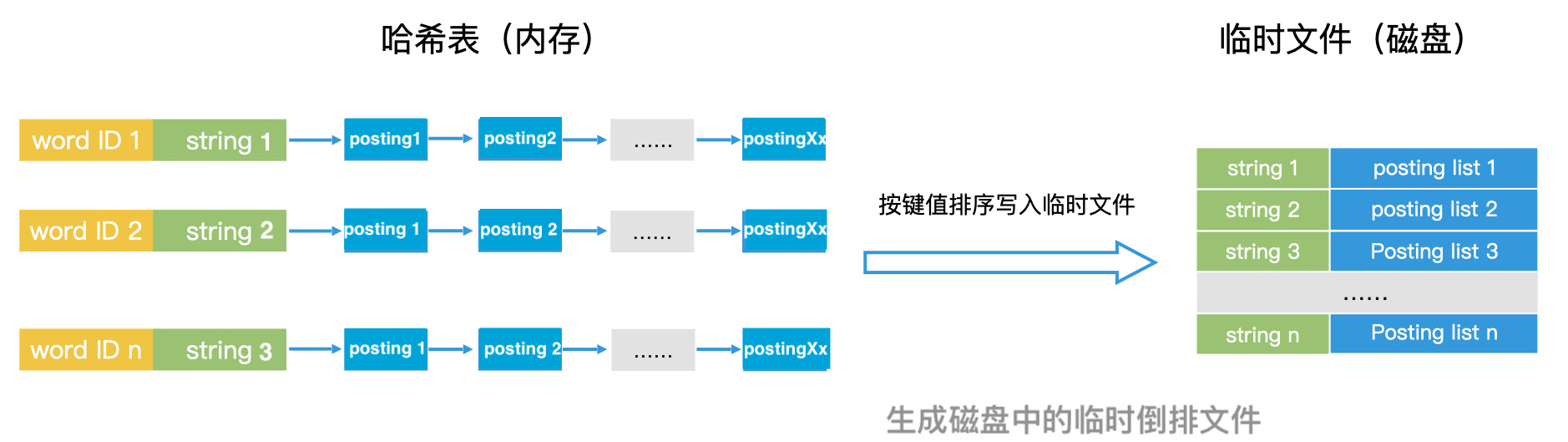
我们依次处理每一批小规模的文档集合,为每一批小规模文档集合生成一份对应的临时文件。等文档全部处理完以后,我们就得到了磁盘上的多个临时文件。合并临时倒排文件
由于文档被分割,所以每个临时倒排文件中可能会出现重复的term。此时我们使用多路归并技术将磁盘中的多个临时倒排文件合并为一个整体倒排文件。因为每个临时倒排文件里的每一条记录都是根据关键词有序排列的,所以我们在做多路归并的时候,需要先将所有临时文件当前记录的关键词取出。如果关键词相同的,我们就可以将对应的 posting list 读出,然后合并。
如果 posting list 可以完全读入内存,那我们就可以直接在内存中完成合并,然后把合并结果作为一条完整的记录写入最终的倒排文件中;如果 posting list 过大无法装入内存,但 posting list 里面的元素本身又是有序的,我们也可以将 posting list 从前往后分段读入内存进行处理,直到处理完所有分段。这样我们就完成了一条完整记录的归并。
每完成一条完整记录的归并,我们就可以为这一条记录的关键词赋上一个编号,这样每个关键词就有了全局唯一的编号。重复这个过程,直到多个临时文件归并结束,这样我们就可以得到最终完整的倒排文件。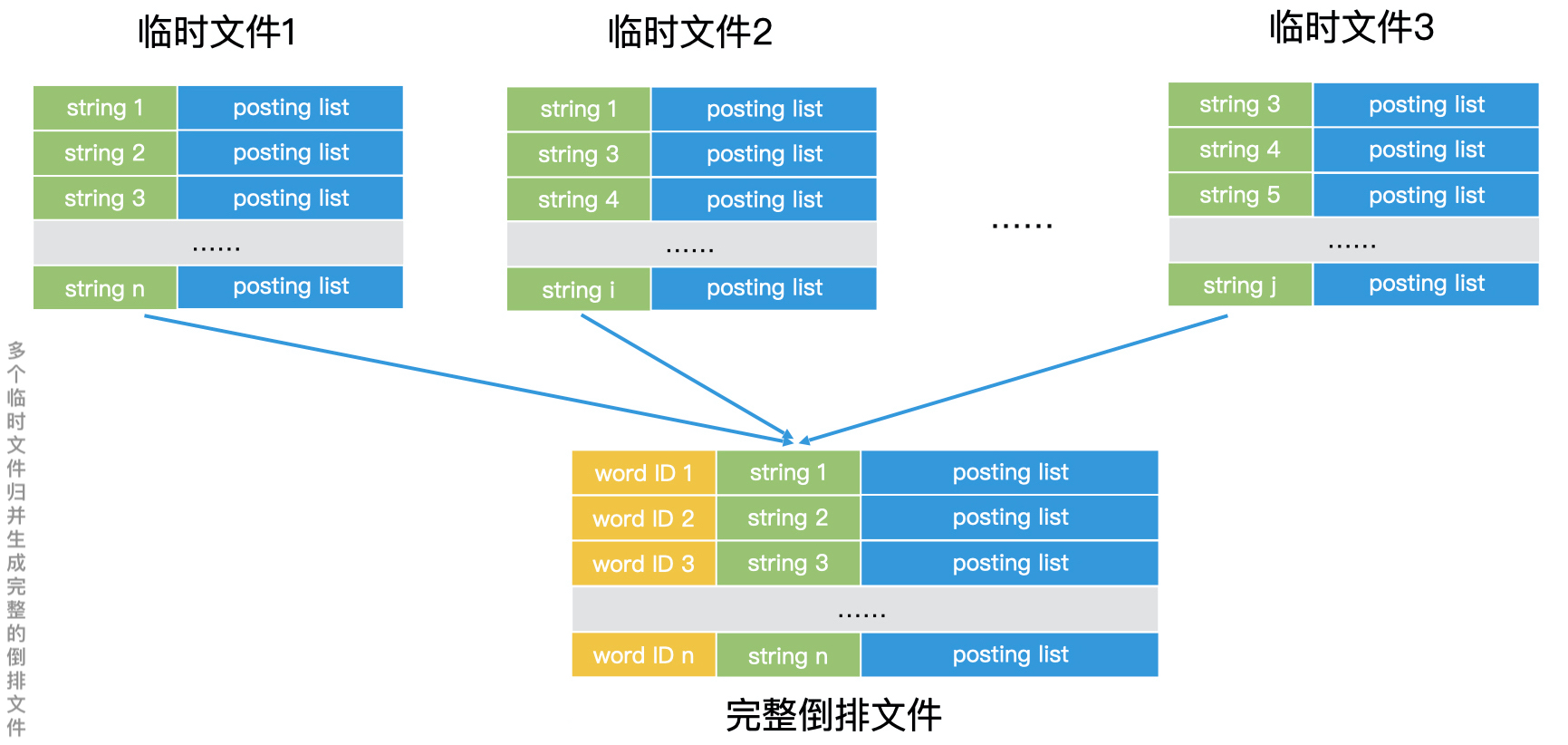
这种将大规模文档拆分成多个小规模文档集合,再生成倒排文件的方案,其实和分布式计算 Map Reduce 的思路是十分相似的,它可以非常方便地迁移到 Map Reduce 的框架上,在多台机器上同时运行,大幅度提升倒排文件的生成效率。
如何检索磁盘上的大规模倒排文件?
那对于这样一个大规模的倒排文件,我们在检索的时候是怎么使用的呢?其实,使用的时候有一条核心原则,那就是内存的检索效率比磁盘高许多,因此,能加载到内存中的数据,我们要尽可能加载到内存中。
如果词典数量不大,可以使用哈希表结构将其全部加载到内存中,那么查询时,通过检索内存中的哈希表,我们就能找到对应的 term,然后将term 对应在磁盘中的 postling list 读到内存中进行处理。(哈希表的key,是term的哈希值,value则是term的字符串。当然,由于我们还需要得到pos,因此,value其实应该是一个结构体,即保存了字符串,又保存了pos(term对应的posting list在磁盘中的位置)。)
如果词典本身也很大,只能存储在磁盘,无法加载到内存中。可以将词典看作一个有序的 key 的序列,我们完全可以用 B+ 树来完成词典的检索。如下图: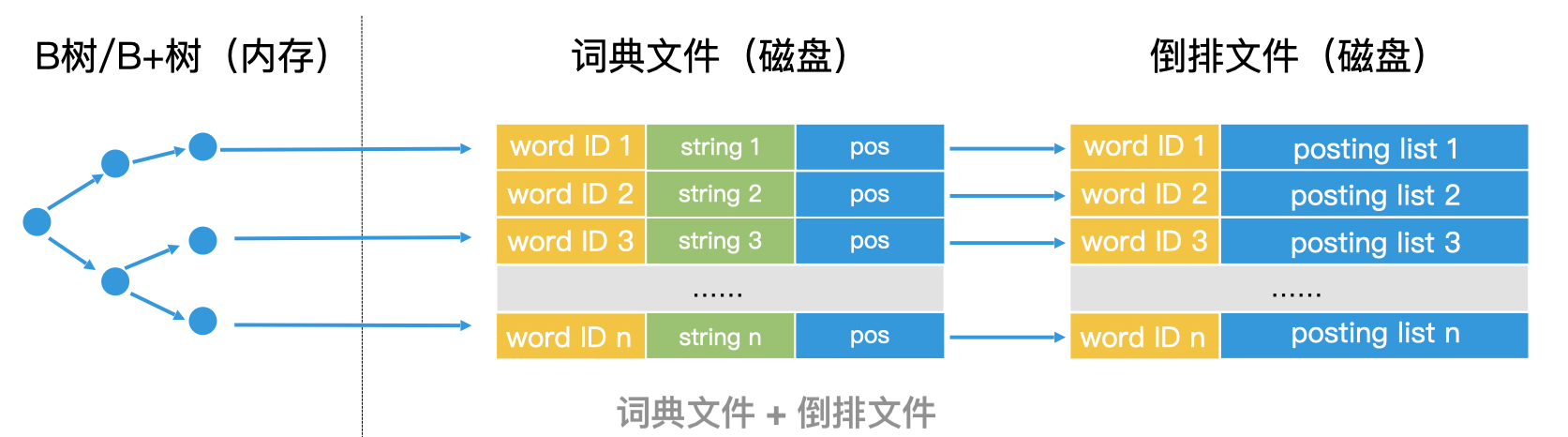
这样一来,我们就可以把检索过程总结成两个步骤。第一步,我们使用 B+ 树或类似的技术,查询到对应的词典中的关键字。第二步,我们将这个关键字对应的 posting list 读出,在内存中进行处理。
注意:如果 posting list 非常长,它是很有可能无法加载到内存中进行处理的。这个问题在本质上和词典无法加载到内存中是一样的。而且,posting list 中的数据也是有序的。因此,我们完全可以对长度过大的 posting list 也进行类似 B+ 树的索引,只读取有用的数据块到内存中,从而降低磁盘访问次数。包括在 Lucene 中,也是使用类似的思想,用分层跳表来实现 posting list,从而能将 posting list 分层加载到内存中。而对于长度不大的 posting list,我们仍然可以直接加载到内存中。
此外,如果内存空间足够大,我们还能使用缓存技术,比如 LRU 缓存,它会将频繁使用的 posting list 长期保存在内存中。这样一来,当需要频繁使用该 posting list 的时候,我们可以直接从内存中获取,而不需要重复读取磁盘,也就减少了磁盘 IO,从而提升了系统的检索效率。同时,索引压缩也是一个重要的研究方向,目前有很多成熟的技术可以实现对词典和对文档列表的压缩。比如说在 Lucene 中,就使用了类似于前缀树的技术 FST,来对词典进行前后缀的压缩,使得词典可以加载到内存中。
讨论
词典如果能加载在内存中,就会大幅提升检索效率。在哈希表过大无法存入内存的情况下,我们是否还有可能使用其他占用内存空间更小的数据结构,来将词典完全加载在内存中?有序数组和二叉树是否可行?为什么?
答:
在无压缩的情况下:对于Hash表的存储而言,数据量大的是value,是内容,也就是词项字符串。对于二叉树而言,内容的内存占用并没有减少,但是求交集的操作比链表复杂些。
数组当然可以直接存储,但是内容太大的情况下,占用的连续内存太大了,可能会导致内存申请失败。
1.使用数组存每个词项,这个需要解决每个词项长度不同的问题,一个思路是使用最长的词项作为数组每个元素的大小(比如说每个元素都是20个字节)。这样就可以用数组存储和查找了。
2.第一种方法空间会浪费,因此,改进方案可以另外开一个char数组,将所有字符串挨个紧凑存入;然后索引数组每个元素都是int 32类型,指向char数组中对应词项的初始位置。这样空间就都是紧凑的了。这就是使用数组的方案。
如果char数组可能无法申请连续空间,那么我们可以将char数组分段即可。如果再深入思考,你会发现char数组中好多字符都是重复的,这时候压缩重复字符的前缀树就出来了。这就是用非连续的空间,用树来组织和压缩的方案。

若有收获,就点个赞吧
0 人点赞
