定义
根据具体内容或属性反过来索引文档标题的结构,我们就叫它倒排索引(Inverted Index)。在倒排索引中,key 的集合叫作字典(Dictionary),一个 key 后面对应的记录集合叫作记录列表(Posting List)。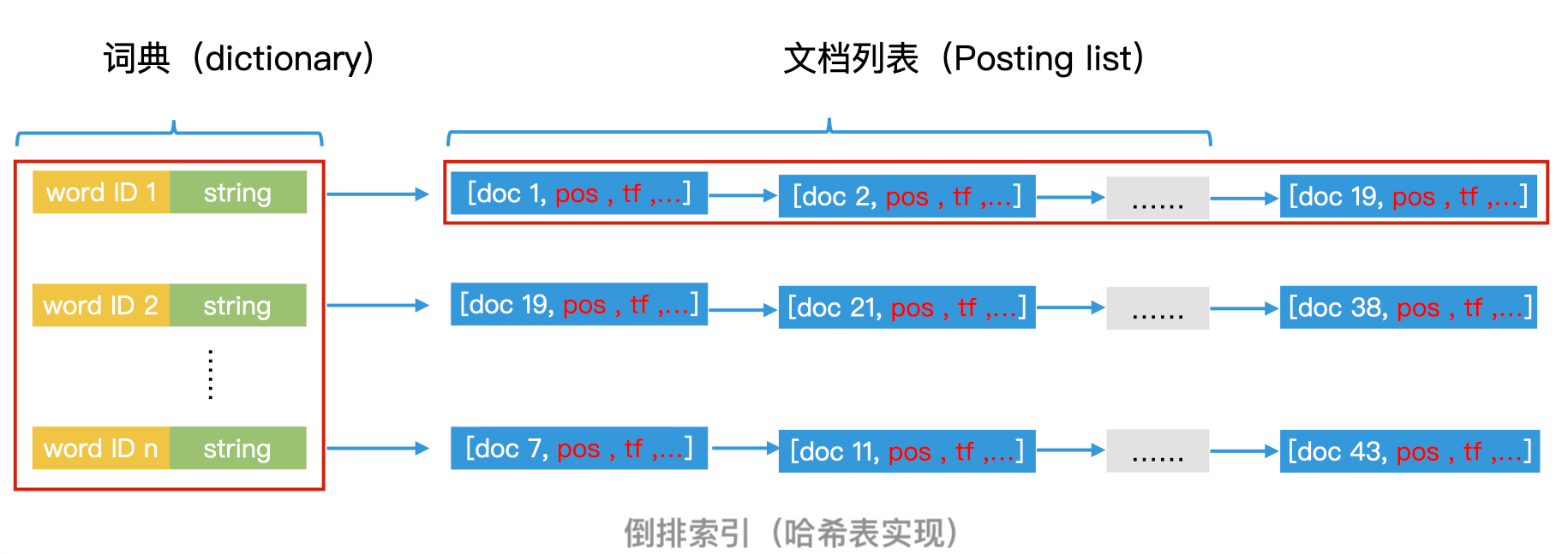
倒排索引的创建过程
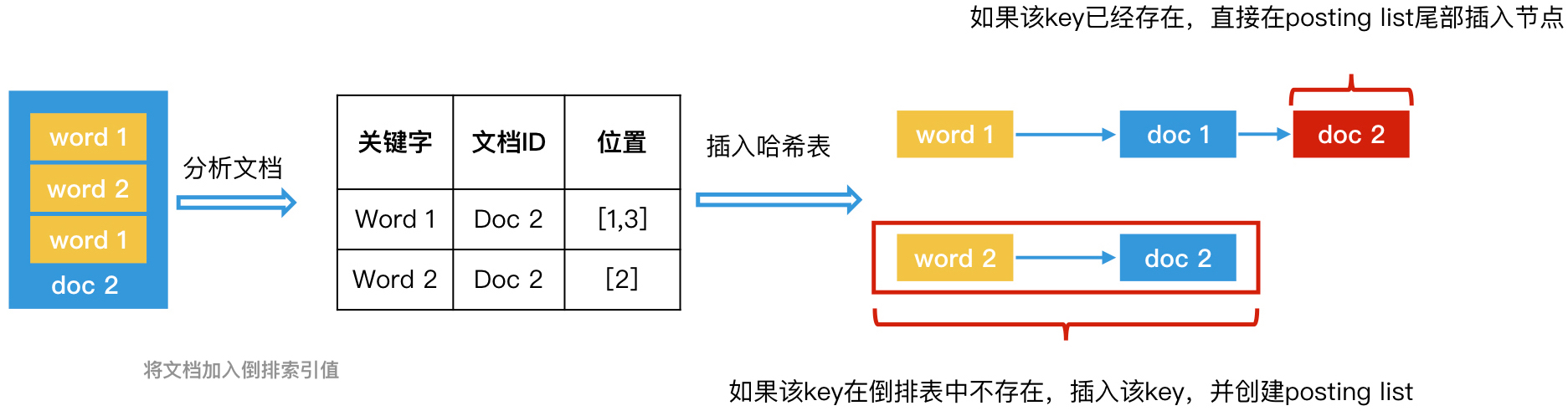
- 给每个文档编号,作为其唯一的标识,并且排好序,然后开始遍历文档(此处排序的主要目的是为了保证在接下来的文档遍历过程中生成的Posting Lits是有序的,也就可以实现快速归并了)。
- 解析当前文档中的每个关键字,生成 < term>: <文档 ID,词频(TF),位置(position),偏移量(offset) > 这样的数据对。
- 将关键字作为 key 插入哈希表。如果哈希表中已经有这个 key 了,我们就在对应的 posting list 后面追加节点,记录该文档 ID(关键字的位置信息如果需要,也可以一并记录在节点中);如
- 果哈希表中还没有这个 key,我们就直接插入该 key,并创建 posting list 和对应节点。
- 重复第 2 步和第 3 步,处理完所有文档,完成倒排索引的创建。
归并
查询同时含有“极”字和“客”字两个 key 的文档,通过分别查找这两个term可以得到其对应的两个PostingList A、B。如果 A 和 B 都是无序链表,那我们只能将 A 链表和 B 链表中的每个元素分别比对一次,这个时间代价是 O(mn)。但是,如果两个链表都是有序的,我们就可以用*归并排序的方法来遍历 A 和 B 两个链表,时间代价会降低为 O(m + n),其中 m 是链表 A 的长度,n 是链表 B 的长度。
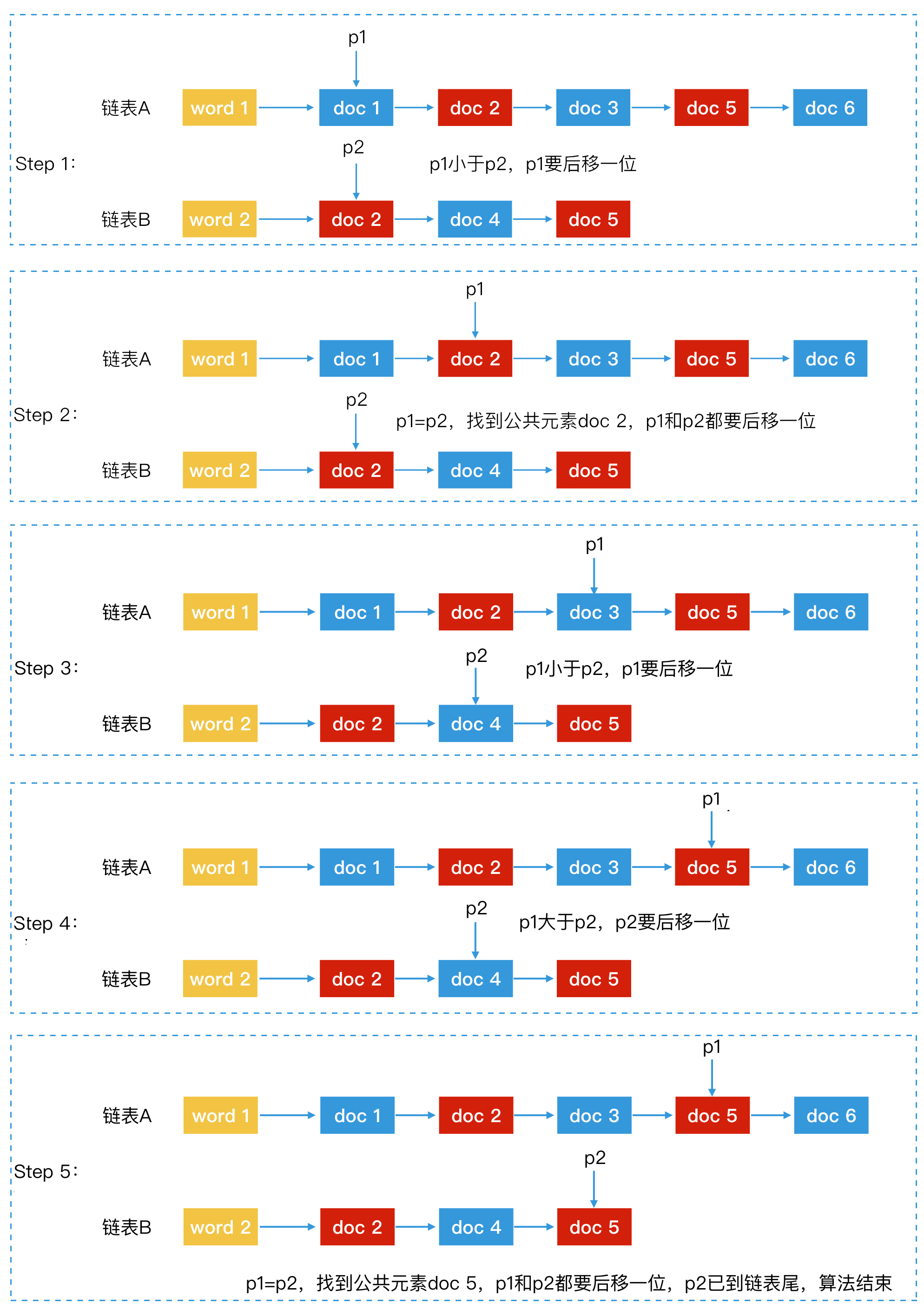
- 链表归并的过程:
- 使用指针 p1 和 p2 分别指向有序链表 A 和 B 的第一个元素。
对比 p1 和 p2 指向的节点是否相同,这时会出现 3 种情况:
1). 两者的 **id 相同**,说明该节点为公共元素,直接将该节点加入归并结果。然后,p1 和 p2 要同时后移,指向下一个元素;<br /> 2). p1 元素的 id 小于 p2 元素的 id,p1 后移,指向 A 链表中下一个元素;<br /> 3). p1元素的 id 大于 p2 元素的 id,p2 后移,指向 B 链表中下一个元素。
重复第 2 步,直到 p1 或 p2 移动到链表尾为止。
使用这个归并思路还可以用来求集合合并中的并集和差集问题。它们的具体实现方法和上述求交集的实现方法差不多,也是通过遍历链表对比的方式来完成的。此外,在实际应用中,我们可能还需要对多个 key 进行联合查询。比如说,要查询同时包含“极”“客”“时”“间”四个字的诗。这个时候,我们利用多路归并的方法,同时遍历这四个关键词对应的 posting list 即可。

若有收获,就点个赞吧
0 人点赞
