- 1 Linux的安装
- 2 JDK安装
- 3 设置SSH无密码登录
- 4 安装Hadoop
- 5 配置Hadoop环境变量
- 6 修改Hadoop配置设置文件
- 7 创建并格式化HDFS目录
- 8 启动Hadoop
- 9 Hadoop ResourceManager Web界面查看Hadoop运行状态:node、application和status.
- 10 Hadoop集群的搭建
- 11 spark集群的搭建
- 12 Anaconda安装
- 13 利用ipython notebook(jupyter notebook)使用spark
- 14 使用Ipython Notebook在Hadoop YARN-client模式运行Spark程序
- 15 使用Ipython Notebook在Spark Stand Alone模式下运行
- 16 总结:不同模式下运行ipython notebook
- 17 Pycharm搭建PySpark集成开发环境
Oracle VM VirtualBox虚拟机安装,请自行百度!!!
1 Linux的安装
可以选择国内的一个镜像,清华大学镜像
选择Ubuntu下载:https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/14.04.5/ubuntu-14.04.5-desktop-amd64.iso
安装,请网上搜索。因为装的是Deskop版,可以选择安装增强功能、默认输入法、设置“终端”程序、设置“终端”程序为白底黑字、设置共享剪切板以及设置最佳下载服务器。
温馨提示:在学习本文之前,请读者熟悉Linux系统下的常用命令,如果不会或者不熟练,请网上或者查阅相关书籍,熟练后再来查看本文。
打开“终端”切换用户(在root用户下工作)sudo passwd root输入密码su rootcd ~
2 JDK安装
实际操作中,有时候会出现jdk版本不一致,hadoop启动不了,建议读者
自己去官网下载:
cd /optwget http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jdk-8u161-linux-x64.tar.gztar -zxvf jdk-8u161-linux-x64.tar.gzmv jdk1.8.0_161 /usr/lib/jdk
3 设置SSH无密码登录
Hadoop是由很多台服务器所组成的,当启动Hadoop系统时,NameNode必须与DataNode连接并管理这些节点(DataNode)。此时系统会要求我们输入密码,为了让系统顺利运行而不需要手动输入密码,需要将SSH设置成为无密码登录。(无密码登录是以事先交换的SSH Key秘钥来进行身份登录)。Hadoop使用SSH(Secure Shell)连接,目前是最可靠、专为远程登录其他服务器提供的安全性协议。
# 安装SSHapt-get install ssh# 安装rsyncapt-get install rsync# 产生SSH Key秘钥进行后续身份验证ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa# 查看目录(在root目录的跟目录下,/root /.ssh/)ll ~/.ssh# 将产生的Key放置到许可证文件中cd /root/.ssh/cat id_dsa.pub >> authorized_keys
4 安装Hadoop
# 建议读者专门建立一个存放应用程序安装包文件夹,本文使用的是/opt,进入/opt目录下cd /opt# 下载Hadoop: http://hadoop.apache.org/wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz# 解压缩tar -zxvf hadoop-2.7.5.tar.gz# 移动hadoop到/usr/local/hadoopmv hadoop-2.7.5 /usr/local/hadoop# 查看hadoop安装目录/usr/local/hadoopll /usr/local/hadoop
5 配置Hadoop环境变量
# 编辑~/.bashrc(这样每次开机登录都会自动运行环境变量设置)nano ~/.bashrc
输入以下内容:
# 设置JDK安装路径export JAVA_HOME=/usr/lib/jdk# 设置HADOOP_HOME为Hadoop的安装路径/usr/local/hadoopexport HADOOP_HOME=/usr/local/hadoop# 设置PATH,这样在其他目录时仍然可以运行Hadoopexport PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin# 设置Hadoop其他环境变量export HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOME# 链接库的相关设置export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY
让~/.bashrc生效
source ~/.bashrc
6 修改Hadoop配置设置文件
主要包括:hadoop-env.sh、core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml
(1)设置hadoop-env.sh文件
nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/usr/lib/jdk
(2)设置core-site.xml
nano /usr/local/hadoop/etc/hadoop/core-site.xml
设置HDFS的默认名称:
<configuration><property><name>fs.default.name</name><value>hdfs://localhost:9000</value></property></configuration>
(3)设置yarn-site.xml
nano /usr/local/hadoop/etc/hadoop/yarn-site.xml
在之间输入:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>
(4)设置mapred-site.xml
mapred-site.xml用于设置监控Map与Reduce程序的JobTracker任务分配情况以及TaskTracker任务运行情况。Hadoop提供了设置的模板文件,可以自行复制修改。
cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xmlnano /usr/local/hadoop/etc/hadoop/mapred-site.xml
在之间输入:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
(5)hdfs-site.xml
hdfs-site.xml用于设置HDFS分布式文件系统.
nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml
在之间输入,默认的blocks副本备份数量是每一个文件在其他node的备份数量,默认值为3。
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value></property></configuration>
7 创建并格式化HDFS目录
# 创建namenode数据存储目录mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode# 创建datanode数据存储目录mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode# 将Hadoop的所有者更改为rootchown root:root -R /usr/local/hadoop# 格式化HDFS,如果HDFS已有数据,格式化操作会删除所有的数据hadoop namenode -format
8 启动Hadoop
分别启动HDFS和YARN,使用start-dfs.sh(启动HDFS)和使用start-yarn.sh(启动YARN)
同时启动HDFS和YARN,使用start-all.sh
# 启动HDFSstart-dfs.sh# 启动YARNstart-yarn.sh# 或者同时启动HDFS和YARN# start-all.sh# 使用jps查看已经启动的进程,查看NameNode和DataNode进程是否启动jps
HDFS功能:NameNode、SecondaryNameNode和DataNode
YARN功能:ResourceManager、NodeManager
9 Hadoop ResourceManager Web界面查看Hadoop运行状态:node、application和status.
http://localhost:8088/cluster# http://192.168.111.226:8088/cluster NameNode# http://192.168.111.227:8088/cluster SecondaryNameNode
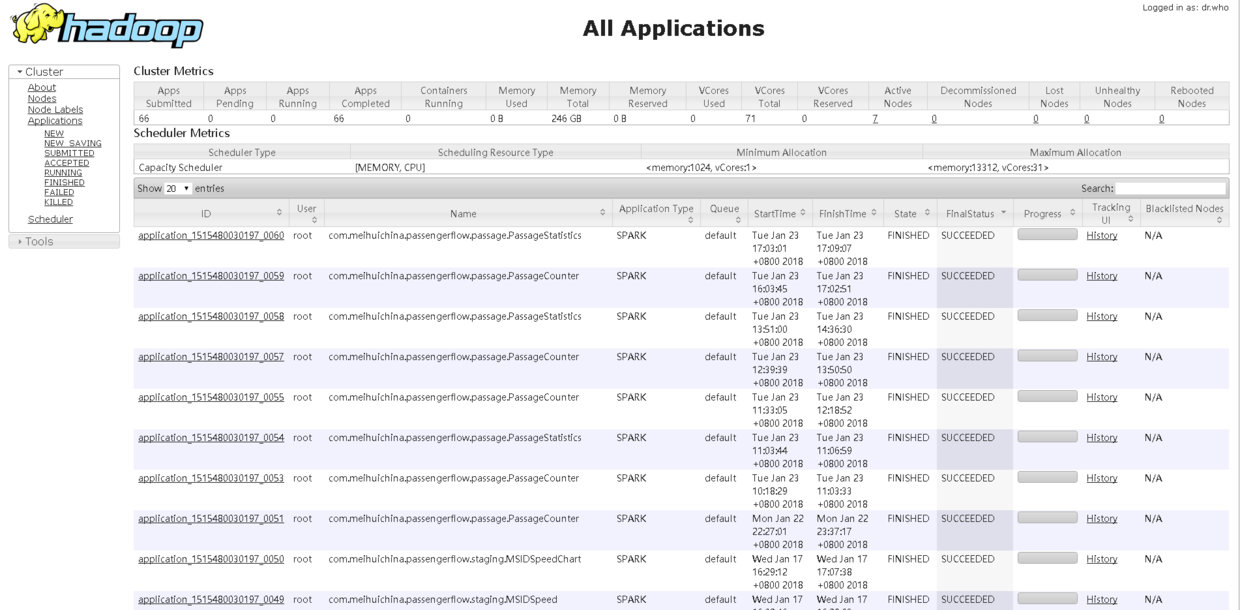
9.1 查看已经运行的节点Nodes
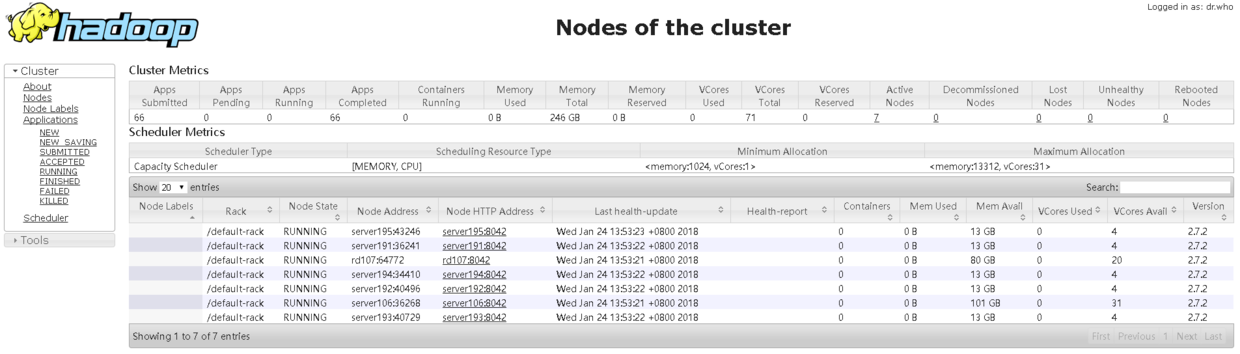 3-Spark集群的搭建
3-Spark集群的搭建
9.2 查看NameNode HDFS Web界面
http://localhost:50070# http://192.168.111.226:50070
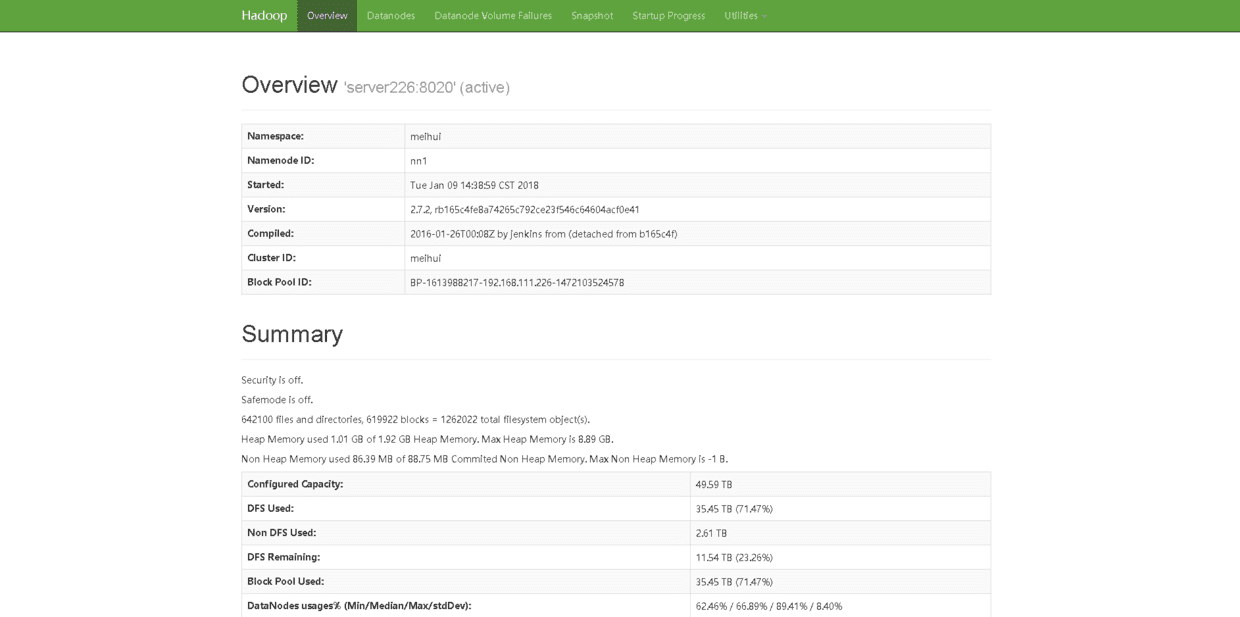
9.3 查看Live Nodes

9.4 查看DataNode
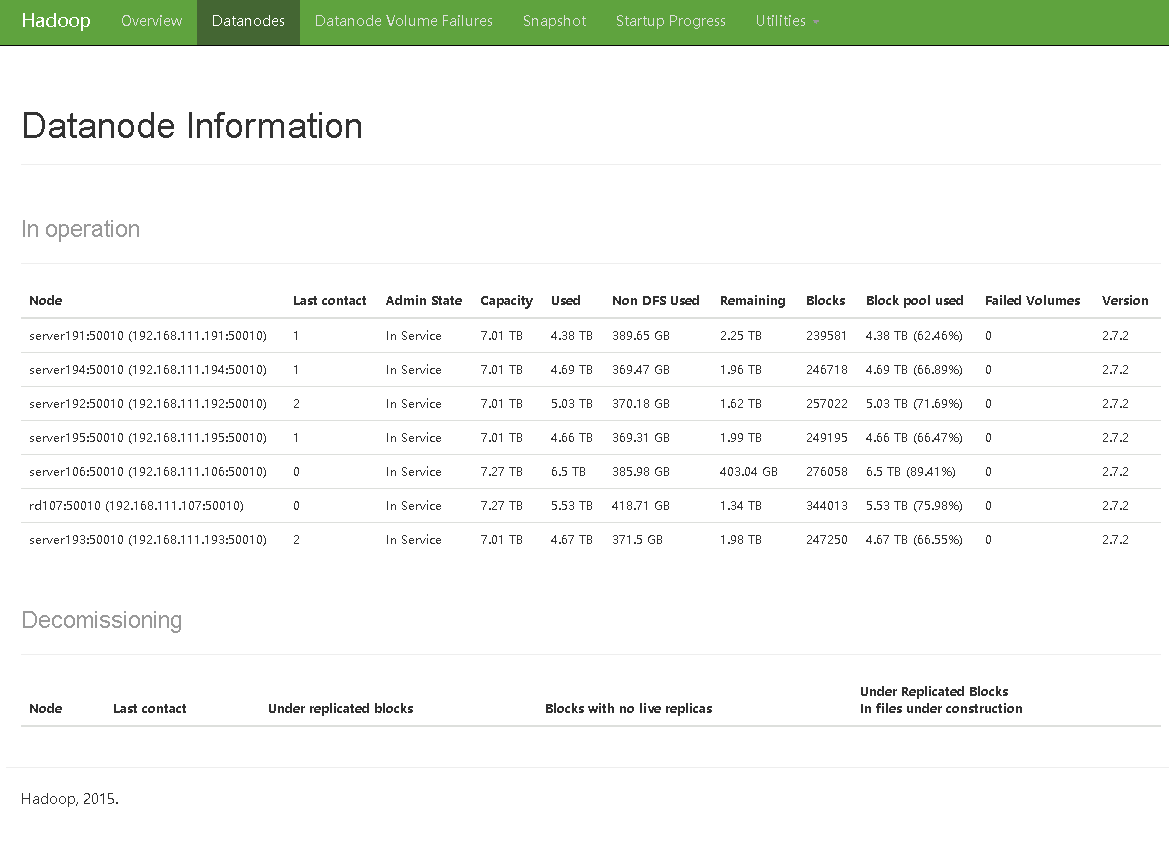
9.5 查看HDFS系统
http://192.168.111.226:50070/explorer.html#/
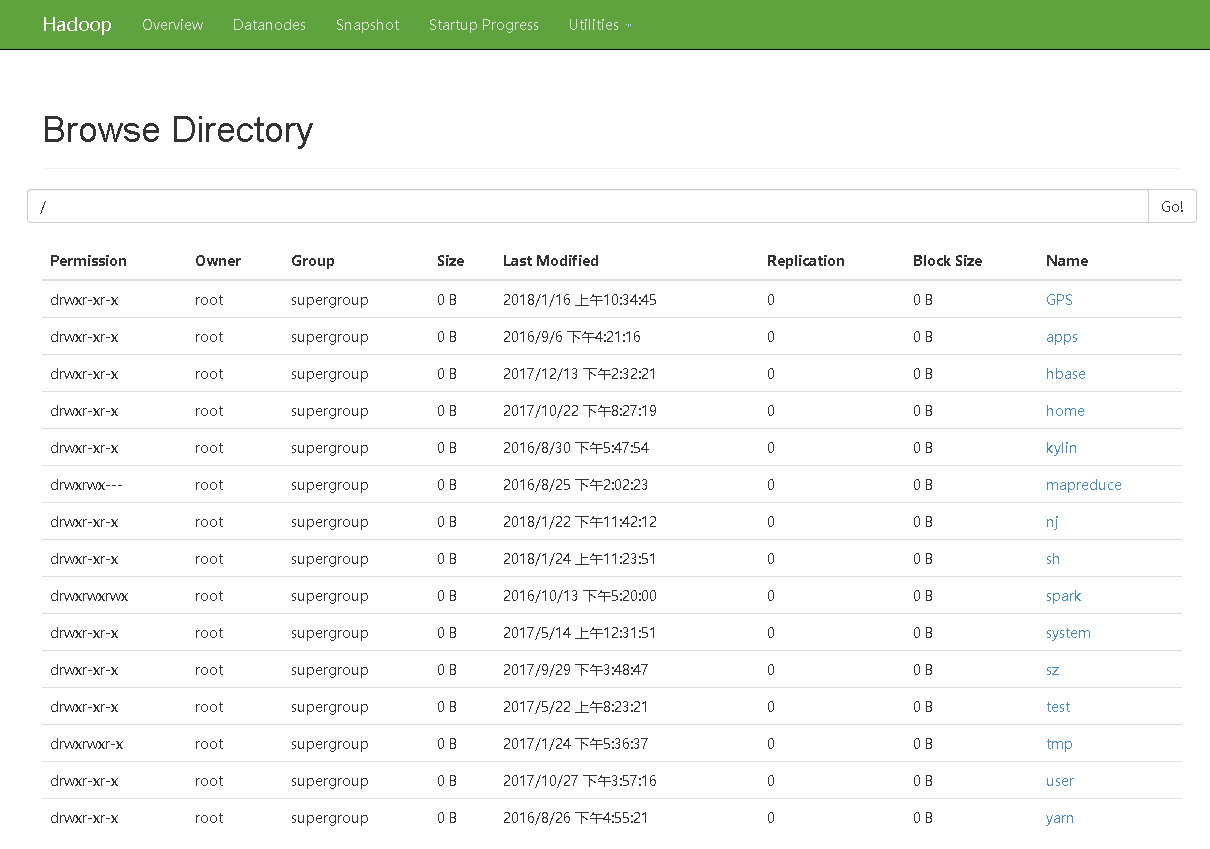
10 Hadoop集群的搭建
前面我们只用了一台机器,实际生产中,不可能这样操作,我们的通常做法是:
(1)有一台主要的计算机master,在HDFS担任NameNode的角色,在YARN担任ResourceManager角色。
注:通常会安排一台机器当做SecondaryNameNode使用,像上文中的http://192.168.111.227:8088/cluster一样,就是辅助节点。
(2)有多台机器data1、data2、data3,在HDFS担任DataNode角色,在YARN担任NodeManager角色。
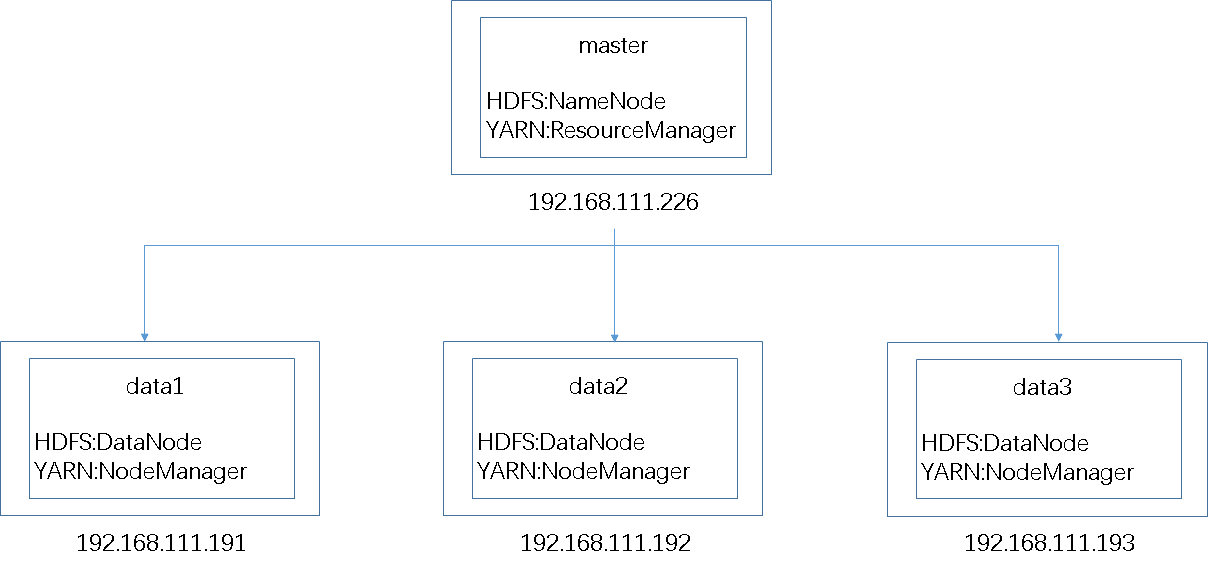
10.1
复制Single Node Cluster VirtualBox hadoop到data1
(1)复制Hadoop到data1;
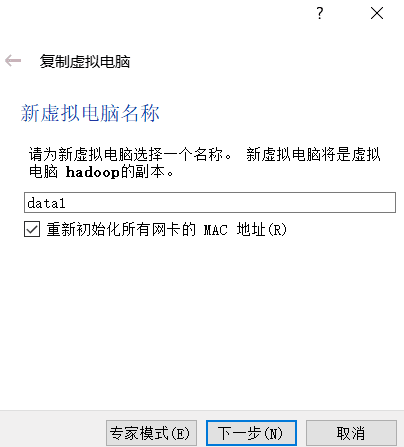
(2)设置虚拟机名称;
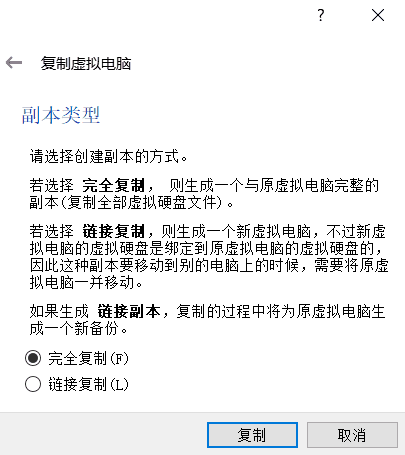
(3)设置复制类型;
10.2
VirtualBox网卡适配卡设置
(1)Host主机,就是安装VirtualBox虚拟机的主机,创建3台虚拟机(master/data1/data2/)。
(2)每一台虚拟主机上设置2张网卡。
网卡1:设置为“NAT网卡”,可以通过Host主机连接到外部网络(Internet)
网卡2:设置为“仅主机适配器”,用于创建内部网络,内部网络连接虚拟主机(master/data1/data2)与Host主机。
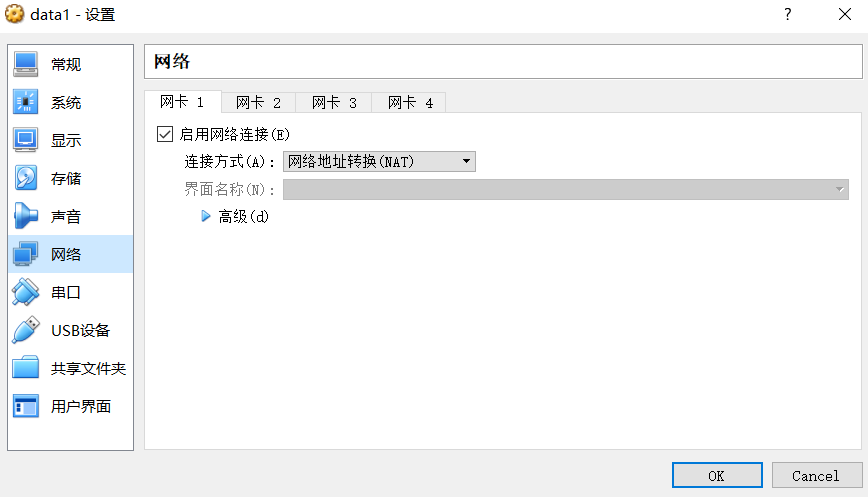
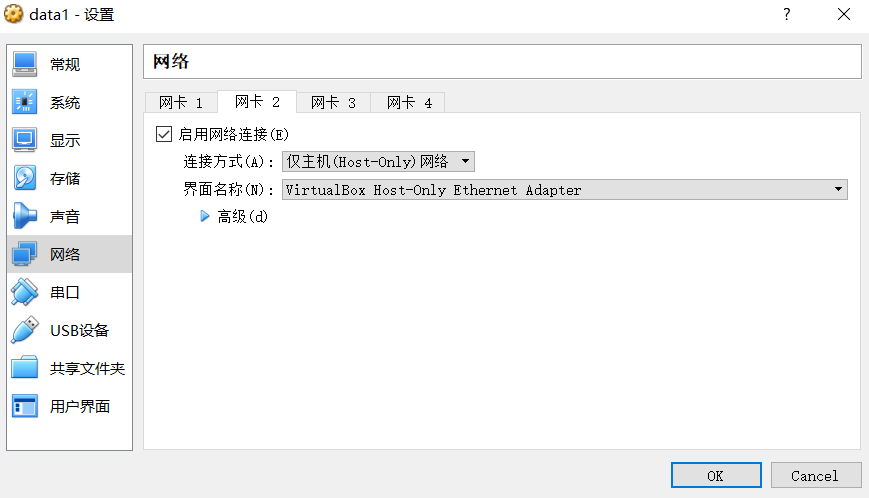
10.3
设置data1服务器
多节点集群的服务器,配置设置文件共同的部分包括:固定IP、hostname、core-site.xml、yarn-site.xml、mapred-site.xml和hdfs-site.xml。
(1)启动data1
(2)编辑网络配置文件设置固定IP
nano /etc/network/interfaces
设置“网卡1”:为NAT网卡,可以通过Host主机连接到外部网络(Internet),设置为eth0,并设置dhcp为自动获取。
设置“网卡2”:为仅主机适配器,用于建立内部网络,内部网络连接虚拟主机(master、data1、data2)与host主机。设置为eth1,并设置为static,即指定固定IP地址。
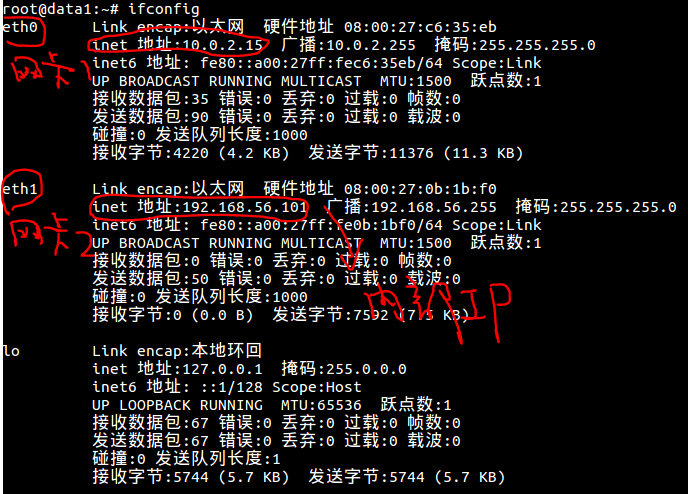
# interfaces(5) file used by ifup(8) and ifdown(8)auto loiface lo inet loopback# NAT interfaceauto eth0iface eth0 inet dhcp# host only interfaceauto eth1iface eth1 inet staticaddress 192.168.56.101netmask 255.255.255.0network 192.168.56.0broadcast 192.168.56.255
(3)设置hostname
nano /etc/hostname
输入下列內容:
data1
(4)设置hosts文档
如何让集群中所有计算机都知道其他计算机的主机名和IP。可以编辑hosts文件或设置DNS。hosts文件通常用于补充或取代网络中DNS的功能,和DNS不同的是,计算机的用户可以直接对hosts文件进行控制。hosts文件可存储计算机网络中各个节点的信息,负责将主机名映射到对应的IP地址。
nano /etc/hosts
输入以下内容:
127.0.0.1 localhost127.0.1.1 hadoop192.168.56.100 master192.168.56.101 data1192.168.56.102 data2
(5)编辑core-site.xml
nano /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration><property><name>fs.default.name</name><value>hdfs://master:9000</value></property></configuration>
(6)编辑yarn-site.xml
nano /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8025</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.address</name><value>master:8050</value></property></configuration>
ResourceManager主机与NodeManager的连接地址为8025;
ResourceManager与ApplicationMaster的连接地址为8030;
ResourceManager与客户端的连接地址为8050.
(7)编辑mapred-site.xml
mapred-site.xml用于监控Map和Reduce程序中的JobTracker任务分配情况,以及TaskTracker运行状况。修改设置mapred.job.tracker的连接地址为master:54311
nano /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration><property><name>mapred.job.tracker</name><value>master:54311</value></property></configuration>
(8)编辑hdfs-site.xml
hdfs-site.xml用于设置HDFS分布式文件系统的相关配置,data1现在作为DataNode,所以删除NameNode配置。
nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value></property></configuration>
(9)重新启动data1
reboot
(10)确认网络设置
ifconfig
(11)确认对外网络连接正常
(11)data1虚拟机关机
10.4 复制data1服务器到data2、master
data1已经设置了hadoop集群的共同部分。
(1)复制data1到data2,与前面data1复制一样。
(2)复制data1到master。
(3)虚拟机内存设置:笔者实体机物理内存是16G,master:4G,data1:2G,data2:2G。
10.5 设置data2服务器
设置data2的固定IP和hostname。
(1) 启动data2
(2)设置data2的固定IP地址,必须设置虚拟机data2每次开机都是使用固定IP地址:192.168.56.102。
nano /etc/network/interfaces
# NAT interfaceauto eth0iface eth0 inet dhcp# host only interfaceauto eth1iface eth1 inet staticaddress 192.168.56.102netmask 255.255.255.0network 192.168.56.0broadcast 192.168.56.255
(3)设置data2的主机名
nano /etc/hostname
data2
(4)重新启动data2
reboot
(5)查看网络设置是否为192.168.56.102
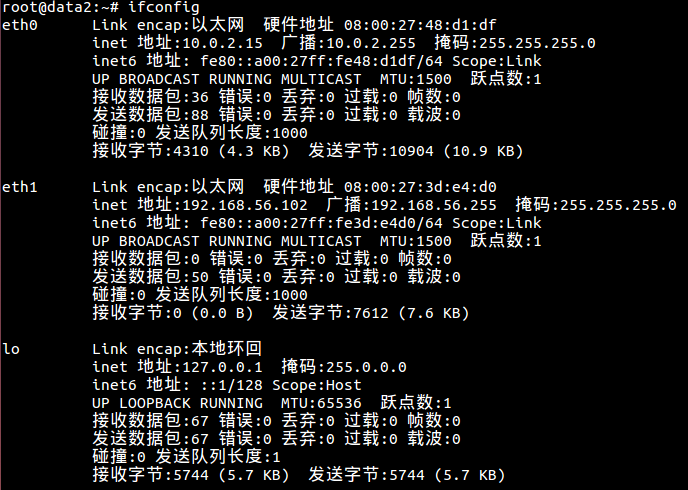
10.6 设置master服务器
(1) 启动master
(2)设置master的固定IP地址,必须设置虚拟机master每次开机都是使用固定IP地址:192.168.56.100。
nano /etc/network/interfaces
# NAT interfaceauto eth0iface eth0 inet dhcp# host only interfaceauto eth1iface eth1 inet staticaddress 192.168.56.100netmask 255.255.255.0network 192.168.56.0broadcast 192.168.56.255
(3)设置data2的主机名
nano /etc/hostname
master
(4)设置hdfs-site.xml
master现在是Namenode,删除原来data1的Datanode的HDFS设置,加入Namenode的HDFS设置。
nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value></property></configuration>
(5)编辑masters文件:告诉hadoop系统哪一台服务器是Namenode
nano /usr/local/hadoop/etc/hadoop/masters
输入:
master
(6)编辑slaves文件:告诉hadoop系统哪些服务器是Datanode
nano /usr/local/hadoop/etc/hadoop/slaves
输入:
data1data2
(7)重新启动master虚拟机并查看网络设置
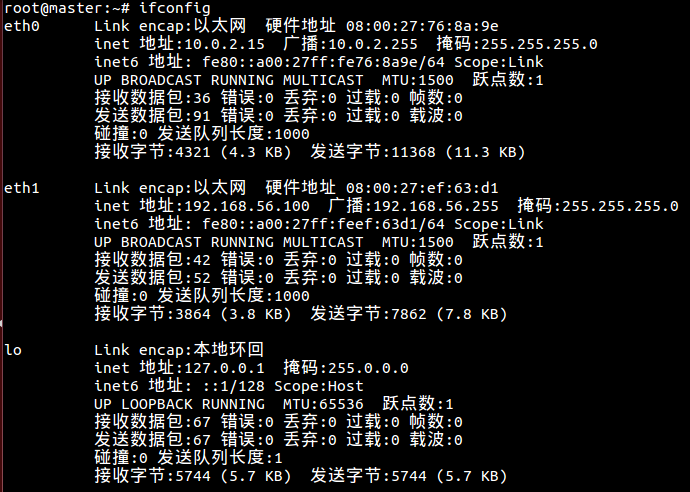
10.7 master连接到data1和data2,创建HDFS目录
创建Namenode(master)的SSH连接到Datanode(data1、data2),并创建HDFS相关目录。
(1)启动master、data1、data2
(2)master连接到data1
ssh data1
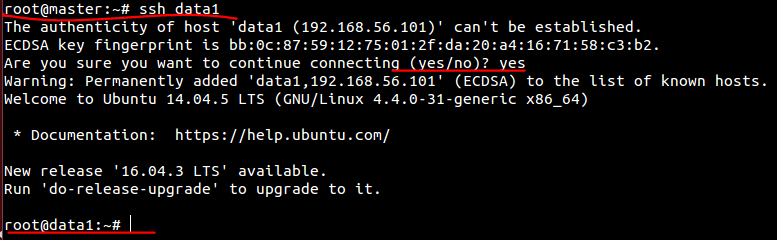
(3)master连接到data1创建HDFS相关目录
登录data1后,我们将在data1创建HDFS相关目录
# 删除HDFS所有目录rm -rf /usr/local/hadoop/hadoop_data/hdfs# 创建Datanode存储目录mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode# 将目录的所有者更改为rootsudo chown root:root -R /usr/local/hadoop# 退出data1,回到masterexit
(4)同理,master连接到data2创建HDFS相关目录
登录data2后,我们将在data2创建HDFS相关目录
# 删除HDFS所有目录rm -rf /usr/local/hadoop/hadoop_data/hdfs# 创建Datanode存储目录mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode# 将目录的所有者更改为rootsudo chown root:root -R /usr/local/hadoop# 退出data2,回到masterexit
10.8 创建并格式化Namenode HDFS目录
(1)删除之前的HDFS目录rm -rf /usr/local/hadoop/hadoop_data/hdfs(2)创建Namenode目录mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode(3)将目录的所有者更改为rootsudo chown root:root -R /usr/local/hadoop(4)格式化Namenode HDFS目录hadoop namenode -format
10.9 启动hadoop集群
# 在master终端输入start-dfs.shstart-yarn.sh
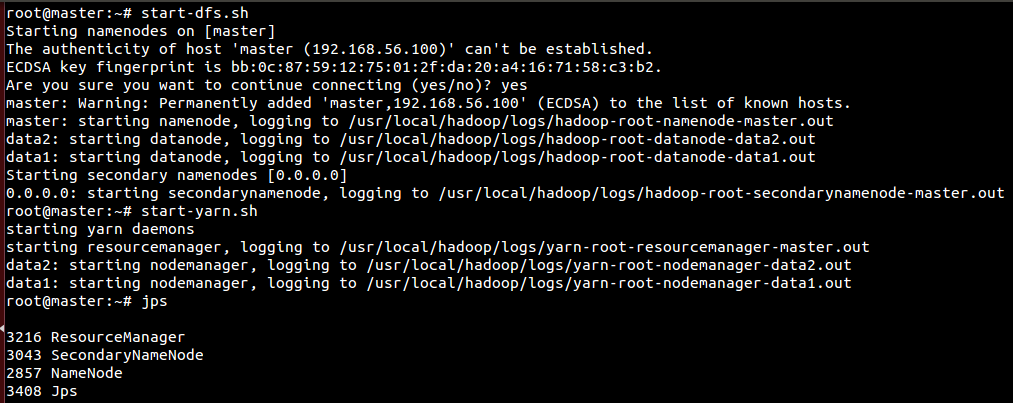
# 查看data1进程ssh data1jps
# 查看data2进程ssh data2jps
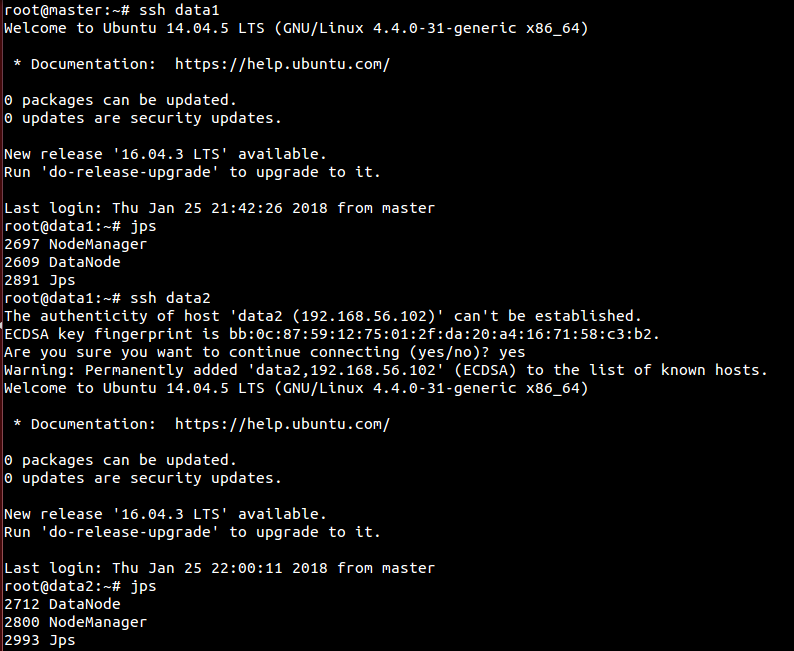
# 两次exit回到masterexitexit
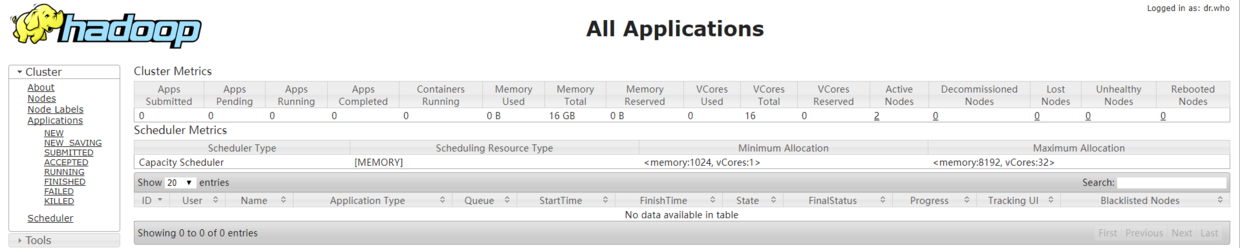
10.10 打开Hadoop ResourceManager Web界面
# 虚拟机浏览器输入http://master:8088/或者http://localhost:8088/# 宿主机浏览器输入http://192.168.56.100:8088/cluster
查看ResourceManager Web界面
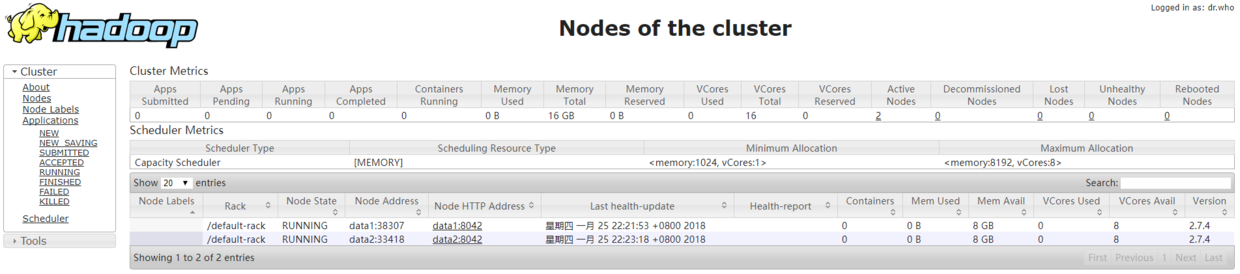
查看已经运行的节点情况
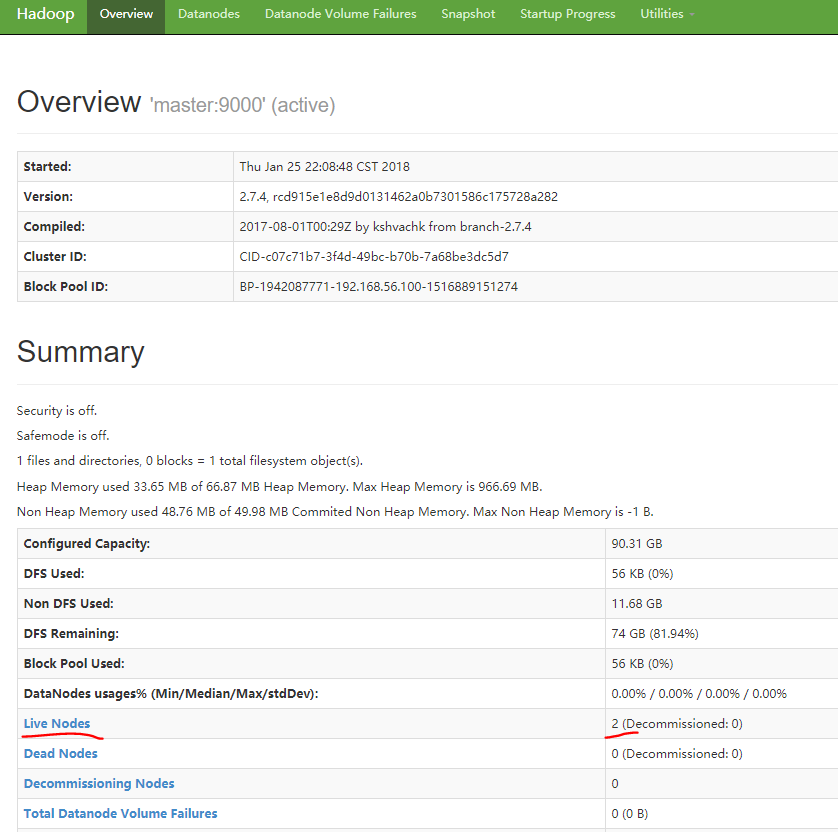
10.11 打开Hadoop NameNode Web界面
# 虚拟机浏览器输入http://master:50070/或者http://localhost:50070/# 宿主机浏览器输入http://192.168.56.100:50070/dfshealth.html#tab-overview
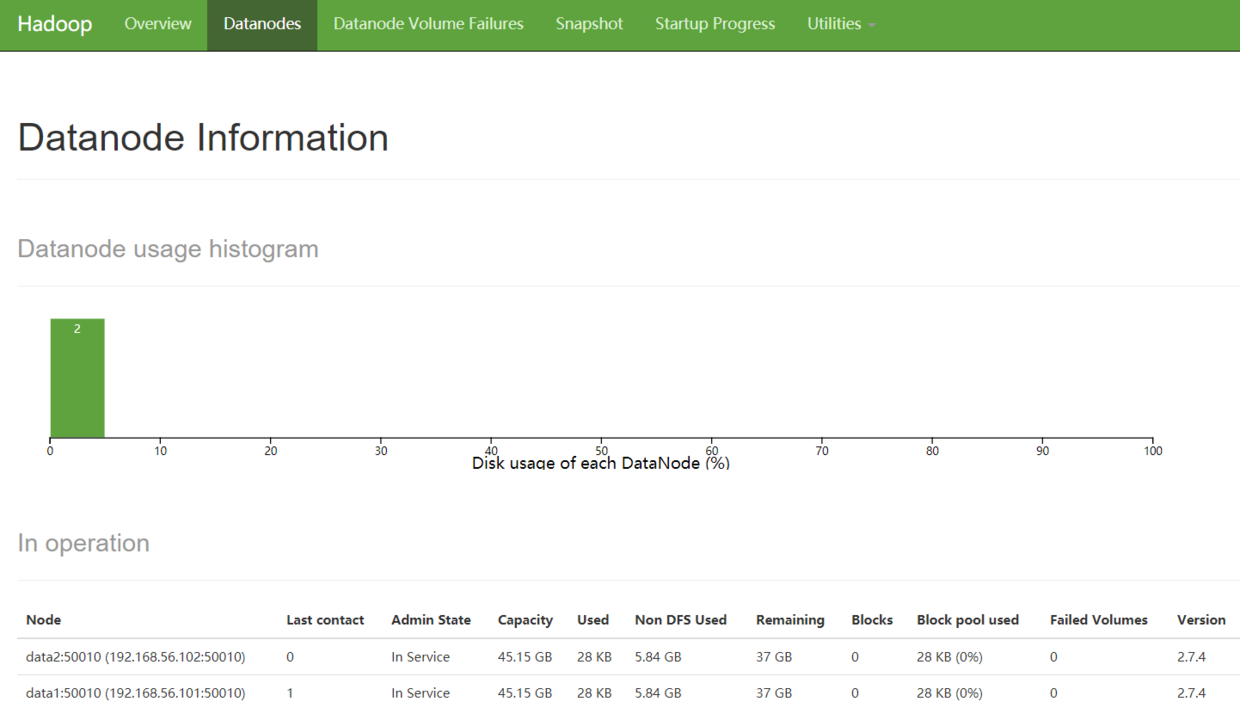
10.12 关闭hadoop集群
stop-dfs.shsyop-yarn.sh
11 spark集群的搭建
在master机器上操作
11.1 Scala的安装
(1)下载scalawget http://www.scala-lang.org/files/archive/scala-2.12.4.tgz(2)解压缩scalatar -zxvf scala-2.12.4.tgz(3)把scala移动到/usr/local目录mv scala-2.12.4 /usr/local/scala(4)设置scala用户环境变量nano ~/.bashrc(5)输入以下:SCALA_HOME为scala的安装目录;设置PATH环境变量,让我们在不同的目录下都可以执行scala程序。export SCALA_HOME=/usr/local/scalaexport PATH=$PATH:$SCALA_HOME/bin(6)使~/.bashrc修改生效source ~/.bashrc(7)查看scala版本,启动scala,关闭scalascala -versionscala:q
11.2 Spark的安装
(1)下载spark# spark与hadoop版本要相互配合,spark会读取hadoop hdfs并且能够在Hadoop YARN上面执行程序,之前安装的是hadoop2.7.4,所以选择Pre-build for Apache Hadoop 2.7 and laterwget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.1/spark-2.2.1-bin-hadoop2.7.tgz(2)解压缩scalatar -zxvf spark-2.2.1-bin-hadoop2.7.tgz(3)把scala移动到/usr/local目录mv spark-2.2.1-bin-hadoop2.7 /usr/local/spark(4)设置spark用户环境变量nano ~/.bashrc(5)输入以下:SPARK_HOME为spark的安装目录;设置PATH环境变量,让我们在不同的目录下都可以执行spark程序。export SPARK_HOME=/usr/local/sparkexport PATH=$PATH:$SPARK_HOME/bin(6)使~/.bashrc修改生效source ~/.bashrc
11.3 Spark若干配置
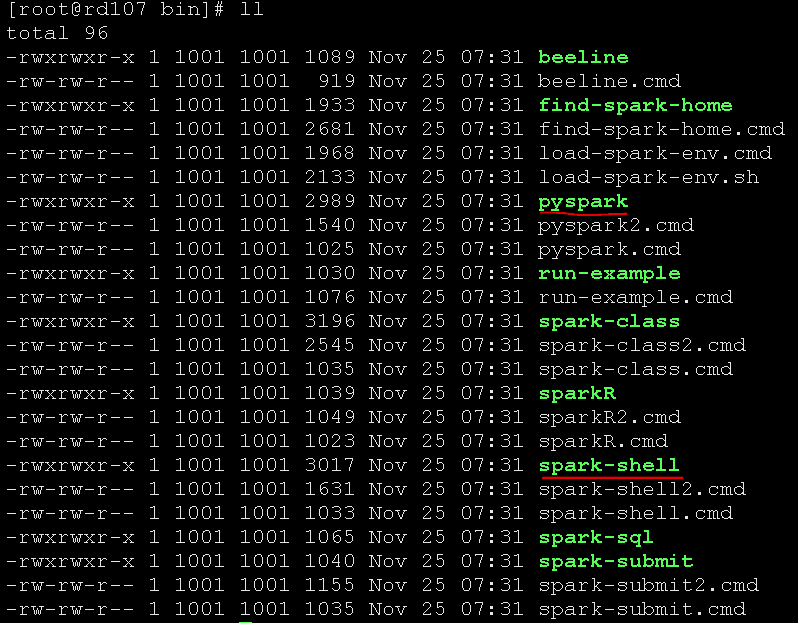
在spark的bin目录中,spark-shell是以scala语言调用打开的,而pyspark是以python语言调用打开的
(1)启动和退出pyspark交互式界面
pysparkexit()
(2)设置pyspark显示信息
spark系统安装后,在pyspark交互式界面默认会显示很多信息,有时候太多信息会影响我们的阅读,所以建议修改设置,让他们只显示警告信息。

# 复制log4j模板文件,在conf目录下cd /usr/local/spark/confcp log4j.properties.template log4j.properties# 编辑设置log4j.properties,将INFO改为WARNnano log4j.propertieslog4j.rootCategory=WARN, console# 再次进入pyspark,少了很多信息,只列出了重要的信息pyspark
11.4 创建Spark测试文件并上传至HDFS上
mkdir /data# 测试数据text.txt放在master机器上的/data/test.txt,text.txt文件内容为python,goodjava,powerfulspark,speed# 启动hadoop集群start-dfs.shstart-yarn.sh# HDFS上新建 /data目录hdfs dfs -mkdir /data# 上传文件到HDFS上面hdfs dfs -put /data/test.txt /data
11.5 本地运行pyspark程序
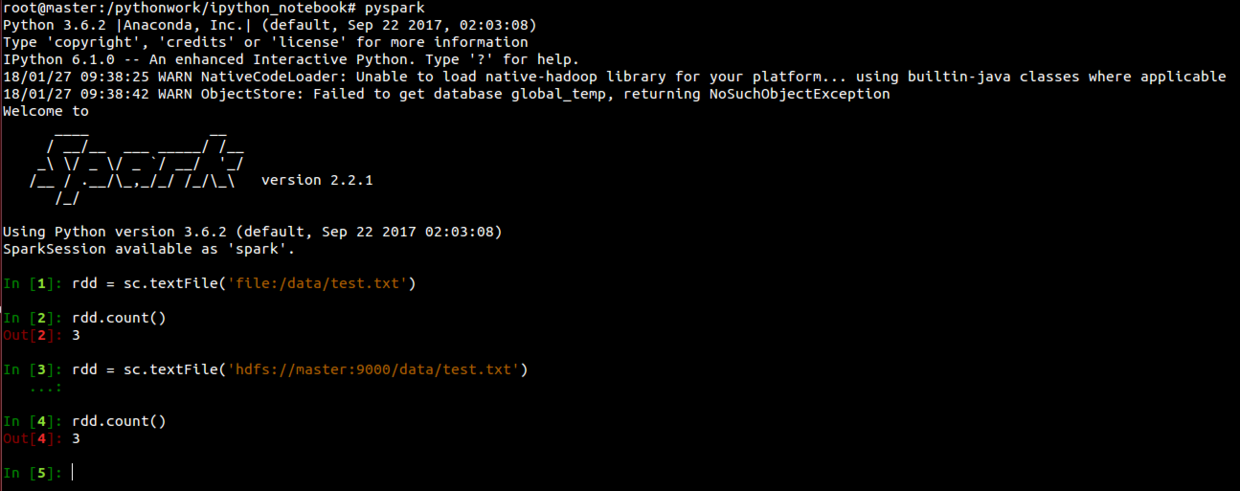
# 启动pyspark --master local[4]# 查看当前运行模式sc.master# 读取本地文件rdd = sc.textFile('file:/data/test.txt')rdd.count()# 读取HDFS文件rdd = sc.textFile('hdfs://master:9000/data/test.txt')rdd.count()
local[N]代表本地运行,使用N个线程(thread),也就是说可以同时执行N个程序。虽然是在本地运行,但是因为现在CPU大多是多个核心,所以使用多个线程仍然会加速执行。
local[*]会尽量使用我们机器上的CPU核心。
HDFS的存储路径为“hdfs://master:9000”,在安装hadoop时设置的,可以编辑core-site.xml。
11.6 Hadoop YARN运行pyspark
Spark 可以在Hadoop YARN 上运行,让YARN帮助它进行多台机器资源的管理。
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark --master yarn --deploy-mode clientsc.masterrdd = sc.textFile('hdfs://master:9000/data/test.txt')rdd.count()
HADOOP_CONF_DIR :设置Hadoop配置文件目录
pyspark:要运行的程序pyspark
—master yarn —deploy-mode client:设置运行模式yarn-client
11.7 构建Spark Standalone Cluster运行环境
master机器操作
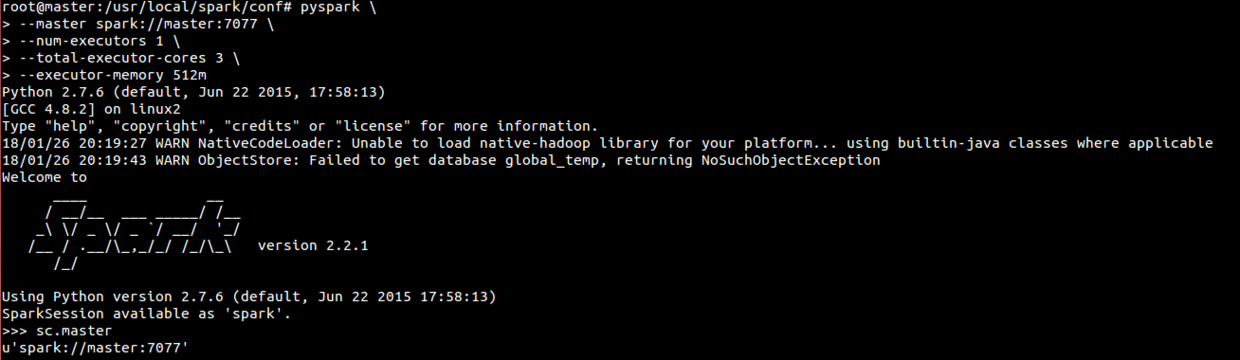
(1)复制模版文件来创建spark-env.shspark-env.sh是spark的环境配置文件。spark系统中提供了模版文件,便于用户设置时作为参考cp /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh(2)设置编辑spark-env.shnano /usr/local/spark/conf/spark-env.sh输入以下内容:export SPARK_MASTER_IP=masterexport SPARK_WORKER_CORES=1export SPARK_WORKER_MEMORY=512mexport SPARK_WORKER_INSTANCES=4(3)将master的spark复制到data1ssh data1mkdir /usr/local/sparkchown root:root /usr/local/sparkexitscp -r /usr/local/spark root@data1:/usr/local(4)将master的spark复制到data2ssh data2mkdir /usr/local/sparkchown root:root /usr/local/sparkexitscp -r /usr/local/spark root@data2:/usr/local(5)编辑slaves文件,设置Spark Standalone Cluster有哪些服务器cp slaves.template slavesnano /usr/local/spark/conf/slaves(6)启动Spark Standalone Cluster/usr/local/spark/sbin/start-all.sh或者分别启动master和slaves/usr/local/spark/sbin/start-master.sh/usr/local/spark/sbin/start-slaves.sh(7)在Spark Standalone Cluster运行pysparkpyspark \--master spark://master:7077 \--num-executors 1 \--total-executor-cores 3 \--executor-memory 512m# 查看运行模式sc.master# 读取本地文件:注意在cluster模式(如YARN-client或Spark Standalone )读取本地文件时,因为程序会分布在不同的机器上执行,所以必须确认所有的机器都有该文件,否则会发生错误。# 建议在cluster模式下读取HDFS文件,这样才不会出错。rdd = sc.textFile('file:/data/test.txt')rdd.count()# 读取HDFS文件rdd = sc.textFile('hdfs://master:9000/data/test.txt')rdd.count()(8)停止Spark Standalone Cluster运行/usr/local/spark/sbin/stop-all.sh
12 Anaconda安装
pyspark集群模式配置
(1)下载wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.0.0-Linux-x86_64.sh(2)安装:-b 批次安装,自动安装到用户目录下(/root/anaconda3)bash Anaconda3-5.0.0-Linux-x86_64.sh -b(3)编辑~/.bashrc加入模块路径nano ~/.bashrc#加入anaconda路径export PATH=/root/anaconda3/bin:$PATHexport ANACONDA_PATH=/root/anaconda3#加入pyspark设置export PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/ipythonexport PYSPARK_PYTHON=$ANACONDA_PATH/bin/python#使~/.bashrc生效source ~/.bashrc(4)查看Python版本root@master:~/anaconda3# python --versionPython 3.6.2 :: Anaconda, Inc.此时启动Python会默认为anaconda的Python3.6.2,而不是系统自带的版本Python2.7.6如:ipythonjupyter notebook --allow-root(5)在data1和data2中也安装anaconda# data1scp Anaconda3-5.0.0-Linux-x86_64.sh root@data1:/optssh data1cd /optbash Anaconda3-5.0.0-Linux-x86_64.sh -bnano ~/.bashrcexport PATH=/root/anaconda3/bin:$PATHexport ANACONDA_PATH=/root/anaconda3export PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/ipythonexport PYSPARK_PYTHON=$ANACONDA_PATH/bin/pythonsource ~/.bashrc# data2scp Anaconda3-5.0.0-Linux-x86_64.sh root@data2:/optssh data2cd /optbash Anaconda3-5.0.0-Linux-x86_64.sh -bnano ~/.bashrcexport PATH=/root/anaconda3/bin:$PATHexport ANACONDA_PATH=/root/anaconda3export PYSPARK_PYTHON=$ANACONDA_PATH/bin/pythonexport PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/ipythonsource ~/.bashrc
装完Anaconda,因为我们我们对spark使用了ipython打开,所以,当用户在终端输入pyspark时会使用ipython打开
13 利用ipython notebook(jupyter notebook)使用spark
mkdir -p /pythonwork/ipython_notebookcd /pythonwork/ipython_notebook# 用jupyter notebook启动pyspark,分别在master /data1 /data2修改pyspark设置。# 注意笔者使用的是root用户使用,需要加上--allow-root参数,否则打不开;# --NotebookApp.open_browser=False默认没有用浏览器打开,我们可以复制屏幕上打印出的地址,在虚拟机上的浏览器,也可以在宿主机浏览器打开。# --NotebookApp.port=8889自定义端口号,将会避免不同软件的端口号冲突被占用问题。nano ~/.bashrc#export PYSPARK_PYTHON=$ANACONDA_PATH/bin/python#export PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/ipython# jupyter notebookexport PYSPARK_PYTHON=$ANACONDA_PATH/bin/pythonexport PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/jupyter-notebookexport PYSPARK_DRIVER_PYTHON_OPTS=" --allow-root--NotebookApp.open_browser=False --NotebookApp.ip='192.168.56.100' - -NotebookApp.port=8889"# jupyter labexport PYSPARK_PYTHON=$ANACONDA_PATH/bin/pythonexport PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/jupyter-labexport PYSPARK_DRIVER_PYTHON_OPTS=" --allow-root --NotebookApp.open_browser=False --NotebookApp.ip='30.76.226.208' --NotebookApp.port=8889"# 启动pysparkpyspark#关闭pyspark关闭浏览器Ctrl+CyEnter
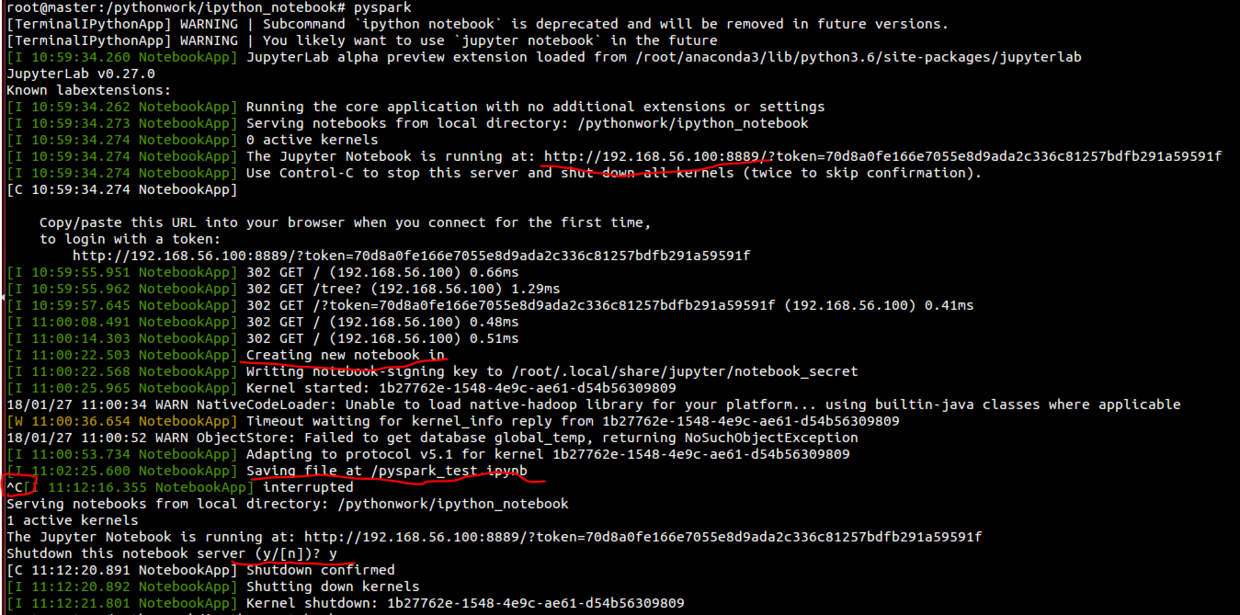

这样我们就可以像操作Python一样,通过使用jupyter notebook一样去操作spark了,关于jupyter notebook的使用,网上有很多文章,大家可以去自己查阅学习,这不是本文的重点。jupyter notebook是作为我们调试代码的好帮手,务必学会利用,可以有效地提高我们的工作效率。
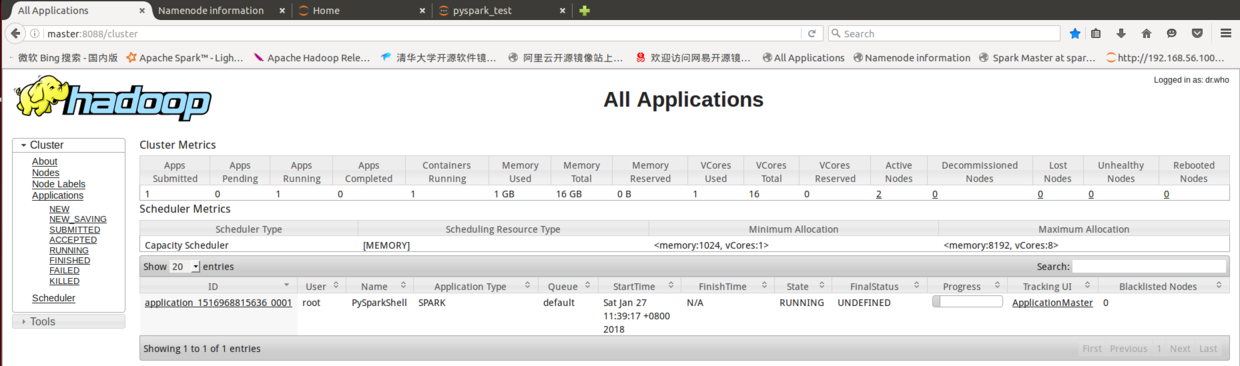
14 使用Ipython Notebook在Hadoop YARN-client模式运行Spark程序
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop MASTER=yarn-client pyspark
15 使用Ipython Notebook在Spark Stand Alone模式下运行
# 启动Spark Stand Alone cluster/usr/local/spark/sbin/start-all.sh# 启动IPython Notebook运行在Spark Stand Alone模式## 切换目录cd /pythonwork/ipyton_notebook##命令行执行MASTER=spark://master:7077 pyspark \--num-executors 1 \--total-executor-cores 2 \--executor-memory 512m
16 总结:不同模式下运行ipython notebook
(1)Local 启动ipython notebook在任意一台机器终端执行:cd /pythonwork/ipyton_notebookpyspark --master local[*](2)hadoop yarn-client模式启动 ipython notebook启动master、data1、data2机器,在master终端执行:start-all.shHADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark \--master yarn \--deploy-mode client(3)Spark Stand Alone模式启动 ipython notebookstart-all.sh/usr/local/spark/sbin/start-all.shMASTER=spark://master:7077 pyspark \--num-executors 1 \--total-executor-cores 2 \--executor-memory 512m
17 Pycharm搭建PySpark集成开发环境
前面的都是使用jupyter notebook交互式模式,在实际项目中适合测试,但是如果想要建立批量的开发环境用于生产,通常我们可以选择(以Python语言为例)Pycharm 、IntelliJ IDEA(通过安装Python插件)作为开发环境。
下面以Pycharm作为PySpark的集成开发环境的配置进行讲解。
17.1 下载、解压和启动Pycharm
cd /optwget https://download.jetbrains.8686c.com/python/pycharm-community-2017.3.3.tar.gztar -zxvf pycharm-community-2017.3.3.tar.gz
cd pycharm-community-2017.3.3/./bin/pycharm.sh &
17.2 配置Pycharm
(1) 打开Pycharm,导入已有的或者新建工程。
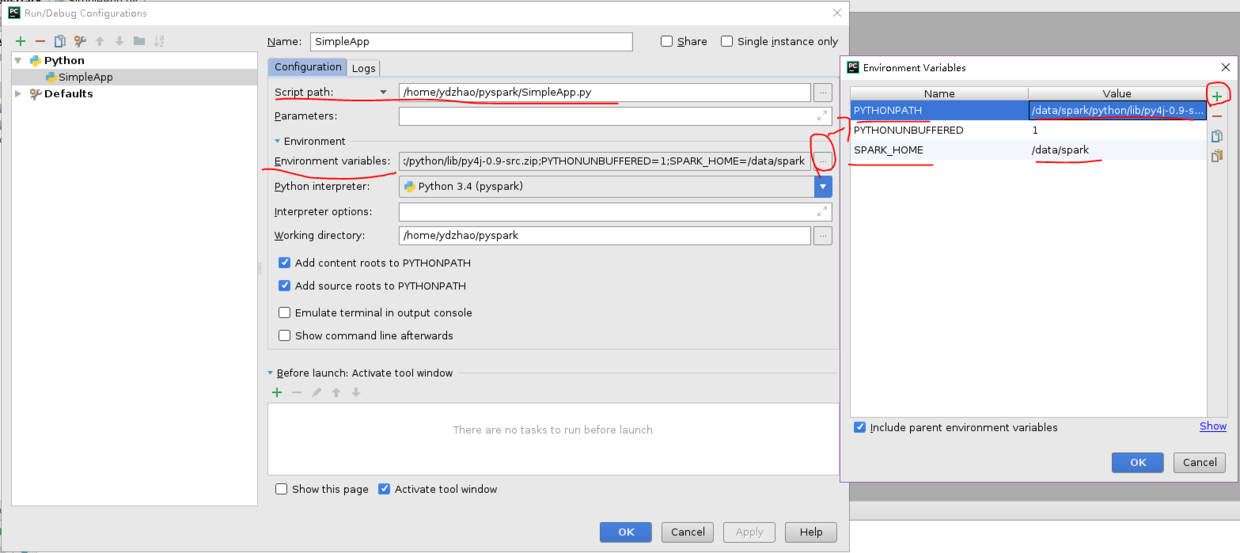
(2)创建新的run configurition——>选择edit configurition,
设置环境,创建PYTHONPATH和SPARK_HOME
配置路径,都可以在Spark安装路径下找到:
如:
PYTHONPATH :/data/spark/python/lib/py4j-0.9-src.zip
SPARK_HOME:/data/spark
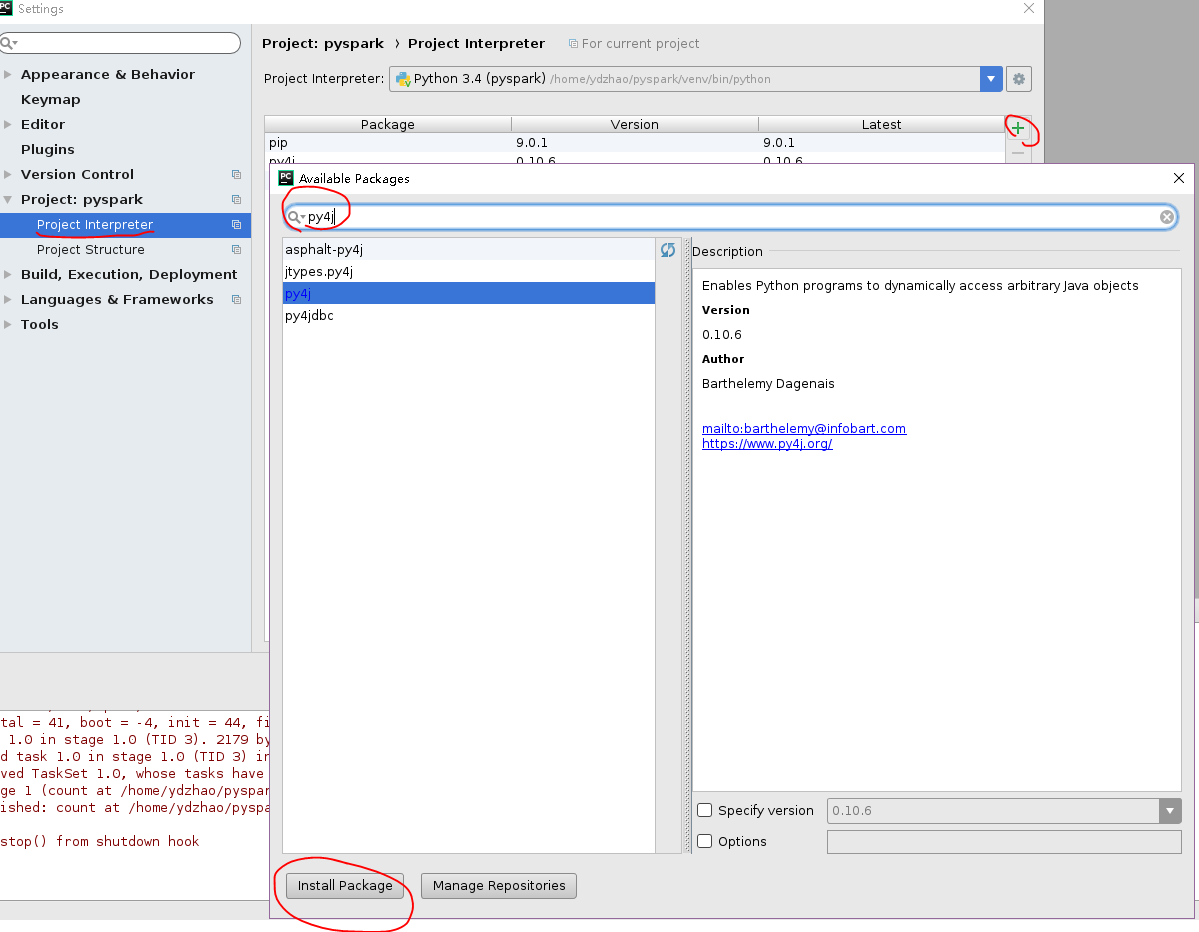
(3)安装py4j(Python和Java之间的解释器)
选择 File->setting->你的project interpreter,搜索py4j,安装
(4)添加spark库到Python环境中
选择 File->setting->你的project->project structure

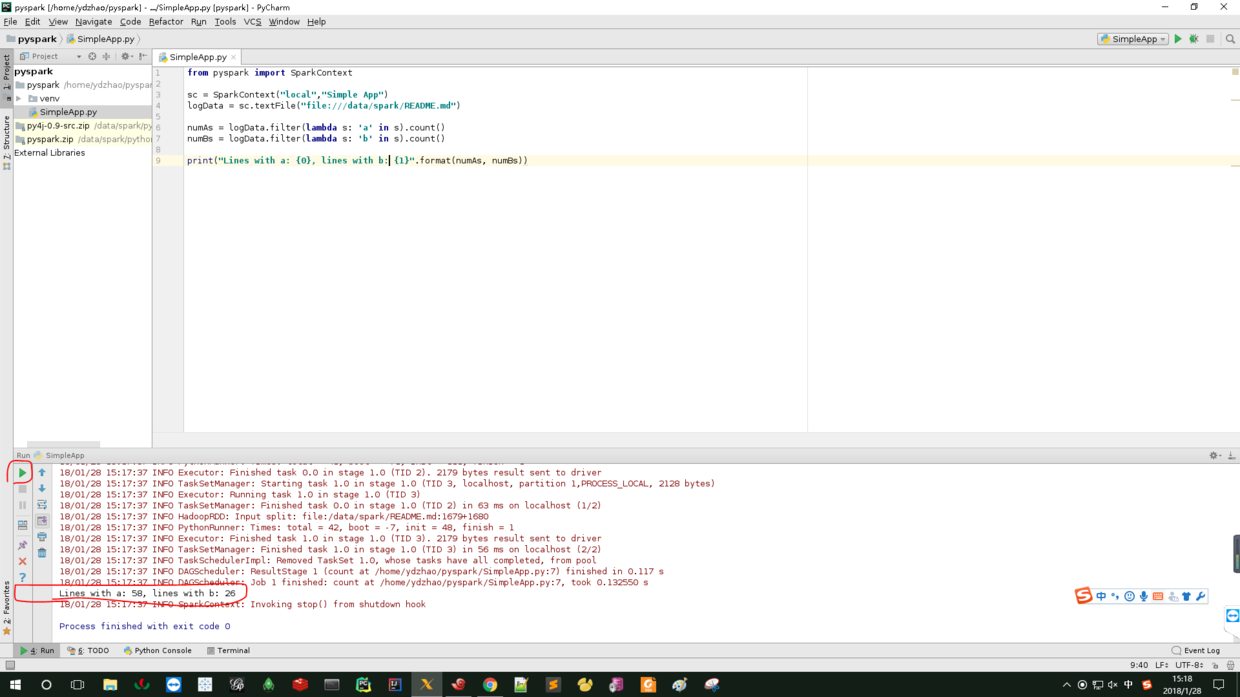
(5)测试SimpleApp

若有收获,就点个赞吧
0 人点赞
