- 01-利用Jupyter-Notebook启动PySpark
- 02-PySpark-INFO-LOG问题
- 03-PySpark调用关系型数据库表
- 04-PySpark过滤问题
- 05-PySpark列表循环
- 06-由RDD生成DataFrame
- 08-PySpark数据预处理
- 09-RDD的生成与转换
- 10-JSON格式嵌套问题
- 11-str转TimestampType()
- 12-字段去重计数:countDistinct和approxCountDistinct
- 13-PySpark新增列问题
- 14-PySpark数据填充、过滤
- 15-Renaming-Columns-for-PySpark-DataFrames-Aggregates
- 16-保存Pyspark-dataframe到Hbase
- 17-新增列时when-otherwise的使用
- 18-PySpark-DataFrame元组列表的解压缩
- 19-Spark—shuffle-write
结合项目中遇到的问题,并参考https://stackoverflow.com/的问题解答,将PySpark开发过程中的问题进行梳理如下欢迎批评指正!!! 后续若有问题会继续更新。。。
01-利用Jupyter-Notebook启动PySpark
推荐先安装好Anaconda
习惯了在Jupyter Notebook上面测试代码,怎么在使用PySpark时也能够利用上,只需要一下几步骤!!!
修改 ~/.bashrc 文件
nano ~/.bashrc
添加以下内容
export PATH="/opt/anaconda3/bin:$PATH"export PYSPARK_PYTHON="python3"export PYSPARK_DRIVER_PYTHON="ipython3"export PYSPARK_DRIVER_PYTHON_OPTS="notebook --NotebookApp.open_browser=False --allow-root --NotebookApp.ip='192.168.111.106' --NotebookApp.port=8889"
source一下
source ~/.bashrc
就可以让Jupyter Notebook启动 pyspark
[root@server106 pyspark_app]# pyspark[TerminalIPythonApp] WARNING | Subcommand `ipython notebook` is deprecated and will be removed in future versions.[TerminalIPythonApp] WARNING | You likely want to use `jupyter notebook`... continue in 5 sec. Press Ctrl-C to quit now.[I 16:27:26.624 NotebookApp] Serving notebooks from local directory: /home/ydzhao/pyspark_app[I 16:27:26.624 NotebookApp] 0 active kernels[I 16:27:26.624 NotebookApp] The Jupyter Notebook is running at: http://192.168.111.106:8889/?token=b7a226911d027509bf277fe40641b3572608ae47b26983f7[I 16:27:26.624 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).[C 16:27:26.625 NotebookApp]Copy/paste this URL into your browser when you connect for the first time,to login with a token:http://192.168.111.106:8889/?token=b7a226911d027509bf277fe40641b3572608ae47b26983f7
02-PySpark-INFO-LOG问题
Spark 1.6.2
log4j = sc._jvm.org.apache.log4jlog4j.LogManager.getRootLogger().setLevel(log4j.Level.ERROR)# 设置Spark控制台不要显示太多信息def SetLogger(sc):logger = sc._jvm.org.apache.log4jlogger.LogManager.getLogger("org"). setLevel( logger.Level.ERROR )logger.LogManager.getLogger("akka").setLevel( logger.Level.ERROR )logger.LogManager.getLogger("INFO"). setLevel( logger.Level.ERROR )logger.LogManager.getLogger("WARN"). setLevel( logger.Level.ERROR )logger.LogManager.getRootLogger().setLevel(logger.Level.ERROR)
Spark 2.0+
spark.sparkContext.setLogLevel('WARN')
旧的方法
conf/log4j.properties.template 复制为 conf/log4j.properties
编辑log4j.properties
log4j.rootCategory=INFO, console 修改为 log4j.rootCategory=WARN, console
不同的LOG设置:
OFF (most specific, no logging)FATAL (most specific, little data)ERROR - Log only in case of ErrorsWARN - Log only in case of Warnings or ErrorsINFO (Default)DEBUG - Log details steps (and all logs stated above)TRACE (least specific, a lot of data)ALL (least specific, all data)
pyspark.SparkContext.setLogLevelfrom pyspark.sql import SparkSessionspark = SparkSession.builder.\master('local').\appName('foo').\getOrCreate()spark.sparkContext.setLogLevel('WARN')
03-PySpark调用关系型数据库表
启动pyspark shell时,如果想调用数据库表,可以这样操作
需要提前下载好ojdbc6-11.2.0.3.jar包
pyspark --jars "/data/spark/ojdbc6-11.2.0.3.jar"
提交任务时加上
spark-submit --master yarn \--deploy-mode cluster \--num-executors 25 \--executor-cores 2 \--driver-memory 4g \--executor-memory 4g \--conf spark.broadcast.compress=true \--jars "/data/spark/ojdbc6-11.2.0.3.jar" /home/project/test.py
04-PySpark过滤问题
使用boolean expressions
'&' for 'and''|' for 'or''~' for 'not'
‘~’ for ‘not’
rdd = sc.parallelize([(0,1), (0,1), (0,2), (1,2), (1,10), (1,20), (3,18), (3,18), (3,18)])df = sqlContext.createDataFrame(rdd, ["id", "score"])l = [10,18,20]df.filter(~df.score.isin(l))df.where(df.score.isin(l))输出:(0,1), (0,1), (0,2), (1,2)(1,10), (1,20), (3,18), (3,18), (3,18)
‘&’ for ‘and’
‘|’ for ‘or’
df1.filter((df1.LON == 0)|(df1.LAT == 0)).count()24105df1.filter((df1.LON == 0)&(df1.LAT == 0)).count()14252df1.filter(~df1.LON == 0).count()AnalysisException: "cannot resolve 'NOT LON' due to data type mismatch:argument 1 requires boolean type, however, 'LON' is of double type.;"df1.filter(~df1.LON.isNotNull()).count()0
05-PySpark列表循环
df.select([c for c in df.columns if c != 'id'])#(缺失值个数,行号)df_miss.rdd.map(lambda row:(sum([c == None for c in row]),row['id'])).sortByKey(ascending=False).collect()df_miss.agg(*[(1.00 - (fn.count(c) / fn.count('*'))).alias(c + '_missing') for c in df_miss.columns]).show()df_miss.select([c for c in df_miss.columns if c != 'income'])df_miss_no_income.agg(*[fn.mean(c).alias(c) for c in df_miss_no_income.columns if c != 'gender']).\toPandas().to_dict('records')[0]
06-由RDD生成DataFrame
# RDD到DataFramefrom pyspark.sql import typesfraud = sc.textFile('file:///root/ydzhao/PySpark/Chapter04/ccFraud.csv.gz')header = fraud.first()
header'"custID","gender","state","cardholder","balance","numTrans","numIntlTrans","creditLine","fraudRisk"'
fraud.take(3)['"custID","gender","state","cardholder","balance","numTrans","numIntlTrans","creditLine","fraudRisk"','1,1,35,1,3000,4,14,2,0','2,2,2,1,0,9,0,18,0']
fraud.count()10000001
(1) 去除标题行数据,每个元素转换成整型Integer,还是RDD
fraud = fraud.filter(lambda row: row != header).map(lambda row: [int(x) for x in row.split(',')])fraud.take(3)[[1, 1, 35, 1, 3000, 4, 14, 2, 0],[2, 2, 2, 1, 0, 9, 0, 18, 0],[3, 2, 2, 1, 0, 27, 9, 16, 0]]
(2) 创建DataFrame模式
h[1:-1]代表第一行到最后一行
schema = [*[types.StructField(h[1:-1], types.IntegerType(), True) for h in header.split(',')]]schema = types.StructType(schema)
(3) 创建DataFrame
# spark2.0+# fraud_df = spark.createDataFrame(fraud, schema)# spark1.6.2fraud_df = sqlContext.createDataFrame(fraud, schema)fraud_df.printSchema()root|-- custID: integer (nullable = true)|-- gender: integer (nullable = true)|-- state: integer (nullable = true)|-- cardholder: integer (nullable = true)|-- balance: integer (nullable = true)|-- numTrans: integer (nullable = true)|-- numIntlTrans: integer (nullable = true)|-- creditLine: integer (nullable = true)|-- fraudRisk: integer (nullable = true)
08-PySpark数据预处理
RDD读取数据、RDD动作操作、RDD创建DF、读Oracle数据库、新增一列,转换数据类型,过滤,join、做聚合、去重、排序(基于Spark1.6.2)
rdd = sc.textFile('/sh/signaling/2016/10/22/TRAFF_20161022232800.txt.lzo')rdd1 = rdd.map(lambda x:x.split(",")).map(lambda line:(line[2]+line[3],1)).reduceByKey(lambda x,y:x+y)df1 = sqlContext.createDataFrame(rdd1,['LACCELL','NUM'])df = sqlContext.read.format("jdbc").options(url="jdbc:oracle:thin:@192.168.111.107:1521:orcl", driver = "oracle.jdbc.driver.OracleDriver", dbtable = "TBL_LAC_CELL_TAZ", user="shanghai_base", password="shanghai_base").load()from pyspark.sql import typesdf2 = df.\withColumn('LACCELL',df.LAC_CELL.cast(types.LongType())).\select('LACCELL','TAZID').filter(df.TAZID>100000)df3 = df1.\join(df2,df1.LACCELL == df2.LACCELL,'right').\select(df2.TAZID.alias('GRID_1KM'),df1.LACCELL,df1.NUM).\dropna(how='any').\orderBy(["GRID_1KM", "LACCELL"], ascending=[1, 0])df3.show()
09-RDD的生成与转换
# 1 txt读取生成RDD和转换保存rdd = sc.textFile('/nj/signaling/2016/07/11/TRAFF_20160711235500.txt')rdd_save = sc.textFile('/nj/signaling/2016/07/11').\filter(lambda line: int(line.split(",")[0], 16) % 2 ==0).\saveAsTextFile("/nj/signaling2/2016/07/11")
# 2 自定义函数读取RDDfile=sc.textFile('/GPS/FeiTian/2017/07/*')def line2record(line) :segs = line.split(" ")return (segs[0],segs[1],segs[2],segs[5])file.map(line2record).take(10)[('2017-07-27', '23:59:57', '21582', '0'),('2017-07-27', '23:59:58', '133386', '0'),('2017-07-27', '22:59:00', '130387', '0'),('2017-07-27', '23:59:57', '125899', '0'),('2017-07-27', '22:59:58', '142358', '0'),('2017-07-27', '23:59:58', '110065', '0'),('2017-07-27', '22:59:58', '136810', '0'),('2017-07-27', '23:59:58', '139889', '1'),('2017-07-27', '23:59:57', '19877', '2'),('2017-07-27', '23:56:54', '32764', '0')]
# 3 自定义字段,方便字段组合生成新字段rdd = sc.textFile('/GPS/FeiTian/2017/07/201707302338.dt')rdd_split = rdd.map(lambda x:(x.split(" ")[2],(x.split(" ")[0]+" "+x.split(" ")[1],x.split(" ")[3],x.split(" ")[4],x.split(" ")[5],x.split(" ")[6],x.split(" ")[7],x.split(" ")[8],)))rdd_split.take(3)[('33712',('2017-07-30 23:37:55', '121.74655', '31.051933', '0', '0', '0.0', '05')),('135249',('2017-07-30 23:37:56', '121.4169', '31.2813', '0', '6', '11.0', '02')),('11292',('2017-07-30 23:37:20', '121.5148', '31.1553', '0', '2', '0.0', '02'))]rdd_groupbykey = rdd_split.groupByKey().map(lambda x : (x[0], list(x[1])))rdd_groupbykey.take(5)[('21664',[('2017-08-30 23:38:29', '121.77598', '30.958338', '0', '4', '0.0', '04')]),('1114',[('2017-07-30 23:38:33', '121.58', '31.3436', '1', '7', '0.0', '02')]),('172072',[('2017-07-30 23:38:39', '121.4904', '31.351997', '1', '2', '0.0', '05')]),('160125',[('2017-07-30 23:38:00', '121.344795', '31.19619', '0', '6', '0.0', '05'),('2017-07-30 23:38:40', '121.344795', '31.19619', '0', '6', '0.0', '05')]),('135655',[('2017-07-30 23:38:28', '121.4507', '31.3406', '1', '0', '0.0', '02')])]rdd_groupbykey.map(lambda x:x[1]).take(5)[[('2017-08-30 23:38:29', '121.77598', '30.958338', '0', '4', '0.0', '04')],[('2017-07-30 23:38:33', '121.58', '31.3436', '1', '7', '0.0', '02')],[('2017-07-30 23:38:39', '121.4904', '31.351997', '1', '2', '0.0', '05')],[('2017-07-30 23:38:00', '121.344795', '31.19619', '0', '6', '0.0', '05'),('2017-07-30 23:38:40', '121.344795', '31.19619', '0', '6', '0.0', '05')],[('2017-07-30 23:38:28', '121.4507', '31.3406', '1', '0', '0.0', '02')]]
# 4 自定义字段,方便字段组合生成新字段rdd = sc.textFile('file:///root/ydzhao/Two_passengers_and_one_danger/20171219_20171219135232.txt',4)from datetime import datetimerdd_split= rdd.map(lambda x:(datetime.strptime(x.split("@@")[0], "%Y-%m-%d %H:%M:%S"),x.split("@@")[1],x.split("@@")[2],x.split("@@")[3],int(x.split("@@")[4])*0.000001,int(x.split("@@")[5])*0.000001,int(x.split("@@")[6]),int(x.split("@@")[7]),int(x.split("@@")[8]),x.split("@@")[9],int(x.split("@@")[10]),x.split("@@")[11],x.split("@@")[12]))from pyspark.sql.types import *schema = StructType([StructField("TimeStamp",TimestampType(),True),StructField("VehicleID",StringType(),True),StructField("VehiclePlateColor",StringType(),True),StructField("MessageSeq",StringType(),True),StructField("Lng",DoubleType(),True),StructField("Lat",DoubleType(),True),StructField("TerminalSpeed",IntegerType(),True),StructField("DrivingSpeed",IntegerType(),True),StructField("TotalMile",IntegerType(),True),StructField("Direction",StringType(),True),StructField("Altitude",IntegerType(),True),StructField("StatusBit",StringType(),True),StructField("AlarmStatus",StringType(),True)])df2 = sqlContext.createDataFrame(rdd_split,schema)df2.registerTempTable("df2")
10-JSON格式嵌套问题
解决JSON格式嵌套问题
df = sqlContext.read.json('file:///home/UnicomGSM/data/20170614103000.json')df.printSchema()root|-- RoadSegState: struct (nullable = true)| |-- DateTimeDelay: long (nullable = true)| |-- Datetime: string (nullable = true)| |-- Description: string (nullable = true)| |-- IntersectionDelay: long (nullable = true)| |-- IsRoadIntersection: string (nullable = true)| |-- MobileNumber: long (nullable = true)| |-- Number: long (nullable = true)| |-- RoadSegID: string (nullable = true)| |-- SigNumber: long (nullable = true)| |-- Speed: double (nullable = true)| |-- SpeedDiff: double (nullable = true)| |-- State: string (nullable = true)| |-- Time: double (nullable = true)
df1 = df.select([df.RoadSegState.DateTimeDelay.alias("DateTimeDelay"),df.RoadSegState.DateTime.alias("DateTime"),df.RoadSegState.Description.alias("Description"),df.RoadSegState.IntersectionDelay.alias("IntersectionDelay"),df.RoadSegState.IsRoadIntersection.alias("IsRoadIntersection"),df.RoadSegState.MobileNumber.alias("MobileNumber"),df.RoadSegState.Number.alias("Number"),df.RoadSegState.RoadSegID.alias("RoadSegID"),df.RoadSegState.SigNumber.alias("SigNumber"),df.RoadSegState.Speed.alias("Speed"),df.RoadSegState.SpeedDiff.alias("SpeedDiff"),df.RoadSegState.State.alias("State"),df.RoadSegState.Time.alias("Time")])df1.printSchema()root|-- DateTimeDelay: long (nullable = true)|-- DateTime: string (nullable = true)|-- Description: string (nullable = true)|-- IntersectionDelay: long (nullable = true)|-- IsRoadIntersection: string (nullable = true)|-- MobileNumber: long (nullable = true)|-- Number: long (nullable = true)|-- RoadSegID: string (nullable = true)|-- SigNumber: long (nullable = true)|-- Speed: double (nullable = true)|-- SpeedDiff: double (nullable = true)|-- State: string (nullable = true)|-- Time: double (nullable = true)
11-str转TimestampType()
import pyspark.sql.functions as funcfrom pyspark.sql.types import TimestampTypefrom datetime import datetimedf_y = sqlContext.read.json("/user/test.json")udf_dt = func.udf(lambda x: datetime.strptime(x, '%Y%m%d%H%M%S'), TimestampType())df = df_y.withColumn('datetime', udf_dt(df_y.date))df_g = df_y.groupby(func.hour(df_y.date))df_y.groupby(df_y.name).agg(func.countDistinct('address')).show()
12-字段去重计数:countDistinct和approxCountDistinct
精确计数countDistinct
from pyspark.sql.functions import col, countDistinctdf.agg(*(countDistinct(col(c)).alias(c) for c in df.columns))from pyspark.sql.functions import col, countDistinctdf.agg(countDistinct(col("colName")).alias("count")).show()
from pyspark.sql.functions import countDistinctdf1.agg(countDistinct(df1.msid).alias('count')).collect()
大概计数approxCountDistinct
如果你想加快速度,可能会损失精度,可以使用approxCountDistinct()
from pyspark.sql.functions import approxCountDistinctdf1.agg(approxCountDistinct(df1.msid).alias('count')).collect()
显然countDistinct不如approxCountDistinct性能好
13-PySpark新增列问题
from pyspark.sql.functions import col, expr, when
方法一
new_column_1 = expr("""IF(fruit1 IS NULL OR fruit2 IS NULL, 3, IF(fruit1 = fruit2, 1, 0))""")
方法二:思路清晰,推荐使用
new_column_2 = when(col("fruit1").isNull() | col("fruit2").isNull(), 3).when(col("fruit1") == col("fruit2"), 1).otherwise(0)
方法三:用的少
from pyspark.sql.functions import coalesce, litnew_column_3 = coalesce((col("fruit1") == col("fruit2")).cast("int"), lit(3))
df = sc.parallelize([("orange", "apple"), ("kiwi", None), (None, "banana"),("mango", "mango"), (None, None)]).toDF(["fruit1", "fruit2"])
df.withColumn("new_column_1", new_column_1).\withColumn("new_column_2", new_column_2).\withColumn("new_column_3", new_column_3)+------+------+------------+------------+------------+|fruit1|fruit2|new_column_1|new_column_2|new_column_3|+------+------+------------+------------+------------+|orange| apple| 0| 0| 0|| kiwi| null| 3| 3| 3|| null|banana| 3| 3| 3|| mango| mango| 1| 1| 1|| null| null| 3| 3| 3|+------+------+------------+------------+------------+
方法四 : 自定义函数
from pyspark.sql.types import IntegerTypefrom pyspark.sql.functions import udfdef func(fruit1, fruit2):if fruit1 == None or fruit2 == None:return 3if fruit1 == fruit2:return 1return 0func_udf = udf(func, IntegerType())df = df.withColumn('new_column',func_udf(df['fruit1'], df['fruit2']))
14-PySpark数据填充、过滤
id Value1 1032 15043 1from pyspark.sql.functions import lpad>>> df.select('id',lpad(df['value'],4,'0').alias('value')).show()+---+-----+| id|value|+---+-----+| 1| 0103|| 2| 1504|| 3| 0001|+---+-----+
# filter/wherefrom pyspark.sql.functions import coldf.where(col("dt_mvmt").isNull())df.where(col("dt_mvmt").isNotNull())df.na.drop(subset=["dt_mvmt"])df.filter(df.dt_mvmt.isNotNull()).count()col_list = df.schema.namesdf_fltered = df.where(col(c) >= 10 for c in col_list)
15-Renaming-Columns-for-PySpark-DataFrames-Aggregates
# 方法一:需要提前知道agg后的列名SUM(money),这个不好df.groupBy("group")\.agg({"money":"sum"})\.withColumnRenamed("SUM(money)", "money").show(100)# 方法二:推荐使用import pyspark.sql.functions as funcdf.groupBy("group")\.agg(func.sum('money').alias('money'))\.show(100)
#####cols = [i.name for i in df.schema.fields if "StructType" in str(i.dataType)]df.select(cols)#####df = sc.\parallelize([(1,'female',233), (None,'female',314),(0,'female',81),(1, None, 342), (1,'male',109)]).\toDF().\withColumnRenamed("_1","survived").\withColumnRenamed("_2","sex").\withColumnRenamed("_3","count")total = df.select("count").agg(sum('count').alias('sum_count')).collect().pop()['sum_count']result = df.withColumn('percent', (df['count']/total) * 100)result.show()+--------+------+-----+------------------+|survived| sex|count| percent|+--------+------+-----+------------------+| 1|female| 233| 21.59406858202039|| null|female| 314|29.101019462465246|| 0|female| 81| 7.506950880444857|| 1| null| 342| 31.69601482854495|| 1| male| 109|10.101946246524559|+--------+------+-----+------------------+
df = sc.parallelize([("XYZ12", "B1, B44, B66", "A, C", 59),("ZYY3 ", "B8, B3, B7", "J, Z", 66)]).toDF(["dbn", "bus", "subway", "score"])from pyspark.sql.functions import col, explode, split, trimwith_bus_exploded = df.withColumn("bus", explode(split("bus", ",")))with_bus_trimmed = with_bus_exploded.withColumn("bus", trim(col("bus")))+-----+---+------+-----+| dbn|bus|subway|score|+-----+---+------+-----+|XYZ12| B1| A, C| 59||XYZ12|B44| A, C| 59||XYZ12|B66| A, C| 59||ZYY3 | B8| J, Z| 66||ZYY3 | B3| J, Z| 66||ZYY3 | B7| J, Z| 66|+-----+---+------+-----+
16-保存Pyspark-dataframe到Hbase
df = sc.parallelize([('a', '1.0'), ('b', '2.0')]).toDF(schema=['col0', 'col1'])catalog = ''.join("""{"table":{"namespace":"default", "name":"testtable"},"rowkey":"key","columns":{"col0":{"cf":"rowkey", "col":"key", "type":"string"},"col1":{"cf":"cf", "col":"col1", "type":"string"}}}""".split())# write to hbasedf.write \.options(catalog=catalog) \.format('org.apache.spark.sql.execution.datasources.hbase') \.mode("overwrite") \.option("zkUrl","host1,host2,host3:2181") \.save()# readingdf_read = spark.read.options(catalog=catalog).format('org.apache.spark.sql.execution.datasources.hbase').load()df_read .show()"PYSPARK_SUBMIT_ARGS": "--master yarn \--jars hbase_spark_jar/hbase-0.90.2.jar,\/hbase_spark_jar/hbase-client-1.3.1.jar,\hbase_spark_jar/spark-avro_2.11-3.0.1.jar,\/hbase_spark_jar/hbase-spark-1.2.0-cdh5.7.3.jar,\/hbase_spark_jar/shc-1.0.0-2.0-s_2.11.jar \--files /etc/hbase/2.5.0.0-1245/0/hbase-site.xml \--executor-memory 8g \--executor-cores 4 \--num-executors 4 \pyspark-shell"
17-新增列时when-otherwise的使用
when otherwise类似于SQL中case when end的作用
df = [**id** **col1** **col2** **col3** **col4**101 1 0 1 1102 0 1 1 0103 1 1 0 1104 0 0 1 1]from pyspark.sql.functions import when, litdef update_col_check(df, col_name):return df.withColumn('col_check', when(df[col_name] == 1, lit(col_name)).otherwise(df['col_check']))update_col_check(df, 'col1').show()+---+----+----+----+----+---------+| id|col1|col2|col3|col4|col_check|+---+----+----+----+----+---------+|101| 1| 0| 1| 1| col1||102| 0| 1| 1| 0| -1||103| 1| 1| 0| 1| col1||104| 0| 0| 1| 1| -1|+---+----+----+----+----+---------+update_col_check(df, 'col2').show()+---+----+----+----+----+---------+| id|col1|col2|col3|col4|col_check|+---+----+----+----+----+---------+|101| 1| 0| 1| 1| -1||102| 0| 1| 1| 0| col2||103| 1| 1| 0| 1| col2||104| 0| 0| 1| 1| -1|+---+----+----+----+----+---------+
from pyspark.sql.functions import whendf.select(df.name, when(df.age > 4, 1).when(df.age < 3, -1).otherwise(0)).show()+-----+------------------------------------------------------------+| name|CASE WHEN (age > 4) THEN 1 WHEN (age < 3) THEN -1 ELSE 0 END|+-----+------------------------------------------------------------+|Alice| -1|| Bob| 1|+-----+------------------------------------------------------------+
18-PySpark-DataFrame元组列表的解压缩
from pyspark.sql.functions import udf, col# create the dataframedf = sqlContext.createDataFrame([(1, [('blue', 0.5),('red', 0.1),('green', 0.7)]),(2, [('red', 0.9),('cyan', 0.5),('white', 0.4)])],('Topic', 'Tokens'))df.show()
+-----+-------------------------------------------+|Topic| Tokens |+-----+-------------------------------------------+| 1| ('blue', 0.5),('red', 0.1),('green', 0.7)|| 2| ('red', 0.9),('cyan', 0.5),('white', 0.4)|+-----+-------------------------------------------+
def get_colors(l):return [x[0] for x in l]def get_weights(l):return [x[1] for x in l]# make udfs from the above functions - Note the return typesget_colors_udf = udf(get_colors, ArrayType(StringType()))get_weights_udf = udf(get_weights, ArrayType(FloatType()))# use withColumn and apply the udfsdf.withColumn('Weights', get_weights_udf(col('Tokens')))\.withColumn('Tokens', get_colors_udf(col('Tokens')))\.select(['Topic', 'Tokens', 'Weights'])\.show()+-----+------------------+---------------+|Topic| Tokens| Weights|+-----+------------------+---------------+| 1|[blue, red, green]|[0.5, 0.1, 0.7]|| 2|[red, cyan, white]|[0.9, 0.5, 0.4]|+-----+------------------+---------------+
root|-- Topic: long (nullable = true)|-- Tokens: array (nullable = true)| |-- element: struct (containsNull = true)| | |-- _1: string (nullable = true)| | |-- _2: double (nullable = true)
from pyspark.sql.functions import coldf.select(col("Topic"),col("Tokens._1").alias("Tokens"), col("Tokens._2").alias("weights")).show()
+-----+------------------+---------------+|Topic| Tokens| weights|+-----+------------------+---------------+| 1|[blue, red, green]|[0.5, 0.1, 0.7]|| 2|[red, cyan, white]|[0.9, 0.5, 0.4]|+-----+------------------+---------------+
cols = [col("Tokens.{}".format(n)) for n indf.schema["Tokens"].dataType.elementType.names]df.select("Topic", *cols)
19-Spark—shuffle-write
什么时候需要 shuffle writer
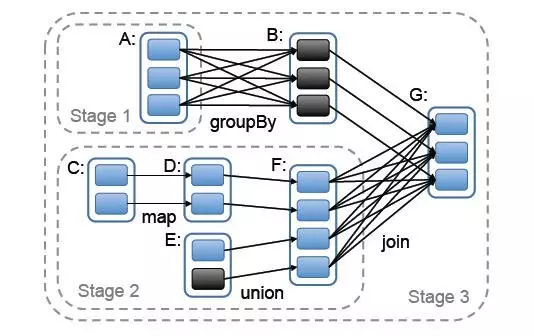
我们抽象出来其中的RDD和依赖关系

对应的划分后的RDD结构为:
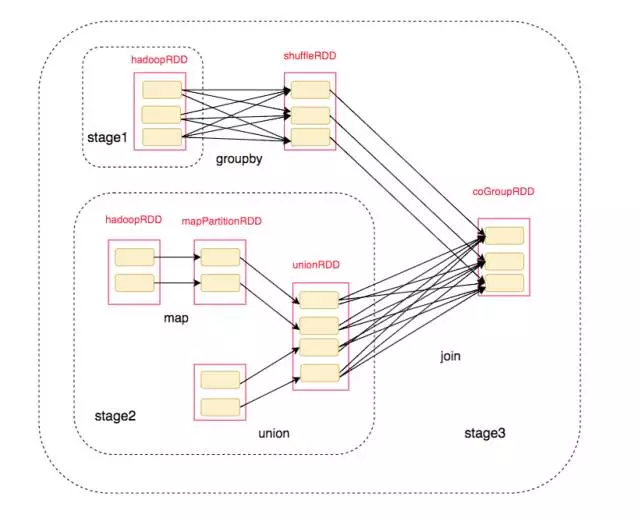
最终我们得到了整个执行过程:
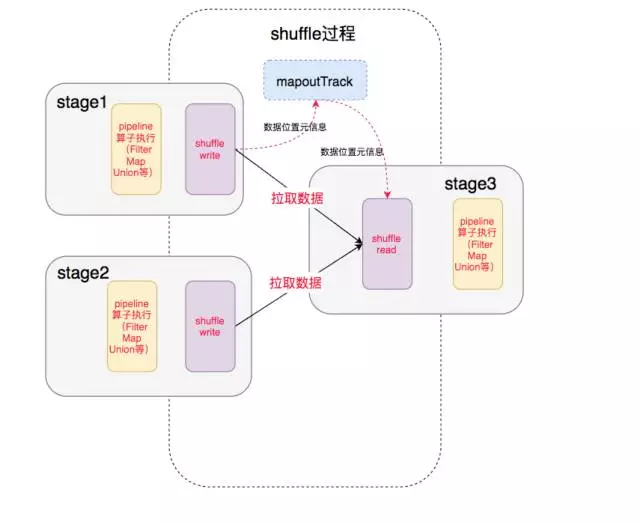
中间就涉及到shuffle 过程,前一个stage的ShuffleMapTask 进行 shuffle write, 把数据存储在 blockManager上面, 并且把数据位置元信息上报到driver 的mapOutTrack 组件中, 下一个stage 根据数据位置元信息, 进行shuffle read, 拉取上个stage的输出数据。
UnsafeShuffleWriter
UnsafeShuffleWriter里面维护着一个 ShuffleExternalSorter, 用来做外部排序,外部排序就是要先部分排序数据并把数据输出到磁盘,然后最后再进行merge 全局排序, 既然这里也是外部排序,跟SortShuffleWriter有什么区别呢, 这里只根据 record的 artition id 先在内存 ShuffleInMemorySorter中进行排序, 排好序的数据经过序列化压缩输出到换一个临时文件的一段,并且记录每个分区段的seek位置,方便后续可以单独读取每个分区的数据,读取流经过解压反序列化,就可以正常读取了。
整个过程就是不断地在ShuffleInMemorySorter插入数据,如果没有内存就申请内存,如果申请不到内存就spill 到文件中,最终合并成一个 依据partition id全局有序 的大文件。


若有收获,就点个赞吧
0 人点赞
