1 Spark应用执行机制分析
(1)Spark基本概念
——SparkContext(Spark2.0以上SparkSession):Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor。
——Driver Program:运行Application的main()函数并创建SparkContext.。
——RDD:Spark Core的数据结构,下节会详细介绍。可以通过一系列算子进行操作。当RDD遇到Action操作时,将会将前面所有的Transform操作形成一个有向无环图(DAG)。再在Spark中转换为Job,提交到集群执行。一个Application中可以包含多个Job。
——Worker Node:集群中任何可以运行Application代码的节点,运行一个或多个Executor进程。
——Executor:为Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。每个Application都会申请各自的Executor来处理任务。
(2)Spark应用(Application)执行过程中各个组件的概念。
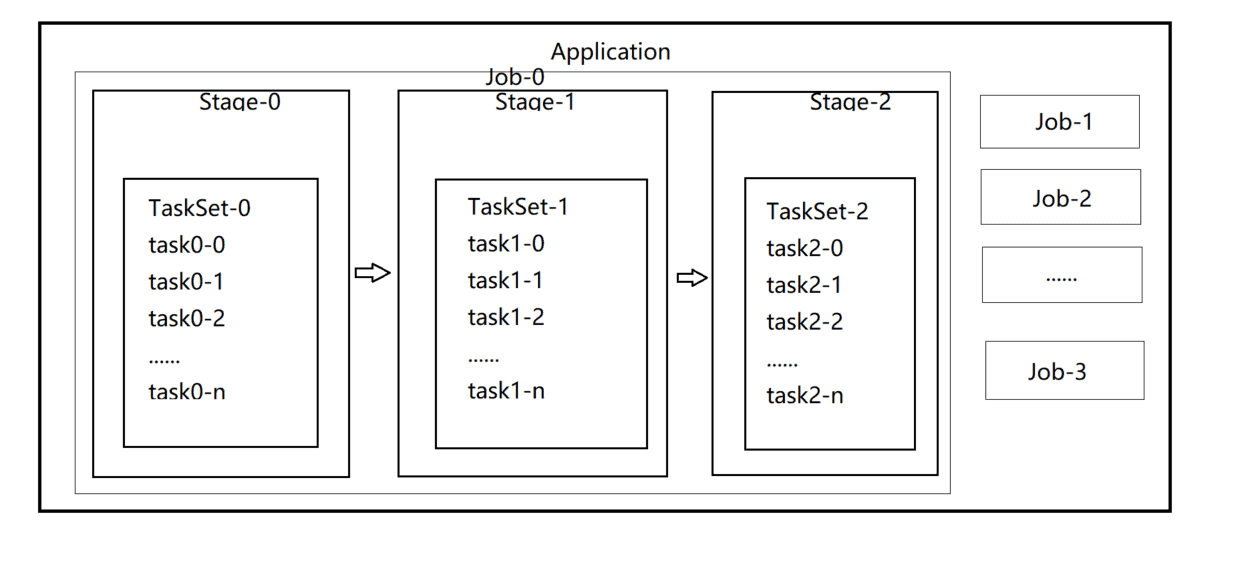
——TASK(任务):RDD 中的一个分区对应一个Task,Task是单个分区上最小的处理流程单元。
——TsakSet(任务集):一组关联的,但是相互之间没有Shuffle依赖关系的Task集合。
——Stage(调度阶段):一个TaskSet对应的调度阶段。每个Job都会根据RDD的宽依赖关系被切分很多Stage,每个Stage都包含一个TaskSet。
——Job(作业):由Action操作触发生成的由一个或多个Stage组成的计算作业。
——Application(应用程序):用户编写的Spark的应用程序,由一个或多个Job组成。提交到Spark之后,Spark为Application分配资源,将程序转换并执行。
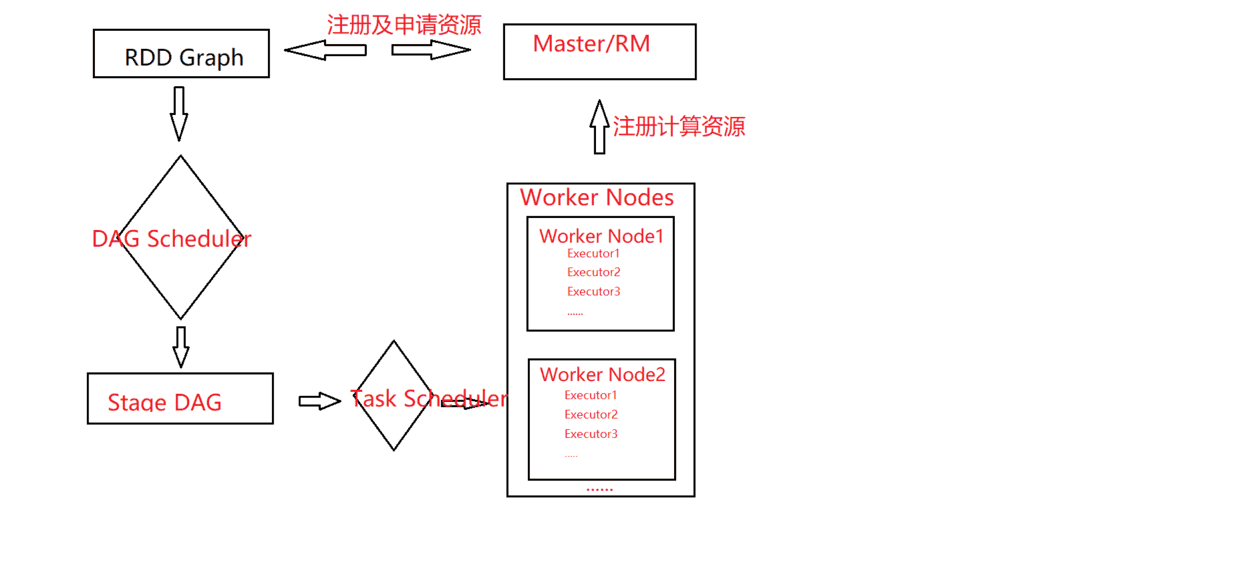
——DAGSchedular:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler。
——TaskScheduler:将TaskSet提交给Worker Node集群运行并返回结果。
Spark基本概念之间的关系:
Spark执行流程:
(3)应用提交与执行
Spark使用Driver进程负责应用的解析、切分Stage并调度Task到Executor执行,包含DAGScheduler等重要对象。Driver进程的运行地点有两种。
Client模式和Cluster模式:
Client模式:Driver进程运行在Client端,对应用进行管理监控。
Cluster模式:Master节点指定某个Worker节点启动Driver进程,负责监控整个应用的执行。
2 Spark调度机制
——Application的调度
Standalone模式
Mesos模式
YARN模式:如果在YARN上运行Spark,用户可以在YARN的客户端上设置
—num-executors:控制应用分配的Executor数量;
—executor-memory:指定每个Executor的内存大小;
—executor-cores:指定Executor占用的CPU的核数。
下面是一个实际生产应用spark-submit采用Yarn模式的参数设置:
spark-submit —master yarn \ —deploy-mode cluster \ —num-executors 25 \ —executor-cores 2 \ —driver-memory 8g \ —executor-memory 8g \ —conf spark.broadcast.compress=true jh_od_stats.py > /app/log/.out 2>&1
3 Spark存储与I/O
4 Spark的通信机制
分布式通信方式:RPC等。
通信框架:AKKA,任何需要高吞吐率和低延迟的系统都是使用AKKA。
Client、Master和Worker之间的通信
5 Spark的容错机制和依赖
对于大数据分析而言,数据检查点操作成本较高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低,同时也会消耗大量存储资源。
Spark选择记录更细的方式,但是更新颗粒度过细时,记录更新成本也不低。因此RDD只支持粗粒度转换,即只记录单个块上执行的单个操作,然后将创建RDD的一系列变换序列记录下来,以便于恢复丢失的分区。
对于分布式系统,数据集的容错性通常有两种方式:
(1)记录数据的更新(在Spark中对应的Linage血统机制)
每个RDD除了包含分区信息外,还包含它从父辈RDD变换过来的步骤,以及如何重建某一块数据的信息,因此RDD的这种容错机制又称为“血统”(Linage)容错。Lineage本质上很类似于数据库中的重做日志(Redo Log),只不过这个重做日志粒度很大,是对全局数据做同样的重做以便于恢复数据。
RDD在Lineage容错方面采用如下两种依赖来保证容错方面的性能:
——窄依赖(Narrow Dependeny):窄依赖是指父RDD的每一个分区最多被一个子RDD的分区所用。表现为一个父RDD的分区对应于一个子RDD的分区,或者多个父RDD的分区对应于一个子RDD的分区。一个父RDD分区对应一个子RDD分区,分为以下两种情况:
子RDD分区与父RDD分区一一对应(如map、filter等算子) 一个子RDD分区对应N个父RDD分区一一对应(如co-partitioned(协同划分)过的Join)
——宽依赖(Wide Dependency):是指一个父RDD分区对应多个子RDD分区,可以分为以下两种情况:
一个父RDD对应所有子RDD分区(未经协同划分的Join) 一个父RDD对应多个RDD分区(非全部分区,如groupByKey)
(2)数据检查点(在Spark中对应Checkpoint机制)
Checkpoint的本质是将RDD写入Disk来作为检查点。这是对lineage血统做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错。如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
6 Spark的shuffle机制
在原来的Hadoop的MapReduce计算框架中,Shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须用到Shuffle这个环节,Shuffle的性能高低直接影响了整个程序的性能和吞吐量。而Spark作为MapReduce框架的一种实现,自然也实现了Shuffle的逻辑。对于大数据计算框架而言,Shuffle阶段的效率是决定计算性能好坏的关键因素之一。
Shuffle是MapReduce计算框架中的一个特定的阶段,介于Map阶段和Reduce阶段之间。当Map的输出结果要被Reduce使用时,输出结果需要按照关键字值(key)哈希,并且分发到每一个Reducer上面,这个过程就叫做Shuffle。Spark Shuffle机制是将一组无规则的数据转换为一组具有一定规则数据的过程。由于Shuffle涉及了磁盘的读写和网络间的传输,因此Shuffle性能的高低直接影响整个程序的运行效率。Shuflle出发包括Shuffle Read和Shuffle Write。

若有收获,就点个赞吧
0 人点赞
